为什么智能体需要显式中间层
Published:
TL;DR:这期我盯着同一件事。真正有意思的工作,不是把端到端系统再堆大一点,而是把中间层做显式:BEV token、latent CoT、概念流形、检索页。模型一旦有了可检查的中间表示,几何、控制和证据就都更容易对齐。
我也刻意避开了前几期已经写很多的那条线。前面几期一直在看可核验状态、可回放工作区和闭环反馈,这一期我更想看另一种东西: 中间层本身是不是被认真建模了,能不能被训练、被检索、被解释,而不是只在最后输出里偷偷出现。
论文细读笔记
Hermes++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
作者:Xin Zhou, Dingkang Liang, Xiwu Chen, Feiyang Tan, Dingyuan Zhang, Hengshuang Zhao, Xiang Bai。
机构:华中科技大学、Mach Drive、香港大学。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | 代码
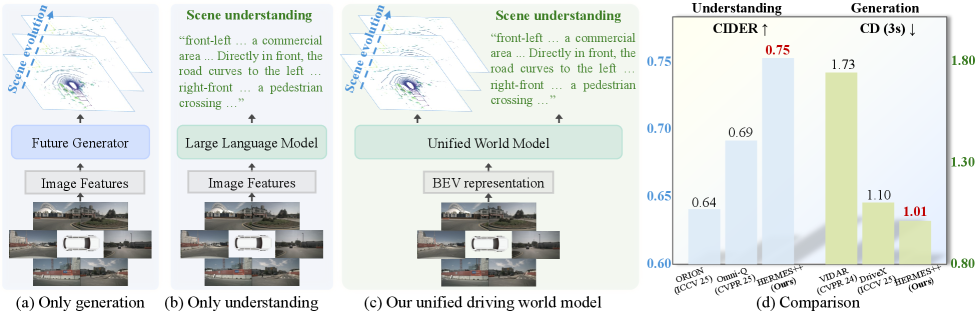
这篇最直接的主张是,驾驶世界模型不该一边做场景理解,一边另起一个模型做未来预测。Hermes++把两件事放进同一个框架里,让几何中间层保持可见。它的限制也很清楚,还是一个驾驶域里的世界模型,不是通用智能体框架。
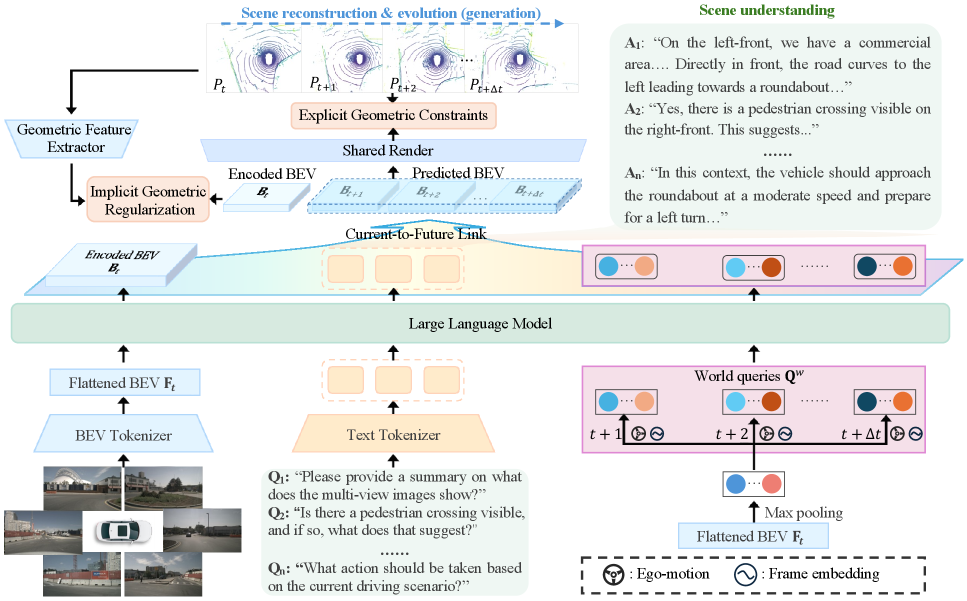
这张图是方法的核心。多视角输入先被压成 BEV token,再和指令、world query 一起送进 LLM,Current-to-Future Link 再把语义上下文传到未来几何预测里。我的理解是,它想阻止模型把几何当成副作用,而是把几何变成显式状态。
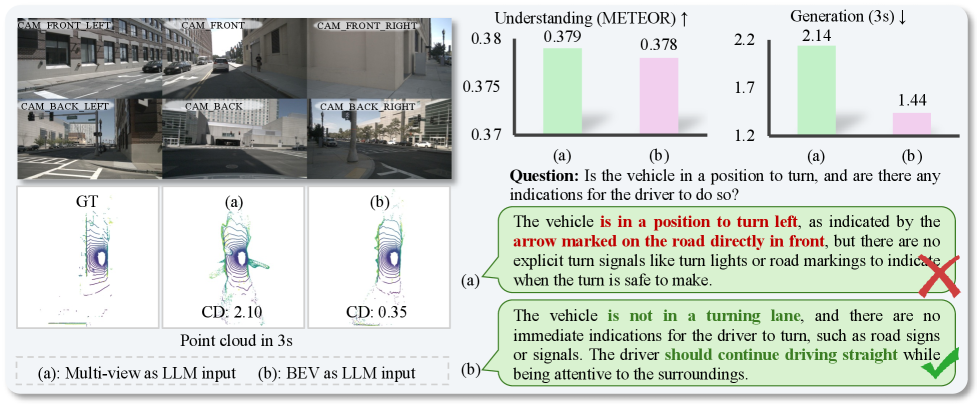
