Why Agents Need an Explicit Middle Layer
Published:
TL;DR: this round keeps circling one idea. The useful papers are not just bigger end-to-end systems, they are systems that make the middle layer explicit: BEV tokens, latent reasoning, manifold groups, retrieval pages. That is where the model gets a handle on geometry, control, or evidence.
I am also trying not to repeat the last few issues. We already spent a lot of time on verifiable state, replayable workspaces, and closed loops. This time I wanted papers that say something slightly different: when the hidden intermediate representation becomes a first-class object, the model gets easier to steer, easier to compare, and sometimes easier to trust.
Paper Notes
Hermes++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
Authors: Xin Zhou, Dingkang Liang, Xiwu Chen, Feiyang Tan, Dingyuan Zhang, Hengshuang Zhao, Xiang Bai.
Institutions: Huazhong University of Science and Technology, Mach Drive, University of Hong Kong.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML | code
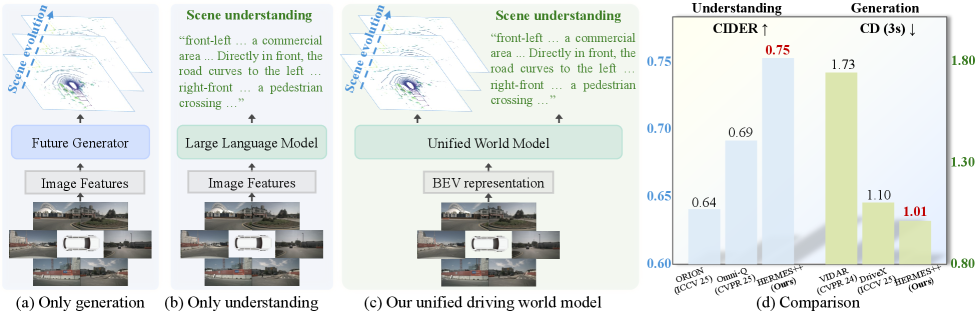
This is the paper’s bluntest claim: driving should not be split into one model that understands the scene and another that predicts the future. Hermes++ puts both into one pipeline and keeps the geometric layer visible instead of burying it. The caveat is that this is still a driving-specific world model, not a general agent architecture.
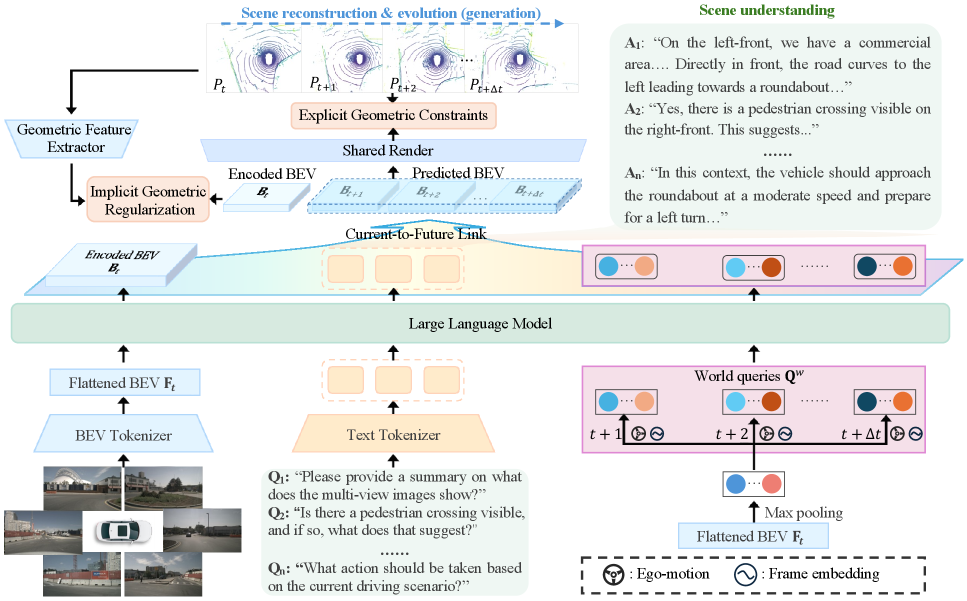
The pipeline is the real story. Multi-view inputs are flattened into BEV tokens, instructions and world queries go into the LLM side, and the Current-to-Future Link carries semantic context into future geometry prediction. I read this as a deliberate attempt to stop the model from treating geometry as a side effect.
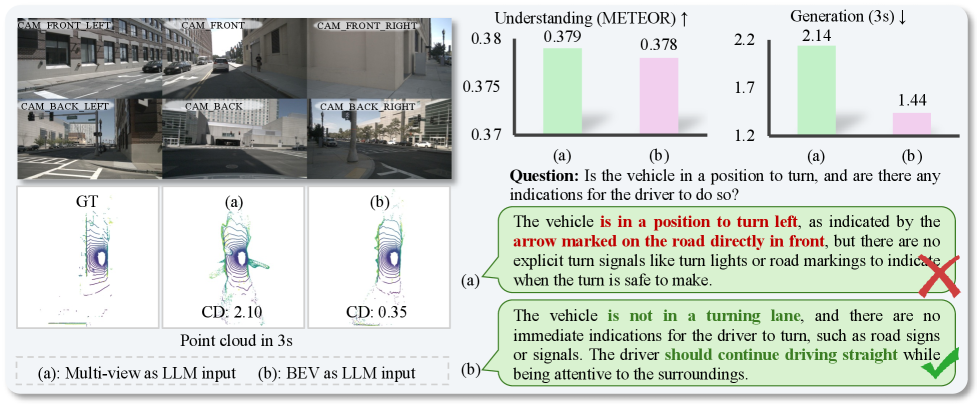
This figure makes the architectural bet more concrete. The multi-view baseline can look fine on text metrics but still collapse spatial structure, while the BEV route keeps the scene organized enough to forecast motion. It is a reminder that for world models, geometry is not a cosmetic detail.
