Compiled Agents, Adaptive Memory, and Derivation Debt
Published:
TL;DR: this round is about the runtime around an agent, not only the agent model. Agent JIT treats web-agent plans as compilable code with state invariants and latency-aware scheduling. Mem-pi turns memory into a small generative policy that can decide not to speak. DeepWeb-Bench shows that deep-research agents often find sources but still fail at derivation, calibration, and cross-source reconciliation.
What I Am Watching This Round
The last few issues were heavy on verifiers, executable worlds, and pre-action inspection. I still care about that thread, but it can become a repeated answer to every problem. For this issue I looked for papers that change how an agent uses its runtime: compile actions before execution, generate memory only when useful, or evaluate whether long research traces actually compute the right thing after retrieval.
I screened recent May 19-20 arXiv and community leads, including Agentic Model Checking, GaussianDream, CoPhy, Structured Layout Priors, ActGuide-RL, runtime architecture patterns for production agents, and several Chinese-media leads around multi-agent systems and scientific protocol generation. I kept three papers because all three had open arXiv HTML, enough method detail, and figures that can carry a mini-explainer without relying on ugly table screenshots.
Paper Notes
Agent JIT Compilation for Latency-Optimizing Web Agent Planning and Scheduling
Authors: Caleb Winston, Ron Yifeng Wang, Azalia Mirhoseini, Christos Kozyrakis
Institutions: Stanford University
Date / venue: arXiv, May 20, 2026; accepted at ICML 2026
Links: arXiv, arXiv HTML
Quick idea: Agent JIT compiles a natural-language web task into executable code plans, checks those plans against tool preconditions and postconditions, and schedules execution using learned latency distributions. The paper is trying to replace the slow screenshot-LLM-action loop with something closer to runtime compilation.
Why it matters: computer-use agents lose a lot of time and accuracy by asking the model to re-decide every click. If a web task has stable state transitions, repeated element types, and predictable latency, then the agent should not behave like it has never seen a browser before. The interesting part here is not only speed. The compiler boundary forces the system to say what state a tool expects before it runs and what state it promises after it runs.
