从路径选择到路由几何
Published:
TL;DR:本期我关注的不是“智能体有没有中间状态”,而是这些中间结构怎样改变决策本身。ToolCUA 研究电脑使用智能体什么时候该继续点 GUI、什么时候该切到工具;DataMaster 把数据工程变成带分支、记忆和反馈的搜索;PriorZero 试图把语言模型先验接入世界模型规划,但只放在 MCTS 根节点;MoE 路由论文则从机理上解释 router 和 expert 为什么会学出共享几何,以及常见 load-balancing loss 可能怎样破坏这种几何。
本期我在看什么
最近几期 Paper Radar 反复写到 trace、state surface、failure attribution。这个方向还重要,但如果每篇都写成“让中间状态可见”,很容易变成同一套话。本期我有意选了四篇更偏“控制面”的论文:一个是 GUI/工具路径选择,一个是数据侧搜索树,一个是语言先验和世界模型的接口,一个是 MoE 内部路由几何。
图表上我也做了一个小调整:方法图和关键曲线直接展示论文图,密集小字表格则改写成 Markdown 表格,尽量让读者在网页里能读清数字,而不是看一张缩小后的截图。
论文细读笔记
ToolCUA:电脑使用智能体什么时候该点屏幕,什么时候该调用工具
作者:Xuhao Hu、Xi Zhang、Haiyang Xu、Kyle Qiao、Jingyi Yang、Xuanjing Huang、Jing Shao、Ming Yan、Jieping Ye
机构:Tongyi Lab, Alibaba Group;Fudan University;Shanghai Artificial Intelligence Laboratory
日期:2026-05-12
链接:arXiv,arXiv HTML,代码
一句话核心 idea:ToolCUA 把 computer-use agent 看成混合动作空间里的路径选择问题。模型不仅要会点击、输入、截图,也要会调用应用 API 或 MCP 工具;真正难的是知道什么时候切换。
为什么重要:很多电脑使用评测默认动作接口是固定的,但真实工作流不是这样。处理表格时,读取工作簿信息可能比鼠标操作更可靠;确认视觉状态时,GUI 截图仍然必要。ToolCUA 的价值在于把“走 GUI 还是走工具”变成一个可训练的决策,而不是把工具简单塞进 prompt。
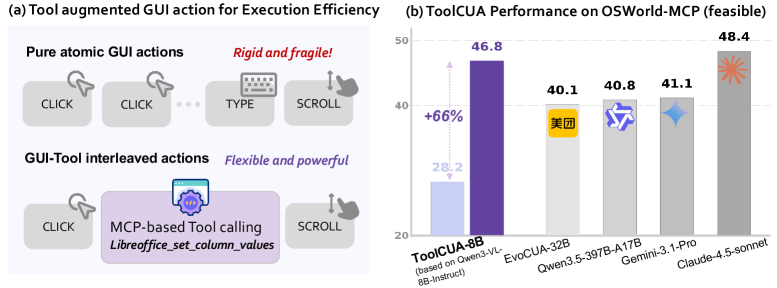
