Strategies, Subagents, and Citation Checks for Long-Horizon Work
Published:
TL;DR: this round is about long-horizon work that does not fit inside a single reactive loop. StraTA trains an agent to carry a global strategy through an episode. RAO trains a model to use recursive subagents rather than treating delegation as a fixed scaffold. The source-attribution paper asks whether deep-research citations actually support the claims they are attached to.
What I Am Watching This Round
The last few issues spent a lot of time on reusable state: skills, retrieval terms, memory latents, workboards, evidence ledgers. I wanted this issue to move one step outward. Once an agent has state, who decides how to use it across a long task? When should the agent keep acting, delegate, or stop trusting a cited source?
At search time, the arXiv API did not show a new May 8-9 CS slice, so I stayed in the May 7 three-day window rather than reaching back into older April papers. The broader non-duplicate shortlist included STALE, Tool-Integrated Reasoning, Execution Lineage for AI-native work, Constraint Decay, LatentRAG, OBLIQ-Bench, Data Language Models, robotic world-model latents, adaptive world-action execution, reversible SFT behavior, SoftSAE, ScaleLogic, StraTA, RAO, BAMI, and source-attribution evaluation for deep research agents. I kept three because each can be read end to end from the open paper, each has usable figures, and together they make a clean question: how do we keep long-horizon agent work planned, delegated, and auditable?
Paper Notes
StraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction
Authors: Xiangyuan Xue, Yifan Zhou, Zidong Wang, Shengji Tang, Philip Torr, Wanli Ouyang, Lei Bai, Zhenfei Yin.
Institutions: The Chinese University of Hong Kong; Shanghai Artificial Intelligence Laboratory; University of Georgia; University of Oxford; Shenzhen Loop Area Institute.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | PDF
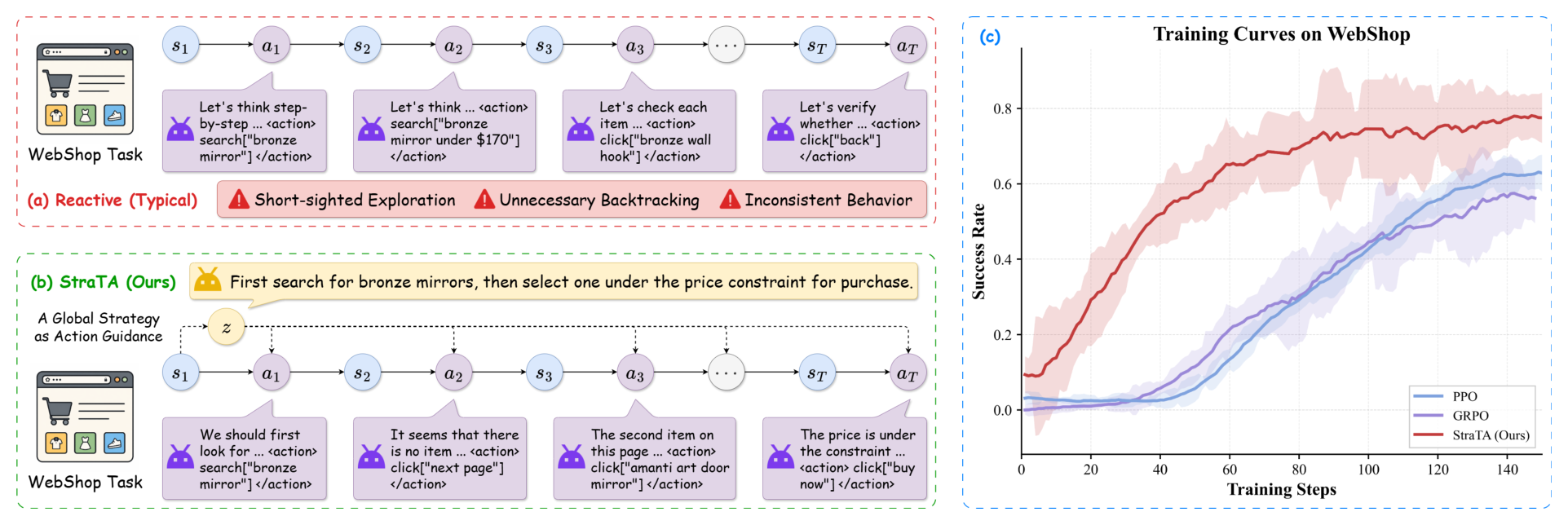
The first figure gives the paper’s main diagnosis. A reactive agent must decide the next action and the whole course of action at the same time, so local mistakes can snowball into backtracking or incoherent behavior. StraTA inserts a compact strategy before the rollout and conditions every later action on that strategy. The caveat is that the strategy is still natural language; if it is vague, the later actions inherit that vagueness.
