从可执行软件世界到物理结构化世界模型
Published:
TL;DR:本期关注的是智能体训练和评测里的“世界”到底有多可靠。EnvFactory 自动合成可执行、可验证的工具环境,用来训练 tool-use agents;OpenComputer 把桌面软件任务做成可以读取真实应用状态的 verifier-grounded software worlds;PH-Dreamer 则把 Port-Hamiltonian 物理结构放进视觉世界模型,让 latent imagination 不只追奖励,也要更接近能量和运动约束。
本期我在看什么
最近几期一直在写“行动之前先检查”:探索 checkpoint、证据图、trace 诊断、状态表面。这条线仍然重要,但如果每期都只讲可见中间状态,容易变成同一个判断的重复。本期我换了一个更具体的问题:智能体所处的环境、奖励和内部模拟器本身,能不能被构造成更可靠的训练对象?
最后选了三篇 2026 年 5 月 18-19 日的 arXiv 论文。EnvFactory 关注 tool-use agent 的训练环境和轨迹质量;OpenComputer 关注 computer-use agent 的可验证桌面软件世界;PH-Dreamer 不是 LLM agent 论文,但它追问世界模型的 latent dynamics 是否应该带物理结构。我会优先用论文图解释机制,密集数字表则重写成 Markdown,避免小字截图影响阅读。
论文细读笔记
EnvFactory:用可执行工具环境训练智能体
作者:Minrui Xu、Zilin Wang、Mengyi Deng、Zhiwei Li、Zhicheng Yang、Xiao Zhu、Yinhong Liu、Boyu Zhu、Baiyu Huang、Chao Chen、Heyuan Deng、Fei Mi、Lifeng Shang、Xingshan Zeng、Zhijiang Guo
机构:LARK, HKUST(GZ);University of Cambridge;UCL;Huawei Technologies Co., Ltd
日期:2026-05-18
链接:arXiv,arXiv HTML
一句话核心 idea:EnvFactory 自动构造可执行、可测试、带状态的工具环境,并生成更像真实用户请求的多轮训练轨迹。它不是只给模型一串工具说明,而是先从真实在线资源发现工具生态,再用代码、数据库、verifier 和测试循环把环境落成可训练的 sandbox。
为什么重要:tool-use agent 的训练常卡在两端。一端是调用真实 API,成本高、延迟大、状态不稳定;另一端是纯 LLM simulator,容易幻觉,训练信号也不可靠。更隐蔽的问题是很多合成轨迹过度说明,把用户意图、推理步骤和工具选择都写得太明白,模型学到的是照着答案执行,而不是处理真实用户的省略、歧义和多轮澄清。