这张图先说明一个反直觉事实:把工具暴露给模型,不一定让模型变强。论文里多个强 GUI agent 加上工具后反而变差,说明模型可能乱用工具,也可能在该用工具时仍然留在 GUI 路径。ToolCUA 的提升来自专门训练路径选择;但要谨慎的是,OSWorld-MCP 仍是构造出来的混合环境,不等于所有真实桌面任务都会自动受益。
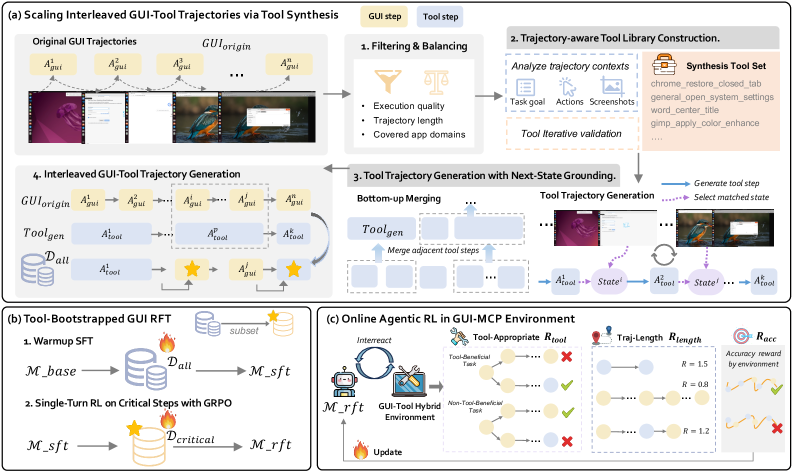
方法分三步。第一步从已有静态 GUI 轨迹里合成 GUI-tool interleaved trajectories,并构造有 grounding 的工具库。第二步先对全部 interleaved 数据做 warmup SFT,再在关键切换步骤上做单轮 GRPO,让模型专门学习“继续 GUI 还是调用工具”。第三步进入在线 agentic RL,用 tool-efficient path reward 同时奖励成功、工具使用是否合适、路径是否更短。
这个 reward 是论文的关键。总奖励由格式、任务成功、工具合适性和路径长度组成。工具项只在成功轨迹上激活:如果任务被标为 tool-beneficial,就要求至少调用一次工具;如果任务不需要工具,就奖励不调用工具。这样可以避免一种很常见的错觉:模型因为最后完成了任务,就把中间所有多余工具调用都当成好行为。
论文报告的部分结果如下:
| 设置 | Accuracy | Tool invocation rate | Avg completion steps |
|---|---|---|---|
| Qwen3-VL-8B-Instruct on OSWorld-MCP | 28.23 | 8.41 | 19.34 |
| ToolCUA-8B on OSWorld-MCP | 46.85 | 24.32 | 14.93 |
| ToolCUA-8B on WindowsAgentArena | 33.8 | 未报告 | 未报告 |
| Qwen3-VL-8B-Instruct on WindowsAgentArena | 26.4 | 未报告 | 未报告 |
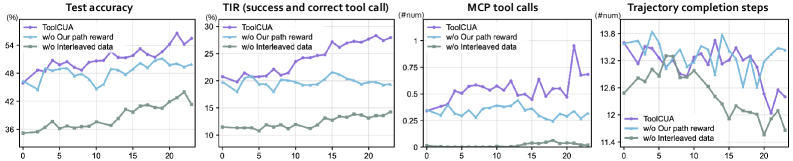
我最关注的是这张消融曲线。没有 interleaved data,在线 RL 很难只靠稀疏反馈学出稳定工具调用;没有 path reward,模型虽然见过工具,但路径选择不稳。这里的启发很直接:agentic RL 不会自动发现你想要的控制策略,reward 必须明确命中错误类型。
我的判断:ToolCUA 值得继续看,因为它问的是部署时真会遇到的问题。未来电脑使用系统大概率会混用截图、GUI 动作、shell、应用 API、文档解析器和远端服务。论文的弱点是仍依赖 task-level tool-beneficial 标签和合成工具库;我更想看到它在动态企业工具目录里是否仍有效,因为那里的工具会重叠、失败、变慢,也可能返回过期状态。
