Path Choices, Data Search, and Routing Geometry
Published:
TL;DR: this round is about decision surfaces inside systems that look agentic from the outside. ToolCUA asks when a computer-use agent should stay with GUI actions and when it should call a tool. DataMaster treats data engineering as a branching search problem rather than a one-shot preprocessing step. PriorZero tries to use language priors without letting them corrupt a learned world model. The MoE routing paper is more mechanistic: it argues that routers and experts learn a shared geometry, and that common load-balancing losses can damage it.
What I Am Watching This Round
The last few Paper Radar issues leaned heavily on trace inspection, state surfaces, and failure attribution. That thread is still useful, but it can become repetitive if every paper is framed as “make the intermediate state visible.” This time I looked for papers where the intermediate object changes the actual control problem: a path decision in a GUI-tool environment, a branching data search tree, a language prior fused only at the root of a planner, and an MoE router whose learned geometry affects training stability.
I also tried to be stricter about visuals. I use paper figures for system structure and curves, but for dense result tables I extract the rows into Markdown tables so the numbers are readable on the site.
Paper Notes
ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
Authors: Xuhao Hu, Xi Zhang, Haiyang Xu, Kyle Qiao, Jingyi Yang, Xuanjing Huang, Jing Shao, Ming Yan, Jieping Ye
Institutions: Tongyi Lab, Alibaba Group; Fudan University; Shanghai Artificial Intelligence Laboratory
Date: May 12, 2026
Links: arXiv, arXiv HTML, code
Quick idea: ToolCUA treats computer-use as a hybrid action problem. The agent should not merely know how to click and how to call APIs; it must learn when the tool path is better than the GUI path, and when tool use is noise.
Why it matters: current computer-use agents are often evaluated as if the action interface were fixed. Real desktop work is messier. A spreadsheet task may be easier through a LibreOffice MCP call; a visual confirmation step may still require screenshots and clicking. The paper’s useful move is to make path selection itself trainable.
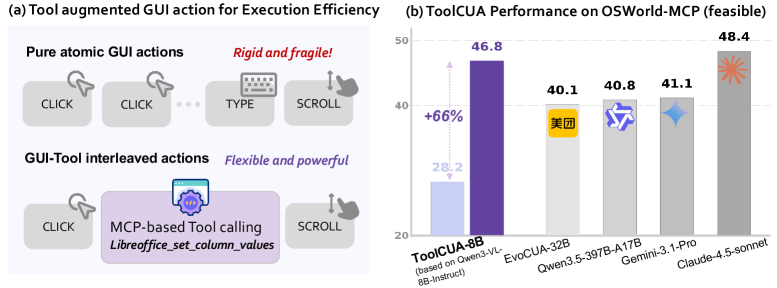
This overview makes the paper’s starting point concrete: exposing a model to tools does not automatically improve the trajectory. Several strong GUI agents get worse when tools are simply added, while ToolCUA is the model that improves under the hybrid action space. The caveat is that this is still a constructed OSWorld-MCP setting, so I would not read the result as a general proof that tools always help computer-use agents.
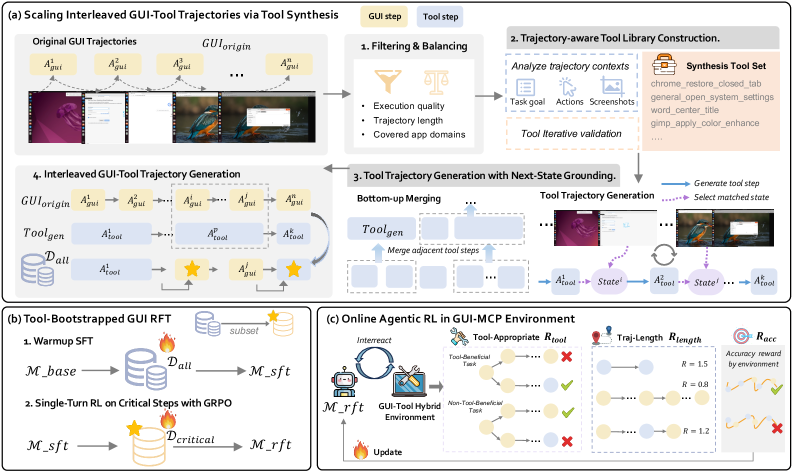
The method has three steps. First, the authors synthesize interleaved GUI-tool trajectories from static GUI data by building a grounded tool library. Second, they run warmup SFT on all interleaved data and single-turn GRPO on critical switching steps, where the model must choose between continuing with GUI actions or calling a tool. Third, online agentic RL adds a tool-efficient path reward: successful trajectories get extra reward when tools are used on tool-beneficial tasks, avoided on non-tool-beneficial tasks, and completed in fewer steps.