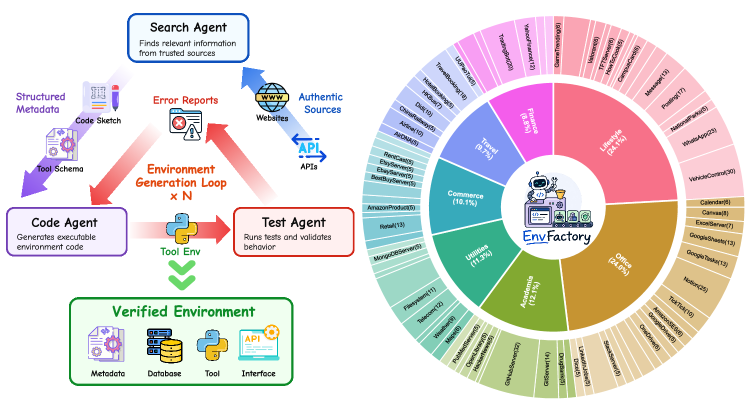
这张图展示 EnvGen 的主循环:Search Agent 提出并搜索真实来源,Code Agent 实现数据库和工具代码,Test Agent 生成测试用例和错误报告。右侧的 sunburst 图展示不同领域和工具数量的环境分布。它支撑了论文的关键主张:训练环境不是抽象 prompt,而是可执行、可验证的工具世界;但自动发现来源和自动写代码仍然可能漏掉真实系统里的边界条件。
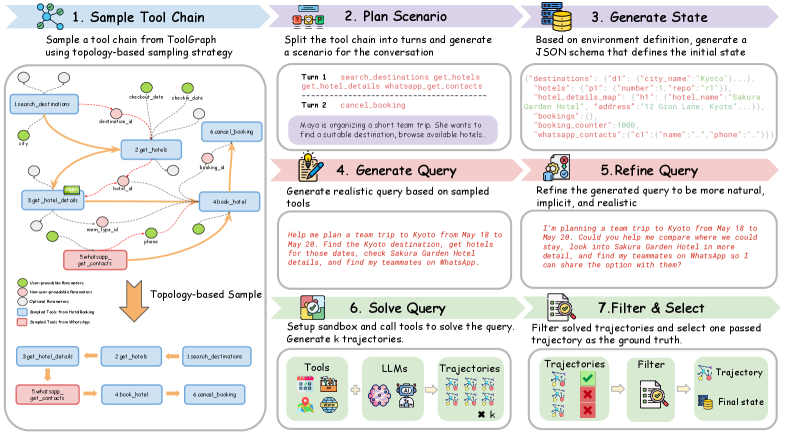
QueryGen 是我最关注的部分。它先构建工具依赖图,再采样逻辑连贯的工具链,生成可执行轨迹,最后把 query 改写成更自然、更隐含的用户请求。这个步骤很重要,因为智能体训练数据如果总是“答案式指令”,模型很难学会真实对话里的意图补全和澄清。
方法可以拆成四步。第一步,EnvGen 为候选工具环境恢复接口、数据库状态、执行策略和 verifier。第二步,Test Agent 检查 metadata 一致性、import、执行行为和状态转移,失败就进入 debug-fix-retry。第三步,QueryGen 依据工具依赖关系生成多轮 agent/user 轨迹。第四步,训练时先用用户交互轨迹做 SFT,再用只包含 tool-call 的轨迹做 GRPO 式 RL。
主要结果里最有信息量的是多轮工具任务:
| 模型 | 环境数 | 任务数 | BFCL 多轮 | MCP-Atlas pass | tau2-Bench 平均 | VitaBench 平均 | 总平均 |
|---|---|---|---|---|---|---|---|
| Qwen3-1.7B base | - | - | 16.75 | 1.03 | 14.61 | 1.33 | 16.27 |
| Qwen3-1.7B EnvFactory | 85 | 2,575 | 28.38 | 3.09 | 15.11 | 7.33 | 19.74 |
| Qwen3-4B base | - | - | 33.50 | 4.12 | 25.25 | 7.67 | 24.09 |
| Qwen3-4B EnvFactory | 85 | 2,575 | 48.50 | 9.97 | 30.13 | 16.00 | 30.77 |
| Qwen3-8B base | - | - | 41.25 | 5.15 | 32.30 | 16.70 | 29.23 |
| Qwen3-8B EnvFactory | 85 | 2,575 | 49.00 | 13.75 | 33.67 | 18.67 | 33.40 |