对应主题:agentic training、GUI agents、tool orchestration、可审计执行路径。
DataMaster:把数据工程变成智能体搜索树
作者:Yaxin Du、Xiyuan Yang、Zhifan Zhou、Wanxu Liu、Zixing Lei、Zimeng Chen、Fenyi Liu、Haotian Wu、Yuzhu Cai、Zexi Liu、Xinyu Zhu、Wenhao Wang、Linfeng Zhang、Chen Qian、Siheng Chen
机构:Shanghai Jiao Tong University;Carnegie Mellon University;Zhejiang University;Beijing University of Aeronautics and Astronautics
日期:2026-05-11
链接:arXiv,arXiv HTML,代码
一句话核心 idea:DataMaster 不让智能体去改模型结构或训练代码,而是只优化数据侧:找外部数据、筛选、组合、清洗、转换,再通过下游训练反馈判断是否真的变好。
为什么重要:现实 ML 项目里,大量提升来自数据工程,但很多 agent benchmark 仍在奖励代码生成、工具调用或最后答案。DataMaster 有意思的地方是把数据工程看成带分支状态、共享候选数据和延迟反馈的搜索问题。
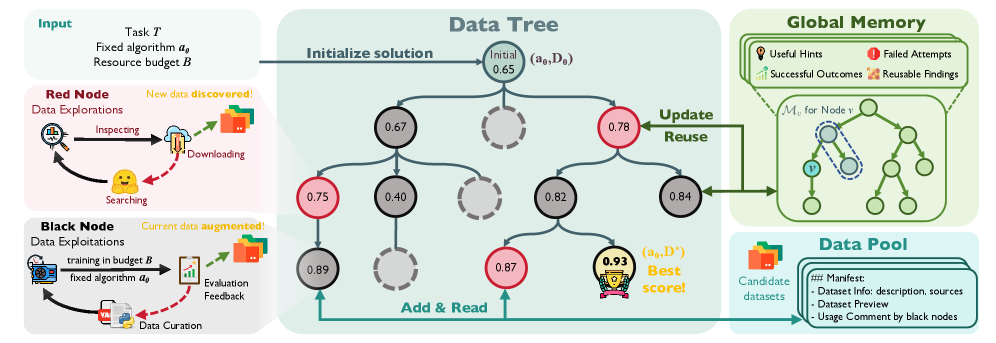
核心结构是 DataTree。红节点负责拓宽搜索,发现外部数据并写入共享 Data Pool;黑节点负责利用已有候选,构造可执行的数据状态,并通过固定训练流程拿到反馈;Global Memory 记录节点结果、工件和可复用发现,避免后续分支反复踩同一个坑。
它的优化目标很朴素:给定任务、初始算法和初始数据,在预算内找到更好的数据状态。具体到节点动作,可以是找公开数据、清洗字段、合并来源、构造变体、修改 split,最后必须通过训练和验证指标来判断有没有收益。
论文报告的主结果摘录如下:
| 系统 | MLE-Bench Lite medal rate | MLE-Bench Lite gold rate | PostTrainBench avg |
|---|---|---|---|
| Initial score | 35.91% | 22.73% | 8.47% |
| Codex baseline | 22.73% | 18.18% | 18.46% |