这张图把架构选择讲得更直白。多视角基线在文本指标上看起来不差,但空间结构会塌掉,而 BEV 路径更容易把场景保持成一个能继续预测的几何对象。对 world model 来说,几何不是装饰,是主体。
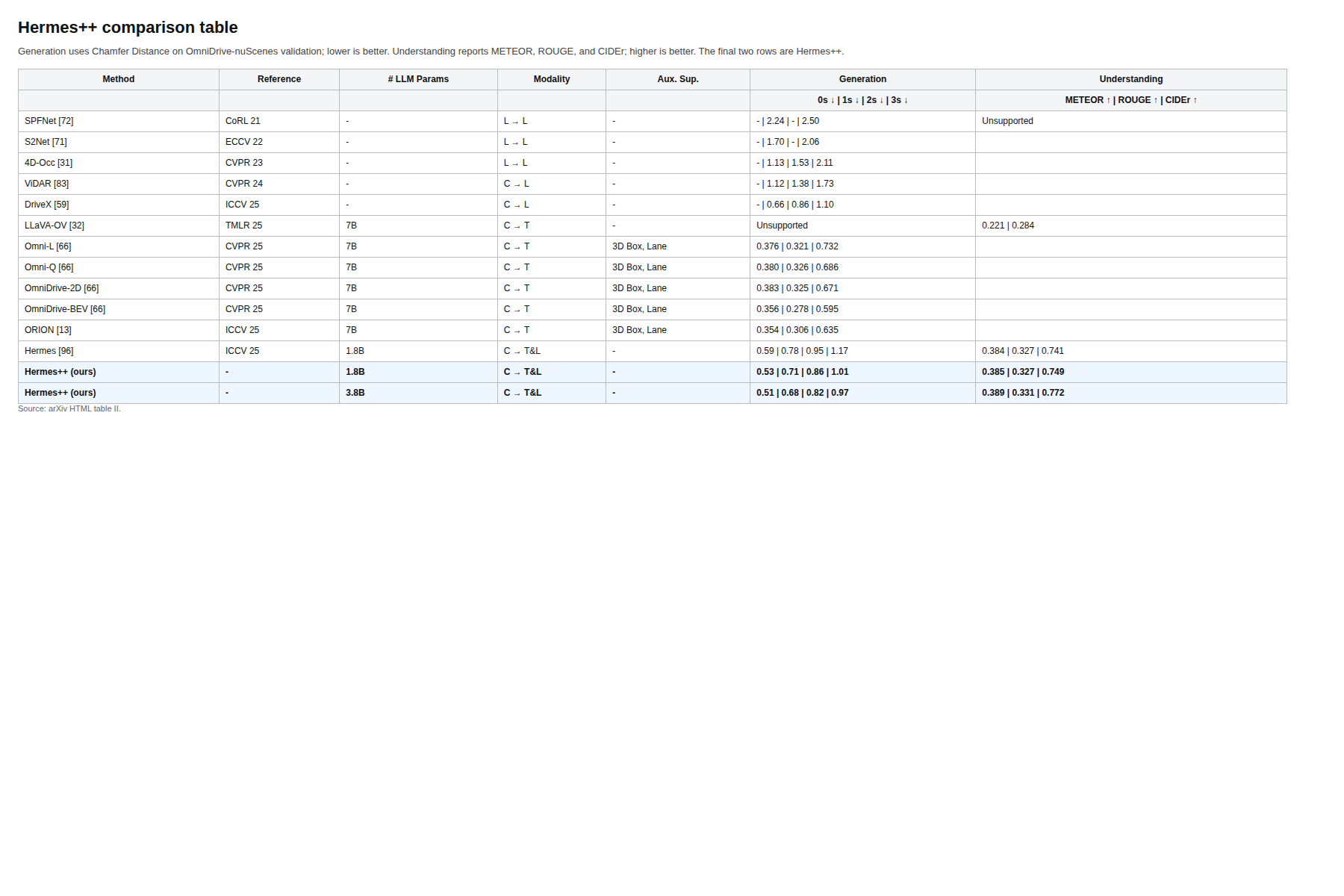
数字落在这里。Hermes++ 3.8B 在 0-3s 未来预测上给出 0.51/0.68/0.82/0.97 Chamfer distance,在理解侧给出 0.389 METEOR、0.331 ROUGE、0.772 CIDEr,比早期 Hermes 版本在生成侧明显更强,在语言侧也保持了竞争力。需要谨慎的地方是,这些还是驾驶基准,说明它在这个域里做得不错,但不能自动推出通用规划能力。
一句话核心:Hermes++ 想把当前场景语义和未来几何放到同一个世界模型里。
为什么重要:很多驾驶系统还是把理解和生成拆开做。这样做的代价是,模型很难把“现在看见什么”和“未来会变成什么”真正连起来。
方法拆解:
- 把多视角 BEV 特征压成 LLM 能处理的 token。
- 用 world query 把理解分支的语义上下文传给生成分支。
- 用 Current-to-Future Link 把当前状态和未来几何直接连起来。
- 用 Joint Geometric Optimization 约束内部表示别偏离几何先验。
关键证据:比较表给出最直接的结果,图 4 说明 BEV 比多视角输入更容易维持结构一致性,图 5 则显示几何正则真的在改内部表示,不只是修一修输出。论文还和专门做理解或专门做生成的模型做了比较,所以它的 tradeoff 不是藏起来的。
我的判断:我一直在找这种把中间状态做实的工作。Hermes++ 有价值的地方,不是它多像一个大一统系统,而是它明确告诉你,未来预测在语义和几何之间要有一个可检查的桥。
局限/问题:它还是很强的驾驶域绑定。真正想追问的是,在更脏、更复杂、域偏移更大的场景里,BEV 和 world query 这套桥还能不能稳住。