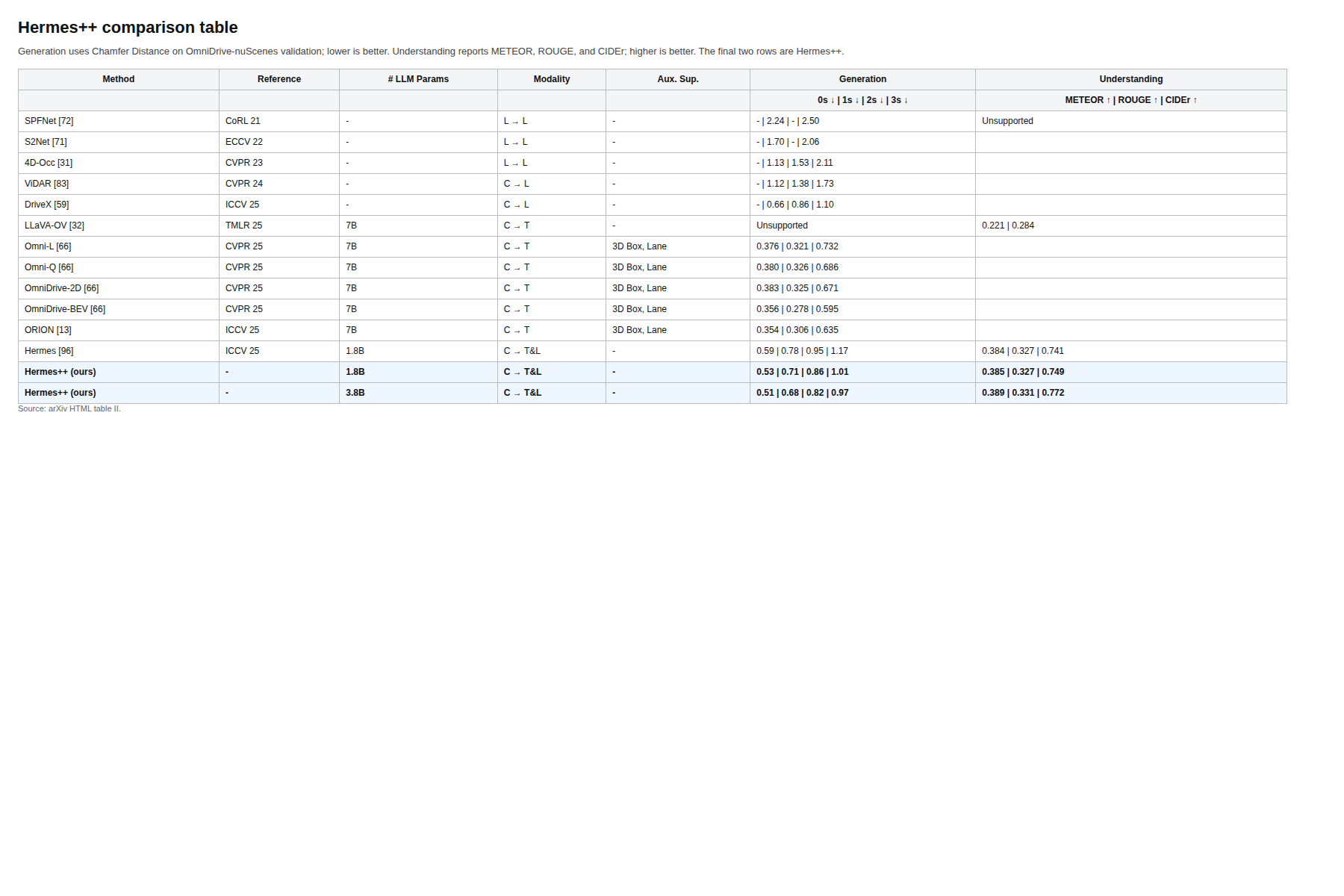
The comparison table gives the numbers. Hermes++ at 3.8B reports 0.51/0.68/0.82/0.97 Chamfer distance for 0-3s prediction and 0.389 METEOR, 0.331 ROUGE, 0.772 CIDEr on understanding, while the earlier Hermes row is weaker on generation and a bit behind on the language side. The caveat is obvious: these are still driving benchmarks, so the gains tell us a lot about this domain and less about open-ended planning.
Quick idea: Hermes++ is a unified driving world model that tries to make current-scene semantics and future geometry talk to each other.
Why it matters: most driving systems still split understanding and generation. This paper argues that split is expensive, because the future is easier to predict when the model has a semantic handle on the current scene.
Method walkthrough:
- Flatten multi-view BEV features into a token stream the LLM can actually work with.
- Inject instructions and world queries so the understanding branch can pass semantic context forward.
- Use a Current-to-Future Link to condition future geometry on that semantic context.
