给科学研究智能体更好的结构化接口
Published:
TL;DR:这期我看的不是“智能体又多会做题了”,而是科学研究智能体到底需要什么接口。四篇论文分别把方法演化图谱、领域 foundation model 调用、复杂文献发现、科学可视化 workflow 做成了更明确的结构。我的判断是:研究智能体真正缺的往往不是更长上下文,而是能被查询、调用、验证和回放的中间层。
本期我在看什么
前几期已经写了很多可核验状态、可回放工作区和 data-agent 的硬证据。这一期我想把视角往上挪一层:如果智能体要参与研究,它不能只靠浏览器、搜索框和长上下文。它需要知道方法之间为什么演化,需要能调用专门处理时间序列或表格的模型,需要能追踪全文里的细粒度证据,也需要在可视化工作流中检查中间状态。
所以这期的共同问题是“接口太薄”。引用图只告诉我们论文之间有边,不告诉我们一个方法解决了另一个方法的哪个瓶颈;语言智能体可以解释科学任务,但不一定适合直接计算非语言数据;文献搜索智能体能找到貌似相关的论文,却很难排除边界案例;可视化智能体要么靠 coding agent 花大量 token 试错,要么在 GUI 长程操作里失去一致性。
论文细读笔记
Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for AI Scientists
作者:Yujun Wu, Dongxu Zhang, Xinchen Li, Jinhang Xu, Yiling Duan, Yumou Liu, Jiabao Pan, Xuanhe Zhou, Jingxuan Wei, Siyuan Li, Jintao Chen, Conghui He, Cheng Tan。
机构:Shanghai Artificial Intelligence Laboratory;Peking University;Xi’an Jiaotong University;Zhejiang University;East China Normal University;Hunan University;Shanghai Jiao Tong University;Shanghai University;University of Chinese Academy of Sciences。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML
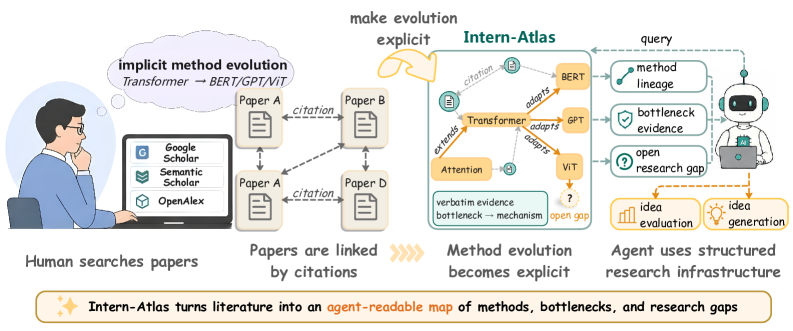
这张总览图讲清了论文的核心:Intern-Atlas 把论文、方法、stub 节点、带类型的引用关系和证据片段组织成一个智能体可查询的图。它不是要替代读论文,而是把“方法如何演化”这件事从研究者脑内的隐性理解变成显性对象。需要谨慎的是,这个图仍然依赖 LLM 抽取,所以 validator 和后续 benchmark 的可信度非常关键。

