Executable Worlds for Agents, Physical Priors for World Models
Published:
TL;DR: this round is about making the world around an agent less imaginary. EnvFactory synthesizes executable tool environments for agentic RL instead of training only on over-specified traces. OpenComputer builds verifier-grounded desktop software worlds where computer-use agents can be scored by application state, not just screenshots or LLM judgment. PH-Dreamer puts a Port-Hamiltonian structure inside a visual world model, so latent imagination is pressured to respect energy and smoothness instead of only predicting reward.
What I Am Watching This Round
The last few issues leaned hard into “inspect before acting”: exploration checkpoints, evidence graphs, trace diagnosis, and state surfaces. That thread is still useful, but it can become too comfortable. This time I looked for papers where the environment itself becomes a training or evaluation object.
Three May 18-19 arXiv papers fit that criterion. EnvFactory is about creating many small, verified tool worlds from real online resources. OpenComputer is about desktop tasks whose rewards can be checked by hard-coded state verifiers. PH-Dreamer is a world-model paper rather than an LLM-agent paper, but it asks the same deeper question: what structure should the simulator carry before a policy trusts it?
I used paper figures for mechanisms and curves, and rebuilt dense numeric tables in Markdown where the table is easier to read than a screenshot.
Paper Notes
EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL
Authors: Minrui Xu, Zilin Wang, Mengyi Deng, Zhiwei Li, Zhicheng Yang, Xiao Zhu, Yinhong Liu, Boyu Zhu, Baiyu Huang, Chao Chen, Heyuan Deng, Fei Mi, Lifeng Shang, Xingshan Zeng, Zhijiang Guo
Institutions: LARK, HKUST(GZ); University of Cambridge; UCL; Huawei Technologies Co., Ltd
Date: May 18, 2026
Links: arXiv, arXiv HTML
Quick idea: EnvFactory automates two things agentic RL usually lacks: executable stateful tool environments and realistic multi-turn queries. It discovers authentic tool ecosystems, reconstructs verified sandbox environments, samples tool-dependency topologies, and turns rigid instruction lists into natural user requests with implicit intent.
Why it matters: tool-use agents are often trained in environments that are either too expensive to call, too fake to trust, or too scripted to teach actual interaction. A good tool agent has to infer missing intent, ask for clarification, update state through tool calls, and survive multi-turn ambiguity. EnvFactory is useful because it treats the environment as part of the dataset, not as a passive API list.
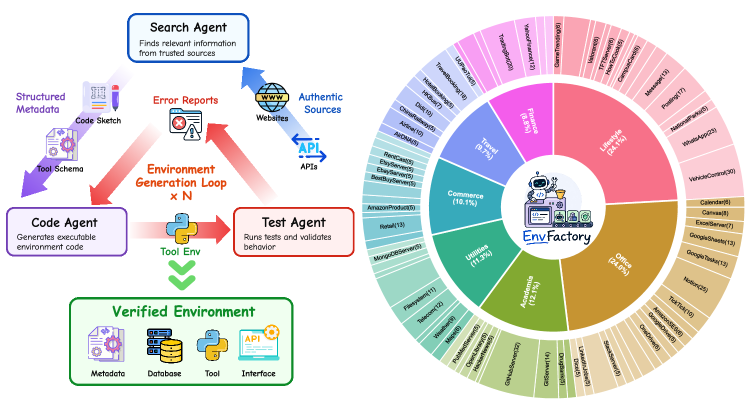
The left side of this figure shows the EnvGen loop: a Search Agent proposes and searches for real sources, a Code Agent implements databases and tool code, and a Test Agent generates unit tests and error reports. The right side summarizes the resulting environment mix by domain and tool count. The figure supports the paper’s main claim that the training substrate is executable and verified, though it still depends on the reliability of automated source discovery and code generation.
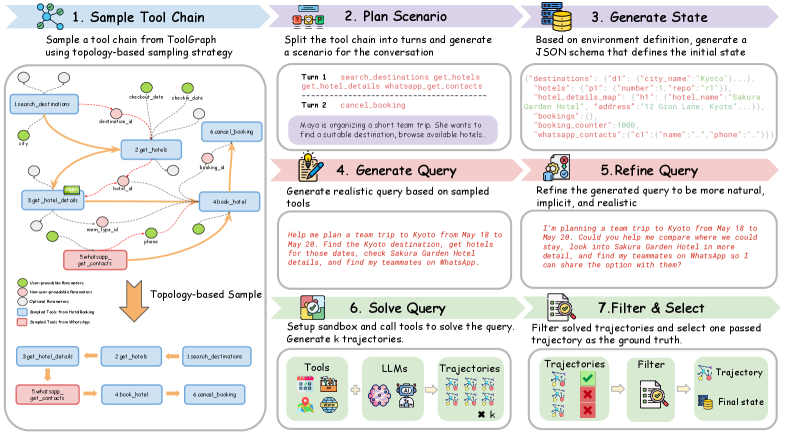
QueryGen is the part I found more interesting than the headline scores. Instead of sampling isolated tools, it builds a tool dependency graph, samples coherent tool chains, generates executable trajectories, and then refines queries so the user request is less like an answer key. That matters because many agent datasets accidentally train agents to follow over-detailed instructions rather than infer what a human actually meant.