和本期主题的关系:世界模型、显式状态、几何感知智能体。
LaST-R1: Reinforcing Action via Adaptive Physical Latent Reasoning for VLA Models
作者:Hao Chen, Jiaming Liu, Zhonghao Yan, Nuowei Han, Renrui Zhang, Chenyang Gu, Jialin Gao, Ziyu Guo, Siyuan Qian, Yinxi Wang, Peng Jia, Chi-Wing Fu, Shanghang Zhang, Pheng-Ann Heng。
机构:香港中文大学、北京大学、Simplexity Robotics。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | 项目页
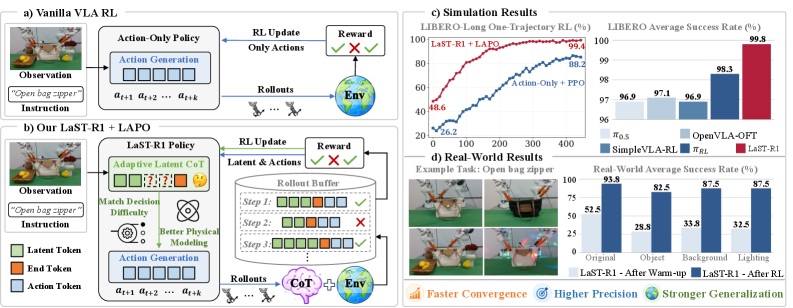
LaST-R1 不是单纯再做一个 VLA 后训练。它的关键是把 latent 物理推理也纳入 RL 优化,而不是只优化最后的 action。换句话说,它把 reasoning 变成了控制的一部分。
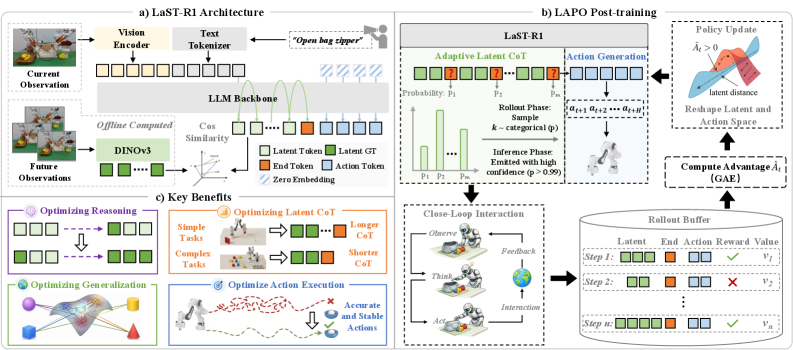
方法图把这件事讲得很清楚。视觉基础模型先给出物理上有意义的 latent target,latent CoT 在 action 之前运行,RL 阶段再把这两条通道一起更新。里面那个 hybrid attention mask 也很关键,推理是顺序的,动作 chunk 可以并行。

我最信这张学习曲线。LIBERO 上,LAPO 版本比只优化 action 的 PPO baseline 收敛更快,这支持了 latent 通道不是“多加几个 token”而已。需要提醒的是,学习曲线有时会被已经接近饱和的 benchmark 美化,所以还要看别的证据。
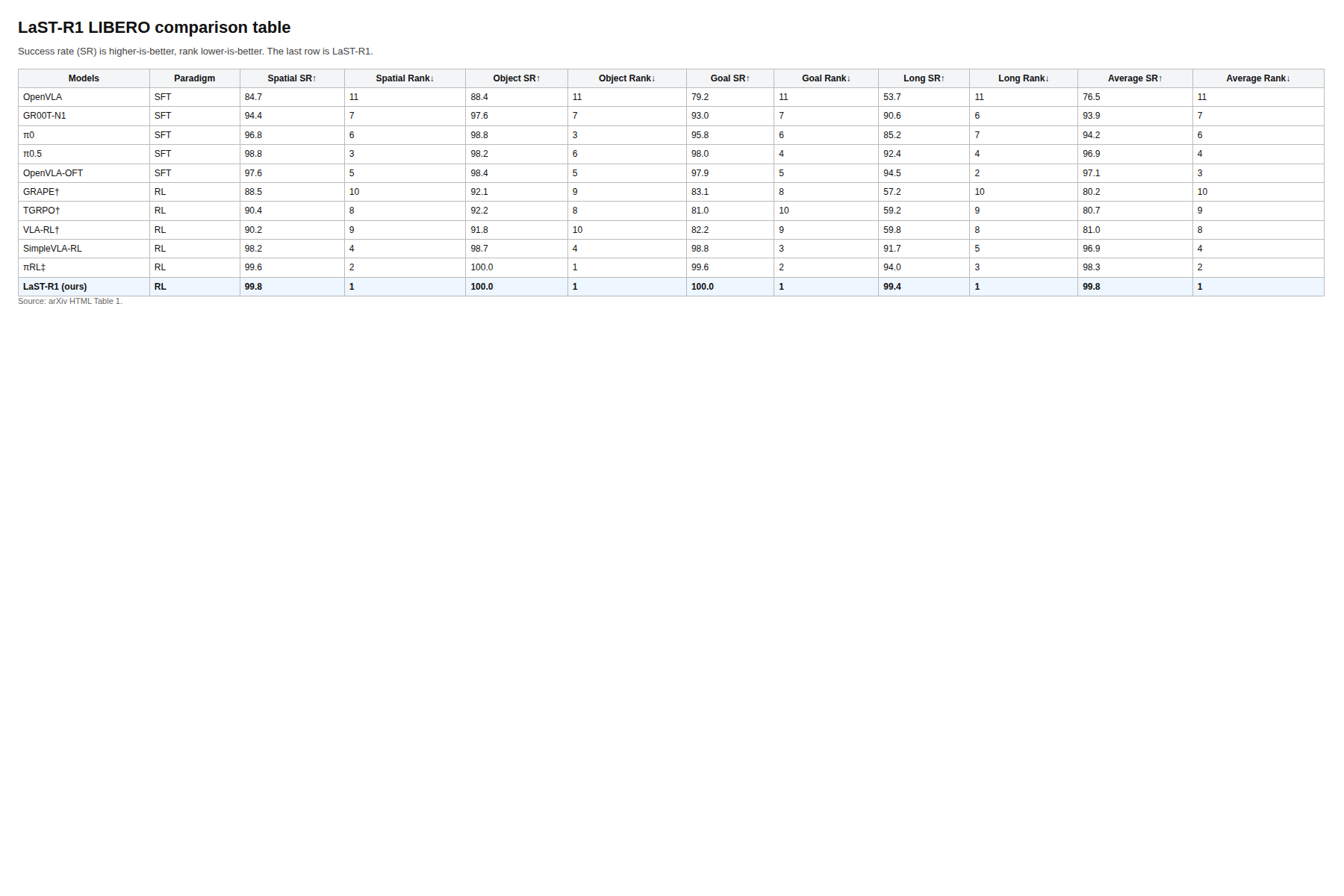