方法地形图说明它不是普通 citation graph。不同方法聚成若干研究大陆,Attention、BERT、GPT-3、CoT、Instruction Tuning、RLHF 等节点之间由带语义的演化边连接。这个图支持了论文的核心判断:研究智能体需要 method-level topology,而不只是 paper-level metadata。不过它也是一个可读性优先的展示图,真实图里绝大多数节点和边都被隐藏了。
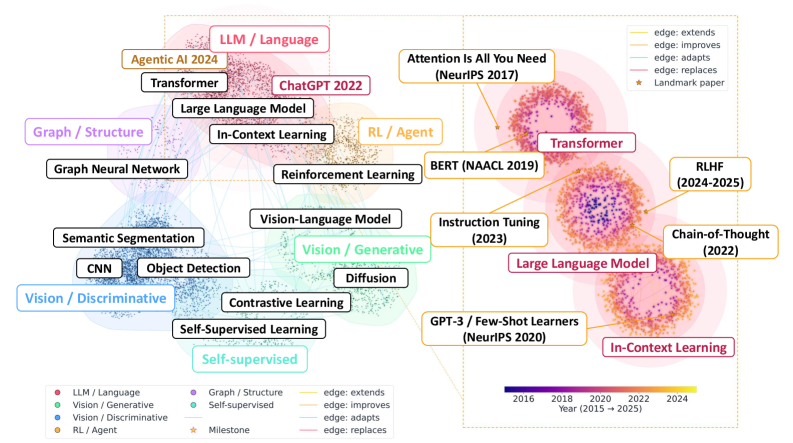
质量评估图是我更愿意相信这篇的原因。作者用 survey-derived method-evolution graphs 做对照,报告 node match ratio 91.0%、edge reachable ratio 89.7%、path semantic correctness 92.0%。SGT-MCTS 在演化链恢复上也明显强于 beam search 和 random walk,说明这不是只靠一个漂亮可视化在讲故事。
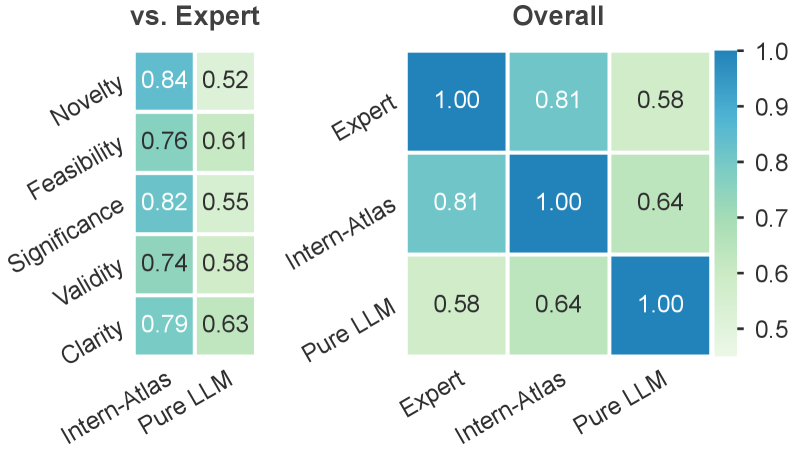
这张图看的是下游用途:图谱能不能帮助 idea evaluation 和 idea generation。它的价值在于,论文没有停在“我们构了一个大图”,而是继续问这个图能否支撑研究判断。我的保留意见也在这里:idea 质量很难自动评估,这些结果说明图谱有用,但不能证明它可以单独替代研究品味。
一句话核心:Intern-Atlas 把 AI 方法之间的 extends、improves、adapts、replaces 等关系做成可查询的演化图,给 AI scientist agent 一个更结构化的研究记忆。
为什么重要:现在的科学检索基础设施仍然以文档为中心。引用边只能告诉智能体两篇论文有关系,不能告诉它一个方法解决了另一个方法的哪个瓶颈。研究智能体如果每次都要从叙述文本里临时推断方法谱系,就很容易把熟悉名词当成真正关系。
方法拆解:
- 从 1,030,314 篇 AI 论文出发,把论文、canonical methods、aliases 和 out-of-corpus stubs 解析成图节点。
- 把引用相关的方法关系分成七类:extends、improves、replaces、adapts、uses_component、compares、background,其中前四类构成强因果演化子图。
- 对 causal edge 抽取 bottleneck、mechanism、trade-off 和 confidence,并用 substring validator 检查证据片段是否真的出现在原文中。
- 在图上实现 lineage reconstruction、graph-grounded idea evaluation 和 gap-driven idea generation。