The method has four concrete steps. First, EnvGen recovers a tool interface, database state, execution policy, and verifier for a candidate environment. Second, a Test Agent validates metadata consistency, imports, execution behavior, and state transitions; failing environments go through a debug-fix-retry loop. Third, QueryGen samples tool dependencies and produces trajectories with agents and simulated users. Fourth, training uses SFT on user-interaction trajectories and GRPO-based RL on tool-call trajectories.
Selected main results show why the paper is not only an environment-synthesis story:
| Model | Envs | Tasks | BFCL multi-turn | MCP-Atlas pass | tau2-Bench avg | VitaBench avg | Overall avg |
|---|---|---|---|---|---|---|---|
| Qwen3-1.7B base | - | - | 16.75 | 1.03 | 14.61 | 1.33 | 16.27 |
| Qwen3-1.7B EnvFactory | 85 | 2,575 | 28.38 | 3.09 | 15.11 | 7.33 | 19.74 |
| Qwen3-4B base | - | - | 33.50 | 4.12 | 25.25 | 7.67 | 24.09 |
| Qwen3-4B EnvFactory | 85 | 2,575 | 48.50 | 9.97 | 30.13 | 16.00 | 30.77 |
| Qwen3-8B base | - | - | 41.25 | 5.15 | 32.30 | 16.70 | 29.23 |
| Qwen3-8B EnvFactory | 85 | 2,575 | 49.00 | 13.75 | 33.67 | 18.67 | 33.40 |
The cleanest signal is BFCL multi-turn: the 4B model rises from 33.50 to 48.50, and the 8B model from 41.25 to 49.00. MCP-Atlas also improves across sizes. The tau2-Bench and VitaBench gains are less uniform, which is a useful warning: environment synthesis helps most when the target task resembles stateful tool interaction.
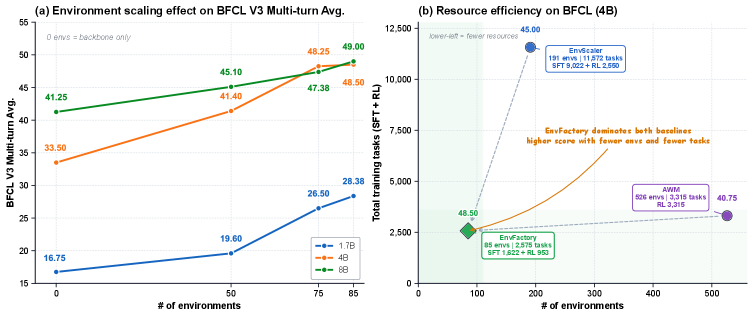
The scaling figure compares environment count, training tasks, and BFCL-v3 multi-turn performance. EnvFactory is trying to show that fewer but better verified environments can beat larger synthetic corpora. I would read this as evidence for data efficiency, not proof that 85 environments are enough for open-ended deployment.
The direct-RL ablation is also worth keeping:
| Model | BFCL single-turn | BFCL multi-turn | tau2-Bench | VitaBench |
|---|---|---|---|---|
| Qwen3-1.7B | 79.48 | 16.75 | 14.67 | 1.33 |
| EnvFactory-1.7B RL | 79.53 | 18.33 | 18.28 | 1.67 |
| Qwen3-4B | 85.15 | 33.50 | 25.33 | 7.67 |
| EnvFactory-4B RL | 85.26 | 41.38 | 24.83 | 12.74 |
| Qwen3-8B | 84.31 | 41.25 | 32.33 | 16.70 |
| EnvFactory-8B RL | 84.42 | 44.35 | 29.08 | 17.00 |
My judgment: I would track EnvFactory because it moves agentic RL away from brittle API demos and toward repeatable environment construction. The weak point is verification scope. A generated sandbox can pass unit tests while still missing messy real-world edge cases, so I would want provenance logs and held-out real APIs before treating this as a deployment-grade training substrate.
Connection to tracked themes: agentic training, tool-use agents, executable environments, synthetic data quality, and verifiable rewards.