最清楚的信号来自 BFCL multi-turn:4B 模型从 33.50 到 48.50,8B 从 41.25 到 49.00。MCP-Atlas 也在三个尺寸上都有提升。tau2-Bench 和 VitaBench 的提升不完全均匀,这反而提醒我:环境合成最适合状态化工具交互,不应被读成所有对话能力都会同步提升。
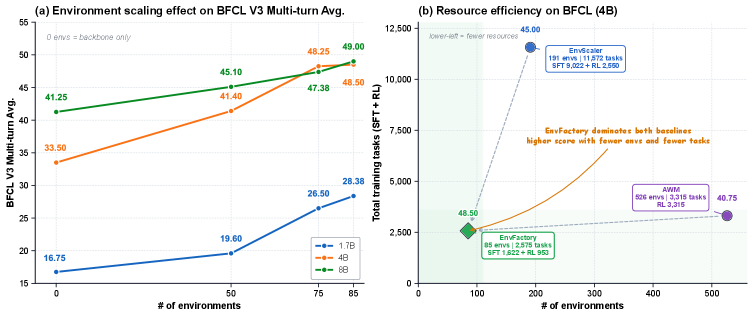
这张 scaling 图把环境数、训练任务数和 BFCL-v3 多轮表现放在一起。作者想说明,少量但经过验证的环境可以比更大的合成语料更有效。我会把它看成 data efficiency 的证据,而不是“85 个环境足够覆盖真实世界”的结论。
直接 RL 的消融也值得看:
| 模型 | BFCL 单轮 | BFCL 多轮 | tau2-Bench | VitaBench |
|---|---|---|---|---|
| Qwen3-1.7B | 79.48 | 16.75 | 14.67 | 1.33 |
| EnvFactory-1.7B RL | 79.53 | 18.33 | 18.28 | 1.67 |
| Qwen3-4B | 85.15 | 33.50 | 25.33 | 7.67 |
| EnvFactory-4B RL | 85.26 | 41.38 | 24.83 | 12.74 |
| Qwen3-8B | 84.31 | 41.25 | 32.33 | 16.70 |
| EnvFactory-8B RL | 84.42 | 44.35 | 29.08 | 17.00 |
我的判断:EnvFactory 值得继续追,因为它把 agentic RL 从“写几个工具调用 demo”推进到“可重复构造训练环境”。但弱点也清楚:sandbox verifier 能保证测试通过,不等于覆盖真实 API 的全部异常、权限、延迟和数据漂移。下一步我会看它是否能保留从真实来源到生成代码、测试、轨迹和 RL reward 的完整 provenance。
对应主题:agentic training、工具智能体、可执行环境、合成数据质量、verifiable rewards。
OpenComputer:给桌面智能体一个可验证的软件世界
作者:Jinbiao Wei、Qianran Ma、Yilun Zhao、Xiao Zhou、Kangqi Ni、Guo Gan、Arman Cohan
机构:未注明
日期:2026-05-19
链接:arXiv,arXiv HTML
一句话核心 idea:OpenComputer 把 computer-use agent 的桌面任务构造成 verifier-grounded software worlds。每个任务不只是自然语言指令,还包含可执行初始环境、机器可检查的成功标准、完整轨迹记录,以及基于应用真实状态计算的部分奖励。