The reward is worth spelling out because it is the paper’s main control signal. The trajectory reward combines format, task accuracy, tool appropriateness, and path length. The tool term is active only on successful trajectories, and checks whether a task labeled as tool-beneficial actually used at least one tool, or a non-tool-beneficial task used none. That avoids rewarding gratuitous API use just because the final answer happened to be right.
Selected reported results:
| Setting | Accuracy | Tool invocation rate | Avg completion steps |
|---|---|---|---|
| Qwen3-VL-8B-Instruct on OSWorld-MCP | 28.23 | 8.41 | 19.34 |
| ToolCUA-8B on OSWorld-MCP | 46.85 | 24.32 | 14.93 |
| ToolCUA-8B on WindowsAgentArena | 33.8 | not reported | not reported |
| Qwen3-VL-8B-Instruct on WindowsAgentArena | 26.4 | not reported | not reported |
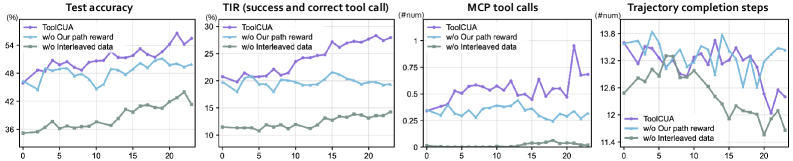
The ablation curve is the figure I would keep in mind. Without interleaved data, online RL does not reliably discover tool use from sparse feedback; without the path reward, the agent has tool knowledge but does not learn a stable switching policy. This is a good reminder that “agentic RL” is not magic: the reward has to name the control mistake you care about.
My read: ToolCUA is useful because it asks a deployable question. A future computer-use stack will almost certainly mix screenshots, GUI actions, shell commands, app APIs, and document parsers. The weak point is that the paper still depends on task-level tool-beneficial labels and synthesized tool libraries; I would want to see whether the same approach survives a dynamic enterprise tool catalog where tools fail, overlap, or return stale state.
Connection to tracked themes: agentic training, GUI agents, tool orchestration, and auditable execution paths.
DataMaster: Towards Autonomous Data Engineering for Machine Learning
Authors: Yaxin Du, Xiyuan Yang, Zhifan Zhou, Wanxu Liu, Zixing Lei, Zimeng Chen, Fenyi Liu, Haotian Wu, Yuzhu Cai, Zexi Liu, Xinyu Zhu, Wenhao Wang, Linfeng Zhang, Chen Qian, Siheng Chen
Institutions: Shanghai Jiao Tong University; Carnegie Mellon University; Zhejiang University; Beijing University of Aeronautics and Astronautics
Date: May 11, 2026
Links: arXiv, arXiv HTML, code
Quick idea: DataMaster makes the data side of ML optimization agentic. Instead of editing the model or training code, the agent searches for, selects, transforms, and validates data while keeping the downstream algorithm fixed.
Why it matters: a lot of practical ML progress comes from data work, but most agent benchmarks still reward code generation, tool execution, or final answers. DataMaster is interesting because it treats data engineering as a search space with branch-local state, shared discovered sources, and delayed feedback from downstream training.
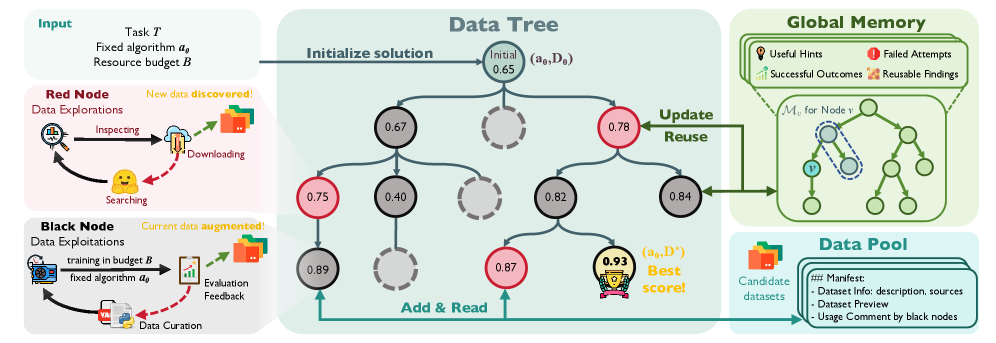
The core abstraction is a DataTree. Red nodes broaden the search by discovering external datasets and placing them into a shared Data Pool. Black nodes exploit the available candidates by building executable data states and evaluating them through the fixed downstream training pipeline. Global Memory stores artifacts, outcomes, and reusable observations so later branches do not start from scratch.