- Add Joint Geometric Optimization so the internal representation does not drift away from geometry-aware priors.
Evidence: the best table row is the clearest evidence, but the qualitative figures matter too. Figure 4 shows why BEV inputs are easier to keep structurally consistent than a multi-view baseline, and Figure 5 suggests the geometric regularizer is shaping the internal space rather than just polishing the output. The paper also compares against specialist generation and understanding models, which helps show the tradeoff instead of hiding it.
Why I care: I keep looking for papers where the intermediate state is not an implementation detail. This one is useful because it makes that state explicit, then asks whether the future can be predicted better when the model can see its own semantic context.
Limitations/questions: the whole setup is still tightly coupled to driving. I would want to know how brittle the BEV and world-query design is under severe domain shift, and whether the same semantic-to-geometric bridge survives when the scene is noisier or less curated.
Connection to the tracked themes: world models, explicit state, geometry-aware agents.
LaST-R1: Reinforcing Action via Adaptive Physical Latent Reasoning for VLA Models
Authors: Hao Chen, Jiaming Liu, Zhonghao Yan, Nuowei Han, Renrui Zhang, Chenyang Gu, Jialin Gao, Ziyu Guo, Siyuan Qian, Yinxi Wang, Peng Jia, Chi-Wing Fu, Shanghang Zhang, Pheng-Ann Heng.
Institutions: The Chinese University of Hong Kong, Peking University, Simplexity Robotics.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML | project
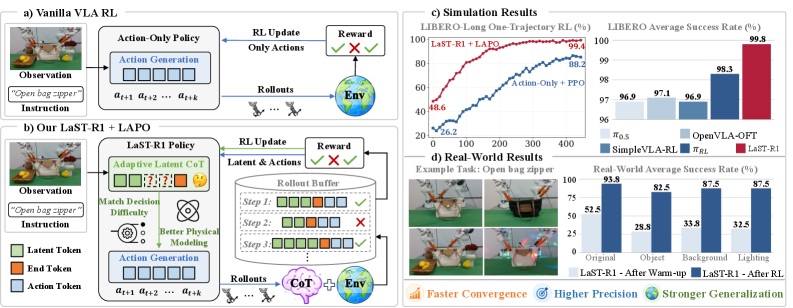
LaST-R1 is not just another VLA post-training paper. The point is that the model is asked to reason in a latent physical space before it acts, and the RL recipe is built to optimize that latent path instead of only the final action. The short version is that the paper treats reasoning as part of control.
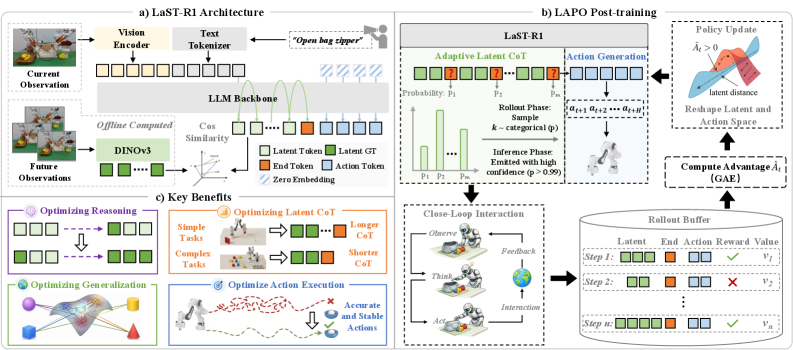
The architecture makes the move explicit. A vision foundation model supplies physically grounded latent targets, the latent CoT runs before action generation, and the RL stage updates both pieces together. The hybrid attention mask is a nice detail: sequential for reasoning, parallel for action chunks.

The learning curves are the part I trust most here. On LIBERO, the LAPO variant converges faster than the action-only PPO baseline, which supports the claim that the latent channel is doing real work rather than just adding tokens. The caveat is that learning curves can flatter a method if the benchmark is already close to saturation.