表格给出的数字更狠。LaST-R1 在 LIBERO 上的平均成功率到 99.8,四个子任务里空间是 99.8,对象和目标都是 100,长程任务 99.4。论文里的真实环境表也显示 RL 之后提升很明显,最夸张能比 warm-up policy 高出 44%。但这里还是要克制一点,这些任务毕竟是有限的机械臂操作,不要把分数直接等同于通用智能。
一句话核心:LaST-R1 直接优化 latent 物理推理和 action,并让 latent 推理长度自己适配任务难度。
为什么重要:很多 VLA 要么用语言推理换来延迟,要么做 RL 时只管动作,不管推理路径。这篇是在把推理路径拉回 policy 本身。
方法拆解:
- 先用少量监督 warm-up 把 VLA 起步。
- 用 LAPO 同时优化 latent reasoning 和 action generation。
- 让 adaptive latent CoT 根据任务复杂度自动伸缩推理长度。
- 用 hybrid attention mask 把推理和动作阶段分开,保证推理是顺序的,动作是高效的。
关键证据:LIBERO 的比较表给出最直观的提升,真实任务表显示在未见物体、背景变化和光照变化下也能涨。学习曲线说明它不是只在最终分数上占便宜,而是确实更快进入有效策略区间。
我的判断:这类工作我会优先看,因为它把 intermediate reasoning 当成可优化对象,而不是 prompt 里的一段文字。它比“最后得分高一点”更接近一个真正会行动的智能体。
局限/问题:目前仍然是 LIBERO 加少量真实任务的范围。我想知道自适应 latent 长度在更脏、更长、更开放的任务里会不会稳定,还是只在这种干净场景里成立。
和本期主题的关系:agentic training、latent world model、显式控制中间层。
Do Sparse Autoencoders Capture Concept Manifolds?