The concrete optimization target is simple: given a task, an initial algorithm, and a starting data state, find a data state that maximizes downstream evaluation under a budget. In practice, that means a node may search public data, clean fields, merge sources, create synthetic variants, or modify splits, then measure whether the resulting training run actually improves.
Selected reported results:
| System | MLE-Bench Lite medal rate | MLE-Bench Lite gold rate | PostTrainBench avg |
|---|---|---|---|
| Initial score | 35.91% | 22.73% | 8.47% |
| Codex baseline | 22.73% | 18.18% | 18.46% |
| DatasetResearcher | 59.09% | 27.27% | 8.50% |
| ML-Master 2.0 | 40.91% | 27.27% | 15.69% |
| DataMaster | 68.18% | 45.45% | 31.17% |
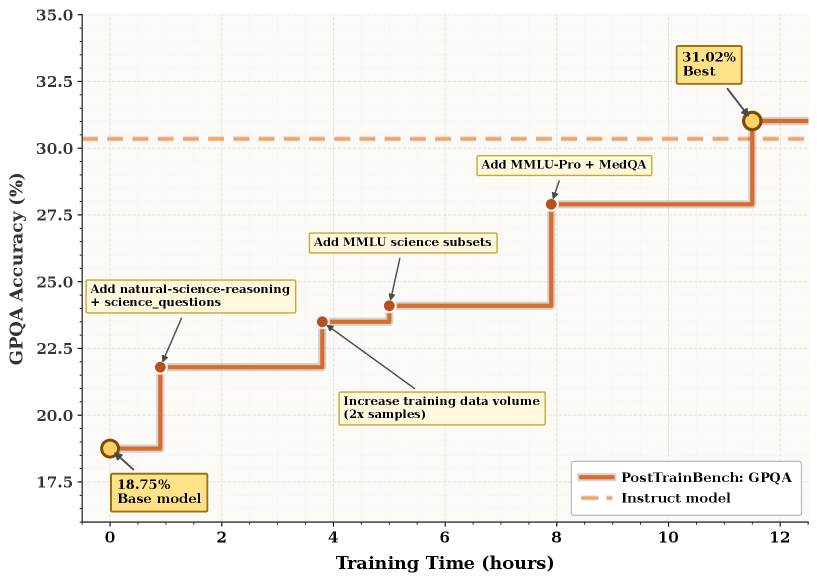
The scaling curve is useful because the system is expensive and search-heavy. The best-node score keeps improving with wall-clock budget on PostTrainBench, which supports the authors’ claim that this is not just a one-pass data-cleaning script. The caveat is cost: a serious data-agent loop spends time running tools and training pipelines, so “more budget helps” is only useful if the user can afford the latency.
The component ablation is the clearest evidence that the abstraction is not decorative:
| Disabled component | Best medal rate | Best gold rate | Overcome rate |
|---|---|---|---|
| No red nodes | 80% | 70% | 72.40% |
| No black nodes | 70% | 50% | 52.41% |
| No memory | 50% | 20% | 28.57% |
| Full DataMaster | 90% | 80% | 69.96% |
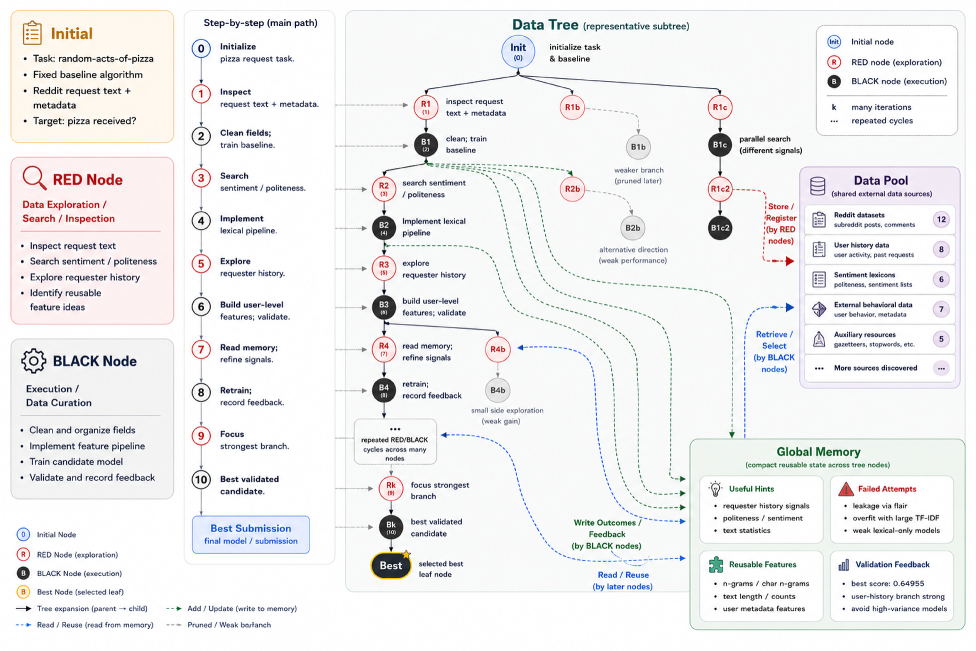
This case walkthrough shows why I like the paper despite the large system surface. The agent is not only “using a dataset”; it is building a record of attempts, data sources, transformations, and downstream feedback. The figure also exposes the risk: without very careful provenance, a data agent can make improvements hard to audit, especially when external sources and repeated transformations accumulate over many branches.