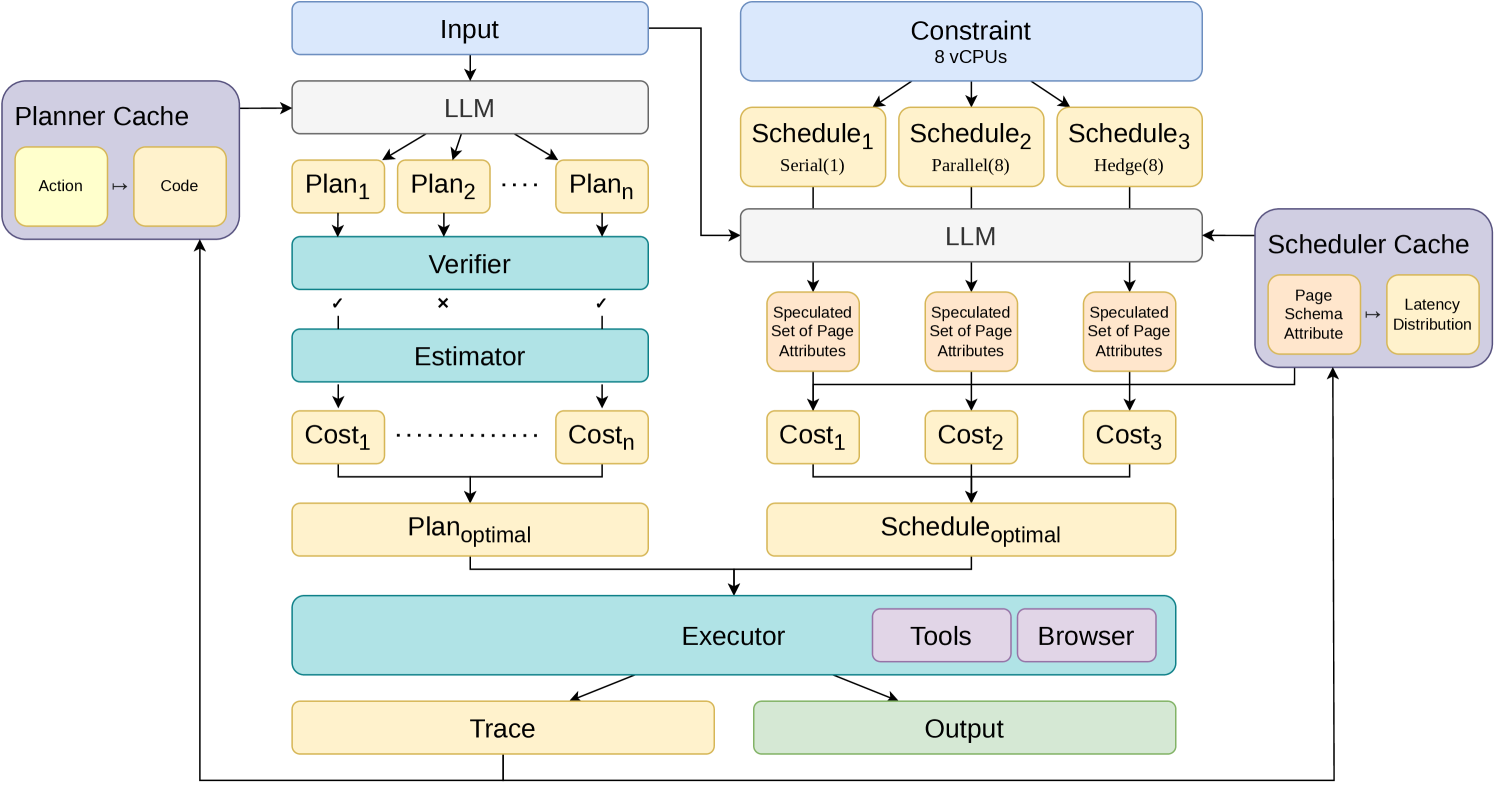
The architecture has an offline cache and an online compiler loop. Execution traces populate a planner cache from actions to reusable tool code, plus a scheduler cache from page elements to latency distributions. At runtime, JIT-Planner samples candidate code plans, validates state flow, and chooses a low-cost valid plan; JIT-Scheduler then decides whether serial execution, parallel execution, or hedged execution is cheapest. The caveat is that this assumes the web environment has enough repeated structure for cached tools and latency models to stay useful.
The method has three moving pieces. First, each tool exposes pre, post, optional runtime checks, type schemas, and implementation code. A plan is statically valid only when the current abstract state covers the next tool’s precondition and the tool’s postcondition updates the state for later calls. Second, the planner samples multiple code plans in parallel, builds a control-flow graph, rejects plans with broken state flow, and estimates cost while traversing tool calls and expensive ai_eval calls. Third, the scheduler asks a model which page elements each strategy will touch, samples learned latency distributions with Monte Carlo trials, and selects the expected low-latency strategy.
The main end-to-end result is unusually concrete:
| Model | Browser-Use latency | Browser-Use accuracy | JIT-Planner latency | JIT-Planner accuracy |
|---|---|---|---|---|
| GPT-4.1 | 150.1 s | 61% | 15.4 s | 90% |
| Gemini-2.5-Flash | 100.3 s | 59% | 7.2 s | 94% |
| Gemini-2.5-Pro | 115.9 s | 77% | 12.6 s | 97% |
Aggregated over five web applications, the paper reports 10.4x speedup and +28 percentage points over Browser-Use. The cache-only Browser-Use baseline helps, but it does not close the gap, which suggests the gain is not just from memoizing screenshots or DOM state. The protocol result is also important: protocol-adherent manifests improve valid plan rates by +13.0 pp for GPT-4.1, +10.7 pp for Gemini-2.5-Flash, and +16.8 pp for Gemini-2.5-Pro in the reported plan-generation analysis.