关键证据:图里包含 8,155 个 canonical methods、9,545 个 aliases 和 9,410,201 条 typed edges。评估 benchmark 来自 30 篇高影响力 survey,包含 2,268 个节点、1,462 条边和 133 条演化链。除了构图质量指标较高,SGT-MCTS 的 node recall、edge recall 和 chain alignment 也大幅超过 beam baseline。idea evaluation 中,top-tier、core conference、workshop、rejected papers 的 overall score 均值按预期从 8.48、7.83、6.85 降到 5.84。
我的判断:这篇和 Paper Radar 自己的需求很近。一个研究助理不该只记住 PDF、标题和标签,它应该知道哪些方法为了解决哪些瓶颈而出现,某个新 idea 站在演化链的哪个位置。
局限/问题:我不会把 LLM 构建的方法图当成真值。证据片段能降低风险,但 “improves” 和 “adapts” 这类关系仍然依赖语境。下一步我想看的是:领域专家能不能编辑、审计、版本化这个图,以及小众领域里的错误模式是否会和 LLM/CV 主流领域不同。
和本期主题的关系:data agents、研究记忆、自动科学发现、面向智能体的科学知识基础设施。
Heterogeneous Scientific Foundation Model Collaboration
作者:Zihao Li, Jiaru Zou, Feihao Fang, Xuying Ning, Mengting Ai, Tianxin Wei, Sirui Chen, Xiyuan Yang, Jingrui He。
机构:University of Illinois Urbana-Champaign。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | 项目页 | 代码
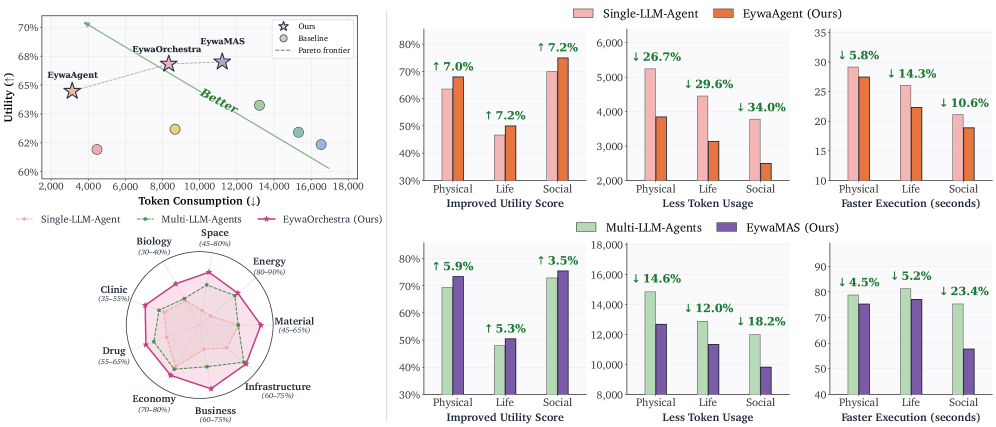
第一张图给了论文的实践主张:科学智能体不应该把所有任务都压进语言 token。Eywa 系列方法在物理、生命和社会科学任务上取得更高 utility,同时消耗更少 token。需要谨慎的是,utility 是跨异构任务聚合出来的,所以我更关注接口设计,而不是单个 headline score。
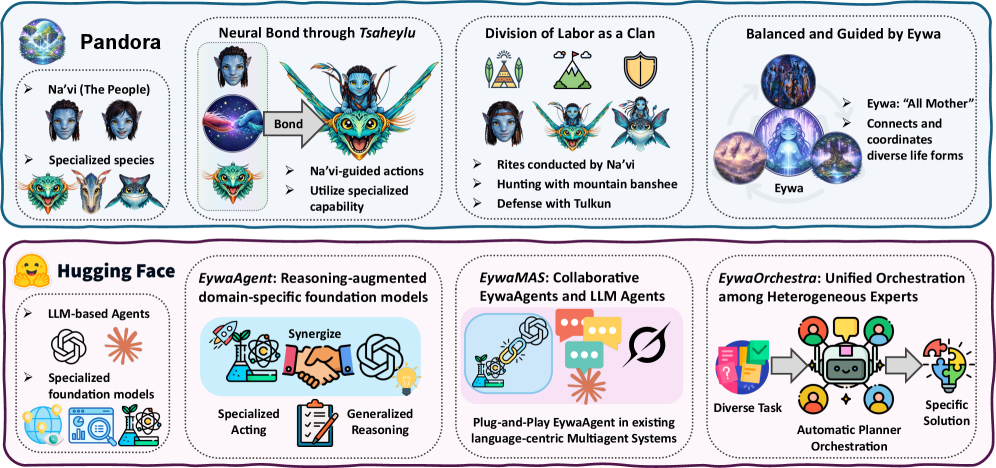
框架图很直观:语言模型负责高层解释和规划,领域 foundation model 负责时间序列、表格或其他科学模态上的专门预测。真正有价值的是双向接口:先把任务编译成结构化模型调用,再把专业模型输出适配回语言推理上下文。