My read: DataMaster is a strong data-agent paper because it moves from answer generation to experimental data work. I would not take the leaderboard gains alone as the main contribution. The important question is whether data-side search can leave behind a provenance trail that a human ML engineer can review, reproduce, and reject when the gain comes from leakage or overfitting.
Connection to tracked themes: data agents, autonomous ML, search trees, memory, and data provenance.
PriorZero: Bridging Language Priors and World Models for Decision Making
Authors: Junyu Xiong, Yuan Pu, Jia Tang, Yazhe Niu
Institutions: University of Science and Technology of China; Shanghai Artificial Intelligence Laboratory; Nanjing University of Aeronautics and Astronautics; The Chinese University of Hong Kong MMLab
Date: May 12, 2026
Links: arXiv, arXiv HTML, code
Quick idea: PriorZero tries to use an LLM as a semantic prior for reinforcement learning without turning the LLM into the dynamics model or an end-to-end policy. The LLM influences only the root of MCTS, while the learned world model handles rollout, value, and policy learning.
Why it matters: language priors can help in sparse-reward environments, but they are also stale and brittle. If the LLM directly acts as the policy, it may not adapt to environment dynamics. If it is fine-tuned end to end under sparse rewards, credit assignment becomes unstable. PriorZero’s design is a compromise: let language focus the first branch of search, then let the world model do the multi-step lookahead.
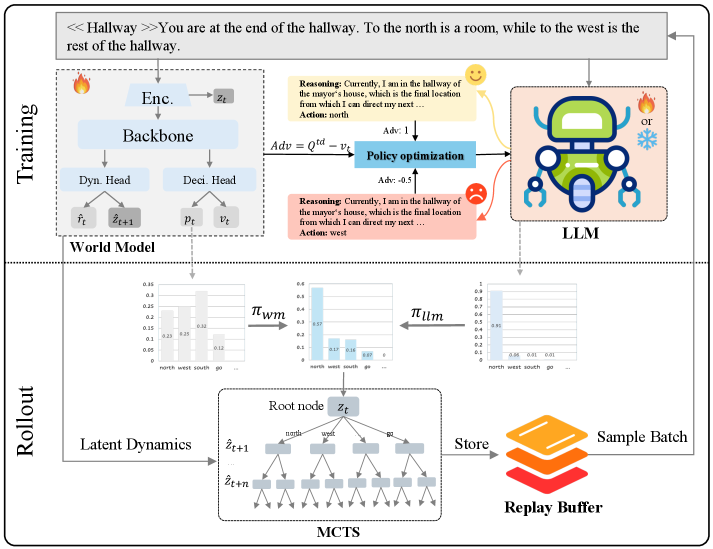
The method has two gradient-decoupled modules. During rollout, the LLM scores admissible action strings from the current observation and history, and its action distribution is fused with the world-model policy only at the MCTS root. At non-root search nodes, MCTS relies on the world model. During training, the world model is updated on interaction data, and its value estimates create advantage signals for alternating LLM fine-tuning.