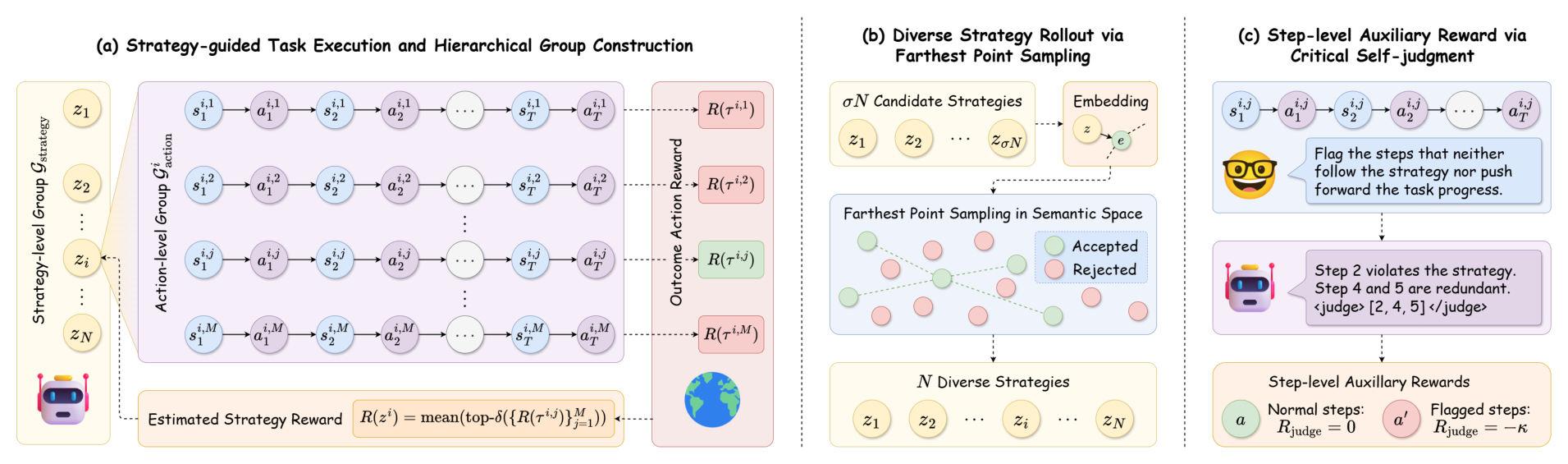
This framework figure is the part I would keep open while reading the method. StraTA samples multiple strategies for a task, rolls out multiple trajectories under each strategy, and then uses the two-level structure for strategy-level and action-level optimization. The diverse-strategy step uses farthest point sampling over strategy embeddings, while critical self-judgment marks steps that neither follow the strategy nor advance the task. The careful interpretation is that the paper is improving credit assignment over a structured rollout, not proving that the generated strategy is human-interpretable in every failure case.
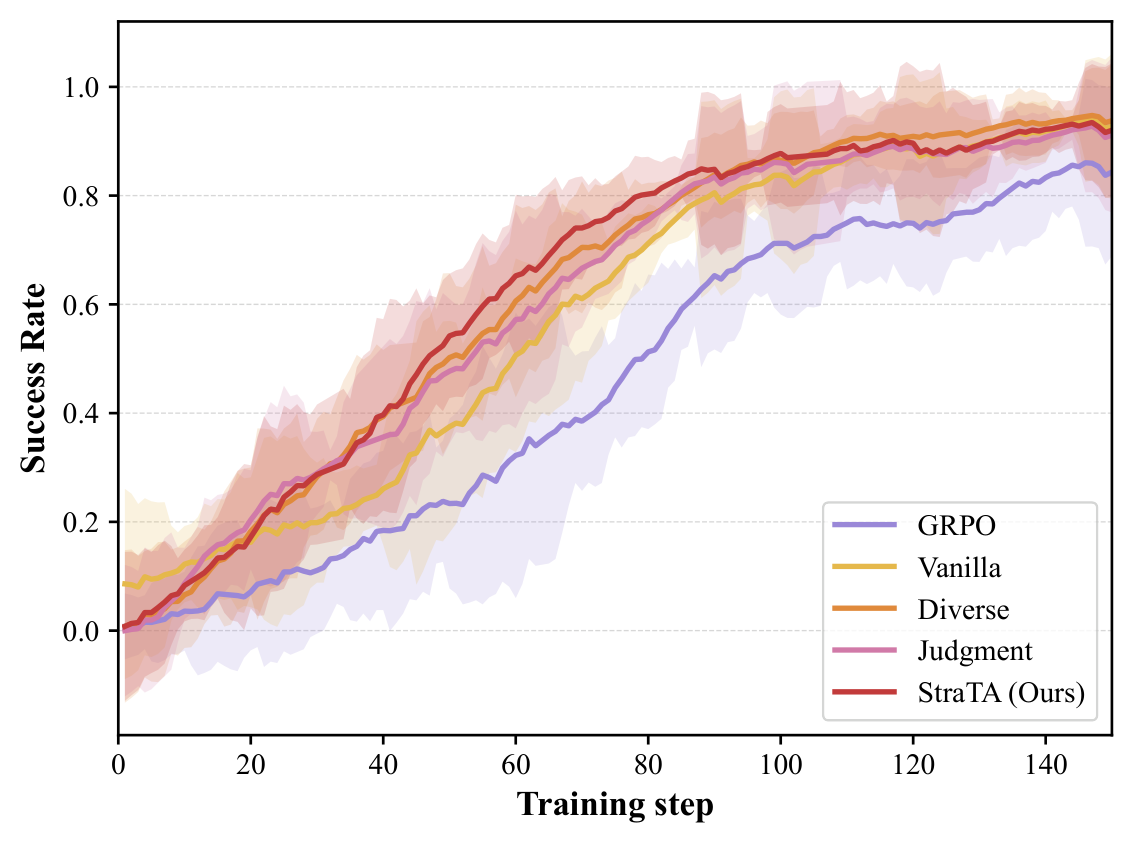
The ablation curve shows why the extra machinery matters. Vanilla strategy conditioning already moves above GRPO, but diverse strategy rollout and self-judgment make convergence faster and more stable. This supports the paper’s narrow claim that the strategy object is useful as a learning handle. It does not settle whether the same handle survives messier tool APIs or partially observed enterprise workflows.