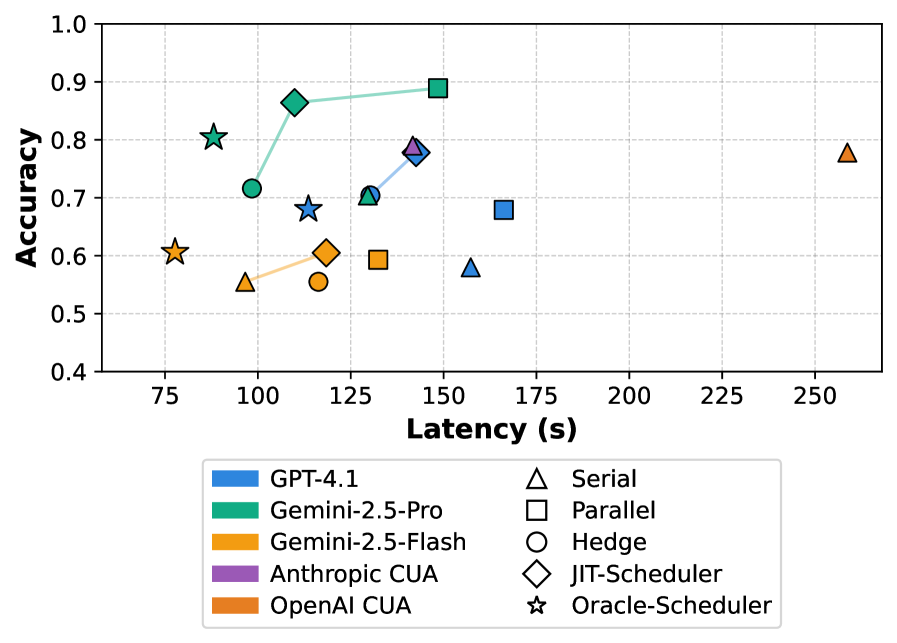
This figure is about scheduling, not planning. It compares fixed serial, parallel, and hedged strategies against JIT-Scheduler and an oracle upper bound, tracing the latency-accuracy frontier across model choices. The useful claim is narrower than “parallelism is always better”: the scheduler adapts because some web elements have high variance and benefit from hedging, while other steps are better left serial. I would be careful about carrying these curves to arbitrary sites, since latency distributions can drift when the UI, network path, or backend load changes.
For the scheduler setting, JIT-Scheduler with Gemini-2.5-Pro reaches 109.9 s and 86.4% accuracy versus OpenAI CUA at 258.7 s and 77.8%, a 2.4x speedup in the paper’s setup. GPT-4.1 matches OpenAI CUA’s 77.8% accuracy while cutting time to 142.6 s. Gemini-2.5-Flash is faster but loses accuracy, which is a useful reminder that scheduling cannot fully compensate for weaker plan or perception quality.
My judgment: I like this paper because it treats agent execution as a systems problem. It makes state invariants and cost models visible instead of hiding them inside repeated LLM calls. The possible overreach is generality: many real websites have unstable widgets, auth flows, A/B variants, and hidden backend constraints. The next thing I would test is whether the invariant protocol can be maintained automatically as apps change, and whether plan validation catches semantic mistakes that still satisfy abstract state flow.
Connection to tracked themes: computer-use agents, agent runtime infrastructure, tool protocols, latency-aware execution, and auditable state transitions.
Mem-pi: Adaptive Memory through Learning When and What to Generate
Authors: Xiaoqiang Wang, Chao Wang, Hadi Nekoei, Christopher Pal, Alexandre Lacoste, Spandana Gella, Bang Liu, Perouz Taslakian
Institutions: ServiceNow AI Research; Mila - Quebec AI Institute; Universite de Montreal; Polytechnique Montreal; McGill University; CIFAR AI Chair
Date: arXiv, May 20, 2026
Links: arXiv, arXiv HTML
Quick idea: Mem-pi replaces retrieval-only agent memory with a dedicated language or vision-language policy that generates context-specific guidance and can abstain when memory would not help. It is trained first by distilling an offline experience bank, then by reinforcement learning from downstream agent outcomes.
Why it matters: most memory-augmented agents retrieve static snippets from a store. That is useful when the matching situation is close, but it can also pollute the context with stale or misleading advice. In long web, terminal, or embodied tasks, memory should answer two questions separately: is advice needed here, and if yes, what advice should be given?