The root-only fusion is the design detail I care about. If the LLM prior were injected throughout the search tree, it could drown out learned transition dynamics. If it were never updated, it would remain a static hint. PriorZero tries to keep the prior adaptive while preventing it from becoming the simulator.

The Jericho results compare PriorZero to UniZero across four text-game environments. The paper reports faster progress in acorncourt and omniquest, later gains in detective, and a higher asymptotic return in zork1. Since these are sparse-reward interactive tasks, the result supports the claim that semantic priors can focus exploration before a world model has learned enough.
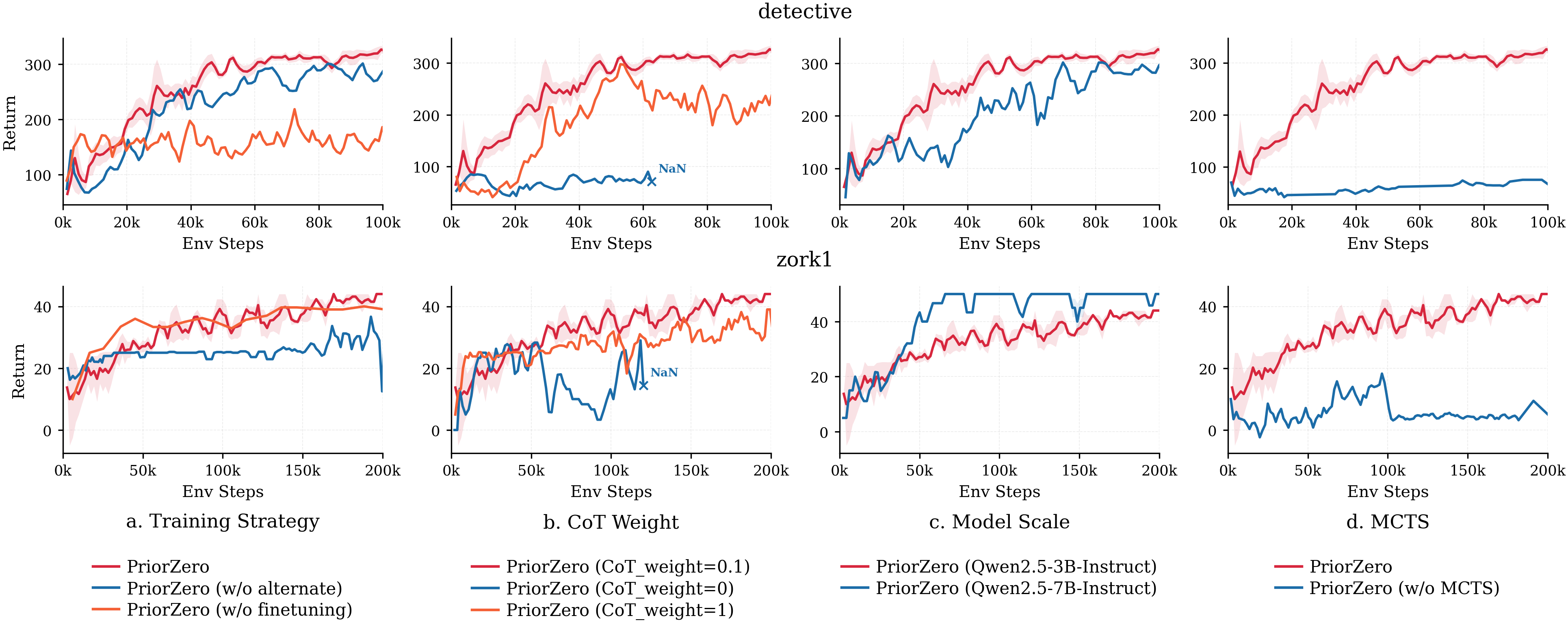
The ablations test whether the main design choices matter: alternating training, chain-of-thought prior extraction, LLM capacity, and MCTS lookahead. I read this as evidence for a fragile balance rather than a universal recipe. The method needs the LLM prior, the world-model planner, and the alternating schedule to cooperate; remove one part and the curves become less convincing.
Selected implementation and benchmark details:
| Detail | Jericho setting | BabyAI setting |
|---|---|---|
| LLM model | Qwen2.5-3B-Instruct | Qwen2.5-7B-Instruct |
| Action space size | 10-100+ | 3-15 high-level actions |
| Max episode steps | 50-500 | 20 |
| MCTS simulations for collection | 25 | 25 |
| MCTS simulations for evaluation | 25 | 50 |
| Fusion weight alpha | 0.5 | 0.5 |
My read: PriorZero is a useful world-model paper because it does not pretend language priors and learned dynamics are the same object. The most interesting follow-up would be uncertainty: when should the system lower the LLM fusion weight because the prior is overconfident, outdated, or semantically plausible but dynamically wrong? I would also want to see harder action spaces than text games and BabyAI before treating it as a general embodied-agent recipe.