Quick idea: StraTA turns a long agent rollout into a two-level learning problem: first sample a trajectory-level strategy, then train actions to execute under that strategy.
Why it matters: many agentic RL runs still reward the final trajectory and smear that scalar reward over every step. That is a blunt signal for long tasks. If the agent chose a bad plan, later action penalties are noisy; if the plan was good but one step failed, plan-level credit should not collapse. StraTA’s useful move is to make the plan an explicit training object.
Method walkthrough:
Generate a natural-language strategy from the initial state, then condition every action on both the fixed strategy and the current state:
\[z \sim \pi_\theta(\cdot \mid s_1), \qquad a_t \sim \pi_\theta(\cdot \mid z, s_t).\]- For each task, sample several strategies and several rollouts per strategy. This creates comparisons between strategies and comparisons between trajectories under the same strategy.
- Estimate strategy quality from the top-performing fraction of its rollouts, so a strategy is not punished too harshly for one unlucky execution.
- Add two training aids: farthest-point sampling to keep sampled strategies semantically diverse, and self-judgment to assign step-level auxiliary penalties when actions violate the strategy or make no progress.
Evidence:
| Setting | PPO | GRPO | GiGPO | StraTA |
|---|---|---|---|---|
| ALFWorld success, Qwen2.5-7B | 87.4 | 77.1 | 90.8 | 93.1 |
| WebShop success, Qwen2.5-7B | 68.9 | 68.2 | 72.8 | 84.2 |
| SciWorld overall, Qwen2.5-7B | 51.4 | 41.8 | not reported | 63.5 |
| Qwen2.5-3B ablation | ALFWorld success | WebShop success |
|---|---|---|
| Vanilla strategy version | 79.0 | 64.0 |
| Diverse strategy rollout only | 87.9 | 64.6 |
| Self-judgment only | 81.9 | 66.7 |
| Full StraTA | 88.6 | 73.4 |
These numbers make the paper more than a prompt-engineering story. At the 7B scale, the WebShop success jump over GiGPO is large enough to notice, and the ablation separates exploration diversity from self-judged step feedback. I would still be cautious about treating the scores as deployment evidence: ALFWorld, WebShop, and SciWorld are useful but controlled environments, and the method samples many strategy/trajectory combinations during training.
Why I care: the paper gives a concrete training target for a problem I see in agent traces all the time. The agent is often not ignorant of the next action; it has lost the thread of the whole episode. A strategy variable gives the training loop something to repair before the final answer is wrong.
Limitations/questions: self-judgment can become another model-shaped reward channel, so I would want human or environment-side audits of the penalized steps. The strategy is textual and prepended repeatedly, which may not be the best representation once tasks include hidden state, changing tools, or conflicting evidence. The next question is whether strategy quality can be checked by the environment, not only by rollout outcomes and model self-critique.
Connection to tracked themes: agentic training, long-horizon credit assignment, structured intermediate state, tool-using agents.
Recursive Agent Optimization
Authors: Apurva Gandhi, Satyaki Chakraborty, Xiangjun Wang, Aviral Kumar, Graham Neubig.
Institutions: Carnegie Mellon University; Amazon AGI Labs.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | PDF

This figure is a useful reminder that recursion is not just “more agents.” The root agent can spawn subagents, those subagents can spawn more subagents, and each node receives a narrower task with its own context. The key design choice is that RAO trains one shared policy across the whole tree. The model is not only learning to answer; it is learning when a subproblem deserves a fresh agent instance.
