让长程智能体会规划、会分工、也会验引文
Published:
TL;DR:本期看长程智能体如何摆脱单一 reactive loop。StraTA 让 agent 在执行前先生成全局策略,并把后续动作都放在这个策略下训练;RAO 把递归 subagent 变成可训练的推理时扩展机制;引文归因评测论文则检查 deep research 报告里的引用是否真的支撑旁边那句话。
本期我在看什么
最近几期一直在看可复用状态:技能、检索词、记忆潜变量、workboard、证据账本。这次我想往外走一步:有了状态以后,谁来决定长任务里怎么用这些状态?什么时候继续执行,什么时候拆给子智能体,什么时候不能再信一个看似正常的引用?
检索时 arXiv API 还没有显示 2026 年 5 月 8 到 9 日新的 CS 批次,所以我没有硬凑“今天”的论文,而是留在 5 月 7 日这个三天窗口内。初筛候选包括 STALE、Tool-Integrated Reasoning、AI-native work 的执行谱系、Constraint Decay、LatentRAG、OBLIQ-Bench、Data Language Models、机器人 world model latent、world-action model 自适应执行、可逆 SFT 行为、SoftSAE、ScaleLogic、StraTA、RAO、BAMI,以及 deep research agent 的 source attribution 评测。最后只选 3 篇,因为它们都有开放全文、图表可读,而且能围绕一个清楚问题展开:长程 agent 的工作怎样才能被规划、被分工、被审计?
论文细读笔记
StraTA:用战略级轨迹抽象训练长程智能体
作者:Xiangyuan Xue, Yifan Zhou, Zidong Wang, Shengji Tang, Philip Torr, Wanli Ouyang, Lei Bai, Zhenfei Yin。
机构:The Chinese University of Hong Kong;Shanghai Artificial Intelligence Laboratory;University of Georgia;University of Oxford;Shenzhen Loop Area Institute。
日期/会议:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | PDF