Connection to tracked themes: world models, agentic RL, language priors, MCTS, and planning under sparse rewards.
Routers Learn the Geometry of Their Experts: Geometric Coupling in Sparse Mixture-of-Experts
Authors: Sagi Ahrac, Noya Hochwald, Mor Geva
Institutions: Blavatnik School of Computer Science and AI, Tel Aviv University
Date: May 12, 2026
Links: arXiv, arXiv HTML
Quick idea: in sparse MoE language models, routers and experts are not independent modules. The paper argues that selected router directions and the corresponding expert input weights receive gradients along the same hidden-state direction, so they co-accumulate the token history routed to that expert.
Why it matters: MoE models are often discussed in terms of scaling efficiency and load balancing. This paper asks a more mechanistic question: what does a router actually learn, and how can the usual auxiliary load-balancing objective interfere with it?
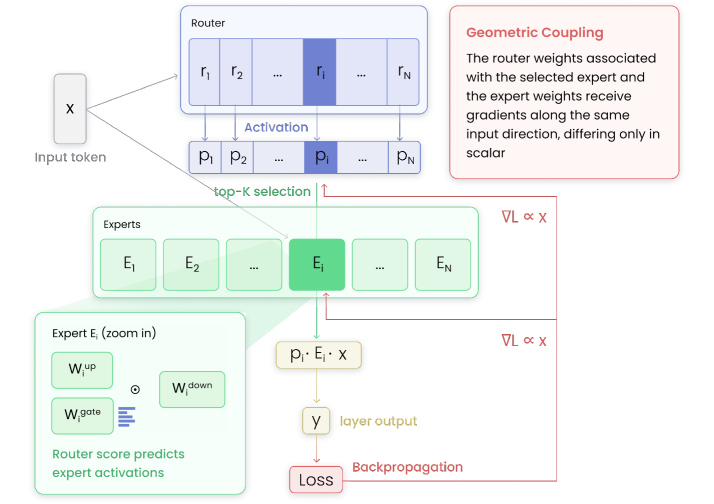
The main diagram captures the paper’s mechanism. For a selected expert, both the router vector and the expert’s input-side weights are updated in a direction proportional to the same token hidden state. Over training, the matched router and expert become coupled summaries of the tokens assigned to that expert. This is not a metaphor; the paper derives the shared input direction in the gradient expressions.
The compact version of the derivation is:
expert row update ~= delta_i,k * x
router vector update ~= gamma_i * x
The scalars differ, but both updates point along the hidden state x. That makes the router an accumulator of routed-token geometry, not merely a learned dispatch table.
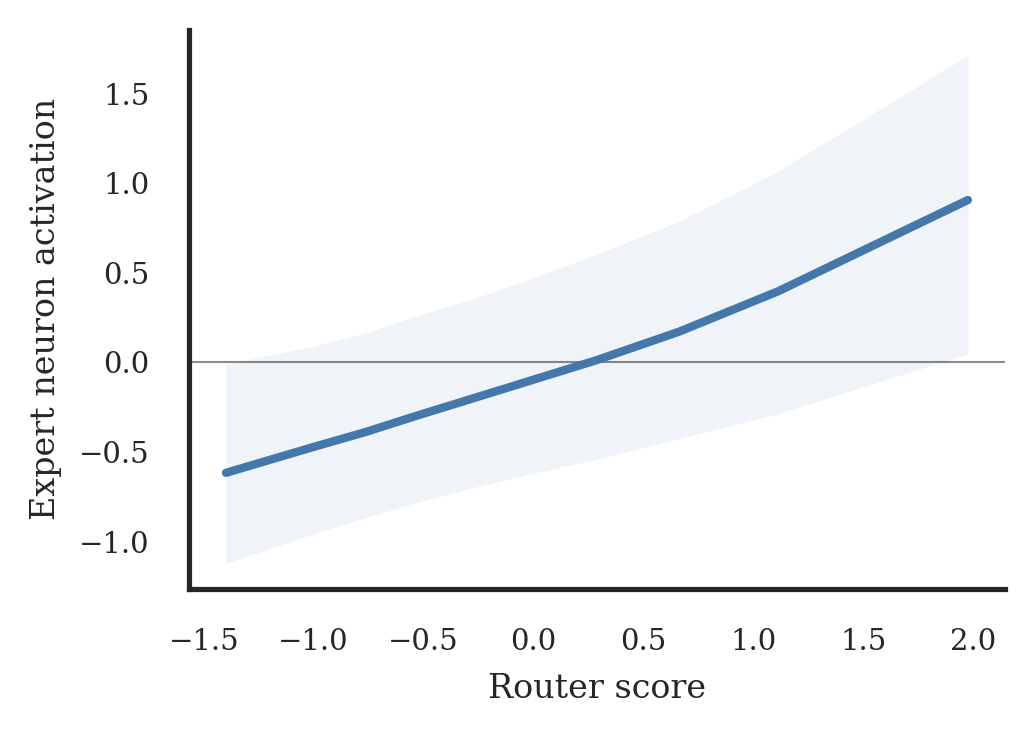
The empirical check is direct. In a 1B SMoE trained from scratch, the authors compare the raw router score for a routed token-expert pair with the average activation of that expert’s gate neurons. The reported correlation is rho = 0.43 with p = 1.2e-81 after per-layer and per-expert normalization. This does not prove every expert is semantically clean, but it does show that router preference is mirrored inside expert computation.