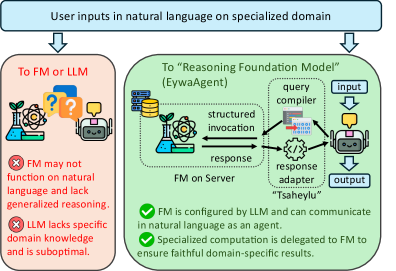
这张图放大了 EywaAgent。语言模型可以跳过 specialist,也可以通过定义好的输入输出 schema 调用它。它支持了论文的主要设计判断:智能体不必把所有科学计算都 verbalize 成自然语言推理,而应该把适合某类数据的部分交给专门模型。
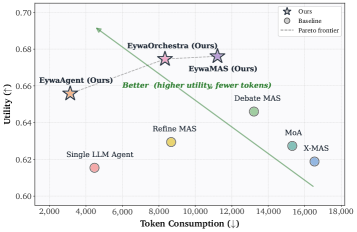
utility-token 图对产品化最有启发。Eywa 试图把系统推向“更好答案、更少 token”,而不是用更长推理轨迹换一点性能。我的保留意见是,当前实验依赖特定 foundation models 和 EywaBench,换成更多噪声数据或更复杂专业模型后,效率收益需要重新验证。
一句话核心:Eywa 给科学智能体一个结构化方式去调用领域 foundation model,而不是把语言当成所有科学数据的统一接口。
为什么重要:语言智能体很灵活,但很多科学数据并不天然适合用语言处理。时间序列模型、tabular model 或领域预测器可能有更合适的归纳偏置;LLM 则更适合规划、解释和协调。Eywa 的判断是,科学智能体应该组合这些能力,而不是把所有东西摊平成文本。
方法拆解:
- 定义 foundation model 与 language model 的接口,其中 query compiler 把任务状态转为结构化模型输入,response adapter 把输出转回可被 planner 使用的上下文。
- 用 MCP 风格 server 暴露每个 foundation model,让模型调用有明确 schema。
- 构建 EywaAgent:它有 invoke-or-skip 控制策略,可以纯语言推理,也可以调用 specialist,并把 specialist 输出写回状态。
- 扩展为 EywaMAS 和 EywaOrchestra,让多个语言智能体和领域模型智能体被组合,或由 conductor 动态选择配置。
关键证据:论文提出 EywaBench,覆盖 physical、life、social science,并进一步拆到 material、energy、space、biology、clinic、drug、economy、business、infrastructure 等子领域。实现中用 Chronos 处理时间序列,用 TabPFN 处理表格预测。在相同 backbone 下,EywaAgent 的 overall utility 从 0.6154 提高到 0.6558,平均 token 从 4,469 降到 3,137。EywaMAS 达到 0.6761 overall utility;EywaOrchestra 达到 0.6746,同时比固定多智能体设置消耗更少 latency 和 token。