作者:Usha Bhalla, Thomas Fel, Can Rager, Sheridan Feucht, Tal Haklay, Daniel Wurgaft, Siddharth Boppana, Matthew Kowal, Vasudev Shyam, Owen Lewis, Thomas McGrath, Jack Merullo, Atticus Geiger, Ekdeep Singh Lubana。
机构:Harvard University、Northeastern University、Technion IIT、Stanford University。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | 代码
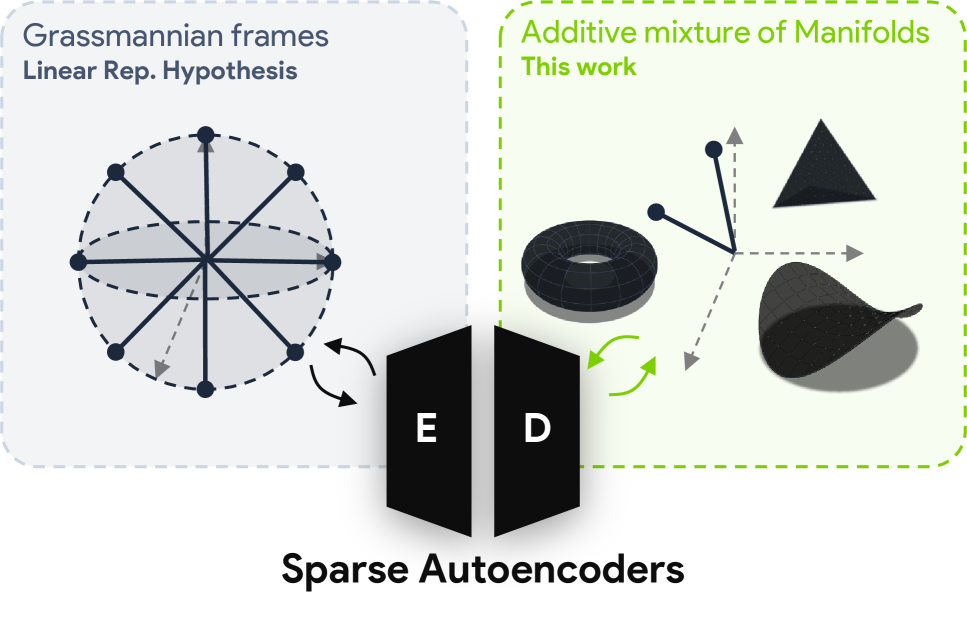
这篇比前两篇更理论,但它提出的问题很实在:概念不一定是单一方向,也可能是流形。论文最有用的地方,是它没有停在“也许是流形”这一步,而是继续问,SAE 到底什么时候真的抓到了这个流形。
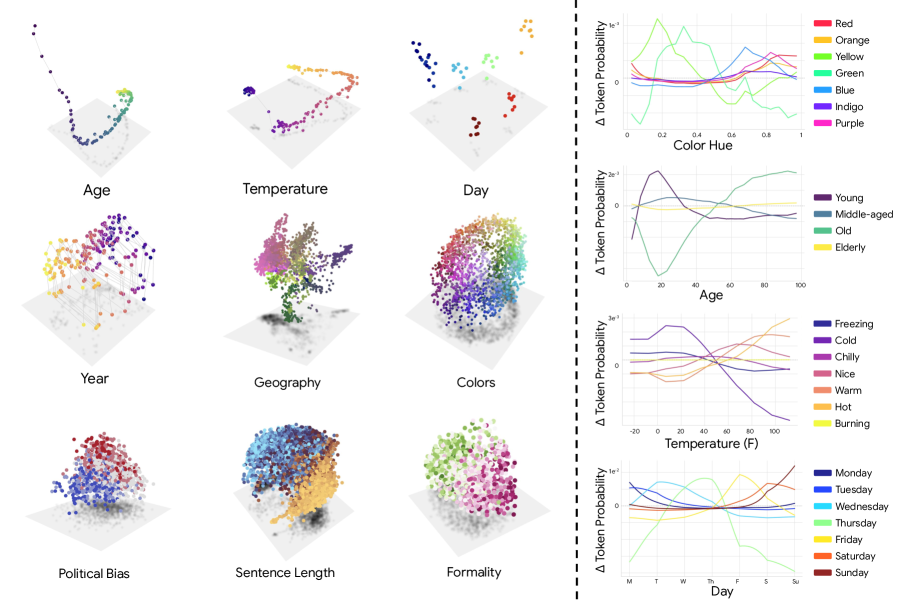
这张图是直觉入口。年龄、温度、日期、颜色这些连续概念,在 PCA 空间里都显得很平滑,概念之间的 steering 也会带来平滑变化。它支持的是一种更连续的几何图景,而不是“一个概念对应一个方向”的老假设。
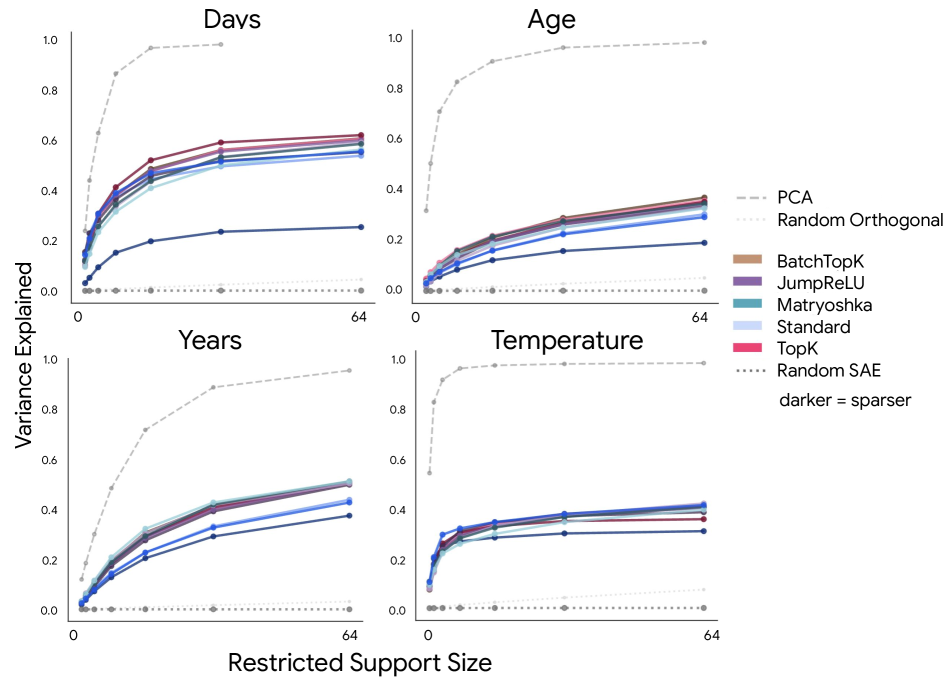
这张图是我最在意的结果。随着受限特征数增加,解释方差会上升,但很快在远超流形本身维度的位置就平台化。作者把这叫做 dilution:几何没有被紧凑打包,而是被很多局部特征碎片化地铺开了。
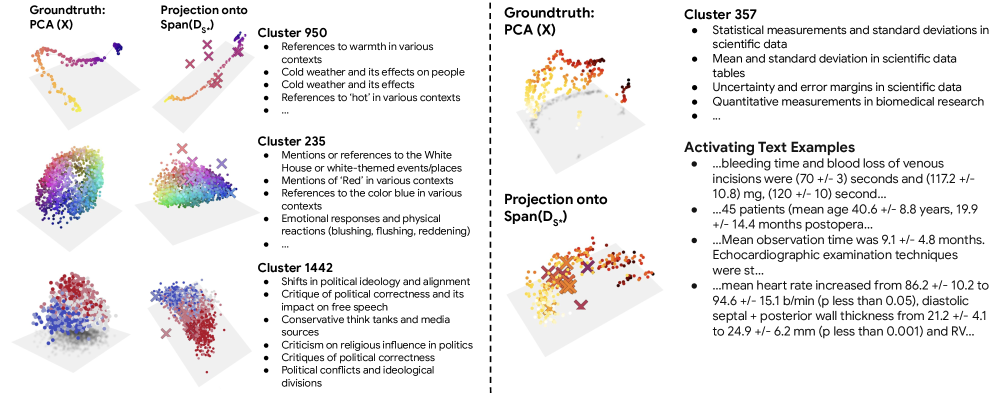
这张图把论文从“诊断”往前推了一步。基于 Ising 的分组不仅找回了 temperature、colors、political bias 这些已知流形,还冒出了一个和科学文本里的 epistemic uncertainty 相关的新流形。需要小心的是,这还是后验发现管线,更多是提示线索,不是因果保证。