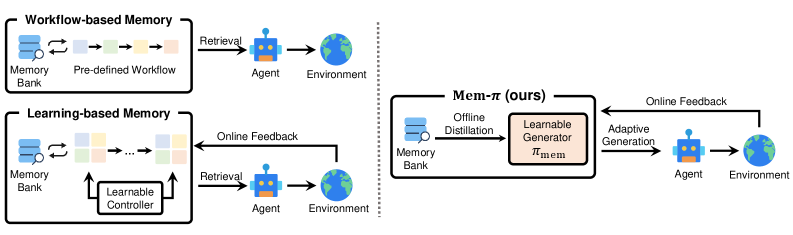
This comparison is the cleanest way to read the paper. Workflow memory has fixed retrieve/update rules, learning-based memory optimizes memory operations, and Mem-pi moves the reusable experience into a separate generative policy. The important design choice is separation: the memory policy is not the downstream agent, so the paper can train “when and what to generate” without changing the base agent itself. The risk is that a second model becomes another component whose failures need monitoring.
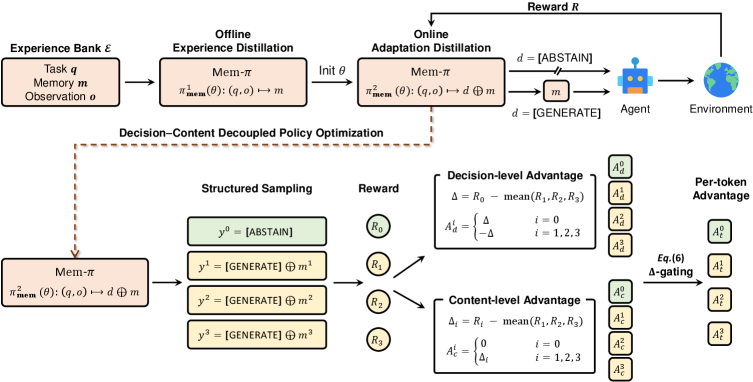
The training pipeline has two stages. Experience distillation teaches the memory model to map a task context, such as a query plus environment observation, to reusable guidance from an offline bank. Adaptation distillation then uses agent outcomes to update the policy with a structured rollout group: one [ABSTAIN] branch and several [GENERATE] branches. This figure supports the paper’s core claim that abstention is learned as a decision, not added as a post-hoc threshold.
The key technical move is decision-content decoupling. Standard GRPO would mix the short decision token with the much longer generated hint, so content gradients can dominate whether the model learns to generate or abstain. Mem-pi instead computes a cross-branch decision signal from the value of abstaining versus generating, and a within-generation content signal only when generation helps. In the paper’s notation, the reward is task success with guidance plus a memory-quality reward for generate branches, and plain task success for abstain branches.