为什么重要:桌面智能体的失败经常“看起来差不多”。截图里表格像是改好了,但实际 cell 错了;终端窗口显示成功,但日志里关键错误被挡住;浏览器页面看似进入正确状态,但 hidden field 或文件 metadata 没对。只用像素或 LLM judge 做 reward,会把很多近似正确当成成功。OpenComputer 的价值在于把 verifier 当作软件工程对象,而不是事后补一个评审 prompt。
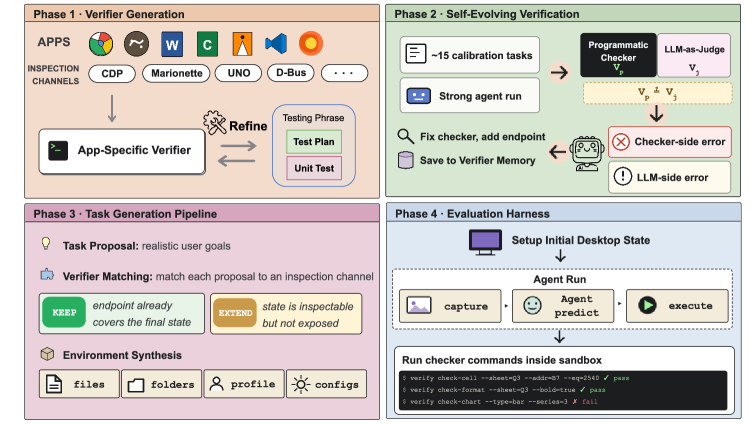
这张图展示四阶段流程:先生成应用级 verifier endpoint,再通过执行中的 disagreement analysis 自我修复 verifier,然后合成可实例化、可检查的用户目标,最后在新的桌面 sandbox 里运行 agent 并计算 reward。它明确了奖励边界:系统评价的是最终软件状态,不是模型对自己操作的叙述。

这个 endpoint 示例说明了 verifier-grounded 的具体含义。一个任务会绑定到应用 endpoint、预期检查、JSON 有效性约束和常见失败情况。需要谨慎的是,verifier 工程本身会成为瓶颈:如果 endpoint 无法读取关键状态,要么任务不能收录,要么必须扩展 verifier stack。
发布规模如下:
| 应用数 | 任务数 | 每个应用平均 verifier endpoint | 每个任务平均检查项 | 每个任务平均 seed files |
|---|---|---|---|---|
| 33 | 1,000 | 17.7 | 6.9 | 1.3 |
这不是简单 prompt generation。系统会根据复杂度、数据可生成性和状态可检查性过滤任务。最终任务可以看成三元组:用户指令、sandbox 初始化、可执行成功标准。这个三元组很关键,因为它既能用于评测,也能用于后续收集轨迹、做 rejection sampling 或 RL。
代表性结果如下:
| 模型 | OSWorld-Verified | OpenComputer 成功率 | 平均步数 | 每步时间 | 平均 reward |
|---|---|---|---|---|---|
| GPT-5.4 | 75.0% | 68.3% | 19.0 | 16.5 s | 88.4% |
| Claude-Sonnet-4.6 | 72.5% | 64.4% | 31.5 | 20.8 s | 76.6% |
| Kimi-K2.6 | 73.1% | 58.8% | 35.7 | 33.0 s | 70.7% |
| Qwen-3.5-27B | 56.2% | 32.3% | 33.1 | 57.3 s | 59.4% |
| Gemini-3-Flash | - | 16.4% | 25.4 | 9.0 s | 37.0% |
| EvoCUA-8B | 46.1% | 10.9% | 67.0 | 9.7 s | 38.1% |