一句话核心:SAE 可能捕捉到概念流形,但常常是以一种碎片化的方式在做事,既有 global subspace,也有 local tiling。
为什么重要:很多解释性工作默认一个概念就是一条方向。如果真实对象是流形,那很多 steering 和 probing 其实只碰到了一半问题。
方法拆解:
- 先把 manifold capture 分成两种模式,global subspace capture 和 local tiling。
- 用 synthetic manifold mixture benchmark 把这两种模式分开验证。
- 在 Llama3.1-8B 的 activation 上训练多种 SAE,规模是 500M tokens。
- 用 restricted R^2、receptive field、Ising coupling 和 feature-group discovery 读回几何结构。
关键证据:合成 benchmark 给了理论一个可控检验,而 Llama3.1-8B 上的曲线、特征相似结构和 Ising 分组则说明当前 SAE 往往更接近 dilution,而不是紧凑捕获。这个结论不花哨,但挺重要。
我的判断:这是少见的机制论文,它改变的是我怎么看 interpretability,而不只是多加一个 probe。它提醒我们,解释对象不一定是方向,也可能是几何对象本身。
局限/问题:分析还是集中在单一模型家族和一组挑选过的连续概念上。我会继续追问它在别的模型、别的层、别的 tokenizer 下是否还能成立。
和本期主题的关系:大模型机理、解释性、几何化中间表示。
A Multistage Extraction Pipeline for Long Scanned Financial Documents: An Empirical Study in Industrial KYC Workflows
