从编译式智能体到选择性记忆与深度研究推导债
Published:
TL;DR:本期看的不是“模型又会了什么”,而是智能体周围的运行时怎么变得更可控。Agent JIT 把网页智能体任务编译成带状态不变量和延迟调度的可执行计划。Mem-pi 把记忆做成一个会选择是否发声的生成式策略。DeepWeb-Bench 则提醒我们,深度研究智能体的主要错误往往不在“找不到资料”,而在推导、校准和跨来源协调。
本期我在看什么
最近几期连续看了 verifier、可执行环境、预执行检查和证据图。这条线仍然重要,但如果每期都用同一个答案解释所有问题,就会变钝。本期我换了一个角度:智能体的运行时本身能不能承担更多工作?比如执行前先编译动作,记忆只在有用时介入,或者把深度研究的长报告拆成可审计的单元格。
我初筛了 5 月 19-20 日的新论文和社区线索,包括 Agentic Model Checking、GaussianDream、CoPhy、Structured Layout Priors、ActGuide-RL、生产级智能体运行时架构,以及中文媒体里提到的多智能体系统和科学协议生成工作。最后只保留三篇,因为它们都有开放 arXiv HTML、方法细节充足,图表也足够支撑一篇真正的 mini explainer。
论文细读笔记
Agent JIT Compilation for Latency-Optimizing Web Agent Planning and Scheduling
作者:Caleb Winston、Ron Yifeng Wang、Azalia Mirhoseini、Christos Kozyrakis
机构:Stanford University
日期 / 会议:arXiv,2026 年 5 月 20 日;ICML 2026 接收
链接:arXiv,arXiv HTML
一句话核心 idea:Agent JIT 把自然语言网页任务编译成可执行代码计划,先检查工具前置条件和后置条件,再用历史延迟分布决定串行、并行或 hedge 执行。它想替代那种“截图一次、问模型一次、点一下、再截图”的慢循环。
为什么重要:网页智能体很多失败并不神秘,就是重复让模型重新决定每一步,既慢又容易把动作顺序搞错。如果一个网页任务有稳定状态转移、重复元素和可预测延迟,系统就不该像第一次打开浏览器一样行动。这里真正有价值的是编译边界:每个工具必须说明运行前需要什么状态、运行后保证什么状态。
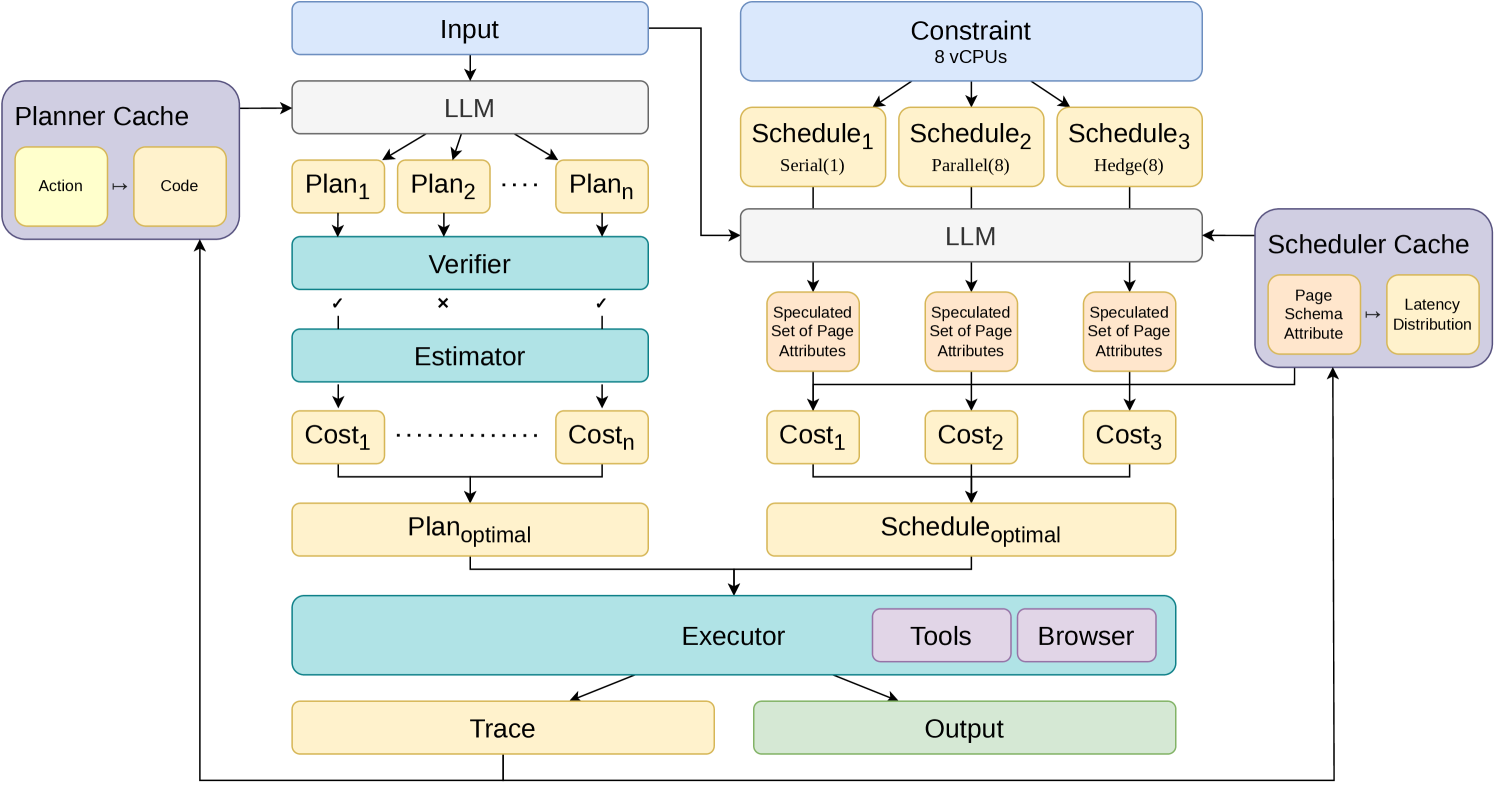