| Qwen-3.5-9B | 41.8% | 7.8% | 39.3 | 17.8 s | 31.7% |
| GUI-OWL-1.5-8B | 52.3% | 5.7% | 73.6 | 9.43 s | 27.8% |
强模型明显领先,但即使最好的一行也没有接近满分。平均 reward 高于二元成功率,说明 agent 经常完成部分检查项但没达到完整目标。对训练来说,这种 partial-credit 信号比单一 success/fail 更有用。
verifier 自我演化也有对应证据:
| 指标 | 数值 |
|---|---|
| 1 轮修复的问题 | 47 |
| 2 轮修复的问题 | 15 |
| 3 轮修复的问题 | 6 |
| 预算内未修复 | 8 |
| 演化前 agreement | 85.2% |
| 演化后 agreement | 94.1% (+8.9%) |
我喜欢这个消融,因为它承认 verifier 也会错。系统必须先调试自己的检查层,才有资格说 reward 更可靠。这比把一个 reward script 永久当成真值更诚实。
GUI 和 CLI 的对比也有信息量:
| 设置 | 模型 | 成功率 | 每任务时间 |
|---|---|---|---|
| GUI | GPT-5.4 | 75.2% | 288 s |
| GUI | Claude Sonnet 4.6 | 73.0% | 622 s |
| CLI | Claude Sonnet 4.6 | 67.2% | 141 s |
CLI 更快,但 GUI 成功率更高。我的理解是,很多桌面任务仍然需要视觉 grounding,但一旦状态检查和文件操作可以转成命令式接口,CLI 路径会节省大量截图-点击循环。未来的 computer-use agent 很可能不是纯 GUI,也不是纯 CLI,而是由 verifier 决定哪些状态必须用哪个接口检查。
我的判断:OpenComputer 很值得追,因为它把桌面智能体评测往软件测试方向推了一步。风险是 coverage。hard-coded verifier 在可检查的地方很精确,但也可能让 benchmark 偏向“容易读取状态”的任务。下一步要看 verifier 生成能否扩大覆盖,而不变成另一个人工维护的大型测试套件。
对应主题:computer-use agents、可验证软件世界、部分奖励、GUI/CLI 工作流、可审计状态。
PH-Dreamer:让世界模型带上物理结构
作者:Xueyu Luan、Chenwei Shi
机构:未注明
日期:2026-05-18
链接:arXiv,arXiv HTML