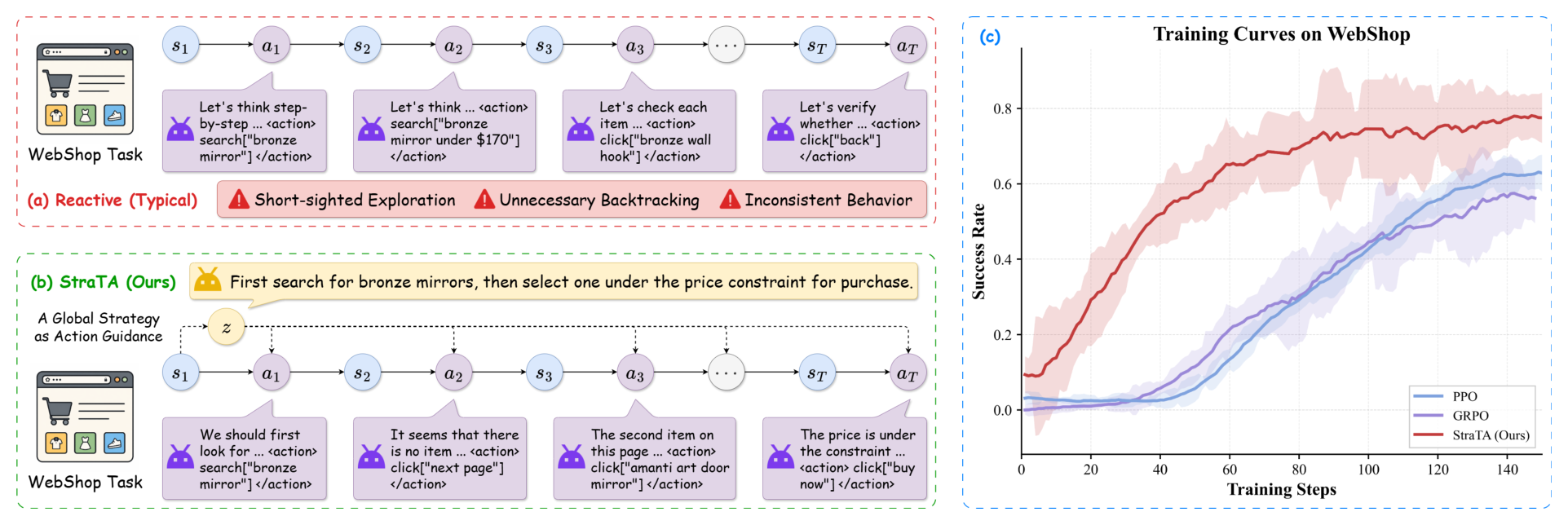
这张图给出了论文的核心诊断。reactive agent 每一步既要决定下一步动作,又要隐式决定整条路径,所以局部错误很容易变成来回试错和行为不一致。StraTA 在 rollout 之前先插入一个紧凑策略,后续每一步动作都在这个策略条件下生成。需要谨慎的是,这个策略仍然是自然语言;如果策略本身很虚,后续动作也会继承这种虚。
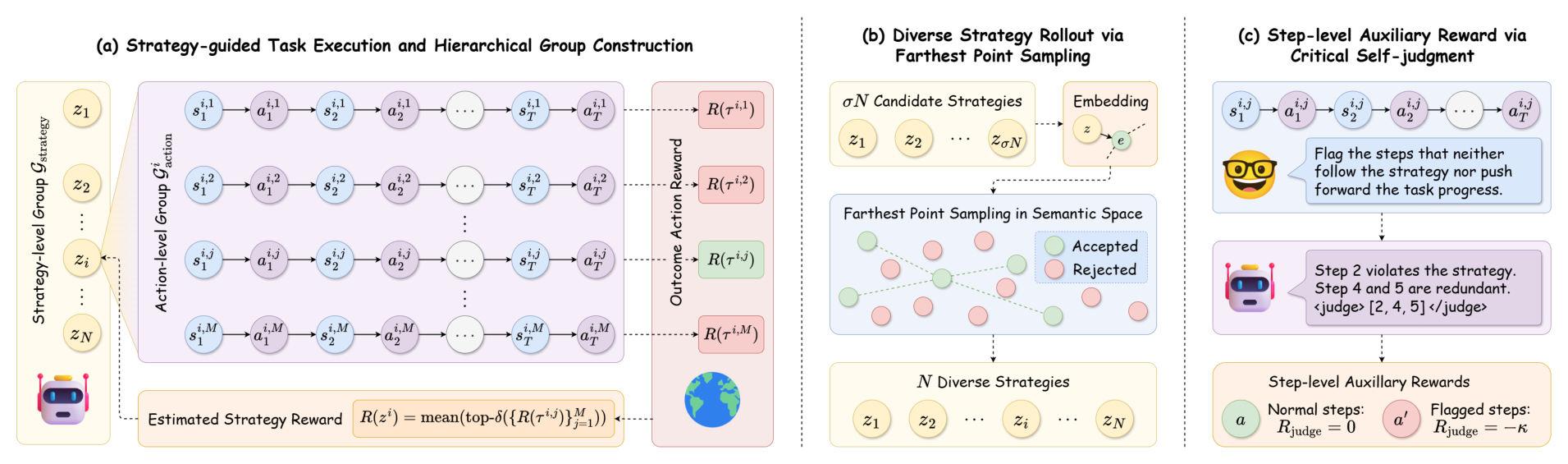
读方法时我会一直看这张框架图。StraTA 对同一个任务采样多个策略,每个策略下再跑多条轨迹,于是训练时既能比较不同策略,也能比较同一策略下的执行好坏。多样策略 rollout 用 strategy embedding 上的 farthest point sampling;critical self-judgment 则标出既不遵守策略、也不推进任务的动作。这里的核心不是“模型学会了完美规划”,而是 rollout 的信用分配终于有了结构。
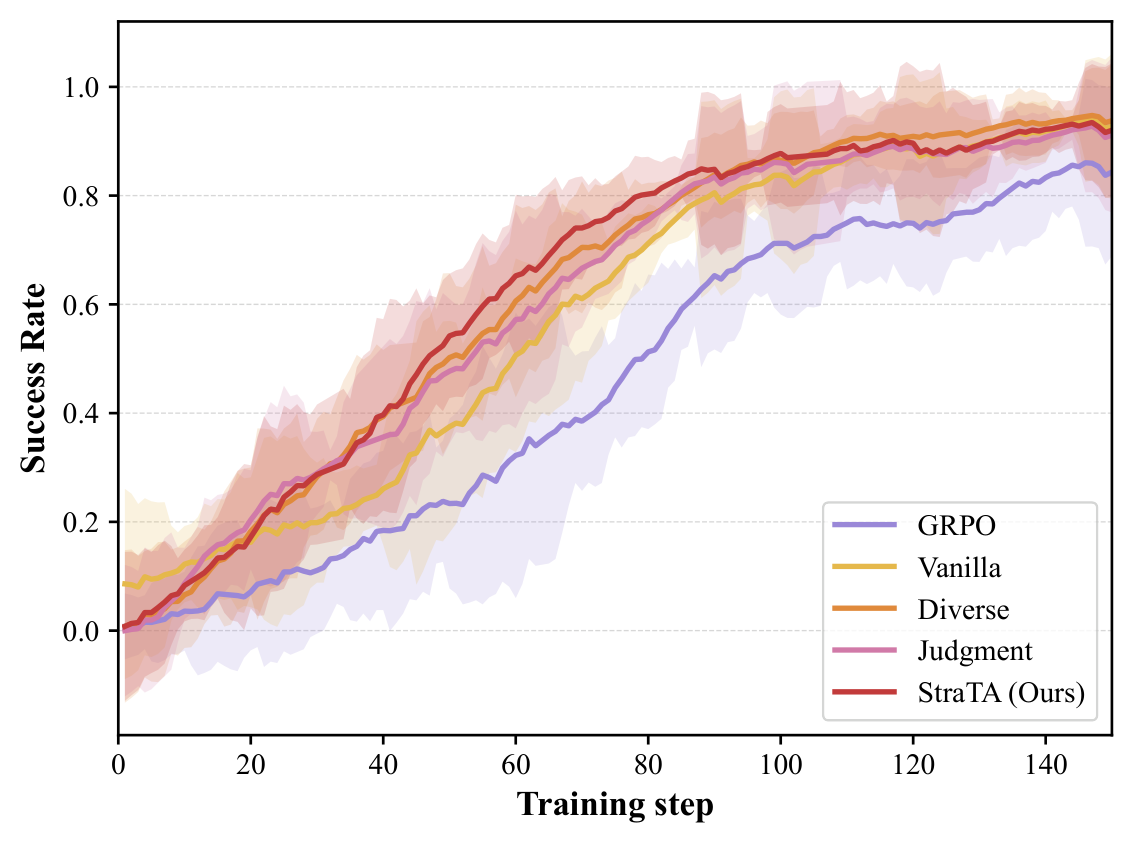
消融曲线说明额外机制并不是装饰。只加入 strategy conditioning 的 vanilla 版本已经超过 GRPO,但 diverse strategy rollout 和 self-judgment 让收敛更快也更稳。这支持了一个较窄但重要的结论:strategy object 可以成为训练抓手。它还不能证明同样机制在混乱工具 API、部分可观测工作流或企业私有环境里也稳定。
一句话核心 idea:StraTA 把长程 agent rollout 拆成两层训练问题:先生成轨迹级策略,再训练动作在这个策略下执行。
为什么重要:很多 agentic RL 仍然把最终轨迹奖励平均摊到每一步。这对长任务太粗了。如果一开始计划就错,后续动作的惩罚会很噪;如果计划不错但某一步失败,也不应该把计划级信用全部打掉。StraTA 的价值在于把“计划”显式变成可训练对象。
方法拆解:
从初始状态生成自然语言策略,再让每一步动作同时条件于固定策略和当前状态:
\[z \sim \pi_\theta(\cdot \mid s_1), \qquad a_t \sim \pi_\theta(\cdot \mid z, s_t).\]- 对每个任务采样多个策略,每个策略下采样多条 rollout。这样既能做 strategy-level 比较,也能做同一策略下的 action-level 比较。