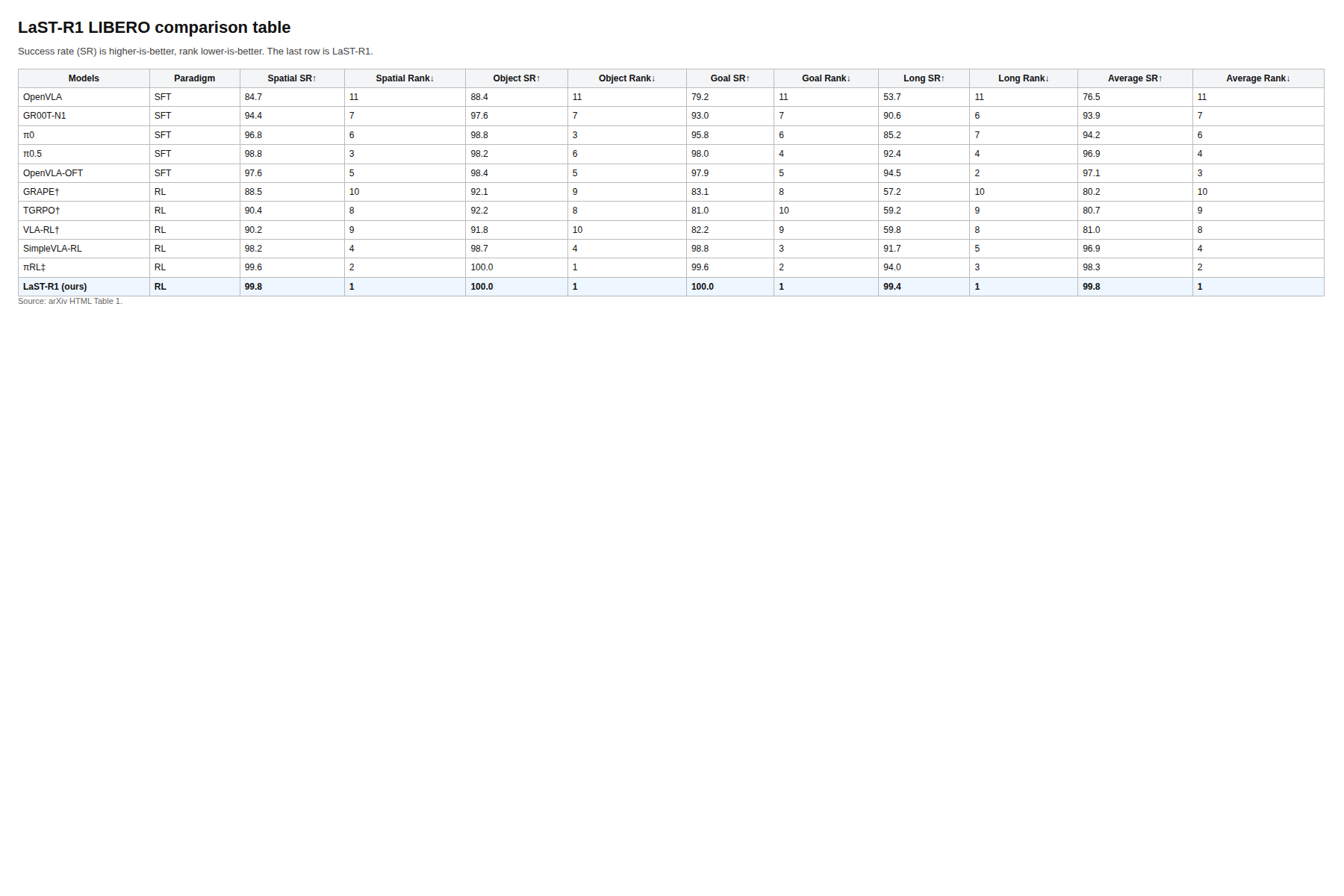
The table is hard to ignore: LaST-R1 reaches 99.8 average success on LIBERO, with 99.8 spatial, 100 object, 100 goal, and 99.4 long-horizon success. The real-world table in the paper shows big jumps after RL as well, including up to 44% improvement over the warm-up policy. The caveat is that these are still a narrow set of manipulation tasks, so I would not overread the headline score.
Quick idea: LaST-R1 jointly optimizes latent physical reasoning and action generation, then learns how long that latent reasoning should be.
Why it matters: most VLA systems either reason in language with extra latency or skip the reasoning path when they do RL. This paper tries to push the reasoning path into the policy itself.
Method walkthrough:
- Warm up the VLA model with one-shot supervised data.
- Run Latent-to-Action Policy Optimization so the latent reasoning trajectory and the action channel are both updated.
- Use an adaptive latent CoT so the model can shorten or lengthen its reasoning horizon by task complexity.
- Keep the reasoning and action phases separated by a hybrid attention mask, so the model can reason sequentially and act efficiently.
Evidence: Table 1 gives the cleanest LIBERO comparison, and Table 2 shows the real-world gains under unseen objects, background changes, and lighting changes. Figure 3 shows the convergence story, and Figure 5 shows that the RL-optimized policy keeps improving under out-of-distribution settings where the action-only baseline stalls.
Why I care: this is one of the few recent VLA papers that treats the intermediate reasoning path as something worth optimizing directly. I care because that is closer to how a useful agent should behave than a system that only gets rewarded at the end.
Limitations/questions: the empirical scope is still modest. I would want to know whether the adaptive latent length remains stable outside LIBERO, and whether the latent objective keeps helping once the observation stream gets noisier or the task horizon gets longer.
Connection to the tracked themes: agentic training, latent world modeling, adaptive control.
Do Sparse Autoencoders Capture Concept Manifolds?
Authors: Usha Bhalla, Thomas Fel, Can Rager, Sheridan Feucht, Tal Haklay, Daniel Wurgaft, Siddharth Boppana, Matthew Kowal, Vasudev Shyam, Owen Lewis, Thomas McGrath, Jack Merullo, Atticus Geiger, Ekdeep Singh Lubana.