| DatasetResearcher | 59.09% | 27.27% | 8.50% |
| ML-Master 2.0 | 40.91% | 27.27% | 15.69% |
| DataMaster | 68.18% | 45.45% | 31.17% |
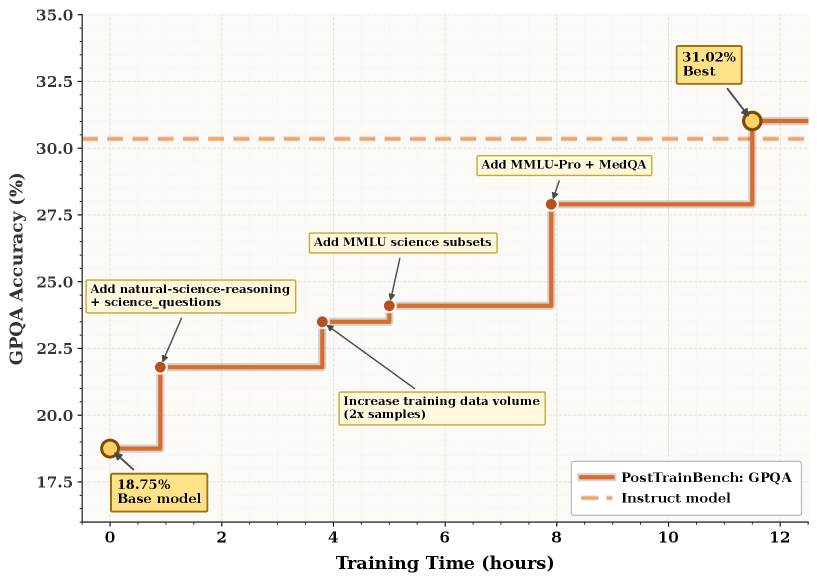
这张 test-time scaling 曲线说明 DataMaster 不是一次性清洗脚本。随着 wall-clock budget 增加,PostTrainBench 上的 best-node score 继续提升,说明分支搜索和反馈循环确实在发挥作用。需要谨慎的是成本:数据 agent 往往要跑工具、训练、评估,延迟和费用本身就是系统设计的一部分。
组件消融更能说明哪些部分不是装饰:
| 禁用组件 | Best medal rate | Best gold rate | Overcome rate |
|---|---|---|---|
| 无红节点 | 80% | 70% | 72.40% |
| 无黑节点 | 70% | 50% | 52.41% |
| 无 memory | 50% | 20% | 28.57% |
| 完整 DataMaster | 90% | 80% | 69.96% |
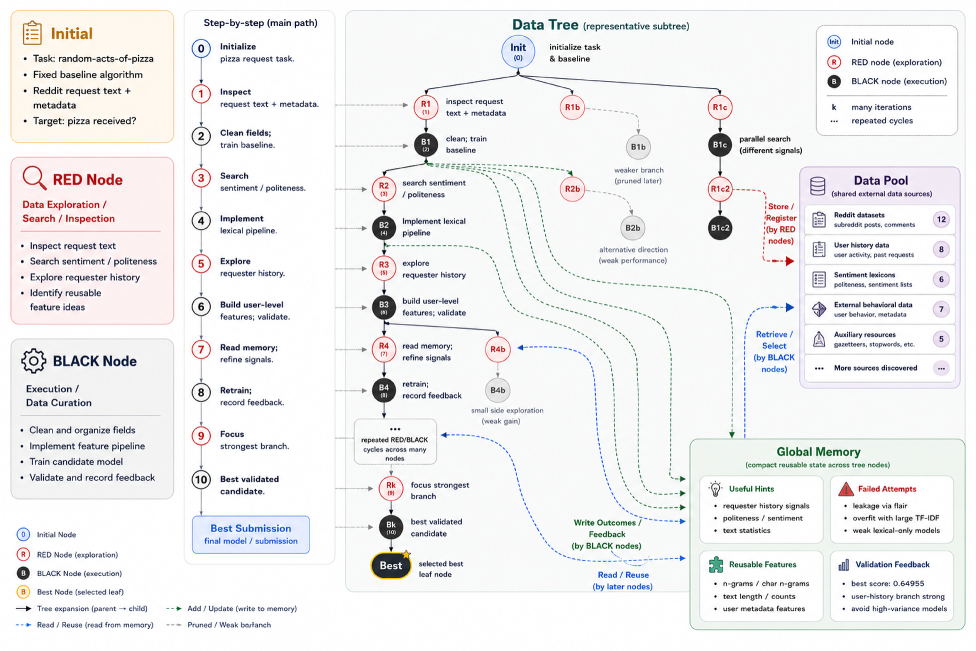
这个 case walkthrough 让我觉得这篇不只是系统堆叠。它展示了 agent 如何记录尝试、数据来源、转换和下游反馈,而不是只说“我用了一个更好的数据集”。但同一张图也暴露风险:如果 provenance 不够强,外部数据和多轮转换叠在一起,后续很难判断提升来自真实泛化、数据泄漏还是过拟合。
我的判断:DataMaster 是本期最贴近 data agent 的论文。我不会把 leaderboard gain 当作唯一贡献,更重要的是它把数据侧优化变成可搜索、可记忆、可反馈的过程。下一步我更关心它能否生成足够清楚的 provenance log,让人类工程师可以复现、审查、回滚,并检查是否存在泄漏。
对应主题:data agents、autonomous ML、搜索树、记忆、数据溯源。
PriorZero:语言先验只进 MCTS 根节点
作者:Junyu Xiong、Yuan Pu、Jia Tang、Yazhe Niu
机构:University of Science and Technology of China;Shanghai Artificial Intelligence Laboratory;Nanjing University of Aeronautics and Astronautics;The Chinese University of Hong Kong MMLab