- 用某个策略下表现最好的部分 rollout 来估计策略质量,避免一个策略因为单次执行失败就被整体否定。
- 加入两个辅助机制:farthest-point sampling 保证策略语义多样性;self-judgment 给不遵守策略或不推进任务的步骤加辅助惩罚。
关键证据:
| 设置 | PPO | GRPO | GiGPO | StraTA |
|---|---|---|---|---|
| ALFWorld success,Qwen2.5-7B | 87.4 | 77.1 | 90.8 | 93.1 |
| WebShop success,Qwen2.5-7B | 68.9 | 68.2 | 72.8 | 84.2 |
| SciWorld overall,Qwen2.5-7B | 51.4 | 41.8 | 未报告 | 63.5 |
| Qwen2.5-3B 消融 | ALFWorld success | WebShop success |
|---|---|---|
| Vanilla strategy version | 79.0 | 64.0 |
| 只用 diverse strategy rollout | 87.9 | 64.6 |
| 只用 self-judgment | 81.9 | 66.7 |
| 完整 StraTA | 88.6 | 73.4 |
这些数字让这篇不只是 prompt 工程。7B 设置下,WebShop 相比 GiGPO 的提升很明显;消融也把“探索到更多策略”和“给步骤级反馈”这两件事分开了。不过我不会把这些 benchmark 分数直接当成部署证据。ALFWorld、WebShop、SciWorld 仍是受控环境,而且训练时采样了多组策略和轨迹。
我的判断:我会看这篇,是因为真实 agent trace 里经常不是“模型不知道下一步该干什么”,而是“模型已经丢了整条任务线索”。strategy 变量让训练循环有机会在最终答案出错之前修理这个问题。
局限和问题:self-judgment 可能变成另一个由模型偏好塑造的奖励通道,因此我更想看到人类或环境侧对被惩罚步骤的审计。策略用自然语言反复 prepend,也未必是隐藏状态、工具变化、证据冲突场景下最好的表示。下一步值得问:策略质量能否由环境 artifact 验证,而不只是由 rollout outcome 和模型自评验证?