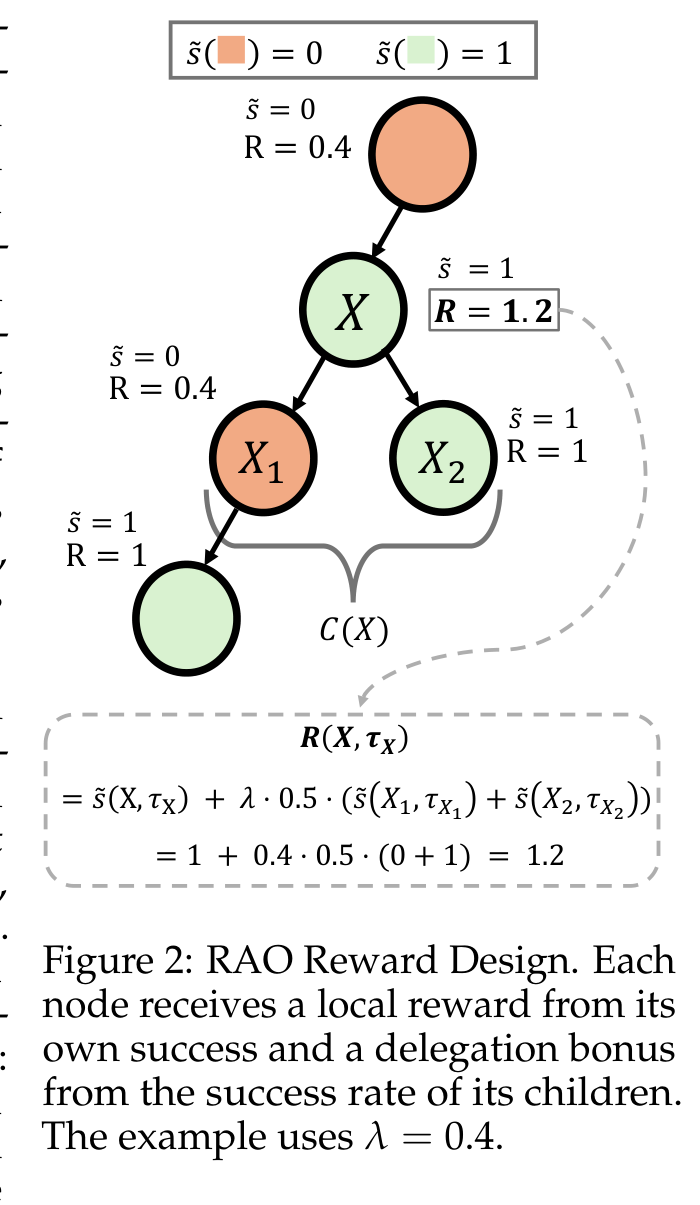
The reward design is the technical center of the paper. Each node gets credit for its own success plus a delegation bonus from its children, so the root is not the only place where reward enters the tree. This matters because a recursive rollout can generate many intermediate tasks whose quality is invisible if only the final root answer is scored. The caveat is that local rewards depend on whether each environment can define success for the delegated task.
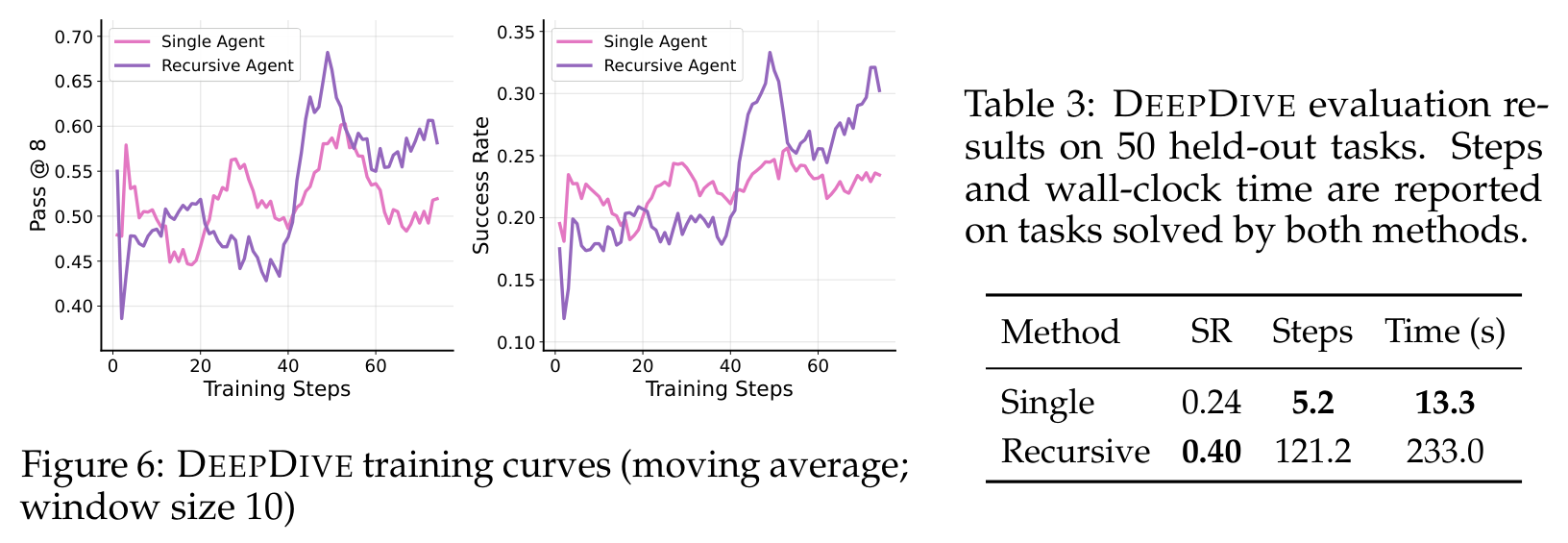
This crop shows the tradeoff most clearly. On DEEPDIVE, the recursive agent improves held-out success from 0.24 to 0.40, but the common-solved tasks become much slower. That is not a footnote; it tells us recursion is a test-time compute allocation mechanism. It helps when deeper decomposition is needed, but it can be the wrong shape for tasks that are sequential and hard to parallelize.