我的判断:这篇对 data agent 很重要。一个好的研究智能体不应该为用更多 token 重新推导专业模型能直接算出的东西而自豪。通用推理和专门行动之间的接口,才是真正的设计面。
局限/问题:接口抽象比当前证据更强。EywaBench 有帮助,但选用的 foundation models 只是科学建模的一小部分。我更想看 specialist 模型错误、校准差或 out-of-distribution 时,语言智能体能不能判断应不应该信它。
和本期主题的关系:data agents、科学工作流智能体、模型上下文协议、异构工具调用。
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
作者:Lei Xiong, Kun Luo, Ziyi Xia, Wenbo Zhang, Jin-Ge Yao, Zheng Liu, Jingying Shao, Jianlyu Chen, Hongjin Qian, Xi Yang, Qian Yu, Hao Li, Chen Yue, Xiaan Du, Yuyang Wang, Yesheng Liu, Haiyu Xu, Zhicheng Dou。
机构:arXiv HTML 页面未注明。
时间/来源:2026-04-28,arXiv 预印本。
链接:arXiv | HTML | 代码

示例图让人有点不舒服,但这种不舒服是有价值的。这个 benchmark 不是让智能体根据接近标题的线索找名论文,而是要求它处理多跳科学搜索:关键证据可能藏在 appendix、ablation、citation context 或多个弱约束的交集里。这更接近真实文献工作的失败方式。
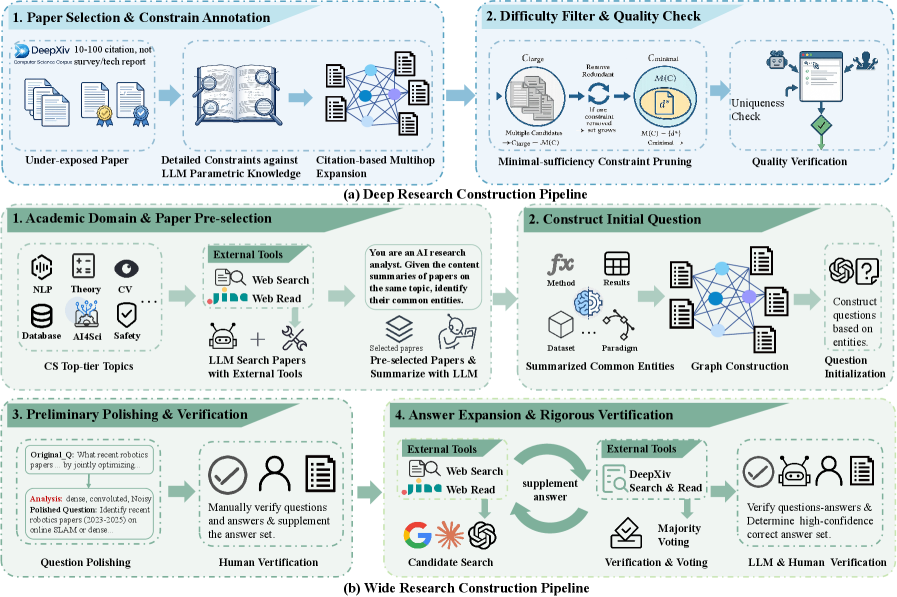
构建流程解释了任务为什么难。Deep Research 要么精确定位唯一论文,要么证明无答案;Wide Research 则要找全满足严格条件的论文集合。人工验证阶段很关键,因为如果没有 adversarial search 和 corpus-level audit,这类 benchmark 很容易被浅层关键词捷径污染。
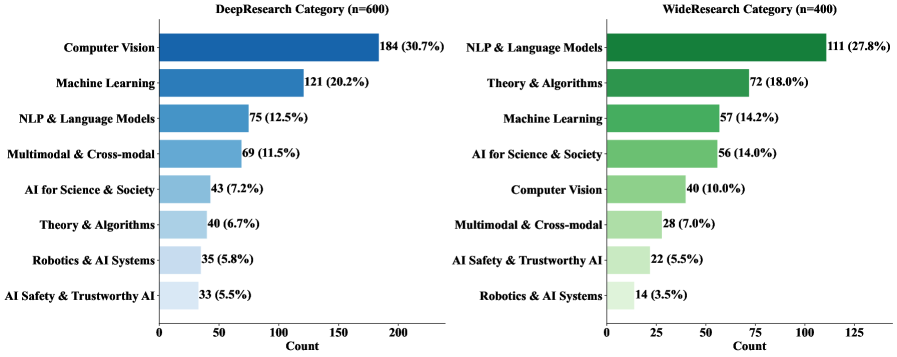
主题覆盖图说明任务不是单一子领域。对研究智能体来说这很重要,因为它可能学会某个领域的搜索套路,却不能迁移到另一个领域。限制也很清楚:benchmark 依赖 DeepXiv corpus 及其全文索引,开放 web 上的搜索噪声会更大。
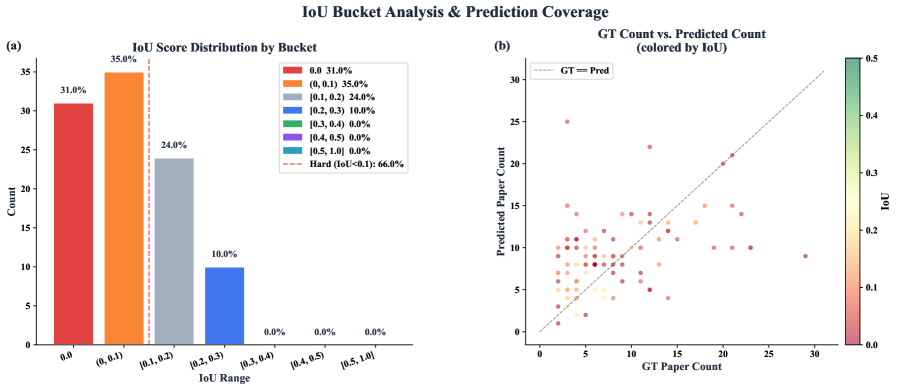
wide-search 图把核心失败暴露出来:智能体经常能找出一些貌似相关的论文,但很难恢复完整答案集合。对文献助理来说,这是严重问题。一个不完整列表看起来有帮助,却可能悄悄改变综述或 claim verification 的结论。