关联主题:agentic training、长程信用分配、结构化中间状态、工具智能体。
Recursive Agent Optimization:训练模型学会递归分工
作者:Apurva Gandhi, Satyaki Chakraborty, Xiangjun Wang, Aviral Kumar, Graham Neubig。
机构:Carnegie Mellon University;Amazon AGI Labs。
日期/会议:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | PDF

这张图提醒我们,递归不只是“多叫几个 agent”。root agent 可以生成子任务,子 agent 又可以继续生成子任务,每个节点都有更窄的任务和独立上下文。RAO 的关键是用同一个共享 policy 训练整棵树。模型学的不只是回答问题,也包括什么时候值得把问题拆给一个新的 agent 实例。
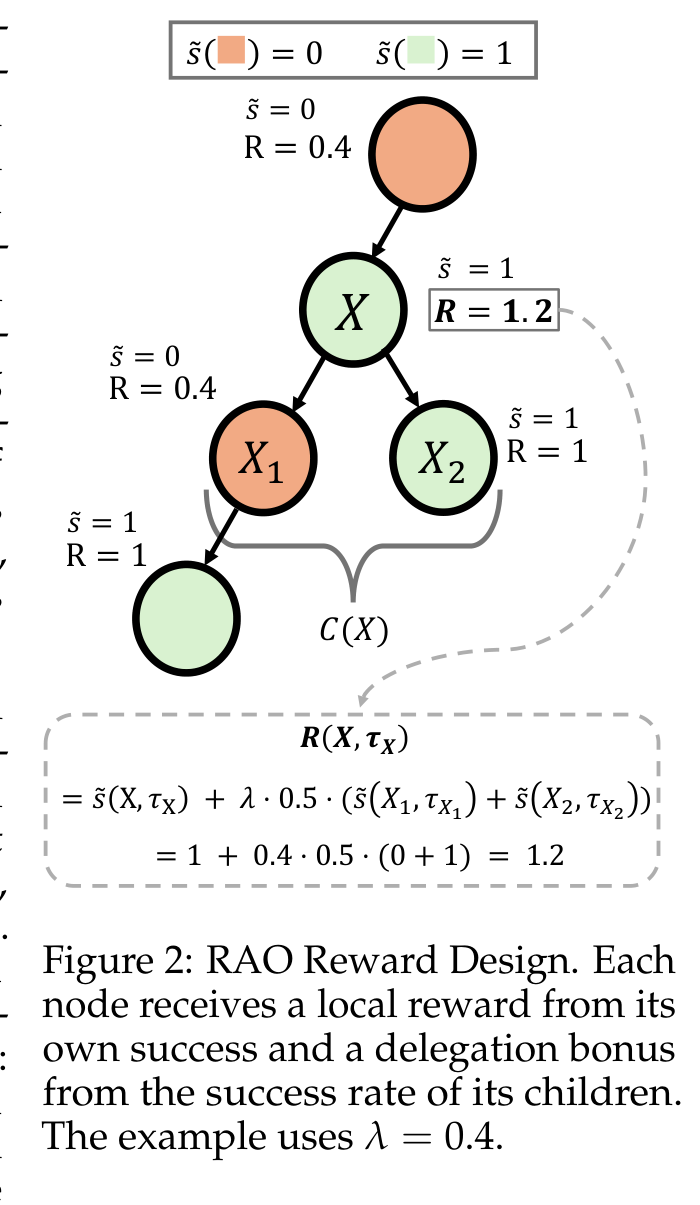
奖励设计是这篇的技术中心。每个节点都获得自己的成功奖励,并从子节点成功中获得 delegation bonus,因此奖励不只在 root answer 处进入系统。递归 rollout 会产生许多中间任务;如果只看最终答案,这些中间任务的质量几乎不可见。谨慎点在于,local reward 依赖环境是否能为被拆出来的任务定义成功信号。
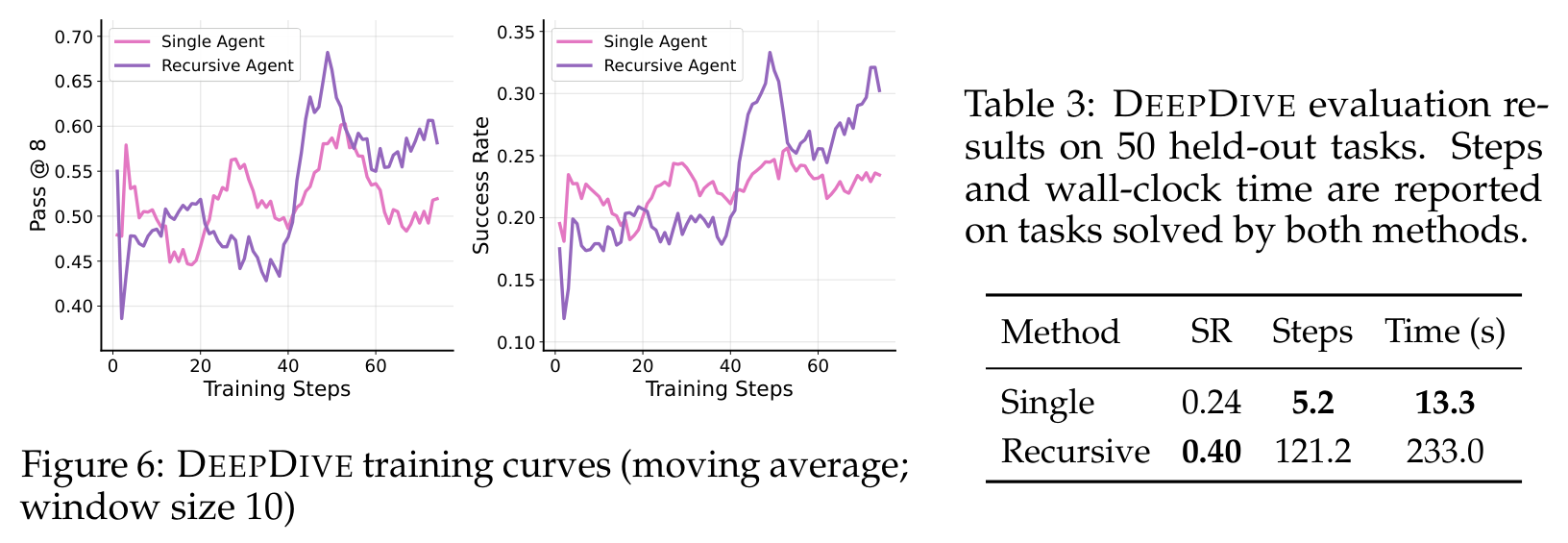