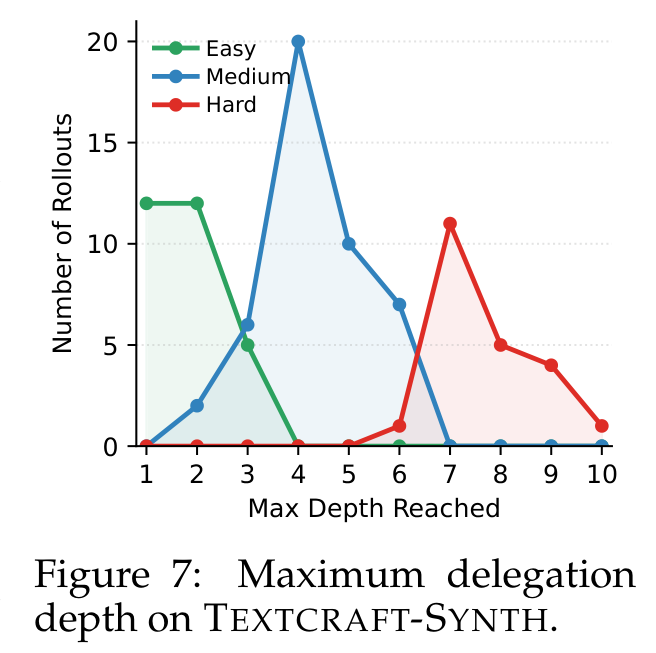
The depth histogram is the qualitative evidence I like most in this paper. Easy tasks use shallow recursion, while harder TEXTCRAFT-SYNTH tasks push to greater depth. This supports the claim that RAO is not simply forcing every task through a fixed multi-agent template. I would still want more analysis of bad delegations, because a histogram can show depth adaptation without proving that the child tasks are well-formed.
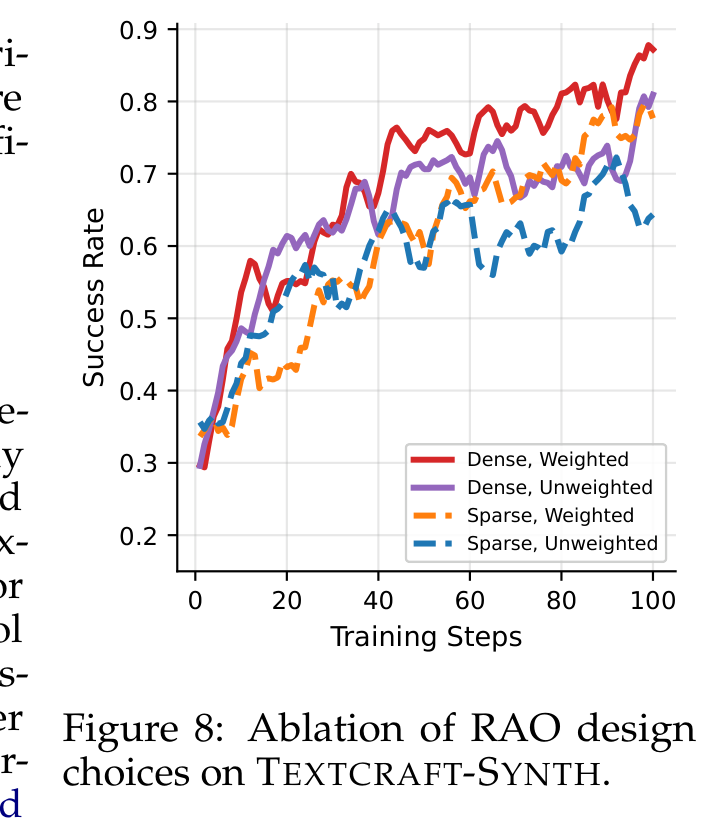
The ablation separates two pieces of RAO: dense node-local rewards and depth-level inverse-frequency weighting. Dense weighted training is the strongest curve, which makes sense because recursive trees otherwise overproduce deep nodes and can let those nodes dominate the update. This figure supports the optimization design more directly than the headline benchmark numbers. The remaining uncertainty is how sensitive the design is to noisy or delayed child-task rewards.
Quick idea: RAO trains the model to use recursive delegation as part of the policy, so subagents become a learned inference-time scaling behavior rather than a hand-written wrapper around a fixed model.
Why it matters: subagents are already common in coding, research, and data-analysis tools, but most systems expose them as a product feature or orchestration pattern. RAO asks a harder question: can the model be trained to decide when to delegate, how to phrase the child task, and how to combine child outputs?