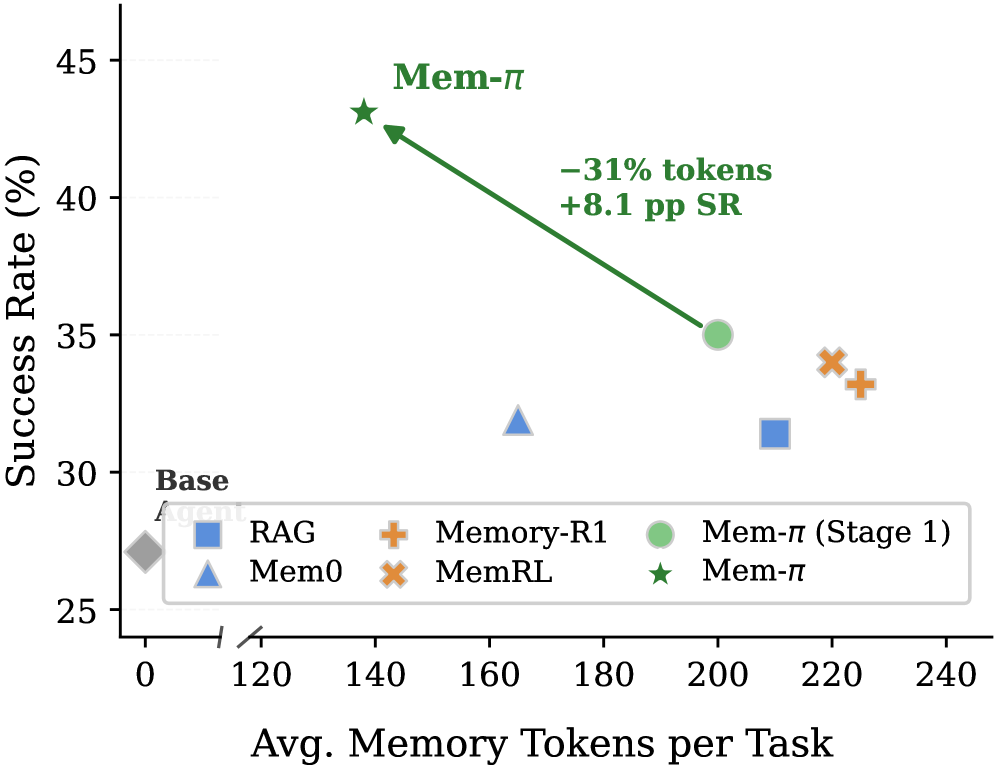
Main success-rate results with gpt-5.4-mini as the base agent:
| Method | WebArena avg | WorkArena avg | ALFWorld avg | LAB avg | Overall avg |
|---|---|---|---|---|---|
| Base agent | 27.1 | 42.0 | 85.5 | 26.8 | 45.3 |
| RAG | 31.4 | 42.6 | 85.8 | 28.5 | 47.4 |
| Mem0 | 31.9 | 44.1 | 87.2 | 30.0 | 48.4 |
| Memory-R1 | 33.2 | 44.3 | 87.7 | 31.2 | 49.2 |
| MemRL | 34.0 | 46.1 | 87.1 | 31.9 | 50.0 |
| Mem-pi Stage 1 | 35.0 | 46.6 | 90.0 | 34.1 | 51.4 |
| Mem-pi | 43.1 | 50.3 | 91.6 | 36.7 | 55.4 |
The web-navigation jump is the clearest signal: WebArena rises from 27.1 for the base agent and 31.4 for RAG to 43.1 for Mem-pi. The gains on ALFWorld and LAB are smaller in absolute terms because the starting point is different, but they are still consistent. The ablations also matter: removing Stage 1 drops WebArena from 43.1 to 37.9, using a unified single-stage setup drops it to 36.3, and removing the structured rollout drops it to 38.3.
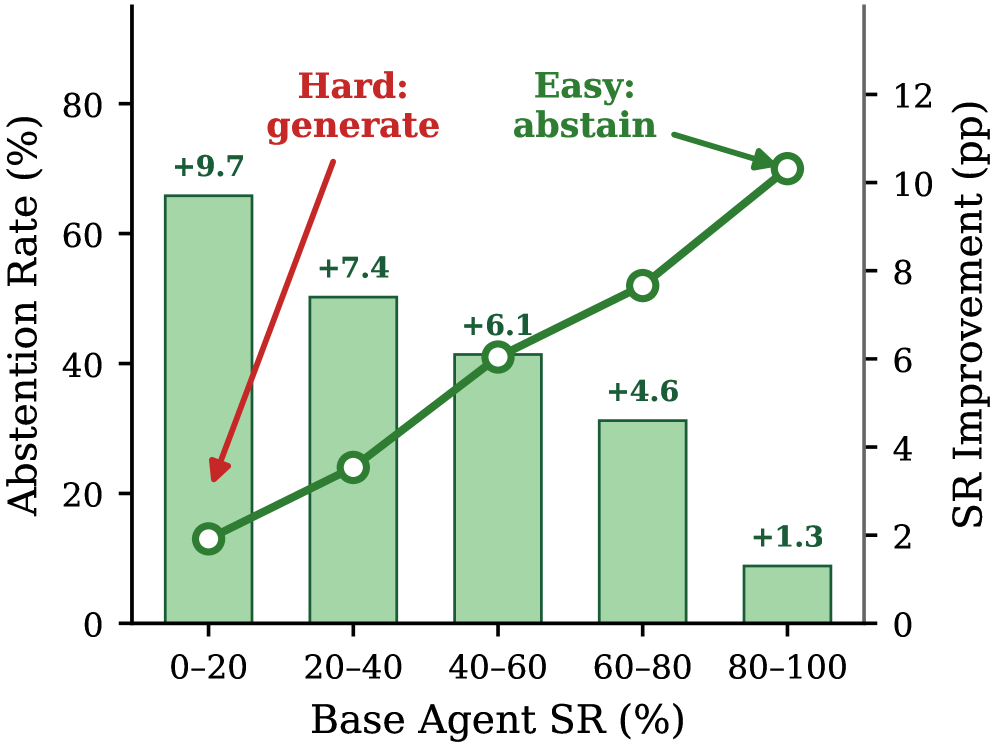
The first abstention plot shows that memory is not simply pasted into every task. Across difficulty bins, the model changes how often it abstains and how much success-rate improvement remains over the base agent. The claim I take from this plot is behavioral: useful memory should be selective. The caveat is that task-difficulty bins are benchmark-defined, so deployment systems would need their own difficulty or uncertainty signals.