日期:2026-05-12
链接:arXiv,arXiv HTML,代码
一句话核心 idea:PriorZero 想把 LLM 的语义先验用于强化学习,但不把 LLM 当 dynamics model,也不直接把它变成端到端策略。LLM 只影响 MCTS 根节点,后续 rollout、value 和 policy 学习仍交给世界模型。
为什么重要:语言模型确实有常识和语义知识,但它的先验可能过时、静态、和环境动力学不匹配。让 LLM 直接动作,可能无法适应具体环境;对 LLM 做稀疏奖励端到端 RL,又会遇到信用分配和稳定性问题。PriorZero 的折中是:让语言先验帮助第一步搜索聚焦,然后让世界模型负责多步 lookahead。
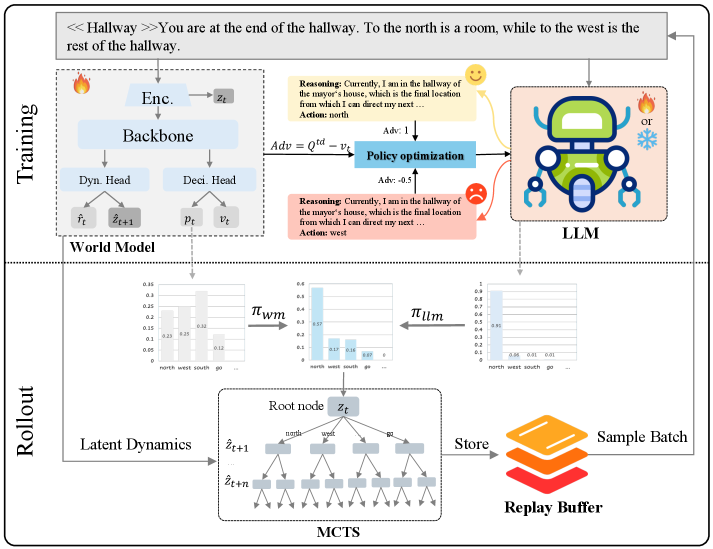
系统里有两个梯度解耦的模块。rollout 时,LLM 根据当前观察和历史给 admissible action strings 打分,然后它的动作分布只在 MCTS 根节点与世界模型 policy 融合;非根节点完全依赖世界模型。训练时,世界模型用交互数据更新 dynamics、value 和 policy,再用 value estimate 构造 advantage,交替微调 LLM。
这里最关键的是 root-only injection。如果把 LLM prior 注入整棵搜索树,它可能盖过学到的环境动力学;如果完全不更新 LLM,它又只是静态提示。PriorZero 想保留先验的适应性,同时不让先验变成模拟器。

Jericho 实验比较 PriorZero 和 UniZero 在四个文字游戏环境上的表现。论文报告 acorncourt 和 omniquest 里 PriorZero 更快进入高回报区域,detective 里后期超过 UniZero,zork1 里最终回报更高。考虑到这些环境奖励稀疏,这组曲线支持了一个直觉:在世界模型还没学清楚之前,语义先验能帮搜索少走一些显然没意义的循环。
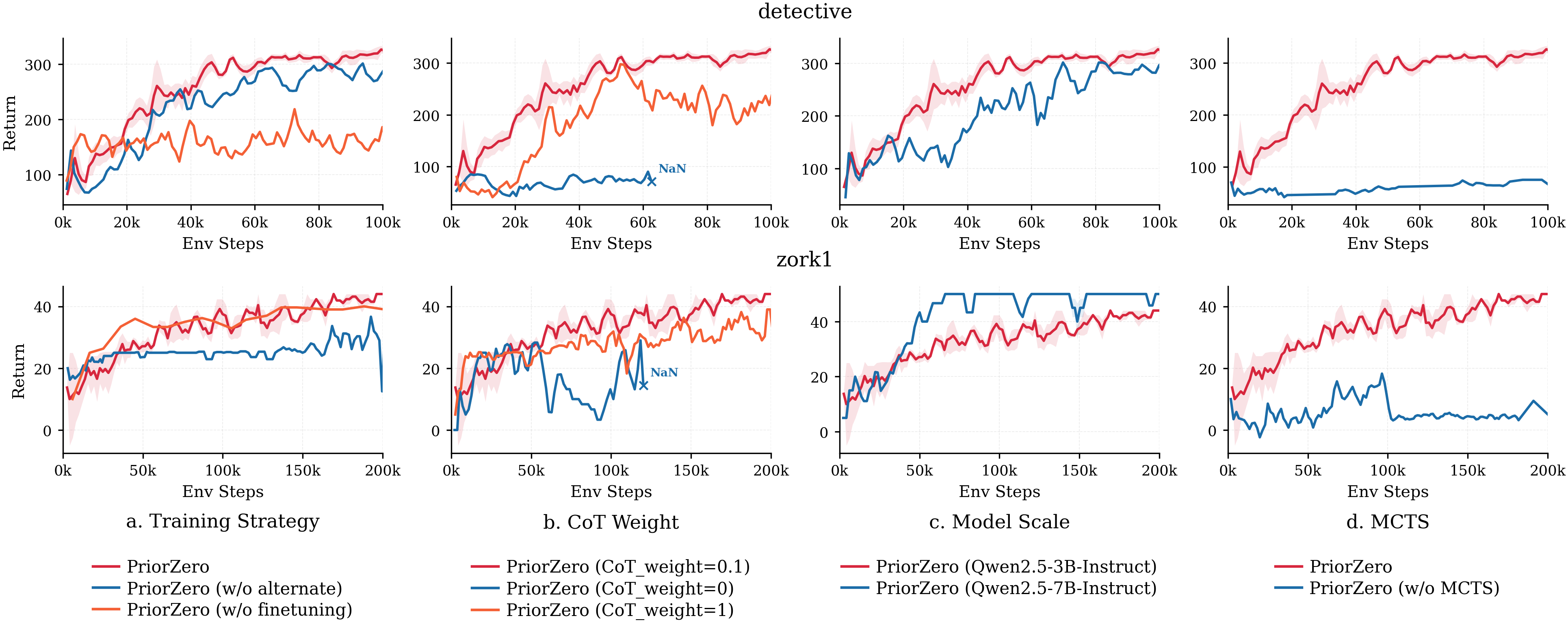
消融测试了几个设计点:交替训练、CoT prior extraction、LLM 容量、MCTS lookahead。我把这组结果理解为“脆弱但有意义的协作”,而不是万能 recipe。LLM prior、world-model planner 和 alternating schedule 必须配合;拆掉任何一部分,曲线都没那么稳。