一句话核心 idea:PH-Dreamer 在 recurrent visual world model 里加入 Port-Hamiltonian 结构。它让 latent transition 带有 energy routing、flow 和 dissipation 的约束,从 proprioceptive observation 估计显式 Hamiltonian 信号,并用 energy-guided actor-critic 正则化策略,让控制更低能耗、更平滑。
为什么重要:很多论文里的“world model”实际只是一个能预测足够奖励的 latent simulator。它可能对策略训练有用,但不一定保留物理结构。PH-Dreamer 的问题更具体:如果模型要在 latent imagination 里训练控制策略,内部动态是否应该被物理先验约束,而不是只靠统计相关性?
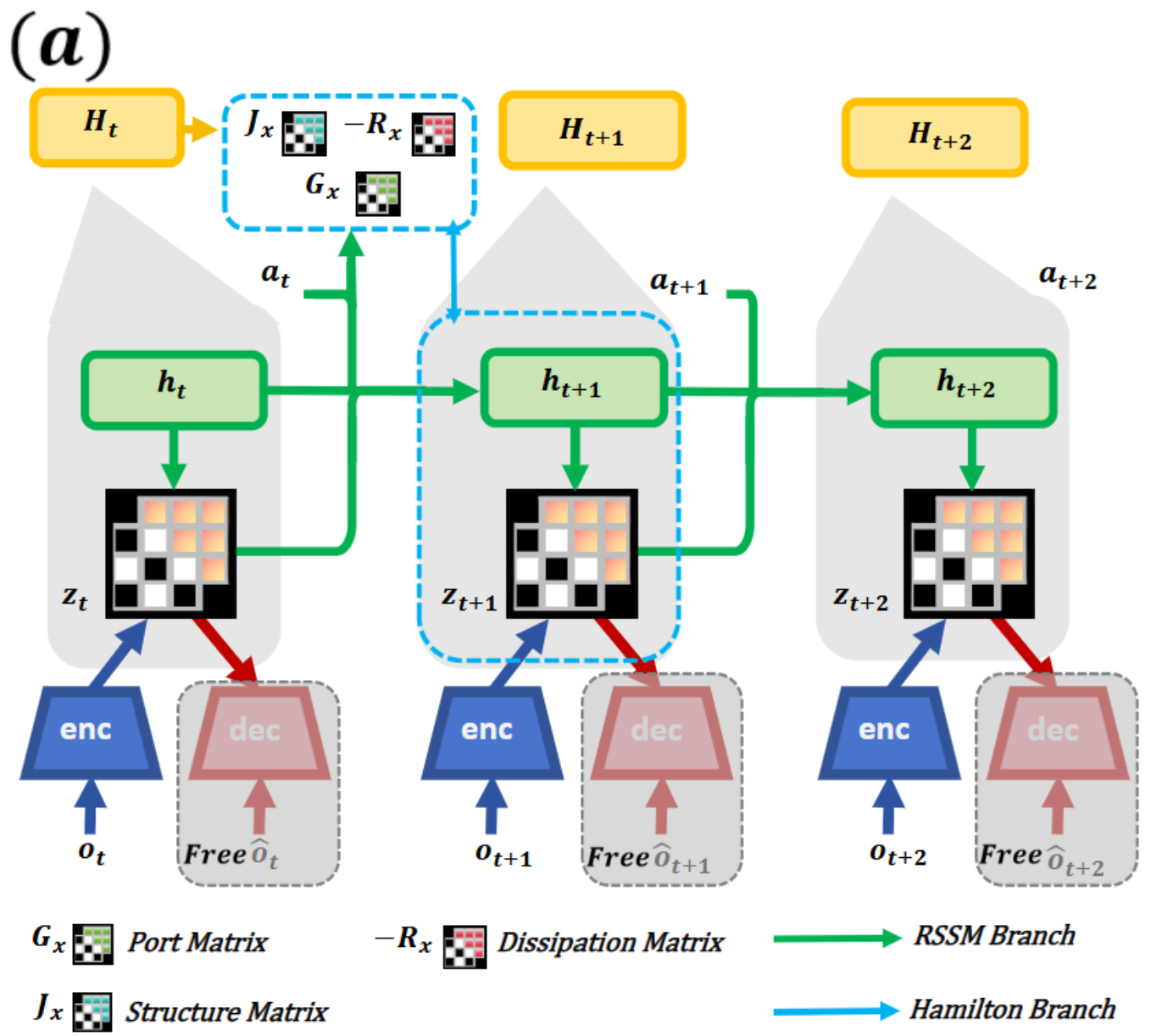
这张架构图展示了 RSSM transition 里的隐式结构约束。作者不是手写完整物理方程,而是把 projected latent phase space 往能量式组织上拉。谨慎点看,这仍然只是 learned model 里的 inductive bias,并不等于证明 rollout 物理正确。
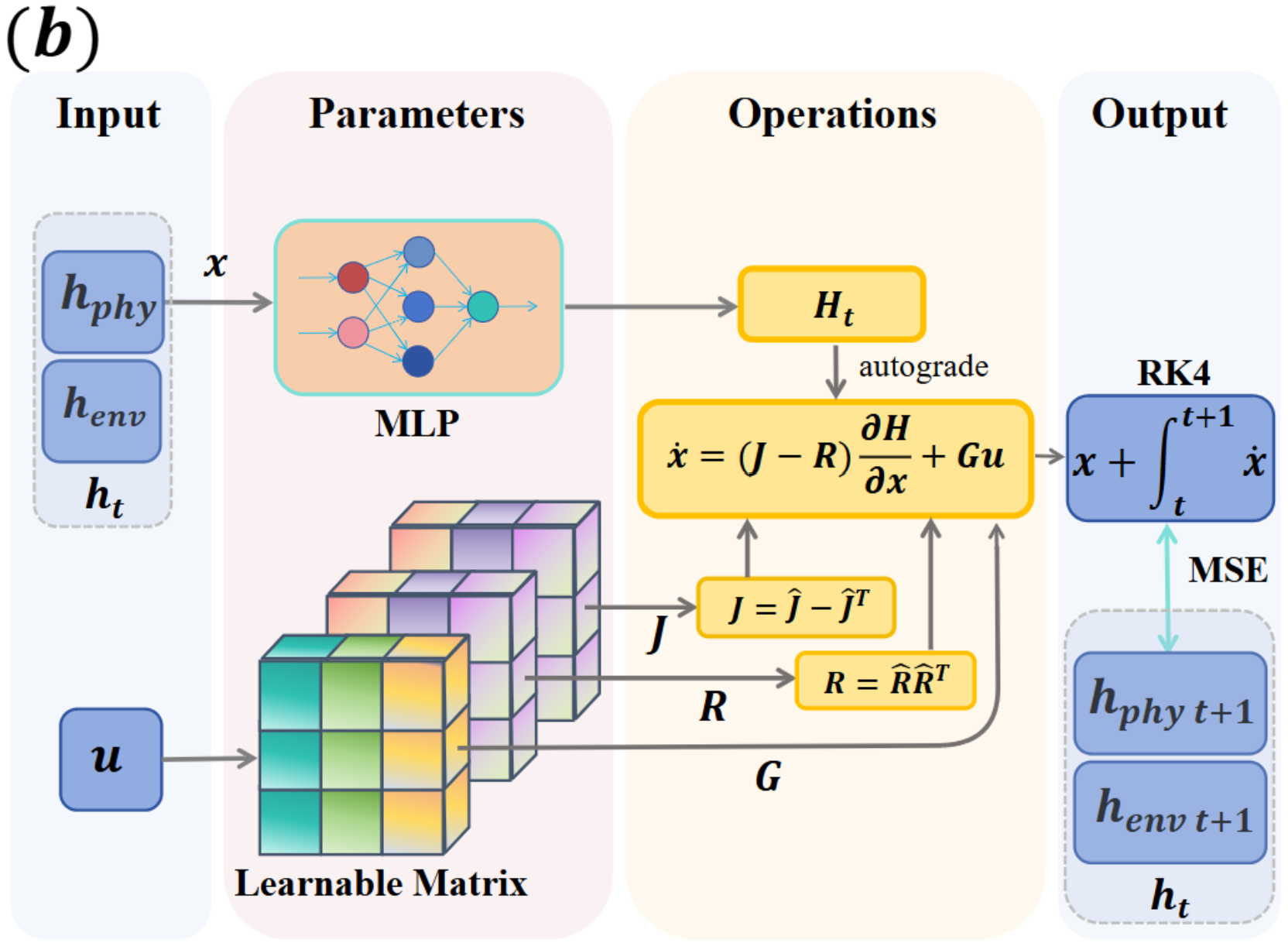
第二张架构图展示显式 Hamiltonian estimator 和 energy-guided actor-critic。模型从本体感知状态估计能量信号,策略优化再用能量梯度和类似 Lagrangian 的惩罚鼓励低能耗、平滑运动。这里的核心不是多加一个 auxiliary head,而是让物理结构同时影响表示学习和控制目标。
实验使用 DeepMind Control Suite,包括 Cheetah Run、Reacher Easy、Hopper Hop、Walker Stand、Walker Walk、Walker Run。作者主要和 R2Dreamer 比,因为 PH-Dreamer 保留相近的感知 backbone,但把普通 recurrent dynamics 换成 Port-Hamiltonian dynamics;另外也对比 DreamerV3、DreamerPro、Dreamer-InfoNCE 和 HRSSM。
500k steps 的渐近 return 如下:
| 方法 | Cheetah Run | Walker Stand | Reacher Easy | Hopper Hop | Walker Walk | Walker Run | 平均 |
|---|---|---|---|---|---|---|---|
| DreamerV3 | 689.9 | 947.8 | 951.2 | 245.7 | 951.5 | 624.3 | 735.1 |
| Dreamer-InfoNCE | 691.3 | 934.1 | 963.4 | 212.3 | 904.2 | 484.7 | 698.3 |