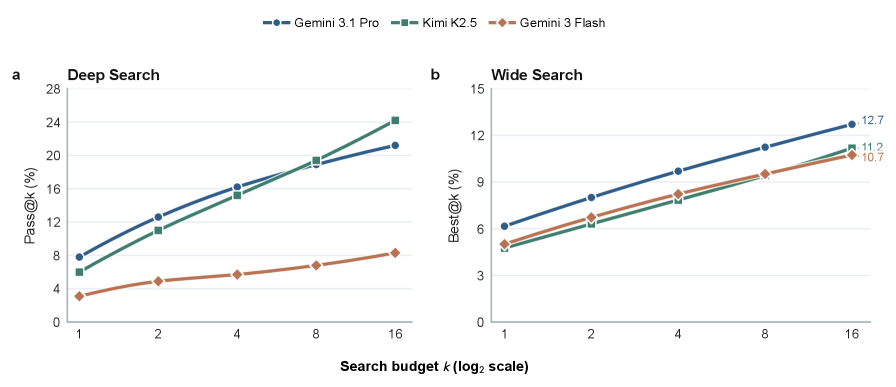
test-time scaling 图提醒我们,给更多轮次不等于更会研究。论文报告说,更长轨迹不稳定地带来更好结果;智能体可能重复类似搜索、反复检查貌似正确但错误的论文,或者过早停止。更多交互不是更好的证据管理。
一句话核心:AutoResearchBench 评测的是智能体能不能在依赖全文、多跳和集合覆盖证据的情况下做复杂科学文献发现。
为什么重要:很多 research assistant demo 看起来不错,是因为线索已经很接近答案。真实研究搜索更混乱:你可能只知道一个方法细节、一个负结果、一个数据集条件或一条引用关系,却不知道标题。可用的智能体必须组合线索、排除边界案例,并判断搜索空间是否已经穷尽。
方法拆解:
- 把 Deep Research 定义为唯一论文识别或有效无答案判断,约束来自全文和引用关系中的细粒度证据。
- 把 Wide Research 定义为 constrained set completion,要求找全满足科学查询的论文,同时避免纳入越界论文。
- 用模型辅助生成加人工验证构造任务,包括 constraint fuzzification、pruning、adversarial search checks 和 corpus-level audit。
- 用 DeepXiv 全文搜索环境评测 ReAct-style agents,并和开放 web search、端到端 research systems 做比较。
关键证据:benchmark 包含 1,000 个 query,其中 600 个 Deep Research、400 个 Wide Research,基于超过三百万篇论文的受控语料。Deep Research 中 90% 是单答案,10% 是无答案;Wide Research 包含 3,692 篇相关论文,平均每个 query 有 9.23 个有效答案。结果很严厉:最佳 Deep Research accuracy 是 Claude Opus 4.6 的 9.39%,最佳 Wide Research IoU 是 Gemini 3.1 Pro Preview 的 9.31%。多数开源和闭源模型在两个任务上都低于 10%。
我的判断:这篇几乎是在审计 Paper Radar 这类工具。它说明瓶颈不只是有没有搜索入口,真正难的是在长假设空间里管理证据,同时不要太早说服自己。
局限/问题:DeepXiv 作为受控全文环境有利于复现,但不等于混乱的公网。另一个我想追的问题是 persistent research memory:记住过去失败的约束会帮助后续搜索,还是会制造新的 anchoring error?
和本期主题的关系:data agents、document intelligence、自动研究、证据驱动文献搜索。