这张图把离线缓存和在线编译连接起来。执行轨迹先沉淀出 planner cache,把动作映射到可复用工具代码;同时沉淀 scheduler cache,把页面元素映射到延迟分布。运行时,JIT-Planner 采样多个代码计划、验证状态流、选择最低成本的有效计划;JIT-Scheduler 再决定应该串行、并行还是 hedge。需要谨慎的是,这套机制依赖网页环境中存在足够可复用的结构,一旦 UI、认证流或后端行为频繁漂移,缓存和延迟模型都要重新维护。
方法可以拆成三步。第一,每个工具暴露 pre、post、可选运行时检查、输入输出 schema 和执行代码;只有当前抽象状态覆盖下一个工具的前置条件时,计划才算静态有效。第二,planner 并行采样多个代码计划,构建控制流图,遇到破坏状态流的计划就提前拒绝,同时统计工具调用和昂贵 ai_eval 调用的成本。第三,scheduler 让模型预测不同策略会接触哪些页面元素,再从离线学习到的延迟分布里做 Monte Carlo 采样,选期望延迟最低的策略。
主结果很直接:
| 模型 | Browser-Use 延迟 | Browser-Use 准确率 | JIT-Planner 延迟 | JIT-Planner 准确率 |
|---|---|---|---|---|
| GPT-4.1 | 150.1 秒 | 61% | 15.4 秒 | 90% |
| Gemini-2.5-Flash | 100.3 秒 | 59% | 7.2 秒 | 94% |
| Gemini-2.5-Pro | 115.9 秒 | 77% | 12.6 秒 | 97% |
在 5 个网页应用上,论文报告 JIT-Planner 相比 Browser-Use 达到 10.4 倍加速和 +28 个百分点准确率。只加缓存的 Browser-Use baseline 有帮助,但没有缩小到同一量级,说明收益不只是缓存截图或 DOM。工具协议也有清晰作用:在计划生成分析里,遵守协议的 manifest 让 GPT-4.1、Gemini-2.5-Flash、Gemini-2.5-Pro 的有效计划率分别提高 +13.0、+10.7、+16.8 个百分点。
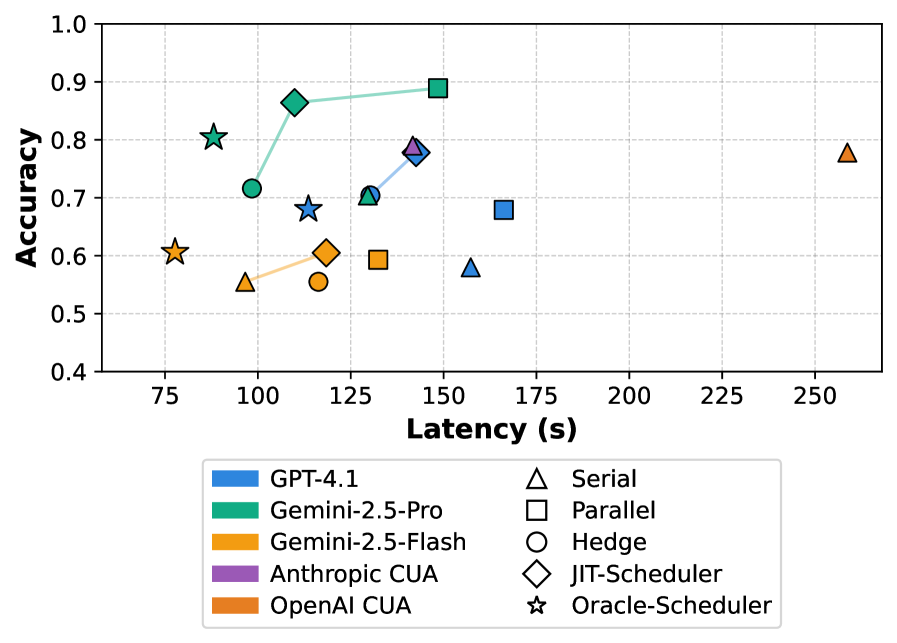
这张图讲的是调度,不是计划生成。它把固定串行、固定并行、固定 hedge 和 JIT-Scheduler 放在同一个延迟-准确率前沿上比较。这里的 claim 不是“并行总是更好”,而是某些网页元素延迟方差很高,适合 hedge;另一些步骤串行反而更稳。把这个结果迁移到任意网站时要小心,因为延迟分布会随 UI、网络路径和后端负载变化。