The companion plot makes the same point from the second slice of WebArena. It helps separate the memory story from a pure “more context is better” story. Some tasks benefit from guidance, some tasks do not, and the learned abstention decision is supposed to protect the agent from bad advice. I would want a calibration curve next: when Mem-pi chooses [ABSTAIN], how often is that decision actually right under distribution shift?
My judgment: Mem-pi is worth tracking because it turns memory from a storage problem into a policy problem. I especially like the counterfactual rollout design: every context directly compares abstain against generate. The limitation is cost and control. A generative memory model can hallucinate procedural advice, and the paper’s benchmarks still evaluate success more than long-term memory governance. The next hard question is how to log, audit, and retire generated memory guidance after it changes an agent’s behavior.
Connection to tracked themes: agentic training, adaptive memory, workflow agents, selective context injection, and data-agent operating state.
DeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation
Authors: Sixiong Xie, Zhuofan Shi, Haiyang Shen, Jiuzheng Wang, Siqi Zhong, Mugeng Liu, Chongyang Pan, Peilun Jia, Baoqing Sun, Xiang Jing, Yun Ma
Institutions: Peking University
Date: arXiv, May 20, 2026
Links: arXiv, arXiv HTML, project page
Quick idea: DeepWeb-Bench evaluates deep-research agents with 100 tasks, each structured as an 8 by 8 matrix of entities and analytical dimensions. Every cell has a reference answer, source-provenance record, and four-tier score, so the benchmark can tell whether agents fail at retrieval, derivation, reasoning, or calibration.
Why it matters: deep-research products are now good enough that many benchmarks mostly measure whether a model can search and cite something plausible. That is not enough for business, scientific, or policy research. The expensive failure is often after retrieval: the agent finds the right filings or reports, then mixes denominators, ignores source conflict, or invents a precise number where public disclosure does not support one.
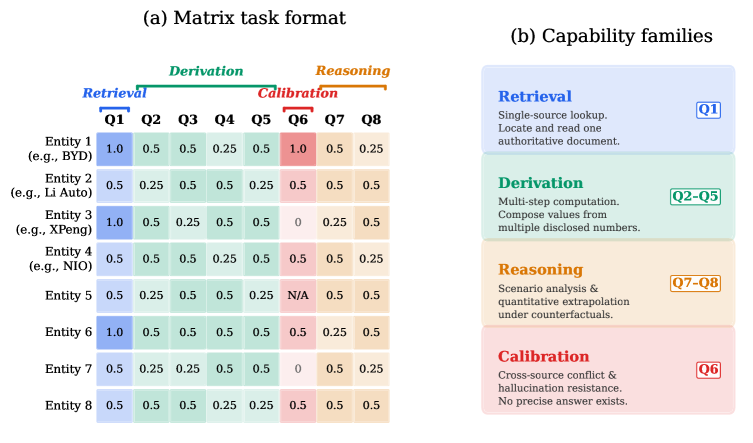
The task format is the main contribution. A task is an 8 by 8 matrix, so a model must fill 64 independently scored cells, each tied to an entity and a research dimension. The dimensions are deliberately split across capability families: retrieval, derivation, calibration, and reasoning. The figure also shows the provenance idea: source records carry disclosure levels and cross-source agreement, which makes the grading target more inspectable than a single final report.