Exploring Interaction Paradigms for LLM Agents in Scientific Visualization
作者:Jackson Vonderhorst, Kuangshi Ai, Haichao Miao, Shusen Liu, Chaoli Wang。
机构:University of Notre Dame;Lawrence Livermore National Laboratory。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML

任务图把论文锚定在真实科学可视化工作里,而不是泛化的 GUI 点击。15 个 ParaView 任务包括加载数据、应用 filter、调参数、设相机视角和构建多步 visualization pipeline。关键是:代码能运行,不代表可视化语义正确。
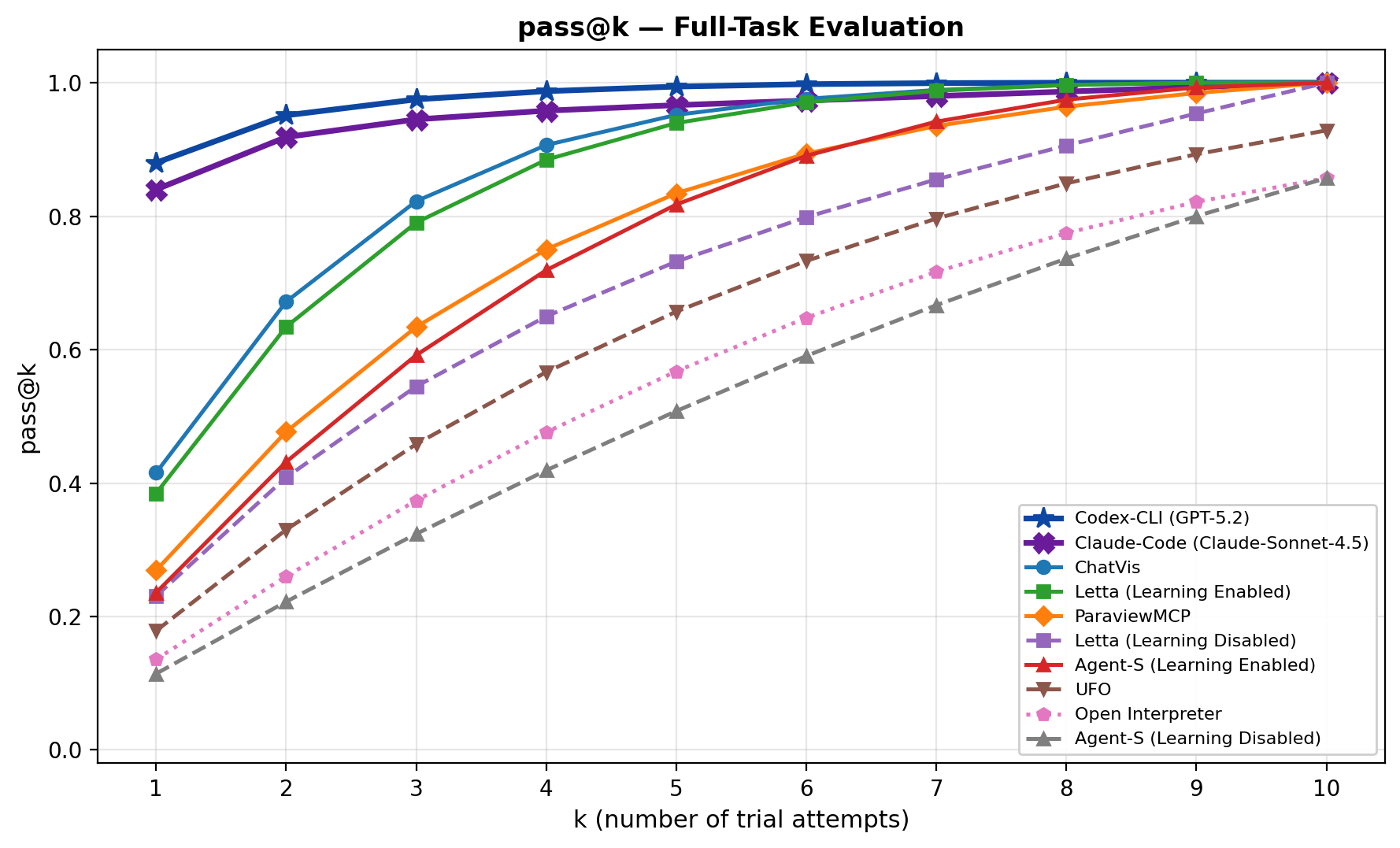
pass-at-k 曲线显示,重复尝试会让一些 agent 看起来很强。coding agents 可以通过代码和报错不断迭代,最终接近较高 pass-at-k。谨慎点在于,部署时除非系统能可靠挑出正确 run,否则 pass-at-k 会偏乐观。
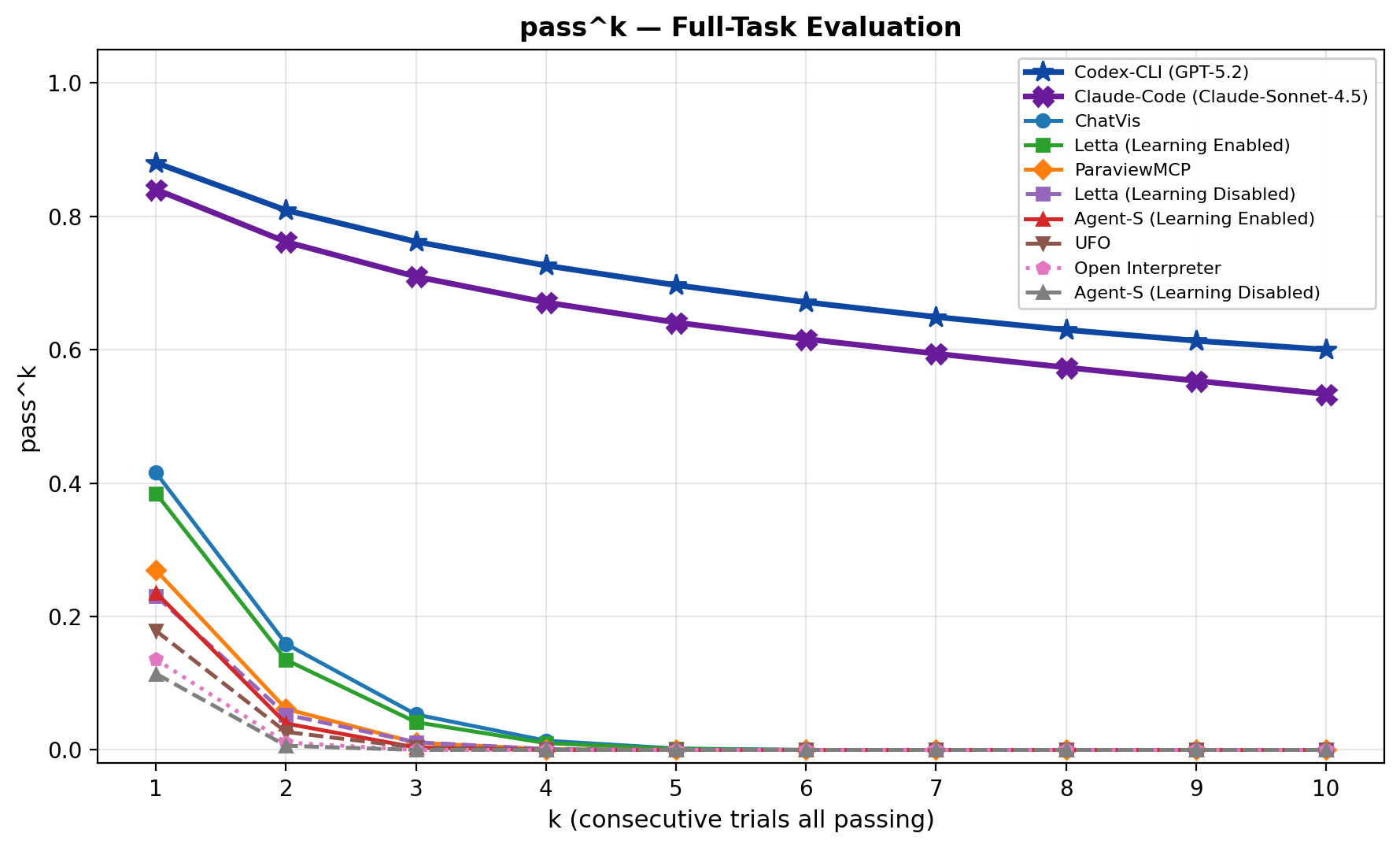
一致性曲线更刺眼。多次运行全部成功的概率下降很快,说明成功并不稳定。科学 workflow 里这种不稳定很重要,因为用户未必知道哪个 render 在语义上是错的。
一句话核心:这篇比较了 domain-specific、GUI-based、coding-agent 和 memory-enabled 四类科学可视化智能体交互范式,结论是每种接口都有不同失败面。
为什么重要:科学可视化很适合作为 agent 压力测试,因为它混合了代码、视觉感知、领域约定和中间状态。一个 workflow 可以可执行但科学上误导人。因此只看 final task completion 太弱,必须检查 pipeline state、参数和渲染结果是否符合意图。
方法拆解:
- 比较三类主要交互范式:ChatVis、ParaView-MCP 这类 domain-specific tools,UFO、Open Interpreter 这类 computer-use agents,以及 Codex CLI、Claude Code 这类 general-purpose coding agents。
- 在 SciVisAgentBench 的 15 个 ParaView 任务上测试,每个任务 10 次 trial,用来观察质量和波动。
- 对 GUI agents 增加 stepwise evaluation:每个任务拆成 5 个中间状态,从 gold previous state 开始执行下一步,避免前面错误层层传播。