作者:Yuxuan Han, Yuanxing Zhang, Yushuo Wang, Yichao Jin, Kenneth Zhu Ke, Jingyuan Zhao。
机构:OCBC, Singapore。
时间/来源:2026-04-29,arXiv 预印本。
链接:arXiv | HTML
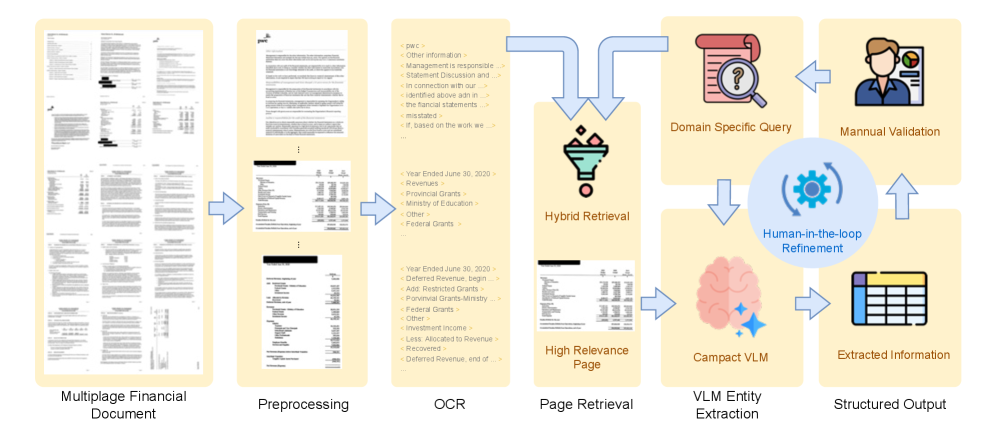
这是这一组里最落地的一篇。它的意思很直接:长扫描版 KYC 文档不要直接丢给 VLM 硬抽,先把页面变清楚,再做 OCR,再检索相关页,最后才让一个紧凑的 VLM 做结构化提取。
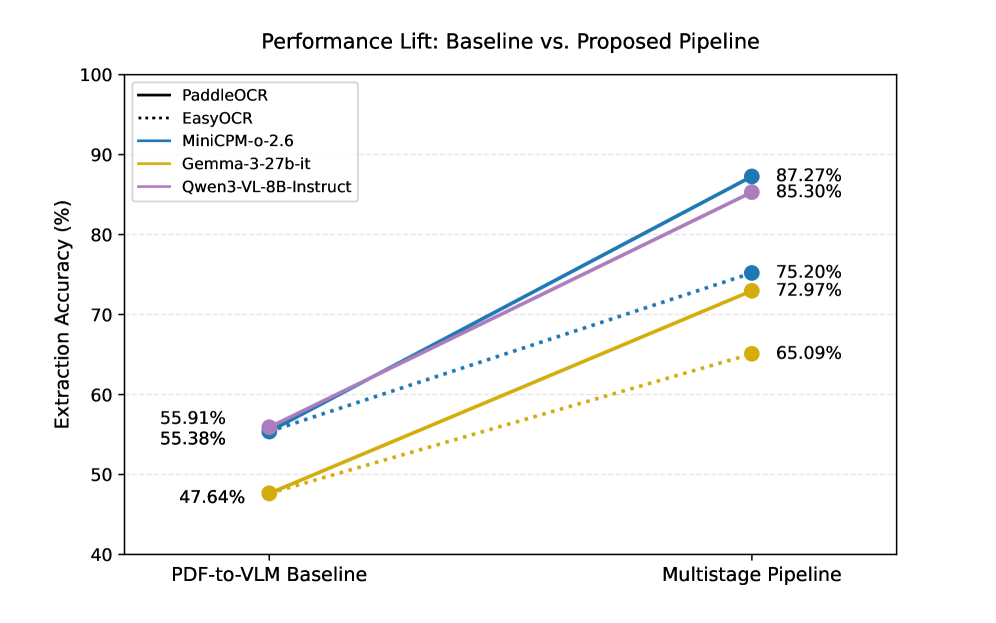
性能图说明了最基本的收益。多阶段 pipeline 在不同设置下都能把准确率往上推,而不是只在某一个 corner case 上好看。需要注意的是,广泛提升不等于对新模板就一定稳,真实文档的分布漂移还是会咬人。
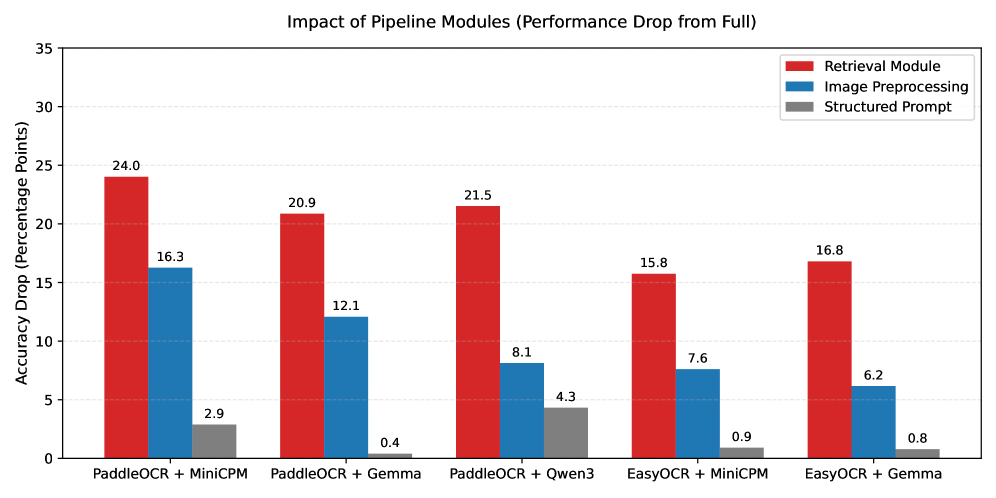
这张图比较诚实。分阶段 pipeline 不会免费,延迟确实上去了,但增加的成本是可见且可控的,比假装一个大模型能一把梭更适合生产系统。对于文档智能来说,这种权衡比一个单点高分更值得看。
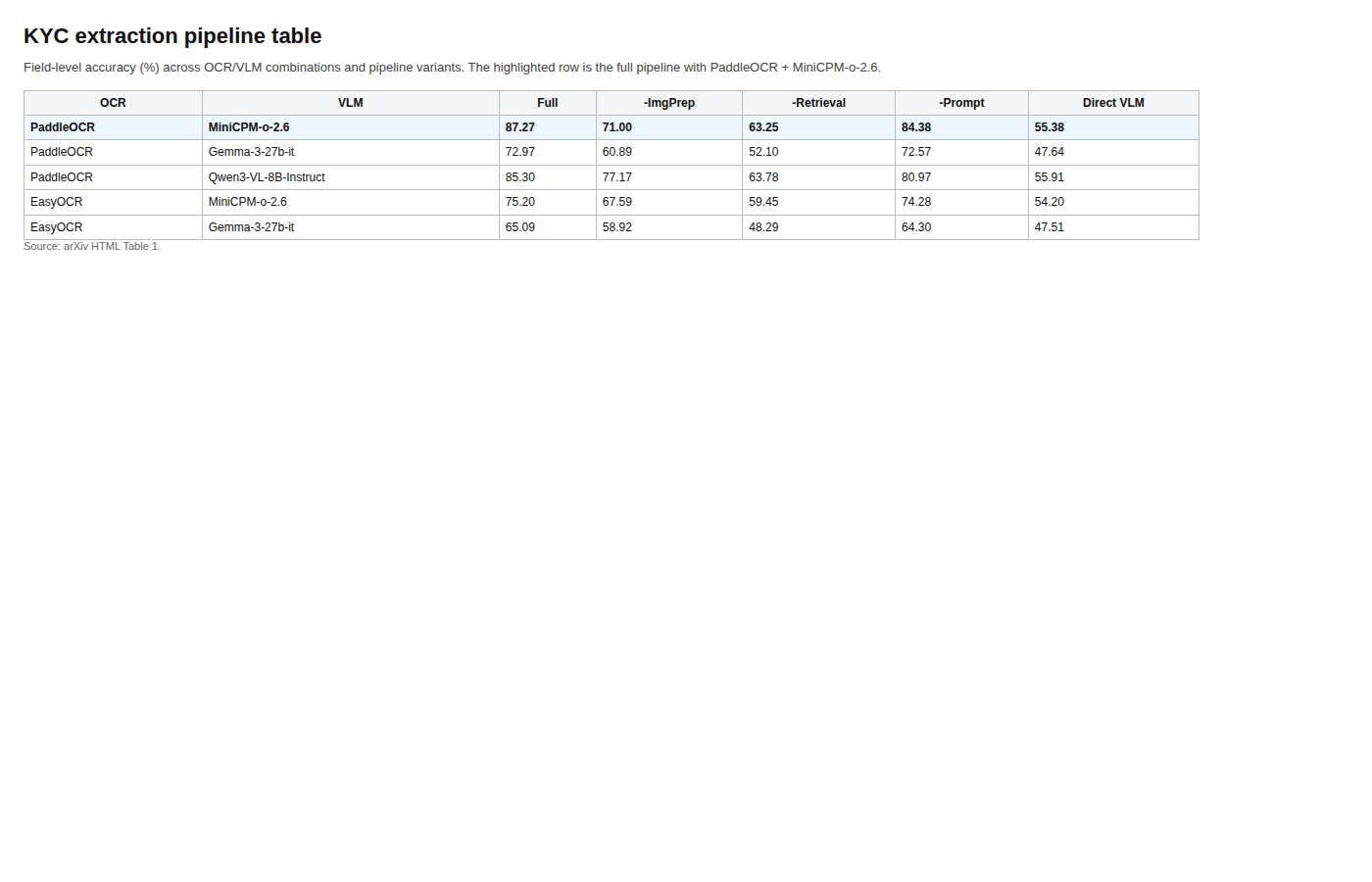
真正能写进笔记里的数字在这张表里。PaddleOCR + MiniCPM-o-2.6 的完整 pipeline 到了 87.27% 的 field-level accuracy,而直接 PDF-to-VLM baseline 只有 55.38%,整体提升最高达到 31.9 个百分点。消融也很清楚:page-level retrieval 是最大的杠杆,尤其对财务报表和非英文页面最重要。
一句话核心:长扫描金融文档的正确做法,是把页面定位和推理拆开,而不是让一个模型同时干完所有事。