OpenComputer: Verifiable Software Worlds for Computer-Use Agents
Authors: Jinbiao Wei, Qianran Ma, Yilun Zhao, Xiao Zhou, Kangqi Ni, Guo Gan, Arman Cohan
Institutions: not specified
Date: May 19, 2026
Links: arXiv, arXiv HTML
Quick idea: OpenComputer builds desktop-agent tasks around application-state verifiers. Instead of asking an LLM judge whether a screenshot looks correct, it creates software worlds with executable initial state, structured success criteria, full trajectory logs, and partial-credit rewards computed from real application state.
Why it matters: computer-use agents can look almost right while being wrong in the exact cell, hidden panel, file metadata, browser state, or terminal log that matters. Pixels are a weak reward interface. OpenComputer is interesting because it treats verifiers as first-class software artifacts and lets tasks be generated only when the target state can be checked.
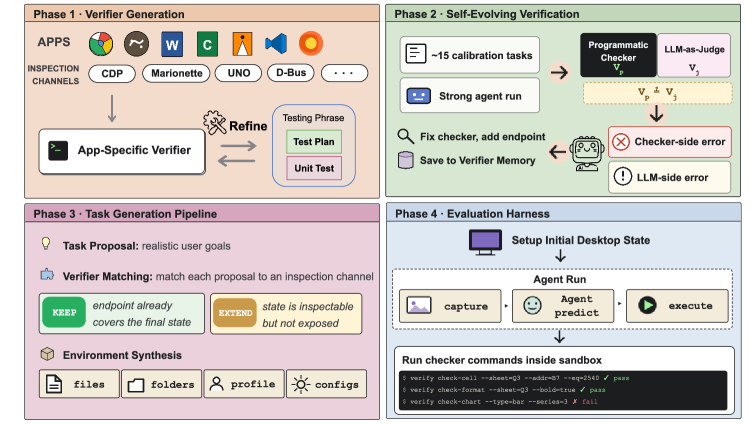
The pipeline has four phases. It first builds app-specific verifier endpoints, then improves them through execution-grounded disagreement analysis, then synthesizes realistic user goals that can be instantiated and checked, and finally runs agents in fresh desktop sandboxes. The figure is useful because it makes the reward boundary explicit: the system scores final software state, not the model’s story about what happened.

This endpoint example shows what “verifier-grounded” means in practice. A task is tied to an application endpoint, expected checks, JSON-validity constraints, and failure cases. The caveat is that verifier engineering becomes the bottleneck: if the endpoint cannot inspect the decisive state, the task either has to be rejected or the verifier stack must be extended.
The released benchmark has a concrete scale:
| Applications | Tasks | Avg verifier endpoints / app | Avg checks / task | Avg seed files / task |
|---|---|---|---|---|
| 33 | 1,000 | 17.7 | 6.9 | 1.3 |
The method is not just “generate prompts.” For each candidate desktop goal, the system checks complexity, data generatability, and state inspectability. A finalized task is a tuple of user-facing instruction, sandbox initialization, and executable success criteria. That tuple is the important object: it can support evaluation now and trajectory collection or RL later.
Representative benchmark results:
| Model | OSWorld-Verified | OpenComputer success | Avg steps | Time / step | Avg reward |
|---|---|---|---|---|---|
| GPT-5.4 | 75.0% | 68.3% | 19.0 | 16.5 s | 88.4% |
| Claude-Sonnet-4.6 | 72.5% | 64.4% | 31.5 | 20.8 s | 76.6% |
| Kimi-K2.6 | 73.1% | 58.8% | 35.7 | 33.0 s | 70.7% |
| Qwen-3.5-27B | 56.2% | 32.3% | 33.1 | 57.3 s | 59.4% |
| Gemini-3-Flash | - | 16.4% | 25.4 | 9.0 s | 37.0% |
| EvoCUA-8B | 46.1% | 10.9% | 67.0 | 9.7 s | 38.1% |
| Qwen-3.5-9B | 41.8% | 7.8% | 39.3 | 17.8 s | 31.7% |
| GUI-OWL-1.5-8B | 52.3% | 5.7% | 73.6 | 9.43 s | 27.8% |
The frontier models do much better than open models, but even the strongest row leaves a sizable gap. The average reward is higher than binary success, which means agents often make partial progress but miss some state checks. That is exactly the kind of signal a training environment should preserve.
The verifier loop also has evidence behind it:
| Metric | Value |
|---|---|
| Verifier issues fixed in 1 round | 47 |
| Fixed in 2 rounds | 15 |
| Fixed in 3 rounds | 6 |
| Not fixed within budget | 8 |
| Agreement before evolution | 85.2% |
| Agreement after evolution | 94.1% (+8.9%) |
I like this ablation because it admits that verifiers are imperfect. The system has to debug its own checking layer before it can claim reliable rewards. That is more honest than treating a reward script as ground truth forever.