在 scheduler 设置里,Gemini-2.5-Pro + JIT-Scheduler 达到 109.9 秒、86.4% 准确率,而 OpenAI CUA 是 258.7 秒、77.8%,论文报告为 2.4 倍加速。GPT-4.1 的 JIT-Scheduler 准确率与 OpenAI CUA 同为 77.8%,但时间降到 142.6 秒。Gemini-2.5-Flash 更快但准确率较低,这个细节很重要:调度不能弥补模型规划或感知能力的全部差距。
我的判断:我会继续追这篇,因为它把智能体执行当成系统问题,而不是只当成提示词问题。状态不变量和成本模型被显式拿出来之后,很多错误才有机会在执行前暴露。可能被高估的地方是泛化性:真实网站有不稳定组件、A/B 测试、隐藏权限和后端约束。下一步我想看的是,当应用持续变化时,工具不变量能否自动更新,以及状态流验证能否抓住那些“形式上有效、语义上错误”的计划。
关联主题:computer-use agents、智能体运行时、工具协议、延迟感知执行、可审计状态转移。
Mem-pi: Adaptive Memory through Learning When and What to Generate
作者:Xiaoqiang Wang、Chao Wang、Hadi Nekoei、Christopher Pal、Alexandre Lacoste、Spandana Gella、Bang Liu、Perouz Taslakian
机构:ServiceNow AI Research;Mila - Quebec AI Institute;Université de Montréal;Polytechnique Montréal;McGill University;CIFAR AI Chair
日期:arXiv,2026 年 5 月 20 日
链接:arXiv,arXiv HTML
一句话核心 idea:Mem-pi 不再把智能体记忆只看成相似片段检索,而是训练一个独立语言或视觉语言策略,根据当前任务生成具体 guidance,并且在不该介入时选择 abstain。它先从离线经验库蒸馏,再用下游智能体成败信号做强化学习。
为什么重要:很多 memory agent 的做法是从库里检索一段过去经验塞进上下文。匹配得好时这很有用,匹配得差时就是噪声,甚至会把智能体带偏。对长网页任务、终端任务或具身任务来说,记忆至少要分开回答两个问题:此刻需不需要建议?如果需要,建议具体是什么?