这张图把 tradeoff 放得很清楚。DEEPDIVE 上递归 agent 把 held-out success 从 0.24 提到 0.40,但在双方都解出的任务上,耗时也大幅增加。这不是附带细节,而是说明 recursion 本质上是一种 test-time compute allocation。遇到需要深入拆解的任务会有帮助;遇到强顺序依赖且难以并行的任务,成本会很高。
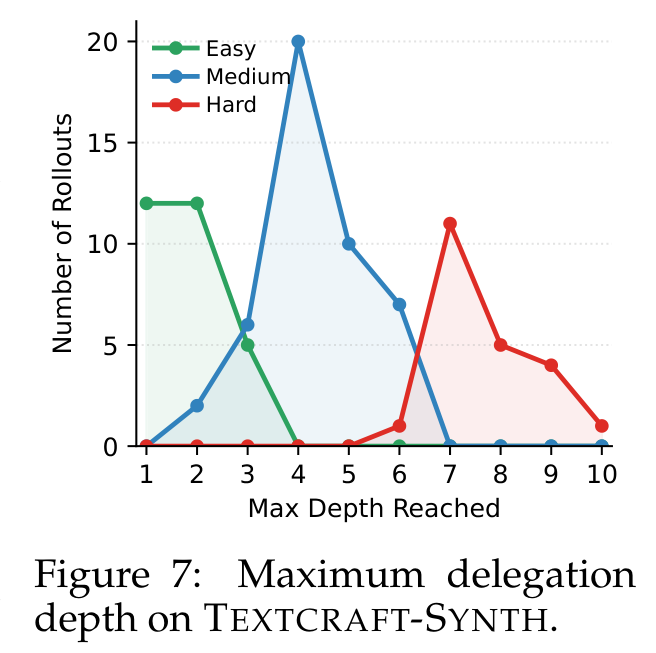
我最喜欢这张深度分布图。简单任务使用浅递归,较难的 TEXTCRAFT-SYNTH 任务会推到更深层级。这支持了一个重要判断:RAO 不是机械地把所有任务塞进固定多 agent 模板。当然,深度适应不等于子任务一定拆得好;我还想看更多失败 delegation 的具体分析。
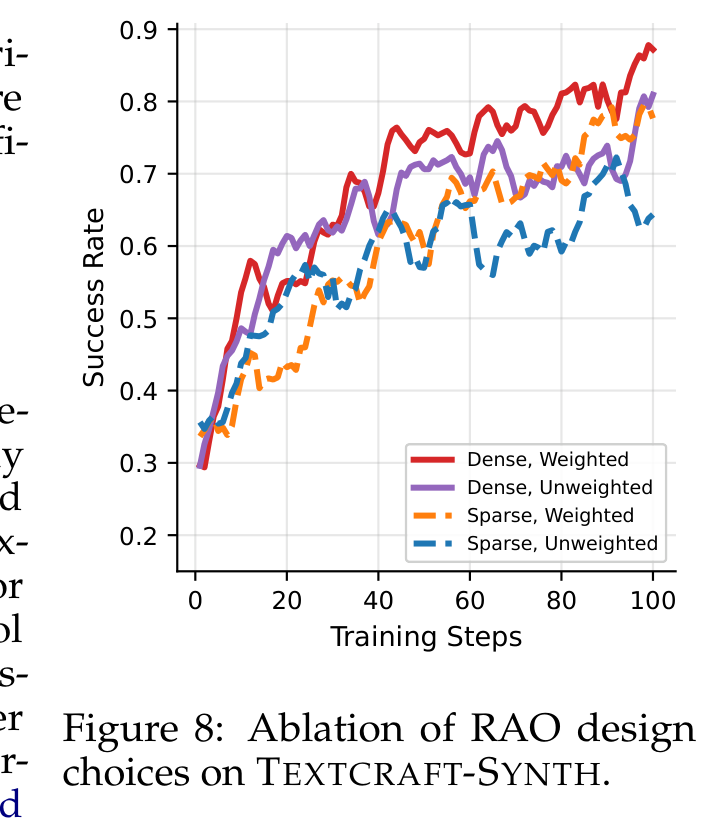
消融图拆开了两个机制:节点级 dense reward 和按深度做 inverse-frequency weighting。Dense weighted 曲线最好,这很合理,因为递归树会产生大量深层节点,如果不加权,训练更新可能被深层 rollout 淹没。这张图比 headline benchmark 更直接地支撑了优化设计。剩下的问题是,如果子任务奖励很噪或延迟很长,这套设计会有多敏感。
一句话核心 idea:RAO 把递归 delegation 放进 policy 训练,让 subagent 不再只是固定脚手架,而是模型学会使用的一种推理时扩展行为。
为什么重要:subagent 已经出现在 coding、research、data analysis 工具里,但很多系统只是把它作为产品功能或编排模式暴露出来。RAO 问的是更难的问题:模型能不能学会什么时候分工、怎么写子任务、以及怎么合并子任务输出?