A smaller GUI-versus-CLI comparison is also informative:
| Setting | Model | Success rate | Time per task |
|---|---|---|---|
| GUI | GPT-5.4 | 75.2% | 288 s |
| GUI | Claude Sonnet 4.6 | 73.0% | 622 s |
| CLI | Claude Sonnet 4.6 | 67.2% | 141 s |
My judgment: OpenComputer is worth following because it makes desktop-agent evaluation more like software testing. The risk is coverage. Hard-coded verifiers are precise where they exist, but they may steer the benchmark toward tasks that are easy to inspect. The next question is whether verifier coverage can expand without turning the benchmark into another hand-maintained test suite.
Connection to tracked themes: computer-use agents, verifiable software worlds, partial-credit rewards, GUI/CLI workflows, and auditable state.
PH-Dreamer: A Physics-Driven World Model via Port-Hamiltonian Generative Dynamics
Authors: Xueyu Luan, Chenwei Shi
Institutions: not specified
Date: May 18, 2026
Links: arXiv, arXiv HTML
Quick idea: PH-Dreamer modifies a recurrent visual world model with Port-Hamiltonian structure. It biases latent transitions toward energy routing with flow and dissipation, learns an explicit Hamiltonian signal from proprioceptive observations, and regularizes actor-critic learning toward lower energy and smoother control.
Why it matters: “world model” is often shorthand for a latent simulator that predicts enough reward to train a policy. That can work, but it does not guarantee that imagined dynamics preserve physical structure. PH-Dreamer is interesting because it asks the simulator to carry a physics prior, not only a statistical one.
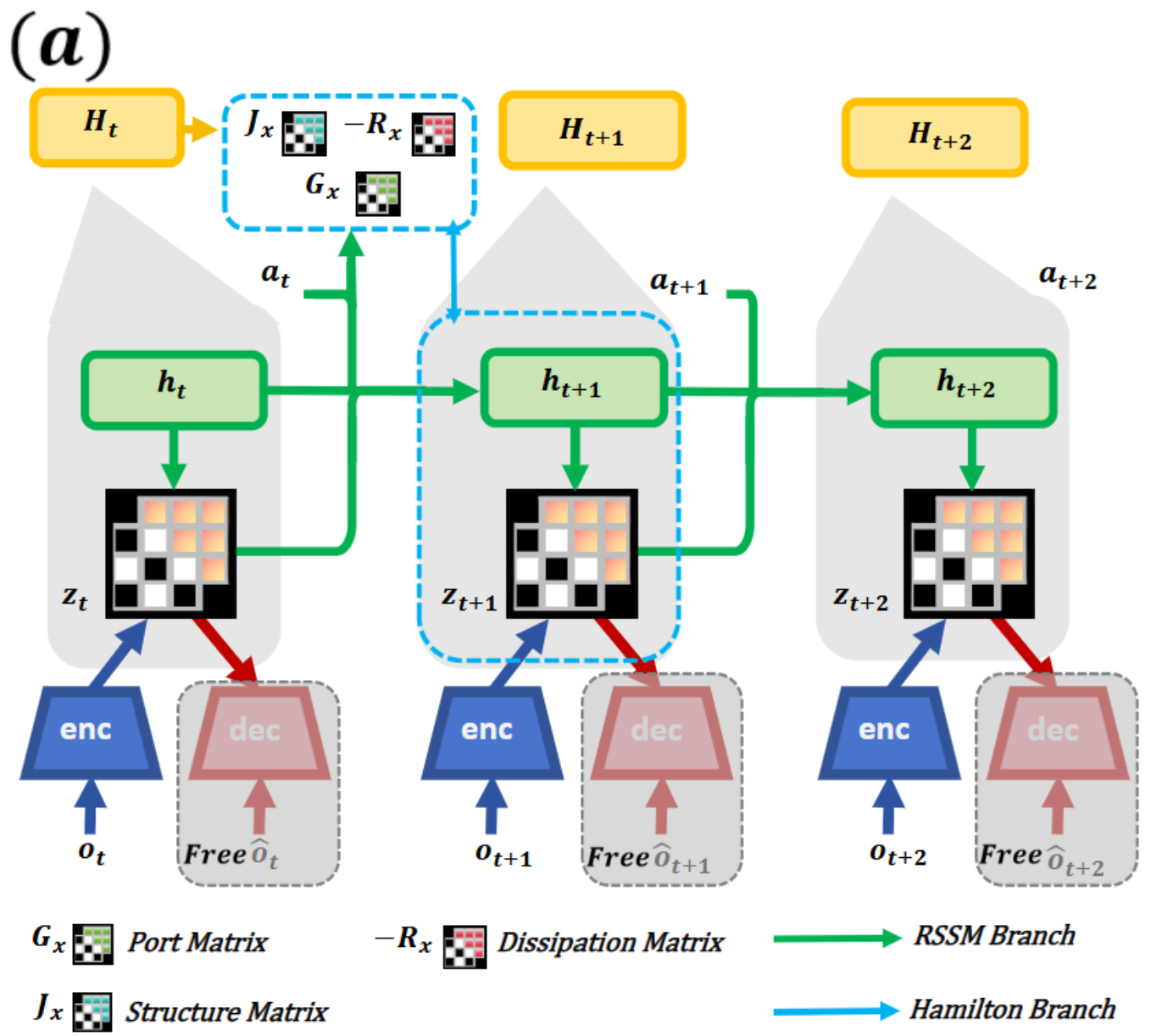
This architecture panel shows the implicit structural constraint inside the RSSM-style transition. The point is not to hand-code full physics, but to regularize the projected latent phase space so the transition has an energy-like organization. The caveat is that this is still an inductive bias inside a learned model; it is not a proof of physically correct rollouts.