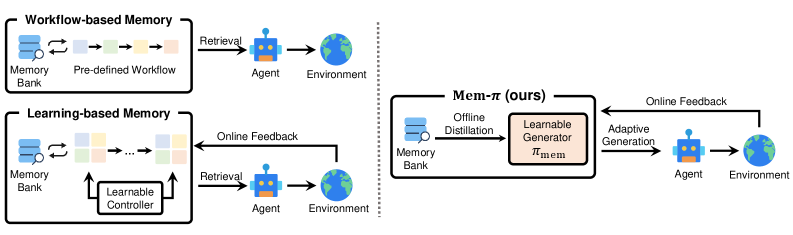
这张图最适合快速理解论文。Workflow-based memory 依赖预设检索和更新流程;learning-based memory 优化记忆操作;Mem-pi 则把可复用经验内化进一个独立生成式策略。这里的关键是“独立”:记忆策略不是下游 agent 本体,因此作者可以单独训练“何时生成、生成什么”,而不必改动基础智能体。风险也在这里:多了一个模型,就多了一个需要监控和审计的行为源。
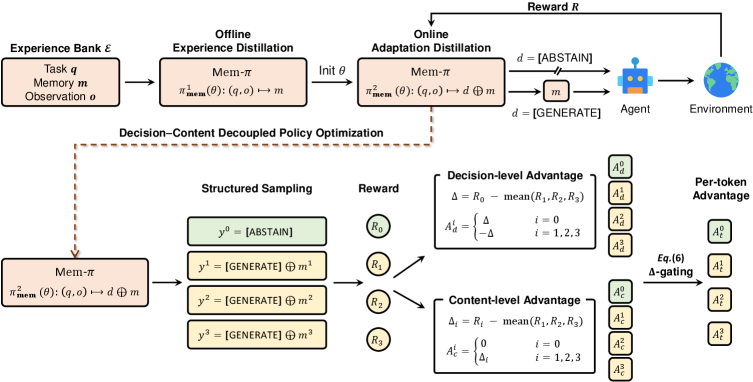
训练分两段。Experience distillation 让记忆模型从离线经验库学习,把任务上下文映射到可复用 guidance。Adaptation distillation 再用智能体执行结果更新策略,每个上下文构造一个结构化 rollout group:一个 [ABSTAIN] 分支,加上多个 [GENERATE] 分支。图里最重要的是 abstention 被当成一个决策来学,而不是最后加一个阈值。
技术关键是 decision-content decoupling。标准 GRPO 会把很短的决策 token 和较长的生成提示混在同一个 token 目标里,导致内容梯度压过“该不该生成”的决策梯度。Mem-pi 把信号拆开:用 abstain 与 generate 的跨分支价值差训练决策 token;只有当生成真正有帮助时,才给 guidance 内容部分更强的正向信号。论文中的奖励设计也对应这个拆分:生成分支使用带 guidance 的任务奖励加记忆质量奖励,abstain 分支使用不加 guidance 的任务奖励。
以 gpt-5.4-mini 为基础智能体的主结果如下:
| 方法 | WebArena 平均 | WorkArena 平均 | ALFWorld 平均 | LAB 平均 | 总平均 |
|---|---|---|---|---|---|
| Base agent | 27.1 | 42.0 | 85.5 | 26.8 | 45.3 |
| RAG | 31.4 | 42.6 | 85.8 | 28.5 | 47.4 |
| Mem0 | 31.9 | 44.1 | 87.2 | 30.0 | 48.4 |