方法拆解:
- policy 在 root task 上执行,过程中可以调用类似
launch_subagent的动作生成子任务;子 agent 也可以继续生成子任务,于是形成动态执行树。 - 整棵树都使用同一个 policy,因此 root、internal node、leaf node 不是人工定义的不同角色,而是一起优化的同一模型。
每个节点使用 local reward:
\[R(X,\tau_X) = \tilde{s}(X,\tau_X) + \lambda \frac{1}{|C(X)|}\sum_{c \in C(X)}\tilde{s}(c,\tau_c),\]第二项用子节点成功奖励有用的 delegation。
- advantage 用 root rollout reward 的 leave-one-out baseline 计算,再用 depth-level inverse-frequency weighting 避免深层子任务过多时主导更新。
关键证据:
| Benchmark slice | Single agent | Recursive agent |
|---|---|---|
| TEXTCRAFT-SYNTH,8K train/eval,all success | 0.24 | 0.95 |
| TEXTCRAFT-SYNTH,8K train/eval,hard success | 0.00 | 0.88 |
| TEXTCRAFT-SYNTH,40K train/256K eval,all success | 0.73 | 0.96 |
| TEXTCRAFT-SYNTH,40K train/256K eval,hard success | 0.20 | 0.88 |
| Benchmark slice | Single agent | Recursive agent |
|---|---|---|
| OOLONG-REAL average reward | 0.203 | 0.320 |
| OOLONG-REAL,175K-token bucket reward | 0.129 | 0.249 |
| DEEPDIVE held-out success | 0.24 | 0.40 |
| DEEPDIVE common-solved wall-clock time | 13.3 s | 233.0 s |
最强的证据不只是“递归赢了”。更重要的是,在 TEXTCRAFT-SYNTH 上,8K context 的递归模型几乎恢复了大 context 递归模型的大部分能力,而且 hard tasks 没有崩掉。OOLONG-REAL 给了更贴近长上下文聚合的证据。DEEPDIVE 则是警告:递归有时是在用更多 wall-clock time 买成功率。
我的判断:这篇把 delegation 变成了可测量对象。我不希望 subagent 只是一个偶尔有用、偶尔产出一堆未合并笔记的 UI 功能。RAO 至少给训练循环提供了奖励子任务成功和塑造 delegation depth 的方式。
局限和问题:实验环境需要 local success signal,但真实研究或代码任务里,子任务是否成功往往要到很后面才知道。递归 rollout 在 OOLONG-REAL 和 DEEPDIVE 上消耗更多 token,所以成本收益强依赖任务形态。下一步我最想看 failure attribution:递归失败时,错在 root 拆分、child prompt、child execution,还是最终 synthesis?