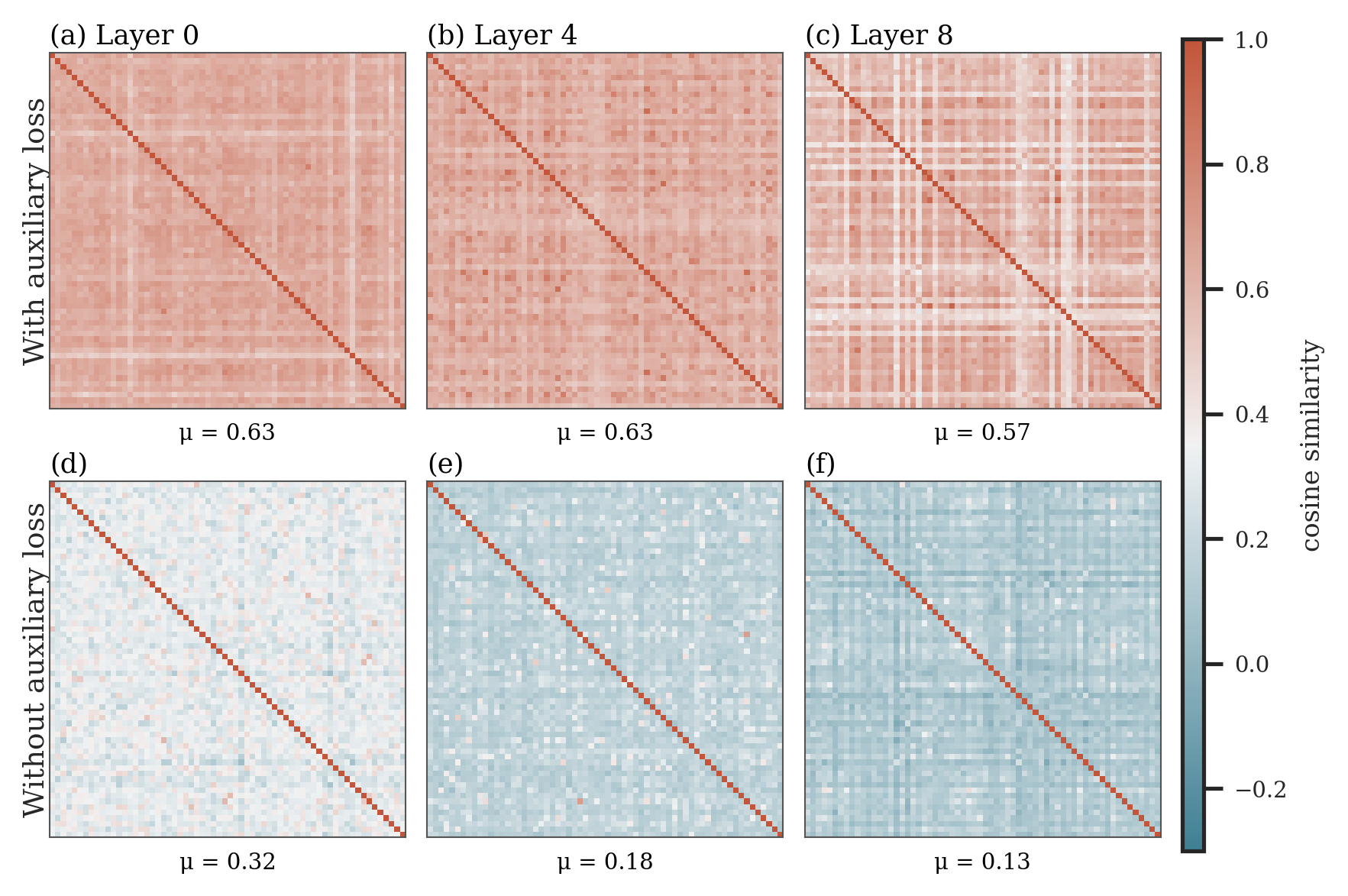
This heatmap is the sharpest warning in the paper. With auxiliary load-balancing loss, router vectors become much more similar to one another; without that auxiliary gradient, the same architecture keeps more diverse router directions. The authors report off-diagonal mean cosine similarities around 0.63, 0.63, and 0.57 under auxiliary loss at layers 0, 4, and 8, versus 0.32, 0.18, and 0.13 under loss-free bias balancing.