部分实现和评测设置如下:
| 细节 | Jericho 设置 | BabyAI 设置 |
|---|---|---|
| LLM model | Qwen2.5-3B-Instruct | Qwen2.5-7B-Instruct |
| Action space size | 10-100+ | 3-15 high-level actions |
| Max episode steps | 50-500 | 20 |
| MCTS sims for collection | 25 | 25 |
| MCTS sims for evaluation | 25 | 50 |
| Fusion weight alpha | 0.5 | 0.5 |
我的判断:PriorZero 有价值的地方,是它没有把语言先验和世界模型混成同一个东西。真正需要继续追的问题是 uncertainty:什么时候系统应该降低 LLM fusion weight,因为这个先验虽然语义上合理,但动态上是错的?我也想看到它从文字游戏和 BabyAI 走向更复杂动作空间之后是否仍然稳定。
对应主题:world models、agentic RL、语言先验、MCTS、稀疏奖励规划。
Routers Learn the Geometry of Their Experts:MoE router 和 expert 共同学出几何
作者:Sagi Ahrac、Noya Hochwald、Mor Geva
机构:Blavatnik School of Computer Science and AI, Tel Aviv University
日期:2026-05-12
链接:arXiv,arXiv HTML
一句话核心 idea:在 sparse MoE 语言模型里,router 和 expert 不是彼此独立的模块。论文证明,被选中的 router direction 和对应 expert 的 input-side weights 会沿同一个 hidden-state 方向接收梯度,因此会共同累积被路由到该 expert 的 token history。
为什么重要:MoE 常被当作扩展参数量和降低推理成本的工程结构来讨论,但训练稳定性、expert collapse 和 load balancing 一直很难。本文问的是更机理的问题:router 到底学到了什么?常见 auxiliary load-balancing loss 会不会破坏它本来该学的结构?
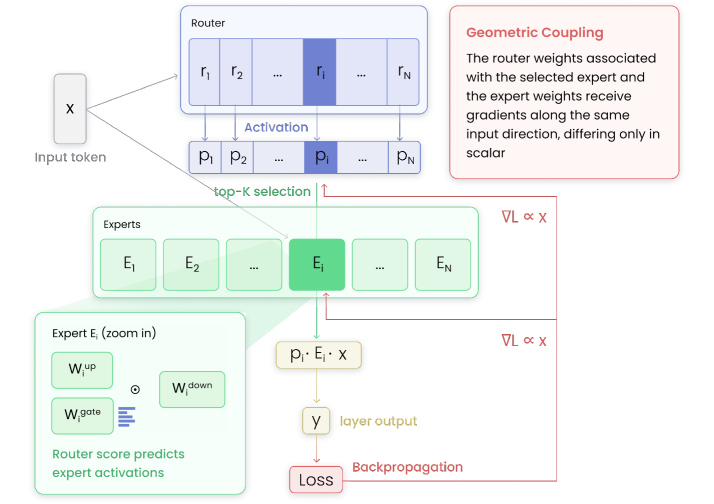