关联主题:agentic training、多智能体分工、长上下文扩展、process reward、数据/研究智能体。
Cited but Not Verified:检查 deep research agent 的引用是否真的支撑论断
作者:Hailey Onweller, Elias Lumer, Austin Huber, Pia Ramchandani, Vamse Kumar Subbiah, Corey Feld。
机构:Commercial Technology and Innovation Office, PricewaterhouseCoopers, U.S.
日期/会议:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | PDF
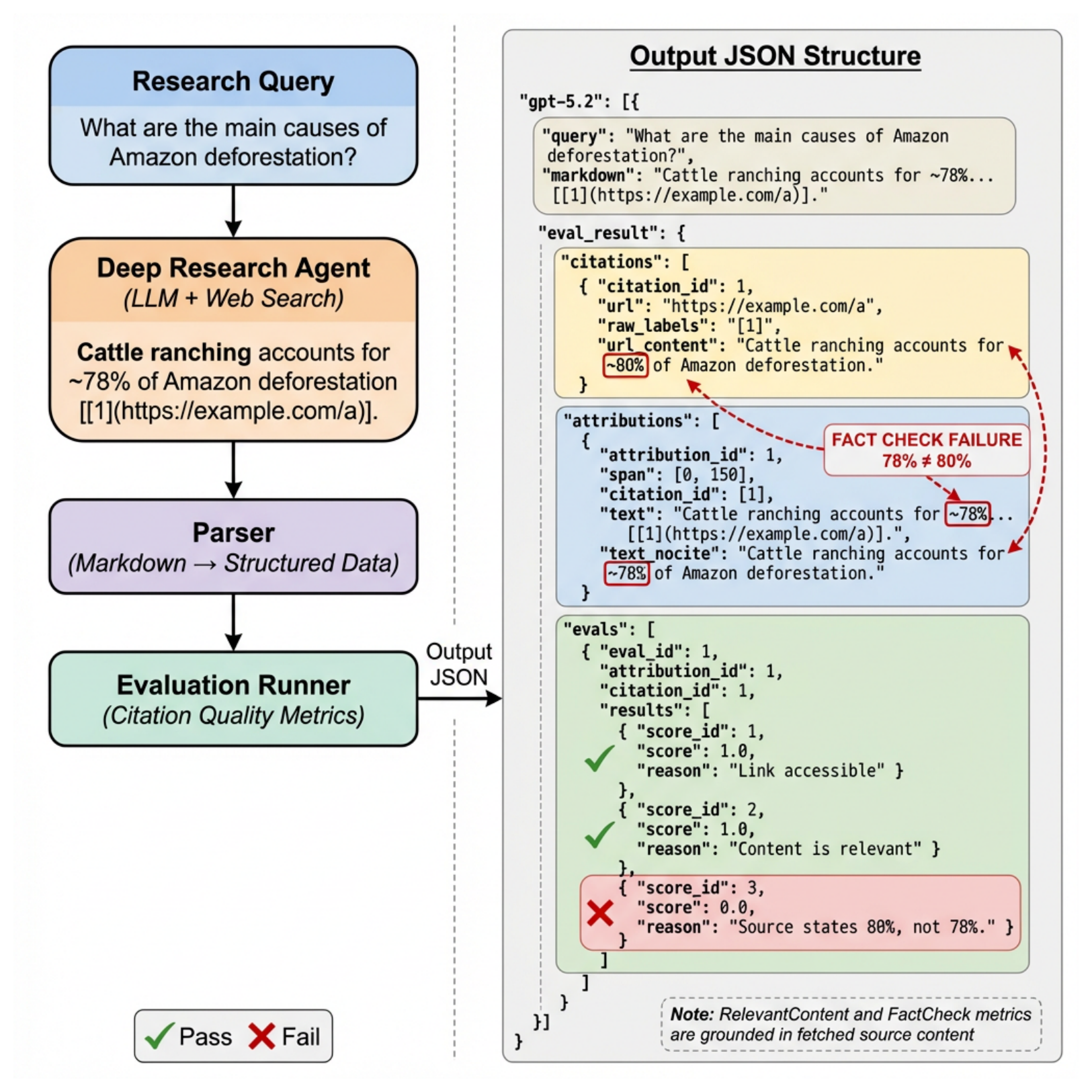
这个框架的优点是简单。deep research agent 生成带引用的 Markdown 报告,AST parser 抽取 claim-citation pair,系统抓取被引用页面,然后分别评估链接是否可访问、内容是否相关、事实是否被支持。关键是它检查 citation 和真实 cited content 的绑定,而不是检查模型自信度或孤立 claim。需要谨慎的是,Relevant Content 和 Fact Check 仍使用 LLM judge,虽然作者对 Fact Check 做了人工校准。
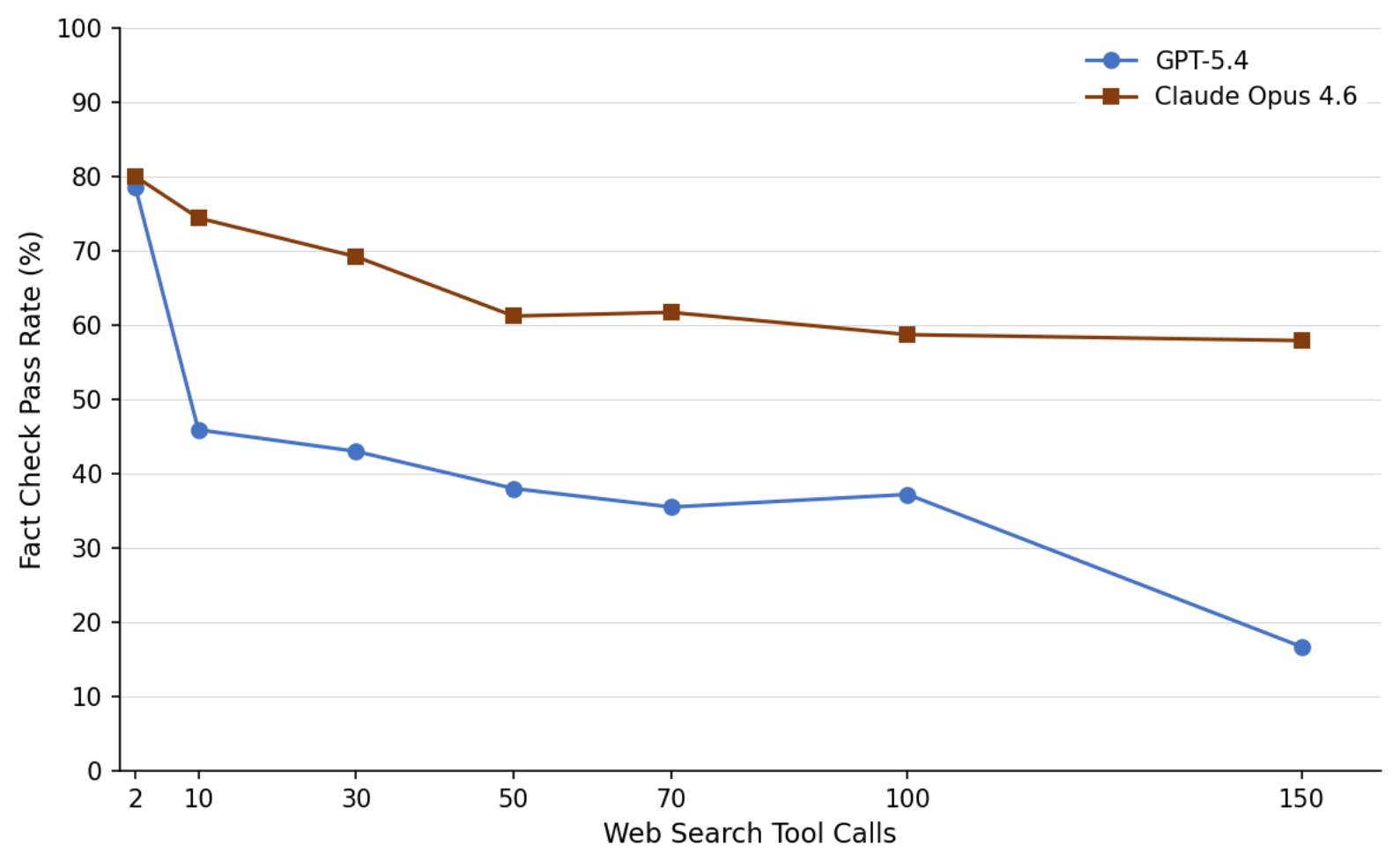
这张搜索深度曲线解释了为什么这篇适合放进 agent digest。更多 tool call 并不自动带来更可靠报告。两个被测 frontier model 随着工具调用数上升,事实支持率下降,而链接可访问性和主题相关性仍保持很高。这正是最危险的研究 agent 失败形态:链接能打开,页面也相关,但旁边那句话并没有被来源支持。
一句话核心 idea:论文在 claim-source 粒度评测 deep research 引用,说明“链接可用且主题相关”并不等于“引用支撑了具体事实”。
为什么重要:deep research agent 很容易因为“有很多引用”而获得不该有的信任。引用只有在把附近论断绑定到证据时才有价值。这篇对 Paper Radar 本身也有提醒意义:Markdown 报告应该被当成结构化 artifact,而不是纯文本 blob。
方法拆解:
- 用带 web search 的 agent 为研究问题生成带内联引用的 Markdown 报告。
- 用 AST pipeline 把 Markdown 解析成 attribution document:规范化文本、剥离 code block、抽取 citation node、拆分 claim,并把 citation 往前绑定到对应句子。
- 抓取每个 cited URL,并对每个 claim-citation pair 评估三个维度:Link Works、Relevant Content、Fact Check。
- 在 DeepResearch Bench 和 BrowseComp 的 130 个 query 上评测 14 个模型,再对 GPT-5.4 和 Claude Opus 4.6 把搜索深度从 2 个 tool call 扩到 150 个 tool call。