| Memory-R1 | 33.2 | 44.3 | 87.7 | 31.2 | 49.2 |
| MemRL | 34.0 | 46.1 | 87.1 | 31.9 | 50.0 |
| Mem-pi Stage 1 | 35.0 | 46.6 | 90.0 | 34.1 | 51.4 |
| Mem-pi | 43.1 | 50.3 | 91.6 | 36.7 | 55.4 |
最醒目的是 WebArena:基础智能体 27.1,RAG 31.4,Mem-pi 到 43.1。ALFWorld 和 LAB 的绝对增益小一些,因为起点不同,但方向一致。消融也说明两阶段训练不是装饰:去掉 Stage 1,WebArena 从 43.1 掉到 37.9;改成统一单阶段训练掉到 36.3;去掉结构化 rollout 掉到 38.3。
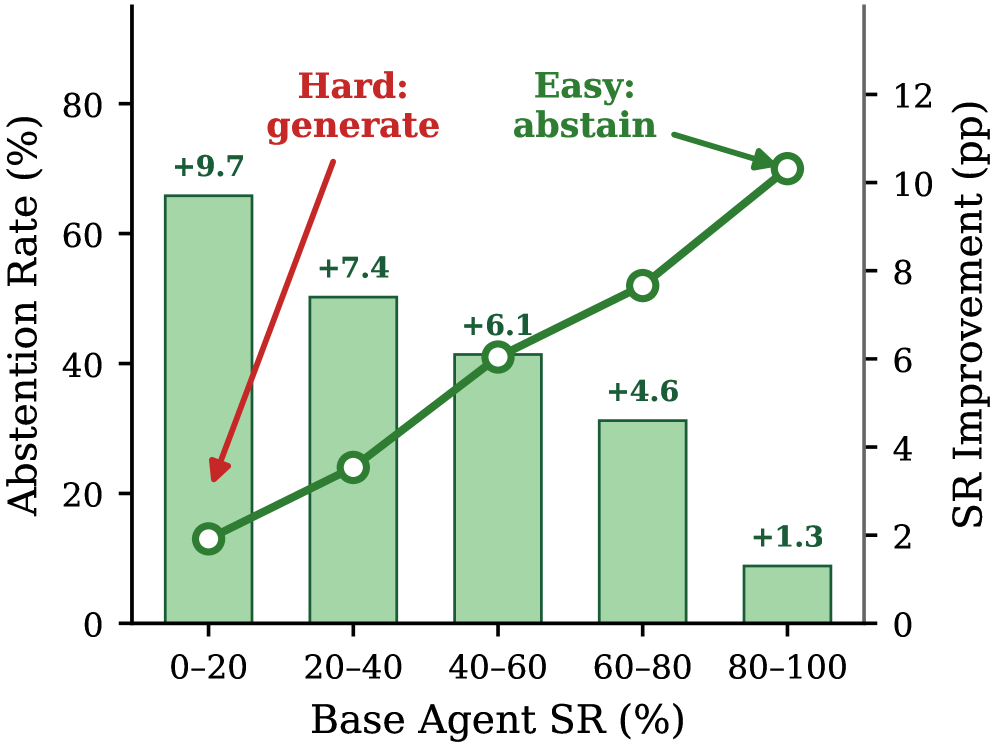
这张图说明 Mem-pi 不是每个任务都硬塞记忆。不同难度分桶里,它的 abstention rate 和相对基础智能体的成功率提升都在变化。我从这里读到的不是某个绝对数值,而是行为模式:有用的记忆应该是选择性的。需要谨慎的是,任务难度分桶来自 benchmark;真实部署中还要有自己的不确定性或难度估计。
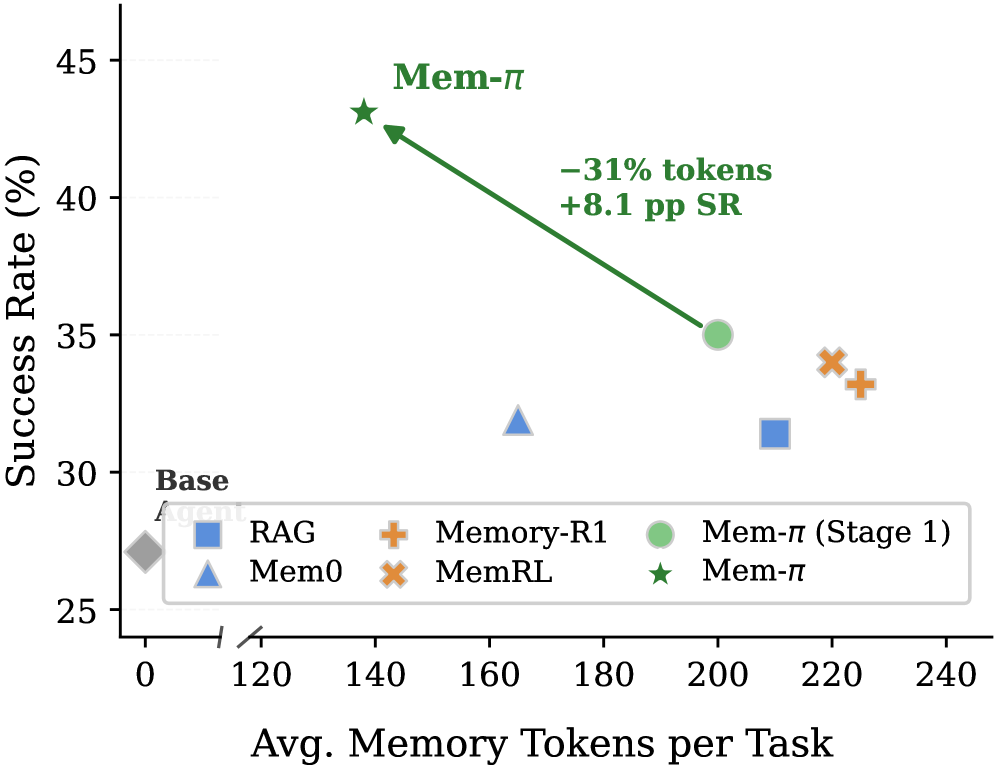
这张 companion 图从另一个切片支持同一件事:更多上下文并不天然等于更好。有些任务需要 guidance,有些任务不需要;学到 abstain 才能避免坏建议污染执行。我下一步最想看校准曲线:当 Mem-pi 选择 [ABSTAIN] 时,在分布变化下这个决定有多大概率真的正确?
我的判断:我会优先看这篇的原因是,它把记忆从“存储层”推进成了“策略层”。结构化反事实 rollout 很实用,因为每个上下文都直接比较 abstain 与 generate。局限也明确:生成式记忆可能编造程序性建议,而且论文主要看任务成功率,还没有完整回答长期记忆治理问题。后续需要追问的是:每条生成 guidance 的来源、置信度、作用和退役规则如何记录?