Institutions: Harvard University, Northeastern University, Technion IIT, Stanford University.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML | code
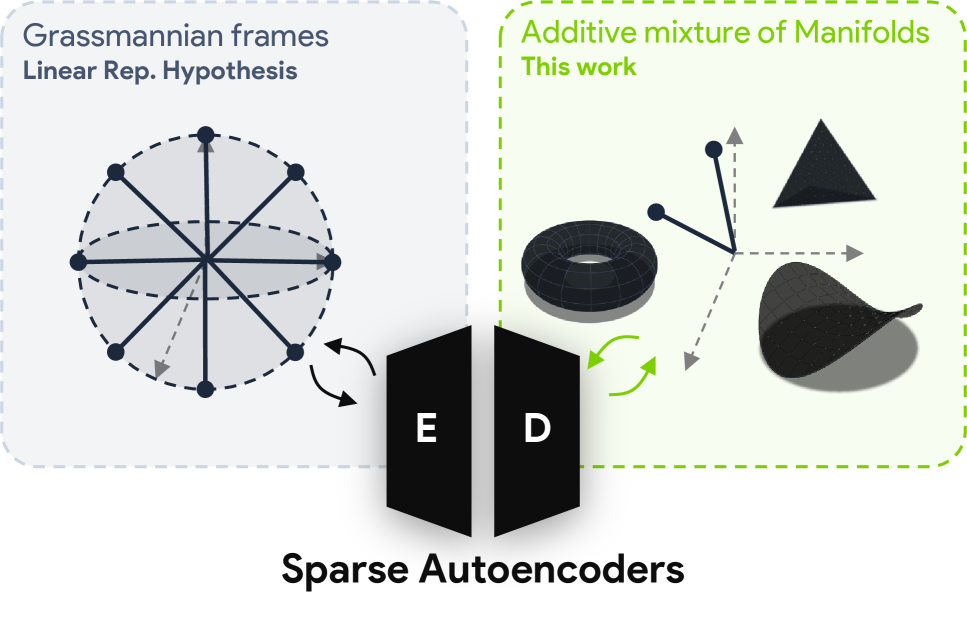
This paper is more theoretical than the others, but it lands on a practical point: concepts in model activations are often not single directions. They are manifolds. The useful part is that the paper does not stop at that observation. It defines what it would mean for an SAE to capture such a manifold and then checks when current architectures actually do it.
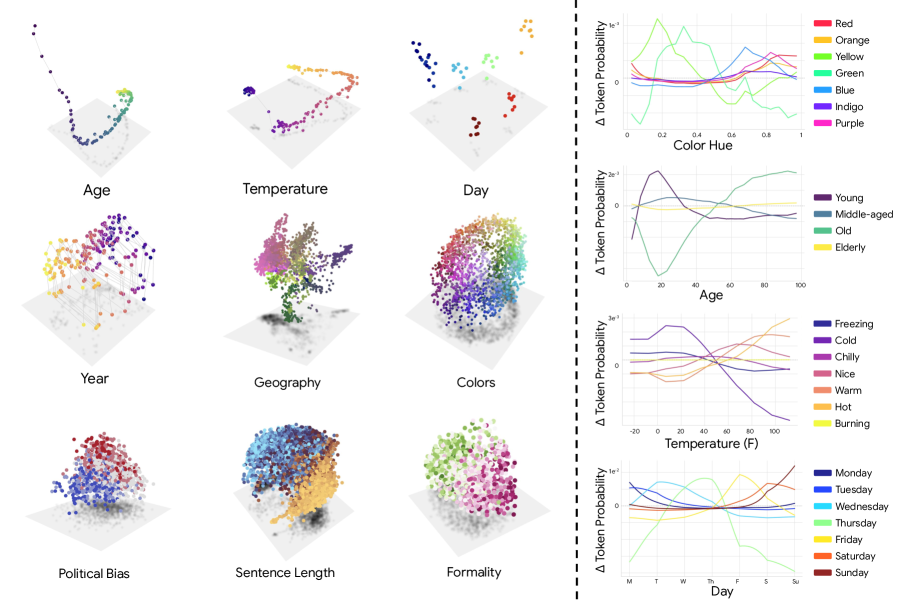
The evidence figure is the intuition pump. Continuous concepts like age, temperature, day, and color look smooth in PCA space, and steering between concept centroids produces smooth output changes. That supports the idea that the latent geometry is continuous, not a bag of isolated features.
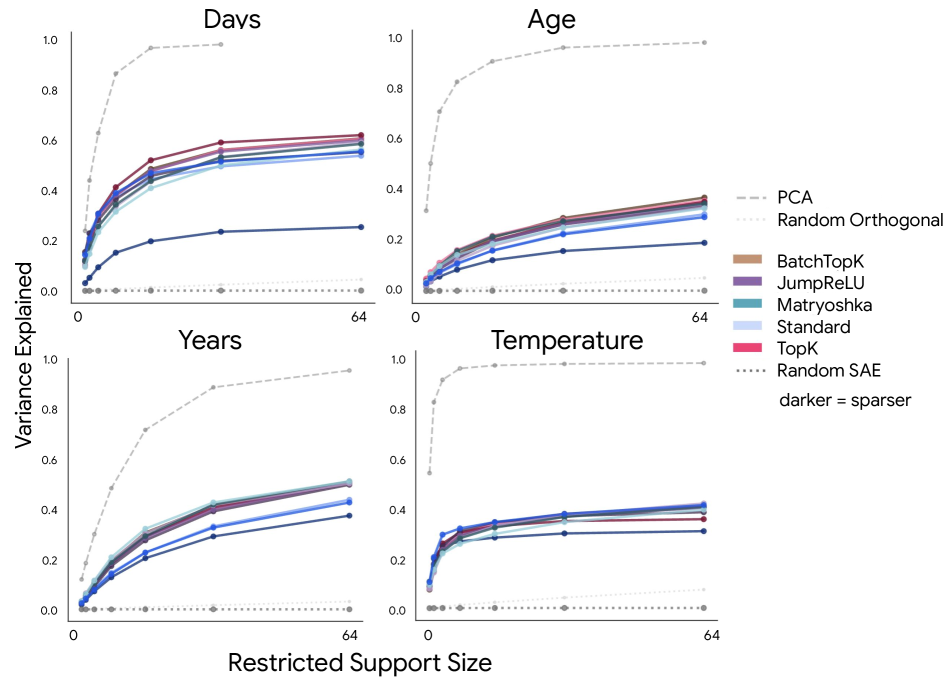
This is the result I would keep coming back to. Variance explained rises as more restricted SAE features are added, but it plateaus well beyond the manifold’s ambient dimension. The authors interpret that as dilution: the geometry is spread across many local features instead of being packed into a compact group.