关键证据:
| 模型 | Success | Link Works | Relevant Content | Fact Check |
|---|---|---|---|---|
| Claude Opus 4.5 | 90.0% | 98.7% | 95.7% | 76.8% |
| GPT-5.4 | 100.0% | 100.0% | 93.7% | 47.7% |
| GPT-5.2 | 100.0% | 98.3% | 92.3% | 58.8% |
| Claude Sonnet 4.6 | 93.3% | 99.2% | 89.8% | 58.7% |
| GPT-5 Mini | 100.0% | 99.3% | 87.4% | 38.9% |
| Gemini 3.1 Pro | 90.0% | 94.1% | 80.7% | 48.5% |
| OSS-120B | 40.0% | 83.9% | 68.7% | 24.4% |
| 搜索深度 | GPT-5.4 Fact Check | Claude Opus 4.6 Fact Check |
|---|---|---|
| 2 tool calls | 78.6% | 80.0% |
| 50 tool calls | 38.0% | 61.2% |
| 150 tool calls | 16.7% | 57.9% |
第一张表让人不太舒服:很多模型的链接指标都很好,但 Fact Check 低很多。也就是说,用户几乎总能点开一个相关页面,却不能因此相信旁边的具体事实。第二张表把 information overload 说得更具体:GPT-5.4 的事实支持率随搜索深度急剧下降,Claude Opus 4.6 更稳,但也在下降。
我的判断:这是我希望 research agent 自带的一层审计。它把“链接存在”与“来源支撑这句话”分开了。对科学综述、市场研究、法律研究,以及会被另一个 agent 复用的报告来说,这个区别非常实际。
局限和问题:评测依赖当时网页可访问性,而 URL 会失效或内容变化。Fact Check 虽经人工校准,但仍是 LLM-as-judge,不是最终真值机。论文也主要研究公共 web search;如果换成企业私有 RAG,权限、版本、内部文档引用会让问题更难。
关联主题:document intelligence、deep research agent、引用验证、可审计证据、data agent。
阅读优先级和下期问题
如果只先读一篇,我会从 RAO 开始,因为递归分工已经在真实 agent 产品里出现,而这篇给的是训练目标,不只是界面模式。StraTA 适合接着看,它回答长程 rollout 的信用分配问题。引文归因这篇则最接近生产工作流,因为它给出了一个很具体的检查:生成的研究报告到底值不值得信。
后面我会继续追这几个问题:
- 策略质量和 delegation 质量能否由环境 artifact 验证,而不只靠模型自评或最终分数?
- 递归 agent 能否输出 blame trace,把坏拆分、坏子任务执行、坏 synthesis 分开?
- citation-level 评测能否迁移到带版本和权限控制的私有文档库?
- 从本期初筛看,STALE、LatentRAG、OBLIQ-Bench、Constraint Decay 和 world-action model 相关论文仍值得下期回看,尤其适合记忆新鲜度、检索和世界模型可靠性主题。