Method walkthrough:
- Run a policy on a root task. During the rollout, the policy may call a
launch_subagent-style action to create child tasks; child agents may do the same, forming a dynamic execution tree. - Use the same policy at every node, so root agents, internal agents, and leaf agents are all optimized together rather than as separate hand-coded roles.
Score each node with a local reward:
\[R(X,\tau_X) = \tilde{s}(X,\tau_X) + \lambda \frac{1}{|C(X)|}\sum_{c \in C(X)}\tilde{s}(c,\tau_c),\]where the second term rewards useful delegation through child success.
- Compute advantages with a leave-one-out baseline from root rollout rewards, then use depth-level inverse-frequency weighting so dense subagent layers do not dominate the update.
Evidence:
| Benchmark slice | Single agent | Recursive agent |
|---|---|---|
| TEXTCRAFT-SYNTH, 8K train/eval, all success | 0.24 | 0.95 |
| TEXTCRAFT-SYNTH, 8K train/eval, hard success | 0.00 | 0.88 |
| TEXTCRAFT-SYNTH, 40K train/256K eval, all success | 0.73 | 0.96 |
| TEXTCRAFT-SYNTH, 40K train/256K eval, hard success | 0.20 | 0.88 |
| Benchmark slice | Single agent | Recursive agent |
|---|---|---|
| OOLONG-REAL average reward | 0.203 | 0.320 |
| OOLONG-REAL, 175K-token bucket reward | 0.129 | 0.249 |
| DEEPDIVE held-out success | 0.24 | 0.40 |
| DEEPDIVE common-solved wall-clock time | 13.3 s | 233.0 s |
The strongest result is not just that recursion wins. It is that the 8K-context recursive model recovers most of the performance of the much larger-context recursive setup on TEXTCRAFT-SYNTH, and it does not collapse on hard tasks. OOLONG-REAL shows the long-context story in a less synthetic setting. DEEPDIVE is the warning label: recursion can buy accuracy by spending a lot more wall-clock time.
Why I care: this paper makes delegation measurable. I do not want subagents to be a mysterious UI affordance that sometimes helps and sometimes produces a pile of unmerged notes. RAO gives the training loop a way to reward local child-task success and to shape delegation depth.