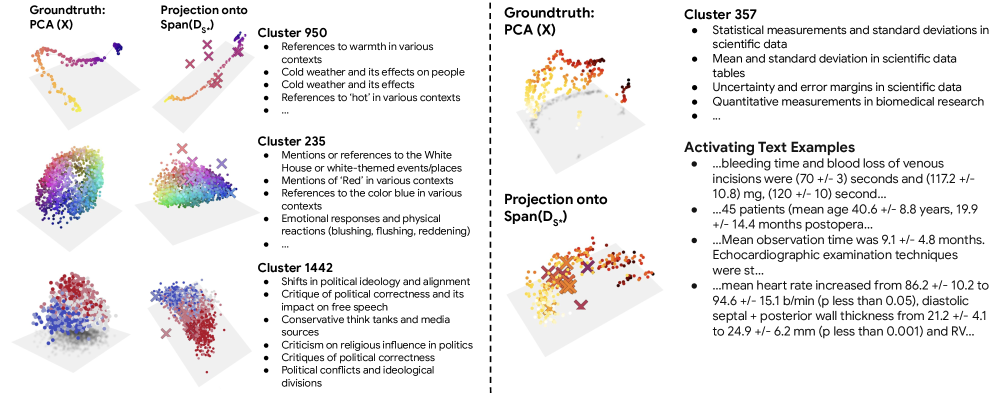
The discovery figure is where the paper stops being only diagnostic. The Ising-based grouping recovers known manifolds like temperature, colors, and political bias, and it even surfaces a possible epistemic-uncertainty manifold in scientific text. The caveat is that this is a post-hoc discovery pipeline, so it is suggestive rather than a clean causal guarantee.
Quick idea: SAEs may capture concept manifolds, but they often do so in a fragmented way, mixing global subspaces and local tiling.
Why it matters: interpretability work often assumes a concept is a direction. If the real object is a manifold, then a lot of steering and probing logic is only halfway pointed at the problem.
Method walkthrough:
- Define manifold capture in two modes: global subspace capture and local tiling.
- Build a synthetic mixture-of-manifolds benchmark to separate those regimes cleanly.
- Train several SAE variants on Llama3.1-8B activations from 500M Pile tokens.
- Read out geometry with restricted R^2, receptive fields, Ising couplings, and feature-group discovery.
Evidence: the synthetic benchmark is useful because it gives the theory a controlled test, but the stronger empirical claim comes from Llama3.1-8B. The paper uses variance-explained curves, feature similarity structure, and Ising-group recovery to argue that current SAEs often live in a dilution regime rather than a compact capture regime.
Why I care: this is the rare mechanisms paper that changes how I think about interpretability rather than just adding another probe. It says the object we should be tracking is not always a direction, and that is a more annoying but more honest claim.
Limitations/questions: the analysis is still centered on one model family and a curated set of continuous concepts. I would want to know whether the same geometric story survives across other models, other layers, and other tokenization regimes.
Connection to the tracked themes: large model mechanisms, interpretability, geometric state.
A Multistage Extraction Pipeline for Long Scanned Financial Documents: An Empirical Study in Industrial KYC Workflows
Authors: Yuxuan Han, Yuanxing Zhang, Yushuo Wang, Yichao Jin, Kenneth Zhu Ke, Jingyuan Zhao.
Institutions: OCBC, Singapore.
Date/Venue: April 29, 2026, arXiv preprint.
Links: arXiv | HTML
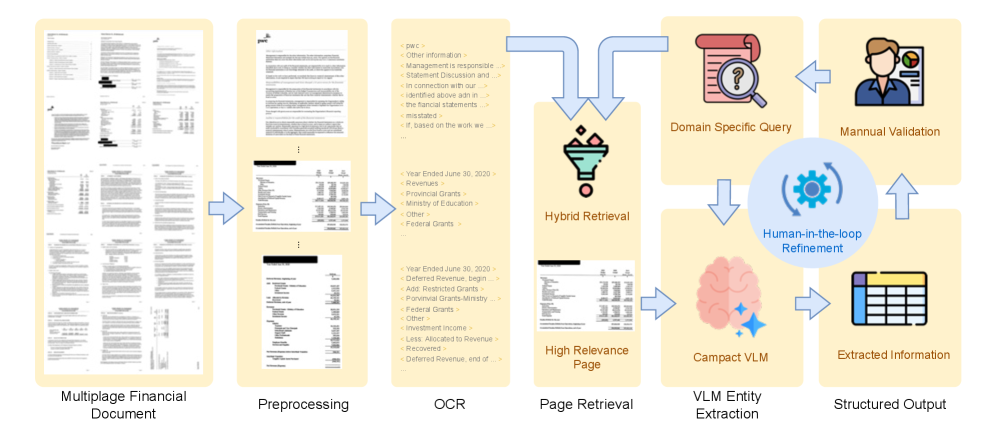
This is the most practical paper in the set. It says that for long scanned KYC documents, the right move is not to throw the whole PDF at a VLM and hope for the best. First make the document legible, then localize the relevant pages, then ask a compact model to extract fields.