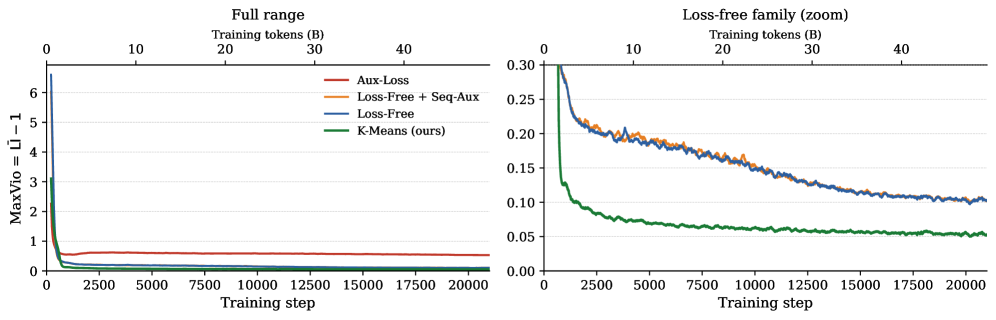
The final experiment replaces trainable router weights with non-learnable online K-Means centroids, updated from the hidden states routed to each expert. This parameter-free router gets the lowest reported load imbalance, though with a modest perplexity cost. I see it less as a proposal that everyone should switch routers tomorrow, and more as evidence that centroid-like routed-token geometry explains a substantial part of what learned routers do.
Selected reported comparison:
| Router variant | Router params | Auxiliary losses | Train PPL | C4-en PPL | Pile PPL | MaxVio |
|---|---|---|---|---|---|---|
| Aux-Loss | 0.59M | load balance + z | 15.09 | 20.54 | 11.82 | 0.526 |
| Loss-Free + Seq-Aux | 0.59M | seq-aux | 15.03 | 20.44 | 11.77 | 0.102 |
| Loss-Free | 0.59M | none | 15.01 | 20.40 | 11.76 | 0.084 |
| K-Means router | 0 | none | 15.40 | 21.01 | 12.09 | 0.037 |
My read: this is the mechanisms paper I would keep from the week. It has a clear local claim, a derivation, a measurement inside a trained model, and an intervention-style router. The limitation is scale and scope: a 1B training run is informative, but the exact load-balancing tradeoff may change in larger production MoEs with different routing rules, expert counts, and data mixtures.
Connection to tracked themes: large model mechanisms, MoE routing, training stability, and interpretability of model internals.
Reading Priority and Next Questions
My priority order is ToolCUA, DataMaster, the MoE routing paper, then PriorZero. ToolCUA is immediately relevant to computer-use agents because it names a real deployment choice: GUI or tool. DataMaster is the most important for data-agent workflows, but it needs provenance scrutiny. The MoE paper is strong mechanistic work and should be tracked alongside future sparse-model training papers. PriorZero is promising, but I want more evidence outside compact decision environments.
Next questions I would track:
- Can GUI-tool agents learn tool-beneficial labels online rather than receiving them from dataset construction?
- Can autonomous data-engineering agents produce provenance logs strong enough for leakage review and human rollback?
- Can language-prior fusion in world-model planners become uncertainty-aware instead of using a fixed alpha?
- Can MoE load-balancing objectives preserve router-expert geometry while avoiding both collapse and expert starvation?