主图展示了论文的核心机制。对一个被选中的 expert,router vector 和 expert input-side weights 的更新方向都与同一个 token hidden state 成比例。训练久了,匹配的 router 和 expert 就会变成一类 routed-token geometry 的共同摘要。这里不是类比,论文在梯度表达式里直接推出了共同输入方向。
简化后的形式是:
expert row update ~= delta_i,k * x
router vector update ~= gamma_i * x
两个标量不同,但方向都沿 hidden state x。因此 router 不只是 dispatch table,而是在累积被分配 token 的几何信息。
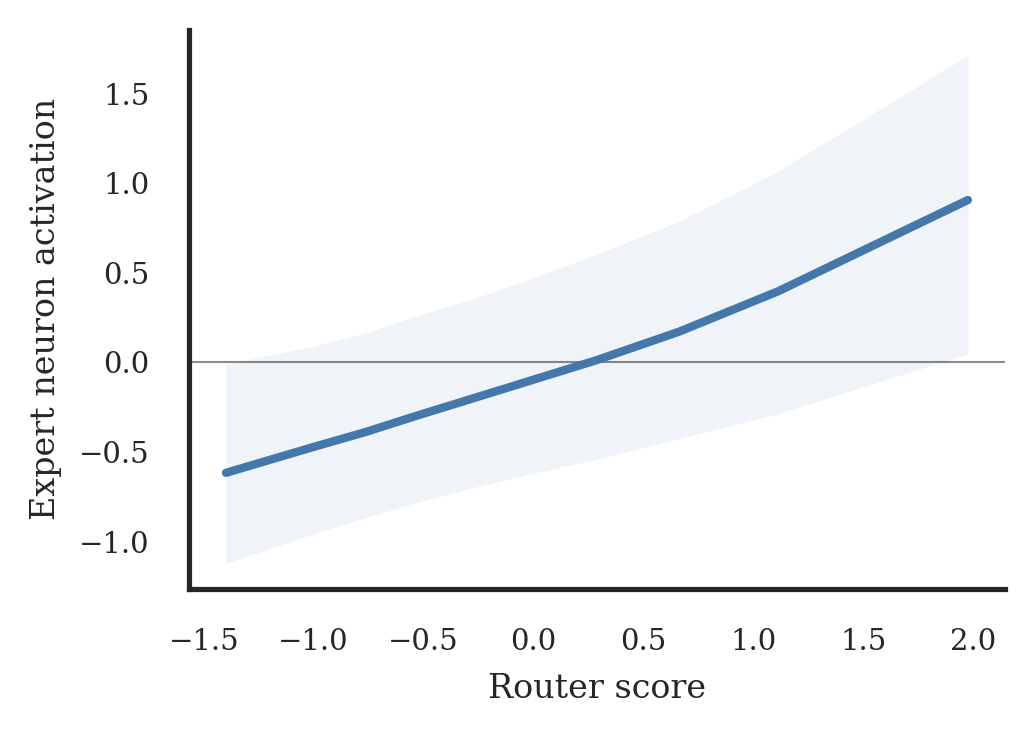
经验验证也很直接。作者在一个从头训练的 1B SMoE 上,比较 routed token-expert pair 的 raw router score 和同一 expert gate neurons 的平均激活。论文报告在按 layer 和 expert 归一化后,相关系数 rho = 0.43,p = 1.2e-81。这不能证明每个 expert 都有清晰语义,但说明 router 偏好确实会在 expert 内部计算中留下对应信号。
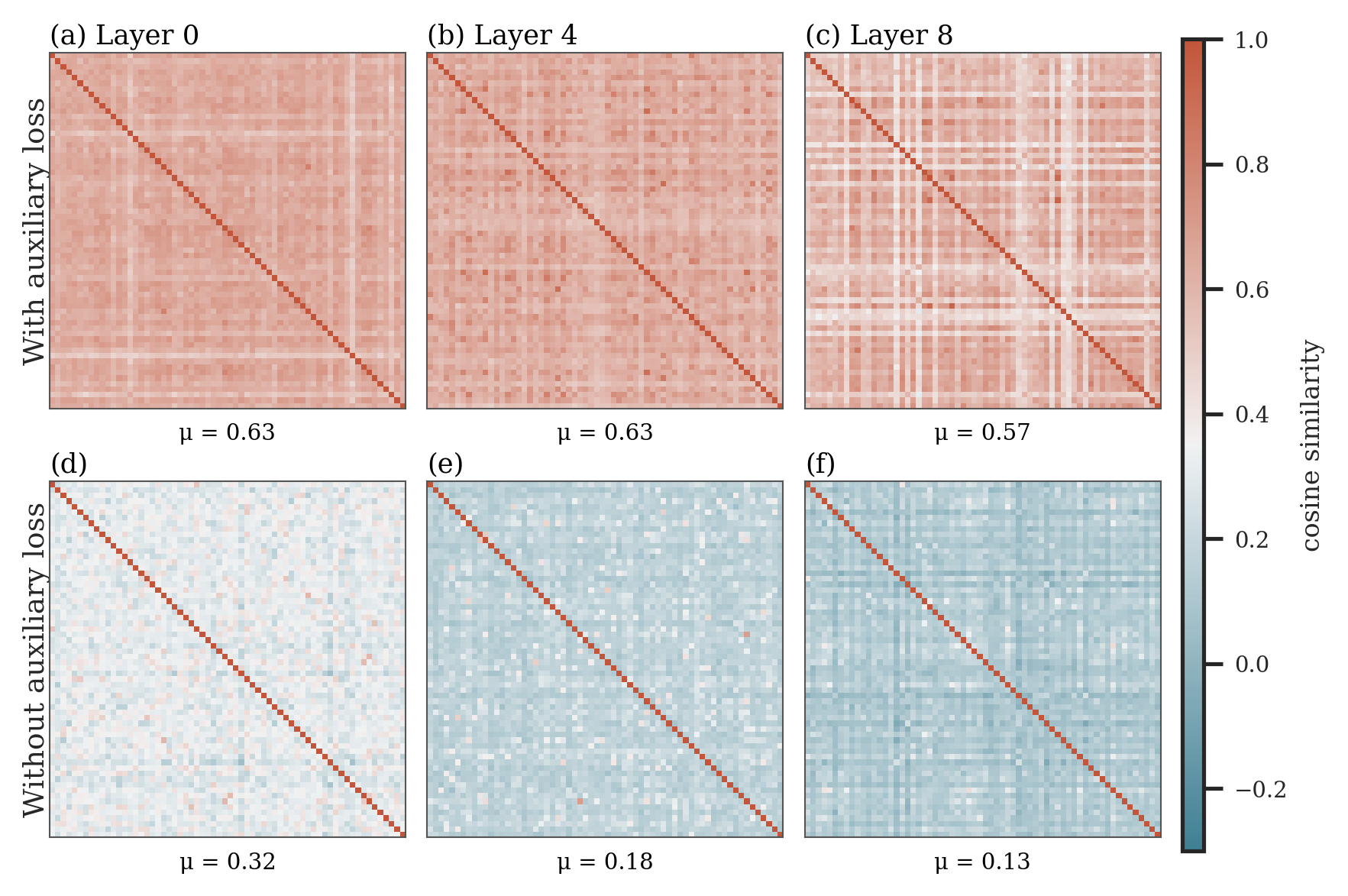
这张热力图是全文最像警告的一张。使用 auxiliary load-balancing loss 时,router vectors 彼此更相似;不让 balancing gradient 进入 router 时,同样架构保持了更分散的 router directions。论文报告在 layers 0、4、8 上,auxiliary loss 下 off-diagonal mean cosine similarity 分别约为 0.63、0.63、0.57,而 loss-free bias balancing 下约为 0.32、0.18、0.13。
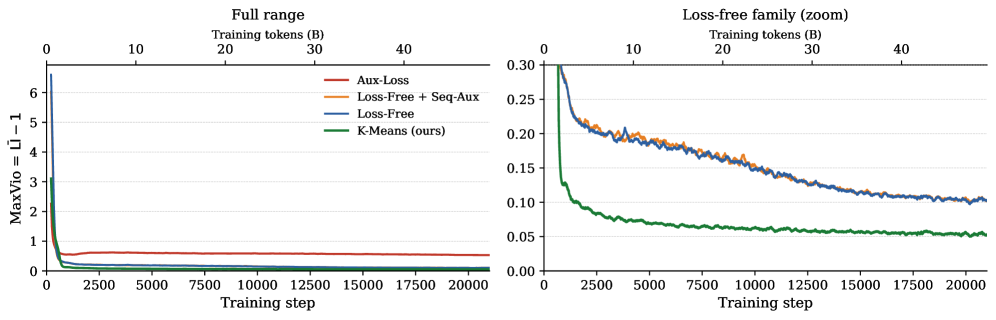
最后一个实验用非可训练的 online K-Means centroids 取代 trainable router weights。每个 expert 维护被路由 hidden states 的指数滑动平均,token 按 cosine similarity 分配。这个 parameter-free router 得到最低的 load imbalance,但 perplexity 有小幅代价。我不会把它理解成“所有人都该立刻换 router”,更像是证据:centroid-like routed-token geometry 解释了 learned router 的相当一部分功能。