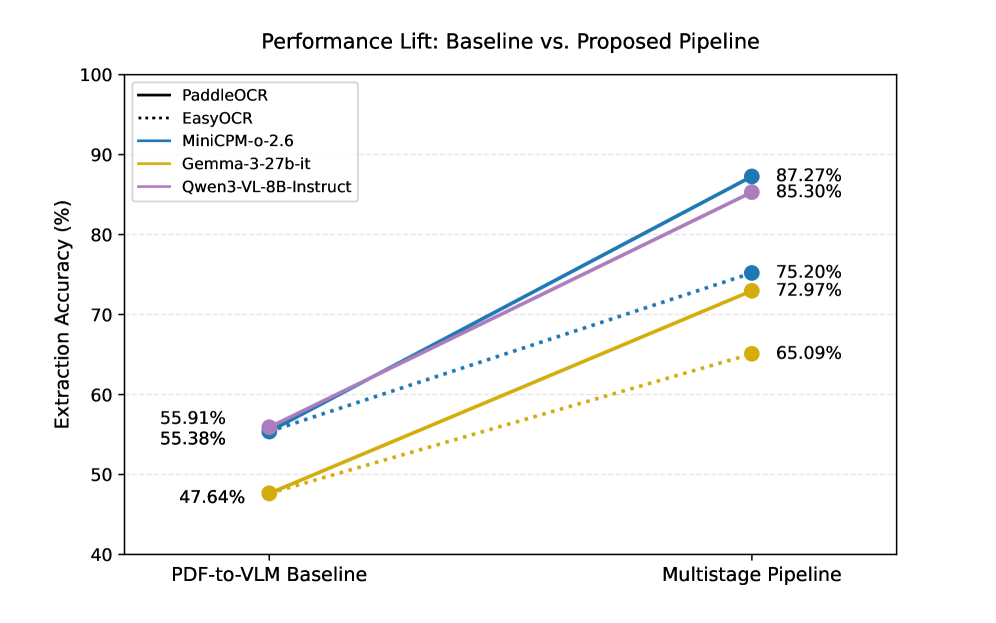
The performance figure shows the basic win: the multistage pipeline lifts accuracy across settings instead of only helping one corner case. That matters because real KYC documents vary a lot in page count, language, and visual noise. The caveat is that a broad lift does not automatically mean the system is robust under new document templates.
The latency plot is the honest part. The staged pipeline is not free, but the extra work is visible and bounded, which is better than pretending the extraction happened in one magical step. I think that tradeoff is the right one for production systems: pay some latency to avoid silent extraction failures.
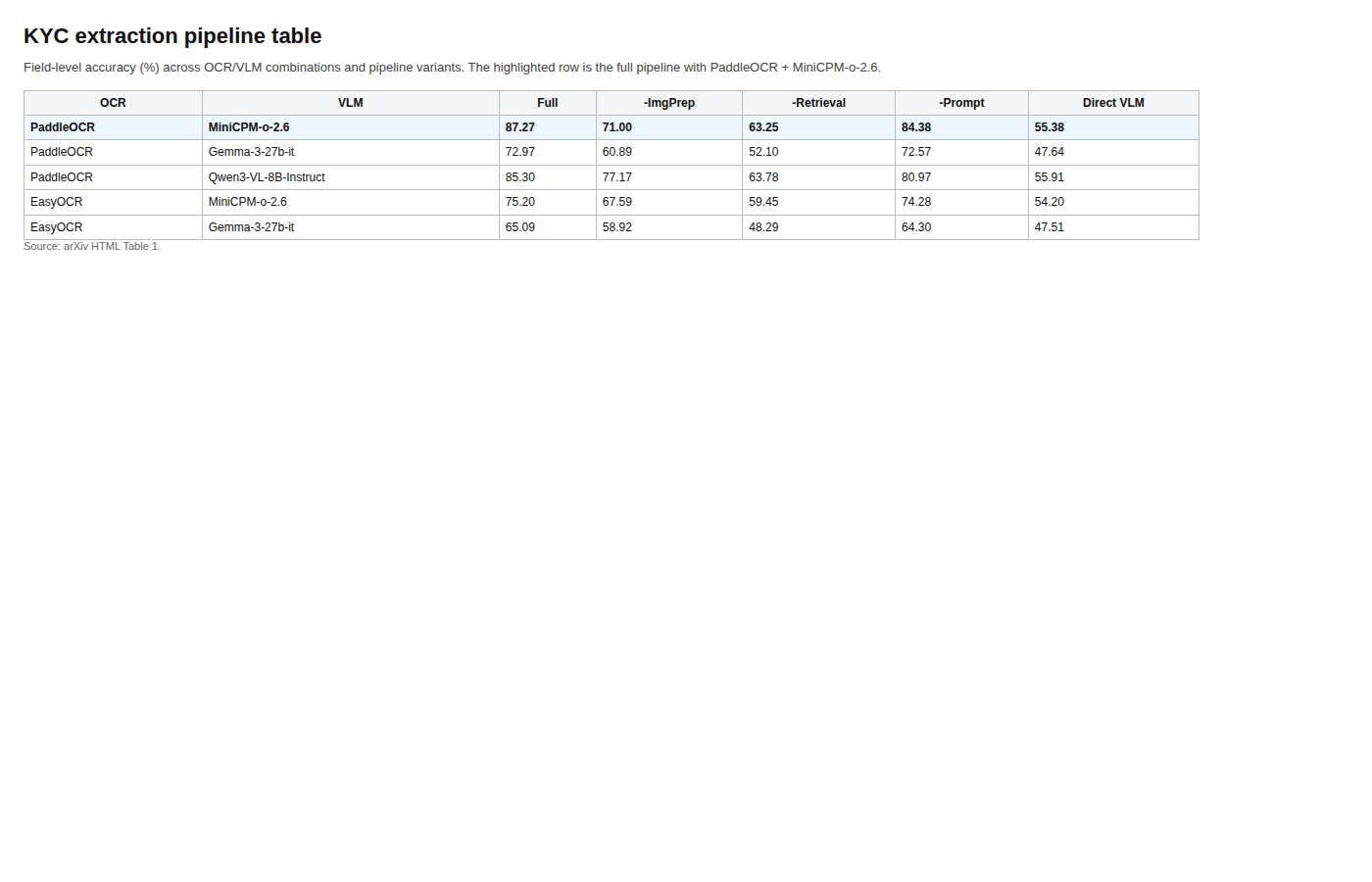
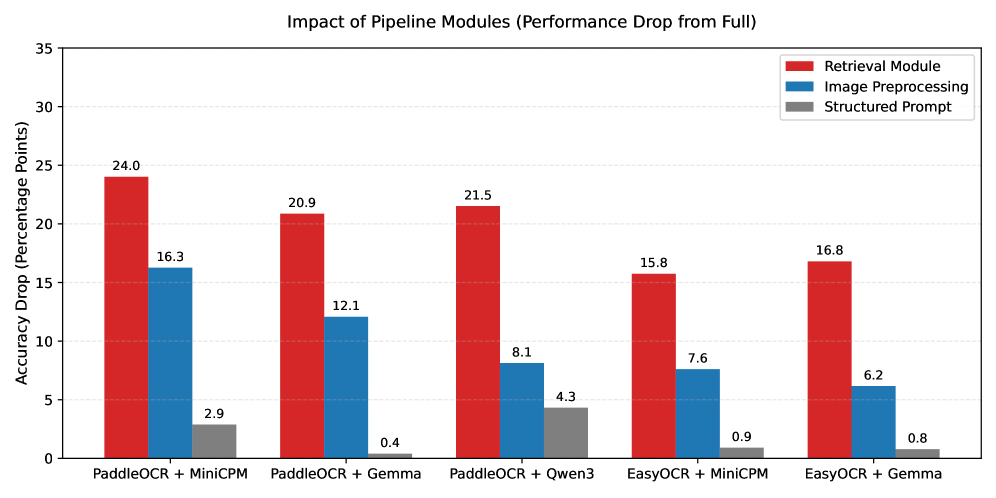
The table gives the concrete number I would cite. The full pipeline with PaddleOCR and MiniCPM-o-2.6 reaches 87.27% field-level accuracy, versus 55.38% for the direct PDF-to-VLM baseline, and the paper reports up to a 31.9 point improvement overall. The ablation pattern is also clear: page-level retrieval is the biggest lever, especially on financial statements and non-English pages.
Quick idea: document intelligence works better when page localization is separated from reasoning.
Why it matters: long scanned financial documents are noisy, multilingual, and sparse in useful fields. If the model has to do OCR, search, and extraction all at once, it is easy to get a fluent but wrong answer.
Method walkthrough:
- Preprocess pages with segmentation, deskewing, and renormalization.
- Run multilingual OCR to turn the scans into layout-aware text.
- Retrieve the pages most likely to contain target fields.
- Send only those pages through a compact VLM for structured extraction.