为什么重要:KYC 文档又长、又脏、又多语种,真正的问题往往不是“模型会不会答”,而是“模型能不能先把证据找对”。如果先找错页,后面答得再流畅也没用。
方法拆解:
- 先做 page segmentation、deskew 和 renormalization。
- 再用多语种 OCR 把扫描件变成带布局信息的文本。
- 接着做 hybrid page-level retrieval,把相关页面挑出来。
- 最后把这些页面交给 compact VLM 做结构化抽取。
关键证据:作者在 120 份生产级 KYC 文档上评估,合计大约 3000 页。表格和消融图都说明,真正拉开差距的不是“更会说”,而是 retrieval 和 OCR 把证据边界找对了。延迟图也把代价摆在桌面上,没有装作这是零成本方案。
我的判断:这是我最愿意往产品里想的一篇 document intelligence 工作。它不要求一个巨型多模态模型记住全部流程,而是先把文档结构本身变得可读。
局限/问题:数据只来自一个 OCBC 的 KYC 工作流,所以外推性还不够宽。我会想看它在别的长扫描场景里会不会继续成立,尤其是版式更乱、OCR 更差的文档。
和本期主题的关系:文档智能、证据定位、分阶段智能体管线。
阅读优先级和下期问题
如果按“改观程度”排,我会先看 Hermes++ 和 LaST-R1,再看 SAE,最后是 KYC pipeline。前两篇都在做同一件事,只是一个在驾驶世界模型里,一个在机械臂 VLA 里: 让中间态变成显式状态。后两篇则告诉我们,这些中间态可以被解释,也可以被检索。
下一轮我会继续追几个问题:
- world query 这类桥接机制,能不能把不确定性也带出来,而不是只带来更高分?
- latent reasoning 能不能像输出一样被审计?
- 概念流形能不能变成稳定的 steering handle,而不只是事后分析结果?
- 文档 pipeline 在 OCR 变差、模板变乱的时候,能不能还站得住?
更一般地说,我这几期一直在看同一个模式: 当中间层被显式化之后,系统通常更容易训练、更容易检查,也更不容易在难题上含糊过去。