关联主题:agentic training、自适应记忆、workflow agents、选择性上下文注入、data-agent 运行状态。
DeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation
作者:Sixiong Xie、Zhuofan Shi、Haiyang Shen、Jiuzheng Wang、Siqi Zhong、Mugeng Liu、Chongyang Pan、Peilun Jia、Baoqing Sun、Xiang Jing、Yun Ma
机构:Peking University
日期:arXiv,2026 年 5 月 20 日
链接:arXiv,arXiv HTML,项目页
一句话核心 idea:DeepWeb-Bench 用 100 个深度研究任务评估 agent,每个任务是一个 8×8 的“实体 × 分析维度”矩阵。每个单元格都有参考答案、来源 provenance 和四档评分,因此能区分模型到底错在检索、推导、推理还是校准。
为什么重要:现在很多 deep research 产品已经会搜网页、会引用、会写很长报告。问题是,长报告经常掩盖真正的错误:模型找到正确年报或行业报告后,分母用错、跨来源冲突没处理,或者在公开数据并不存在时硬给一个精确数字。DeepWeb-Bench 关心的正是这类“检索之后”的推导债。
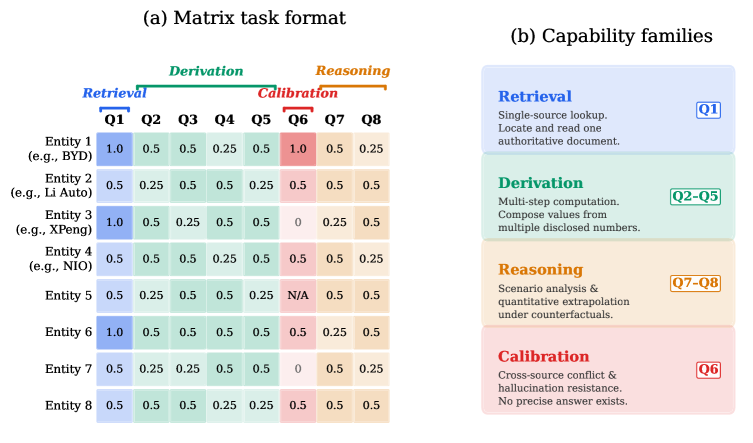
这张图展示了 benchmark 的核心格式。一个任务是 8 行实体和 8 列分析维度,共 64 个独立评分单元格。维度被分到 retrieval、derivation、calibration、reasoning 四类能力里。图里还有 provenance 设计:每个来源记录披露层级和跨来源一致性,这比只给一份最终报告更容易审计。
构造规则是为了减少“靠一个好搜索词碰巧命中答案”的机会。检索型单元格数量受限,非检索单元格通常需要多来源加计算或综合;如果权威来源没有披露,not available 可以是正确答案。评测时,agent 拿到实体列表、维度列表和输出格式,使用同一套 web search、page visit、PDF retrieval 工具。每个任务预算是 200 次工具调用和 30 分钟;空答案得 0。每个单元格按 1、0.5、0.25、0 四档评分,作者还报告了 200 个单元格人工验证与自动 GPT-5.5 grader 的 kappa = 0.82。