Evidence: the paper evaluates on 120 production KYC documents, roughly 3000 scanned pages in total. The table and ablation figures show that retrieval, not just OCR, is the main source of the gain. The latency figure makes the tradeoff explicit instead of hiding it behind a single accuracy number.
Why I care: this is the kind of document paper that actually feels deployable. It does not ask for a giant multimodal model to memorize the whole workflow. It asks the workflow to make the evidence easier to see.
Limitations/questions: the data comes from one industrial KYC setting, so the transfer story is still narrow. I would want to test the same pipeline on other long-form scanned domains, especially ones with even messier layouts or weaker OCR.
Connection to the tracked themes: document intelligence, evidence localization, staged agent pipelines.
Reading Priority and Next Questions
If I rank this issue by how much it changes my head, HERMES++ and LaST-R1 come first, then the SAE paper, then the KYC pipeline. The first two are both trying to make latent structure into something the model can act on. The second two show what happens when that structure becomes interpretable or extractable rather than just implicit.
The next questions I would chase are simple:
- Can world-query style bridges expose uncertainty instead of only better performance?
- Can latent reasoning be audited the way we audit outputs?
- Can manifold groups become stable steering handles instead of post-hoc curiosities?
- Can document pipelines stay robust when the OCR layer gets worse, not better?
The more general pattern is still the same: when the middle layer is explicit, the system gets easier to train, easier to inspect, and less likely to bluff its way through the hard part.