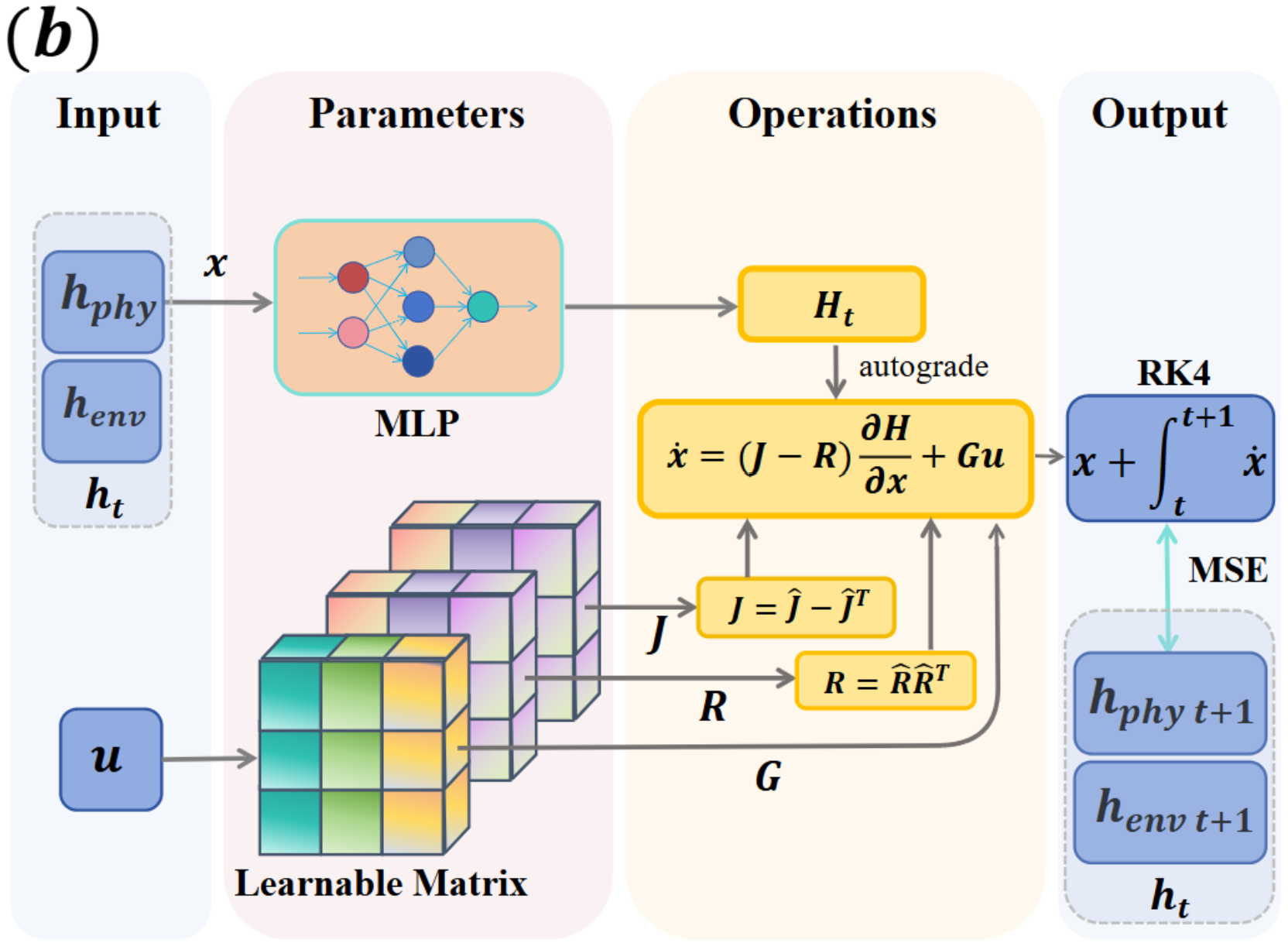
The second architecture panel shows the explicit Hamiltonian estimator and energy-guided actor-critic component. The world model estimates an energy signal from proprioceptive observations, and the policy objective uses energy gradients and Lagrangian-style penalties to favor lower-energy, smoother trajectories. This is the paper’s key move: physical structure affects both representation learning and control.