| HRSSM | 647.9 | 962.8 | 868.1 | 236.7 | 941.6 | 515.8 | 695.5 |
| DreamerPro | 398.0 | 960.4 | 964.6 | 291.6 | 937.2 | 527.5 | 679.9 |
| R2Dreamer | 701.1 | 972.2 | 970.8 | 297.9 | 959.8 | 673.4 | 762.5 |
| PH-Dreamer | 798.6 | 974.7 | 985.1 | 314.8 | 967.2 | 694.8 | 789.2 |
它不是每个任务都大幅跃升,但六个任务方向一致。我会把它理解成:在这个 benchmark 和 backbone 上,物理先验确实带来收益;还不能推广成“Port-Hamiltonian 一定适合所有世界模型”。
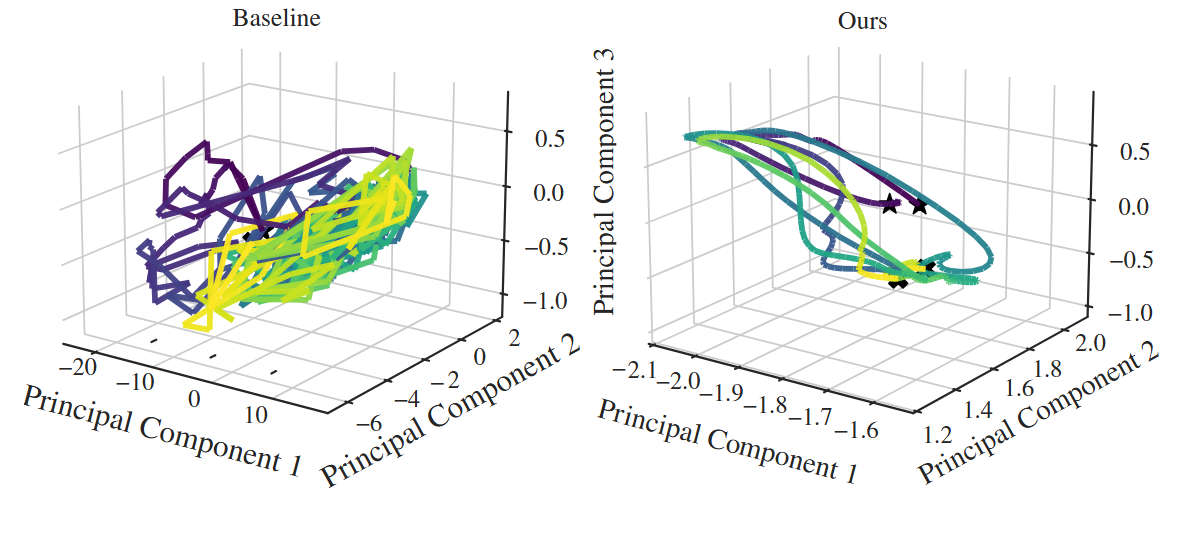
这张 phase-space 图比较 projected latent trajectory。PH-Dreamer 的轨迹更紧凑,支撑了作者关于 latent stability 的判断。作者没有声称这保证 closed-loop boundedness,这个保留很重要。
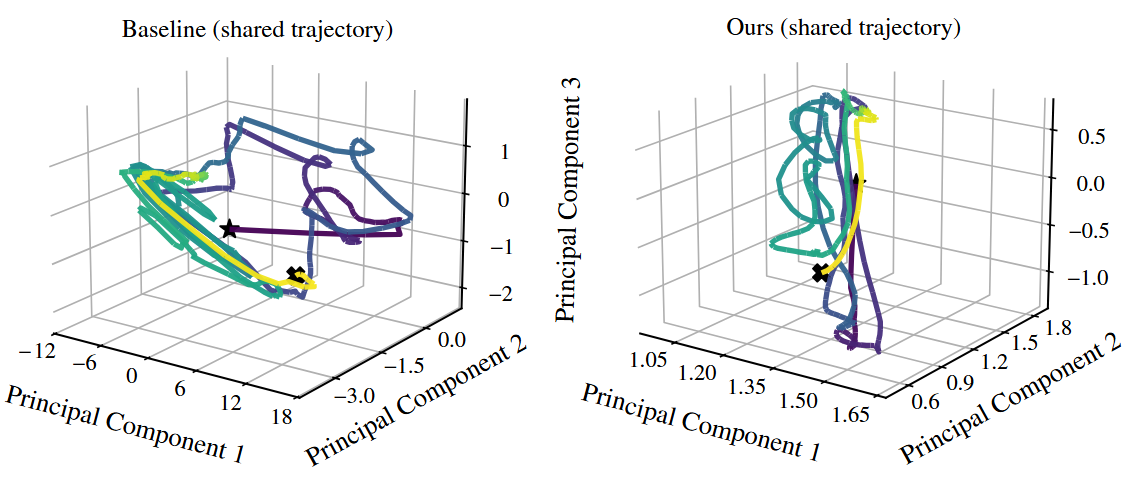
第二个视角强化了同一件事:latent 空间更紧并不是为了好看,而是要和性能不下降一起看。一个紧凑但性能差的 latent space 没意义,所以需要结合上面的 return 表和下面的 phase volume 数字。
Log Phase Volume 结果如下:
| 方法 | Cheetah Run | Walker domain | Reacher Easy | Hopper Hop |
|---|---|---|---|---|
| R2Dreamer | 14.276 | 26.115 | 17.593 | 21.224 |
| PH-Dreamer | 13.227 | 25.023 | 16.185 | 19.439 |
| 相对下降 | 7.35% | 4.18% | 8.00% | 8.41% |
显式能量对齐也很关键:
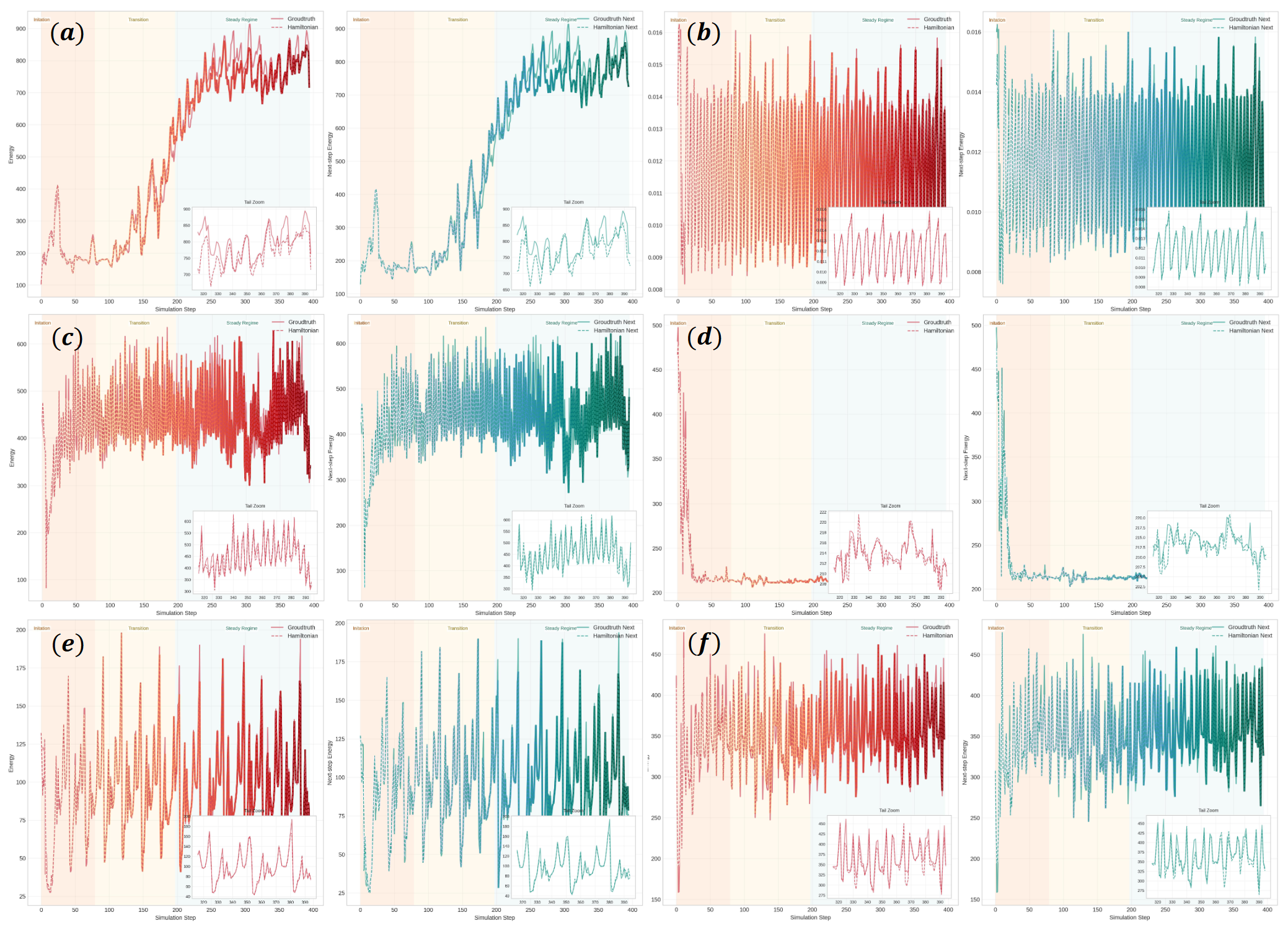
这张图把预测 Hamiltonian 和 MuJoCo ground-truth mechanical energy 放在一起比较。曲线的时间一致性支持一个判断:能量模型不是纯装饰,它确实学到了一些和机械能变化相关的结构。限制也明显:MuJoCo 可以给出干净能量信号,真实机器人或开放视频环境通常没有这么方便的物理状态。
策略行为部分,论文定义了 total energy proxy 和 mean squared jerk:
E_proxy = alpha * sum_t sum_i |tau_i,t * qdot_M(i),t| * dt
+ beta * sum_t sum_i tau_i,t^2 * dt
J = 1 / ((T - 1) * n_dof) * sum_{t=2..T} sum_j ((qddot_j,t - qddot_j,t-1) / dt)^2
| 方法 | Total energy consumption,越低越好 | Mean squared jerk,越低越好 |
|---|---|---|
| HRSSM | 125.43 | 45.12 |
| DreamerV3 | 132.89 | 48.64 |
| DreamerPro | 128.36 | 46.87 |
| R2Dreamer | 122.10 | 44.05 |
| PH-Dreamer without implicit component | 117.52 | 40.19 |
| PH-Dreamer without explicit component | 121.84 | 43.63 |
| PH-Dreamer | 112.58 | 39.92 |
我的判断:PH-Dreamer 的价值在于让“世界模型”这个词更克制。它不只问 latent future 能不能帮策略涨分,还问 latent dynamics 是否保留某种可解释的物理结构,并最终改变控制行为。限制是实验范围仍然集中在 MuJoCo 风格连续控制。我会继续追问:接触丰富的 manipulation、pixels-only setting、action-conditioned video prediction 里,类似物理结构还能不能成立?
对应主题:世界模型、物理先验、latent dynamics、能量感知控制、超越 reward 的评估。
阅读优先级和下期问题
我会优先看 OpenComputer,其次 EnvFactory,再看 PH-Dreamer。OpenComputer 最接近部署痛点:如果 reward 不能读取精确软件状态,桌面智能体会继续从模糊监督里学坏。EnvFactory 更直接指向训练数据和环境构造。PH-Dreamer 则提醒我,embodied agent 的世界模型不能只靠 reward proxy,内部模拟结构本身也值得检查。
下期我想继续追的问题:
- 桌面智能体的 verifier 能不能规模化生成,而不把 benchmark 缩窄到容易检查的任务?
- 从真实在线来源到生成代码、测试、轨迹和 RL reward,工具环境能否保留完整 provenance?
- agentic RL 能否利用 partial-credit verifier signal,同时避免过拟合 reward script?
- 在接触丰富或 pixels-only 的场景里,没有干净能量标签时,物理结构化 world model 还能不能有效?