- 比较部分 agent 的 memory-enabled 和 memory-disabled 配置,看持久记忆能否减少重复错误。
关键证据:coding agents 在 full-task completion 上最强,但成本高。论文报告 Codex CLI overall score 68.99、completion 100.0%,平均每任务 774.52K input tokens;Claude Code 为 66.35 和 96.0%,token 消耗也很高。domain-specific tools token 少很多,例如 ChatVis 平均 8.17K input tokens,但 completion rate 较低。GUI agents 在 full task 上表现弱,但 stepwise evaluation 提升到约 60-65% pass rate,说明主要失败面是长程规划而不是单步界面理解。持久记忆也有收益:Letta overall score 从 19.09 提升到 30.78,Agent-S 从 10.75 提升到 18.31。
我的判断:这篇的价值在于它没有强行选一个赢家。真正的结论是架构性的:科学智能体需要结构化 API、代码级灵活性、视觉验证和记忆,但只靠其中任意一个都会留下明显短板。
局限/问题:benchmark 只有一组 ParaView 任务,所以我不会过度泛化具体排名。更持久的发现是 decomposition。下一步我想看 SciVis agent 把中间可视化状态暴露成可审计 checkpoint,由人或 verifier 在进入下一步之前先检查。
和本期主题的关系:data agents、文档与视觉工作流智能、computer-use agents、中间状态验证。
阅读优先级和下期问题
我会按这个顺序继续追:AutoResearchBench 第一,因为它直接审计 research-assistant 行为;Intern-Atlas 第二,因为它给科学智能体的记忆结构一个具体形态;Eywa 第三,因为它把 LLM 和科学 foundation model 的接口讲清楚;SciVis interaction paper 第四,因为它把 workflow-agent 的设计取舍变成可观察实验。
后续我想继续追四个问题:
- 方法演化图能不能由领域专家编辑、审计和版本化,而不是 LLM 抽取后就冻结?
- 科学智能体能不能判断 specialist foundation model 什么时候 out of distribution 或校准失败?
- 文献搜索智能体能不能维护一个持久 hypothesis ledger,让失败约束帮助后续搜索,而不是浪费更多轮次?
- workflow agent 能不能把中间科学状态作为主要验证对象,而不只是交出最终文件?