The paper evaluates on DeepMind Control Suite tasks: Cheetah Run, Reacher Easy, Hopper Hop, Walker Stand, Walker Walk, and Walker Run. The central comparison isolates R2Dreamer because PH-Dreamer keeps a similar perceptual backbone while replacing generic recurrent dynamics with Port-Hamiltonian dynamics. Broader baselines include DreamerV3, DreamerPro, Dreamer-InfoNCE, and HRSSM.
Selected asymptotic returns at 500k steps:
| Method | Cheetah Run | Walker Stand | Reacher Easy | Hopper Hop | Walker Walk | Walker Run | Avg |
|---|---|---|---|---|---|---|---|
| DreamerV3 | 689.9 | 947.8 | 951.2 | 245.7 | 951.5 | 624.3 | 735.1 |
| Dreamer-InfoNCE | 691.3 | 934.1 | 963.4 | 212.3 | 904.2 | 484.7 | 698.3 |
| HRSSM | 647.9 | 962.8 | 868.1 | 236.7 | 941.6 | 515.8 | 695.5 |
| DreamerPro | 398.0 | 960.4 | 964.6 | 291.6 | 937.2 | 527.5 | 679.9 |
| R2Dreamer | 701.1 | 972.2 | 970.8 | 297.9 | 959.8 | 673.4 | 762.5 |
| PH-Dreamer | 798.6 | 974.7 | 985.1 | 314.8 | 967.2 | 694.8 | 789.2 |
The result is not a huge leap on every task, but it is consistent across the six listed tasks. I would read this as evidence that the physics prior is helpful under this benchmark and backbone, not as a general claim that Port-Hamiltonian structure is always the right prior.
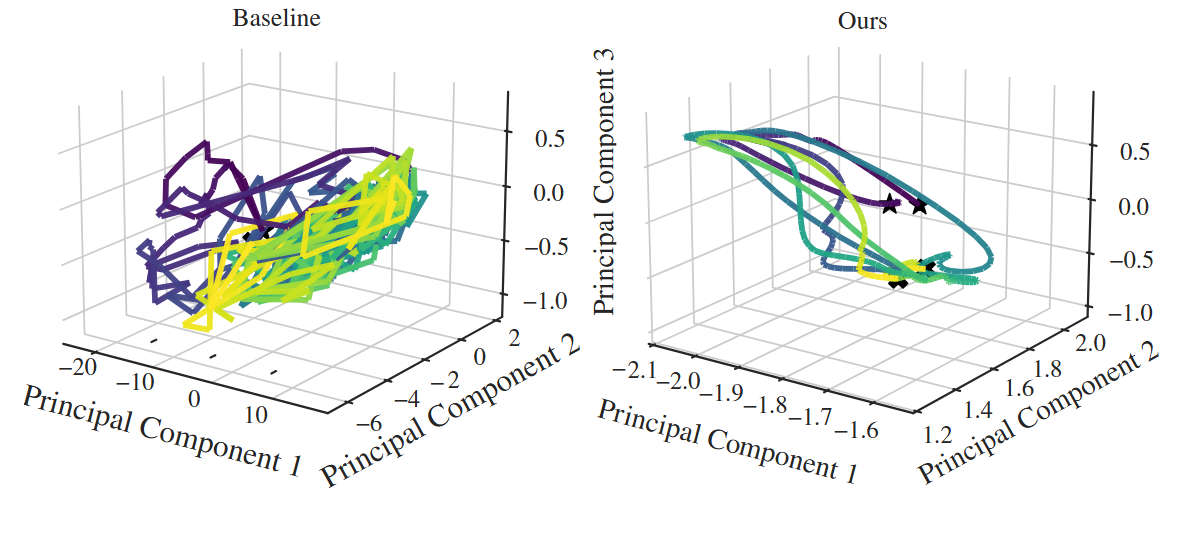
The phase-space visualization compares projected latent trajectories. PH-Dreamer’s trajectory is more compact than the baseline on the shown rollout, which supports the claim that the latent dynamics are less diffuse. The authors are careful not to claim a closed-loop boundedness guarantee, and that caution matters.