论文报告的对比如下:
| Router variant | Router params | Auxiliary losses | Train PPL | C4-en PPL | Pile PPL | MaxVio |
|---|---|---|---|---|---|---|
| Aux-Loss | 0.59M | load balance + z | 15.09 | 20.54 | 11.82 | 0.526 |
| Loss-Free + Seq-Aux | 0.59M | seq-aux | 15.03 | 20.44 | 11.77 | 0.102 |
| Loss-Free | 0.59M | none | 15.01 | 20.40 | 11.76 | 0.084 |
| K-Means router | 0 | none | 15.40 | 21.01 | 12.09 | 0.037 |
我的判断:这是本周我最想保留的机理论文。它有清楚的局部 claim、有推导、有模型内部测量,也有一个 intervention-style 的 router。限制也明显:主要实验是 1B 规模,生产级 MoE 的 router 规则、expert 数、数据混合和 balancing 策略都可能不同,不能直接外推。
对应主题:大模型机理、MoE routing、训练稳定性、模型内部可解释性。
阅读优先级和下期问题
我的优先级是 ToolCUA、DataMaster、MoE 路由论文,然后是 PriorZero。ToolCUA 最贴近 computer-use agent 的真实部署问题;DataMaster 对 data agent 很重要,但需要重点审查 provenance;MoE 论文是很扎实的机理线索;PriorZero 方向有潜力,不过我希望看到更复杂环境中的证据。
下期我会继续追这几个问题:
- GUI-tool agent 能不能在线学习“什么时候工具有益”,而不是依赖数据构造时给的标签?
- 数据工程 agent 能不能留下足够强的 provenance log,支持泄漏检查、人类复审和回滚?
- 世界模型里的语言先验融合能不能根据不确定性动态调节,而不是固定 alpha?
- MoE 的 load-balancing objective 能不能既避免 expert starvation,又不破坏 router-expert geometry?