Limitations/questions: the environments need local success signals, and real research or coding tasks often have child tasks whose success is ambiguous until much later. Recursive rollouts also spend more tokens on OOLONG-REAL and DEEPDIVE, so the economic story is task-dependent. The next thing I would look for is failure attribution: when recursion hurts, was the bad decision the root split, the child prompt, the child execution, or the synthesis step?
Connection to tracked themes: agentic training, multi-agent delegation, long-context scaling, process rewards, data/research agents.
Cited but Not Verified: Parsing and Evaluating Source Attribution in LLM Deep Research Agents
Authors: Hailey Onweller, Elias Lumer, Austin Huber, Pia Ramchandani, Vamse Kumar Subbiah, Corey Feld.
Institutions: Commercial Technology and Innovation Office, PricewaterhouseCoopers, U.S.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | PDF
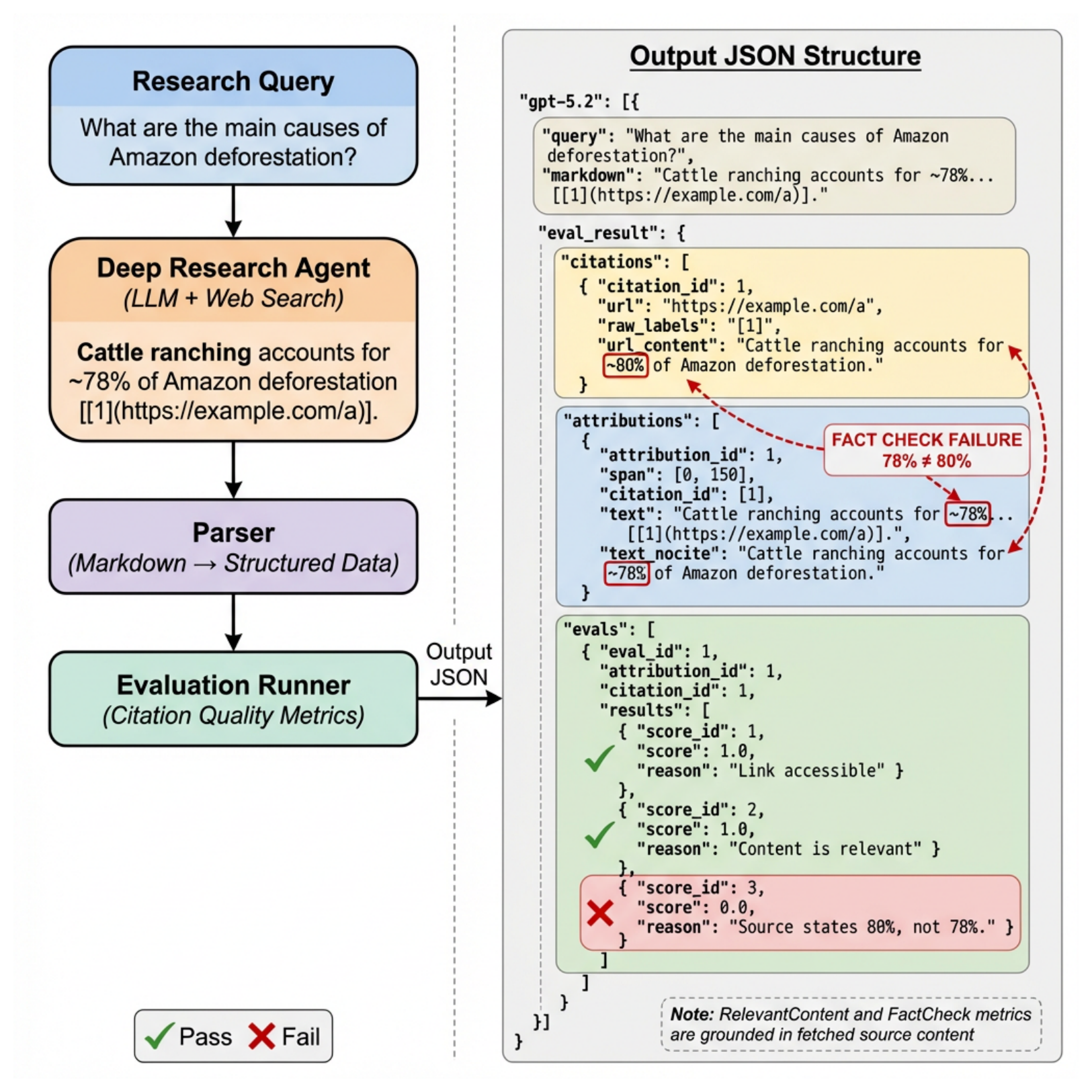
This framework is simple in the right way. A deep research agent writes a Markdown report, an AST parser extracts claim-citation pairs, cited pages are fetched, and each pair is evaluated for link accessibility, topical relevance, and factual support. The important move is that the citation is checked against the actual cited content, not against the model’s confidence or a standalone claim verifier. The caveat is that two of the three dimensions still use LLM judges, even though the authors calibrate Fact Check judgments through manual review.
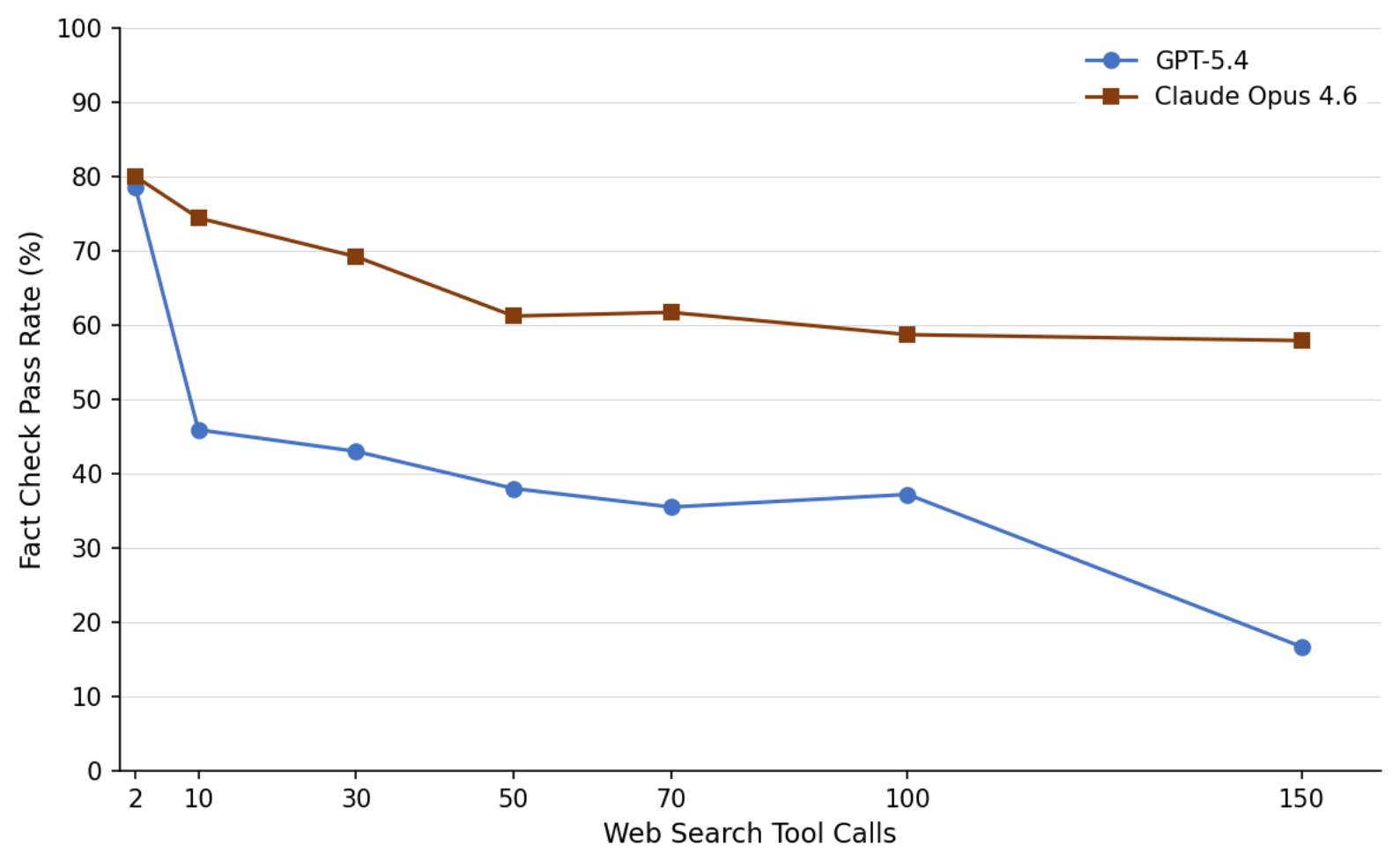
The search-depth curve is the reason this paper belongs in an agent digest. More tool calls do not automatically produce more reliable reports. For both evaluated frontier models, factual support declines as the allowed number of tool calls grows, while working links and topical relevance remain high. This is exactly the kind of failure that looks fine in a browser UI: the links open, the pages are related, and the specific claim is still unsupported.