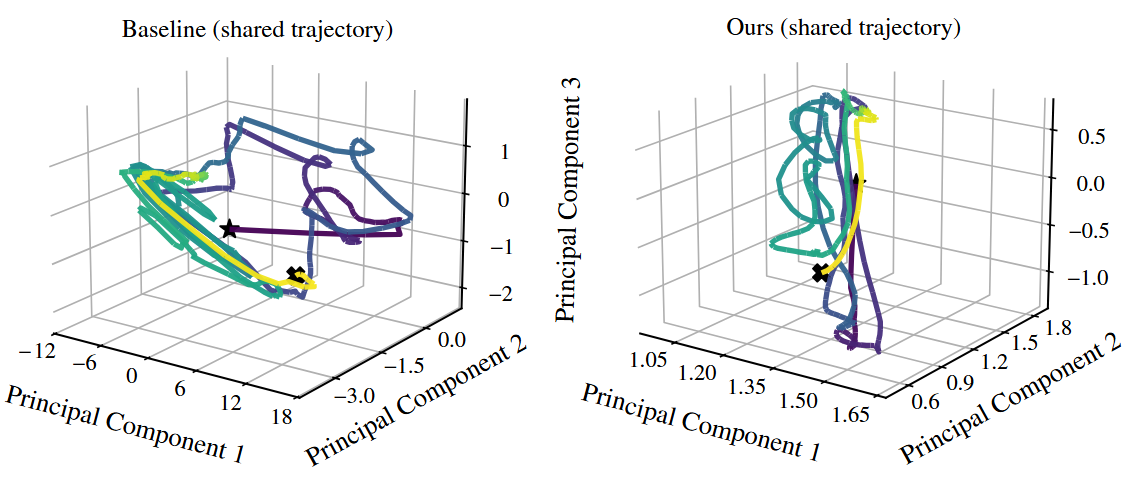
This companion view reinforces the same point from another task slice. The useful signal is not visual neatness alone; it is paired with the Log Phase Volume measurement below. A compact latent space is only meaningful if task performance stays high, which is why the return table and phase-volume table have to be read together.
Log Phase Volume on four task groups:
| Method | Cheetah Run | Walker domain | Reacher Easy | Hopper Hop |
|---|---|---|---|---|
| R2Dreamer | 14.276 | 26.115 | 17.593 | 21.224 |
| PH-Dreamer | 13.227 | 25.023 | 16.185 | 19.439 |
| Relative reduction | 7.35% | 4.18% | 8.00% | 8.41% |
The explicit energy analysis is also important:
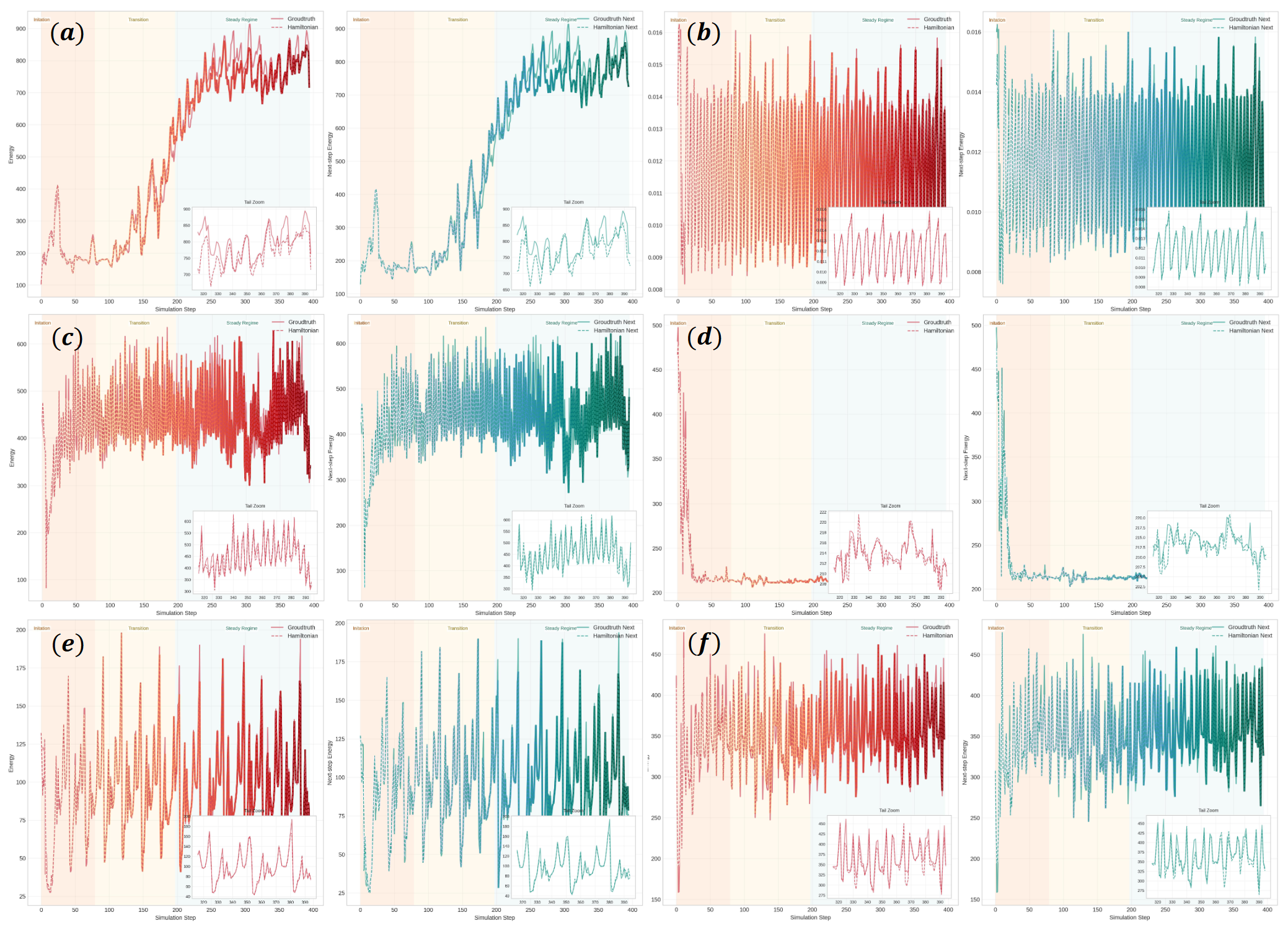
This figure compares predicted Hamiltonians with MuJoCo ground-truth mechanical energy across the six DMC tasks. The visible temporal tracking supports the claim that the learned energy model is not only a decorative auxiliary head. A caveat: ground-truth simulator energy is available here, while many real robotic or video settings would have noisier physical state access.
For policy behavior, the paper defines a total energy proxy and mean squared jerk:
E_proxy = alpha * sum_t sum_i |tau_i,t * qdot_M(i),t| * dt
+ beta * sum_t sum_i tau_i,t^2 * dt
J = 1 / ((T - 1) * n_dof) * sum_{t=2..T} sum_j ((qddot_j,t - qddot_j,t-1) / dt)^2
| Method | Total energy consumption, lower is better | Mean squared jerk, lower is better |
|---|---|---|
| HRSSM | 125.43 | 45.12 |
| DreamerV3 | 132.89 | 48.64 |
| DreamerPro | 128.36 | 46.87 |
| R2Dreamer | 122.10 | 44.05 |
| PH-Dreamer without implicit component | 117.52 | 40.19 |
| PH-Dreamer without explicit component | 121.84 | 43.63 |