100 个任务发布版的主结果:
| 模型 | 总分 | 检索 | 推导 | 校准 | 推理 |
|---|---|---|---|---|---|
| Codex CLI + GPT-5.5 | 33.37 | 37.84 | 32.55 | 34.16 | 32.38 |
| Claude Opus 4.7 | 31.84 | 36.52 | 30.97 | 31.14 | 31.59 |
| DeepSeek V4 Pro | 28.68 | 32.89 | 27.73 | 29.77 | 27.94 |
| GLM 5.1 | 28.18 | 34.19 | 27.06 | 29.56 | 26.70 |
| Claude Sonnet 4.6 | 27.97 | 33.80 | 26.87 | 28.89 | 26.80 |
| 平均 | 27.17 | 32.83 | 26.10 | 27.73 | 26.19 |
绝对分不高,这正是它的价值。检索是平均最高的能力族,达到 32.83;推导和推理更低。论文报告共评分 874/900 个模型-任务对、55,936 个单元格,所以失败分析不是靠几个手挑案例撑起来的。
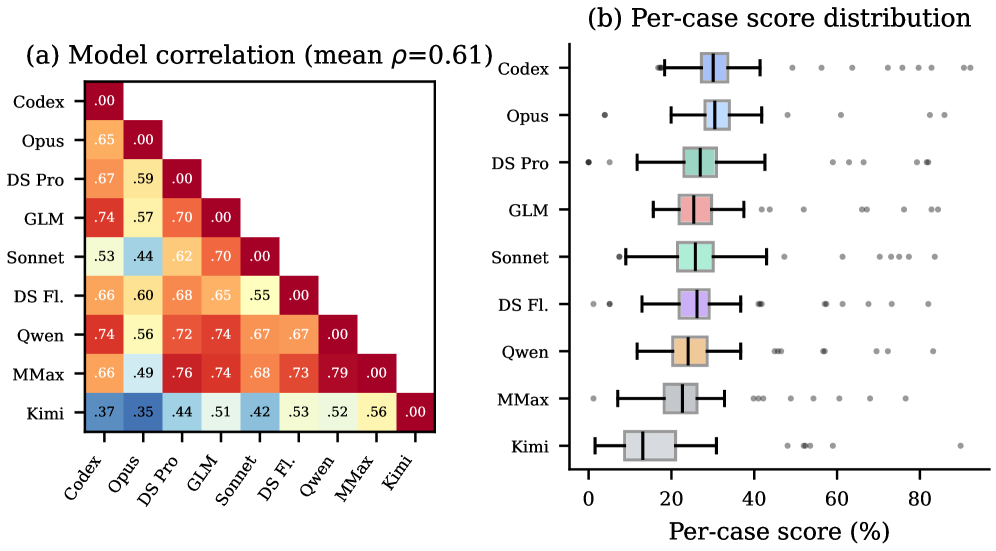
这张图说明模型排名不是固定的。任务级分数的平均 pairwise Spearman 相关为 0.61,意味着不同模型不是在同一批任务上同步失败。这个性质很重要,因为它让 benchmark 不只是一个总分榜单,而能暴露模型的领域和任务专长。限制也要说清楚:这些仍然是公开网页任务和固定工具 harness,不等同于有权限控制、过期内部文档和版本化数据的企业研究环境。
最值得记住的是人工标注的失败模式表:
| 失败模式 | 前四模型 | 其他五个模型 |
|---|---|---|
| 幻觉式精确数字 | 22% | 38% |
| 静默选择来源 | 18% | 14% |
| 推导不完整 | 31% | 24% |
| 范围漂移 | 15% | 12% |
| 检索缺口 | 14% | 12% |