Quick idea: the paper evaluates deep-research citations at the claim-source level, showing that working, relevant links can still fail to support the facts attached to them.
Why it matters: deep-research agents are easy to trust for the wrong reason. A report with many citations feels auditable, but a citation is only useful if it binds the nearby claim to source evidence. The paper is especially relevant to Paper Radar itself because it treats Markdown reports as structured artifacts, not as prose blobs.
Method walkthrough:
- Generate cited Markdown reports for research queries using web-enabled agents.
- Parse the Markdown into an attribution document using an AST pipeline: canonicalize text, strip code blocks, extract citation nodes, split claims, and attach backward citation references.
- Fetch each cited URL and score each claim-citation pair on three axes: Link Works, Relevant Content, and Fact Check.
- Evaluate 14 models on 130 queries from DeepResearch Bench and BrowseComp, then vary search depth from 2 to 150 tool calls for GPT-5.4 and Claude Opus 4.6.
Evidence:
| Model | Success | Link Works | Relevant Content | Fact Check |
|---|---|---|---|---|
| Claude Opus 4.5 | 90.0% | 98.7% | 95.7% | 76.8% |
| GPT-5.4 | 100.0% | 100.0% | 93.7% | 47.7% |
| GPT-5.2 | 100.0% | 98.3% | 92.3% | 58.8% |
| Claude Sonnet 4.6 | 93.3% | 99.2% | 89.8% | 58.7% |
| GPT-5 Mini | 100.0% | 99.3% | 87.4% | 38.9% |
| Gemini 3.1 Pro | 90.0% | 94.1% | 80.7% | 48.5% |
| OSS-120B | 40.0% | 83.9% | 68.7% | 24.4% |
| Search depth | GPT-5.4 Fact Check | Claude Opus 4.6 Fact Check |
|---|---|---|
| 2 tool calls | 78.6% | 80.0% |
| 50 tool calls | 38.0% | 61.2% |
| 150 tool calls | 16.7% | 57.9% |
The first table is uncomfortable because link metrics look good almost everywhere. Several models produce links that work and point to relevant content, while Fact Check accuracy sits much lower. The second table makes the overload effect concrete: GPT-5.4’s fact support drops sharply as search depth grows, and Claude Opus 4.6 is more resilient but still declines.
Why I care: this is the audit layer I want for research agents. It separates “the link exists” from “the cited source supports this sentence.” That distinction matters for scientific literature reviews, market research, legal research, and any agent report that will be reused by another agent later.
Limitations/questions: the evaluation depends on web accessibility at evaluation time, and URLs can change. Fact Check uses LLM-as-judge after calibration, so the framework is not a final truth oracle. The paper also studies public web search, not private enterprise RAG, where access control, document versions, and internal citations make the problem harder.
Connection to tracked themes: document intelligence, deep-research agents, citation verification, auditable evidence, data agents.
Reading Priority and Next Questions
If I had to read one first, I would start with RAO because recursive delegation is already appearing in real agent products, and the paper gives a training objective rather than only an interface pattern. StraTA is the best follow-up if the question is credit assignment in long agent rollouts. The citation paper is the one I would keep closest to production workflows, because it gives a concrete test for whether a generated research report deserves trust.
Next questions I would track:
- Can strategy quality and delegation quality be verified by environment artifacts rather than model self-judgment or final task score?
- Can recursive agents expose a blame trace that separates bad task splitting from bad child execution and bad synthesis?
- Can citation-level evaluation move from public web pages to private document stores with versioned sources and access controls?
- From the broader shortlist, I would still read STALE, LatentRAG, OBLIQ-Bench, Constraint Decay, and the world-action model papers if the next issue turns back toward memory freshness, retrieval, or world-model reliability.