| PH-Dreamer | 112.58 | 39.92 |
My judgment: PH-Dreamer is useful because it gives “world model” a more disciplined meaning: not only predict latent futures, but preserve a physically interpretable structure that changes control behavior. The limitation is scope. The evidence is from MuJoCo-style continuous control, where proprioception and simulator energy are accessible. I would want to see contact-rich manipulation, pixels-only settings, and action-conditioned video prediction before treating this as a general recipe.
Connection to tracked themes: world models, physical inductive bias, latent dynamics, energy-aware control, and evaluation beyond reward.
Reading Priority and Next Questions
My priority order is OpenComputer, EnvFactory, then PH-Dreamer. OpenComputer is closest to a deployment bottleneck: if the reward cannot inspect exact software state, computer-use agents will keep learning from blurry supervision. EnvFactory is the more direct training-data paper, and I would watch whether its generated environments can be audited against real APIs. PH-Dreamer is the conceptual bridge to embodied world models: simulator structure matters before the policy sees a reward.
Next questions I would track:
- Can verifier generation for desktop agents scale without narrowing the benchmark to what is easy to inspect?
- Can executable tool environments preserve provenance from real online sources through code generation, tests, and RL trajectories?
- Can agentic RL use partial-credit verifier signals without overfitting to reward scripts?
- Can physics-structured world models help in contact-heavy or pixel-only settings where clean energy labels are unavailable?