这个表的重点是:retrieval gap 只占 12-14%。更强模型的主要问题是 incomplete derivation,找到中间值后组合错;较弱模型更常见的问题是 hallucinated precision,在没有权威披露时给出自信精确值。两类错误需要不同干预:一个需要更可靠的计算和推导检查,一个需要校准和拒答训练。
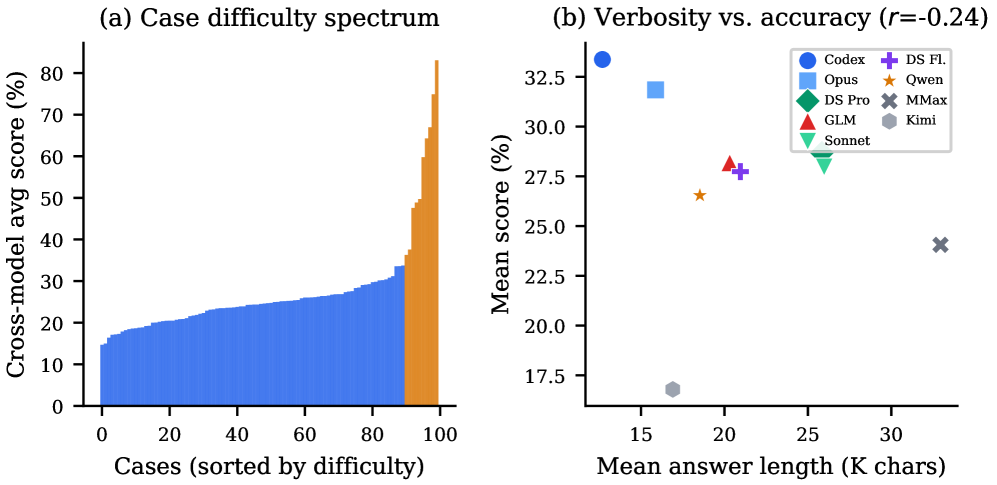
这张诊断图比较了案例难度分布和回答长度与准确率关系。论文报告这里存在负相关,Codex CLI + GPT-5.5 的平均答案最短但总分最高。我不会把它读成“短答案更好”;短而错的推导仍然是错的。更稳妥的结论是:很长的研究轨迹可以掩盖计算错误,所以评测必须拆到单元格和推导链,而不能只看报告是否显得详尽。
我的判断:DeepWeb-Bench 很适合 Paper Radar,因为它把研究智能体的隐藏债务量化出来了。我最看重的是单元格级 provenance 和失败 taxonomy,而不是哪个模型第一。风险在于 judge 依赖和构造成本:自动 GPT-5.5 grader 虽有人类验证,但仍需要持续审计;高质量矩阵任务和来源记录也很费人力。下一步我想看的是,未来版本能否开放足够 reference provenance 供外部审计,同时避免答案泄漏进训练集。
关联主题:文档智能、深度研究智能体、证据 provenance、校准、推导型评测、data-agent 审计轨迹。
阅读优先级和下期问题
我的阅读优先级是 Agent JIT、Mem-pi、DeepWeb-Bench。Agent JIT 最接近真实 computer-use 延迟瓶颈;Mem-pi 的训练思想最有意思,因为它让记忆变成选择性策略;DeepWeb-Bench 是评测锚点,提醒我智能体检索完证据之后,仍然要正确计算、协调来源并知道什么时候该拒答。
接下来我会追几个问题:
- 网页智能体编译器能否在网站变化、隐藏状态漂移时持续维护工具不变量?
- 生成式记忆系统能否为每条 guidance 暴露置信度、来源和退役规则?
- 深度研究 benchmark 能否进入私有文档库、版本化来源和权限控制场景,同时保持可审计?
- 研究智能体训练能否直接针对推导和校准失败,而不是只扩大检索范围?