The construction rules are designed to defeat shortcut search. Retrieval-only cells are limited, non-retrieval cells usually require multiple sources plus computation or synthesis, and “not available” can be the correct answer when no authoritative source discloses the value. Agents receive the entity list, dimension list, and output format, with the same web search, page visit, and PDF retrieval tools. The evaluation budget is 200 tool calls and 30 minutes per task; cells without an answer score 0. A fixed four-tier rubric scores each cell as 1, 0.5, 0.25, or 0, and a human validation sample reports kappa = 0.82 agreement with the automated GPT-5.5 grader.
Main results on the 100-task release:
| Model | Overall | Retrieval | Derivation | Calibration | Reasoning |
|---|---|---|---|---|---|
| Codex CLI + GPT-5.5 | 33.37 | 37.84 | 32.55 | 34.16 | 32.38 |
| Claude Opus 4.7 | 31.84 | 36.52 | 30.97 | 31.14 | 31.59 |
| DeepSeek V4 Pro | 28.68 | 32.89 | 27.73 | 29.77 | 27.94 |
| GLM 5.1 | 28.18 | 34.19 | 27.06 | 29.56 | 26.70 |
| Claude Sonnet 4.6 | 27.97 | 33.80 | 26.87 | 28.89 | 26.80 |
| Mean | 27.17 | 32.83 | 26.10 | 27.73 | 26.19 |
The absolute scores are low, which is the point. Retrieval is the highest family at 32.83 mean, while derivation and reasoning are lower. The paper reports 55,936 scored cells across 874 of 900 model-task pairs, which gives the failure analysis more texture than a small set of case studies.
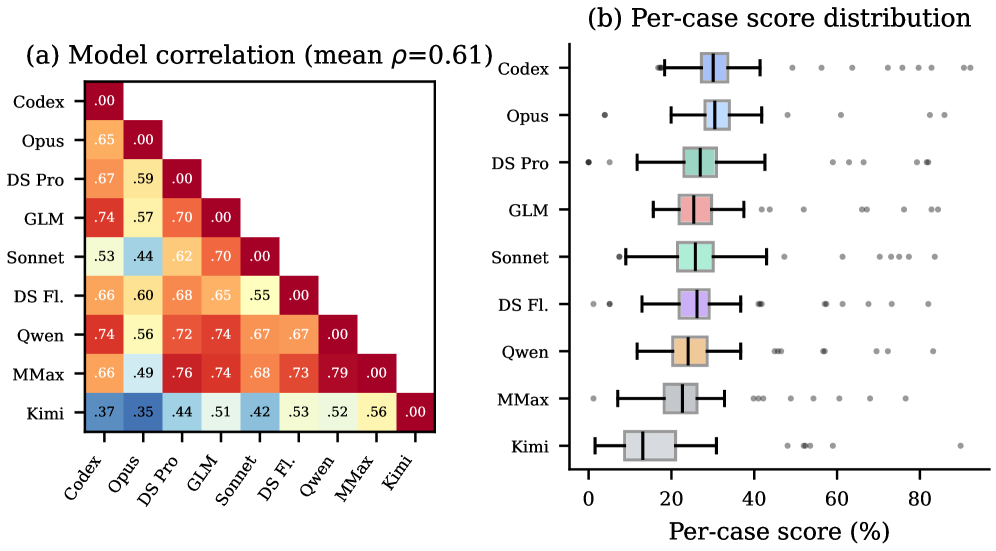
This figure shows that model rankings are not fixed across cases. The mean pairwise Spearman correlation is 0.61, so models do not fail on exactly the same tasks. That is a useful benchmark property because it means a single leaderboard average hides real specialization. The caveat is that these are still public-web tasks with a fixed harness, not private enterprise research with access controls and stale internal documents.
The most interesting table is the human-labeled failure breakdown:
| Failure mode | Top four models | Other five models |
|---|---|---|
| Hallucinated precision | 22% | 38% |
| Silent source choice | 18% | 14% |
| Incomplete derivation | 31% | 24% |
| Scope drift | 15% | 12% |
| Retrieval gap | 14% | 12% |
The headline is easy to miss: retrieval gaps are only 12-14% of failures. For stronger models, incomplete derivation dominates. For weaker models, hallucinated precision dominates. This is exactly the sort of distinction deep-research evaluation needs, because “use better search” and “train calibrated abstention” are different interventions.
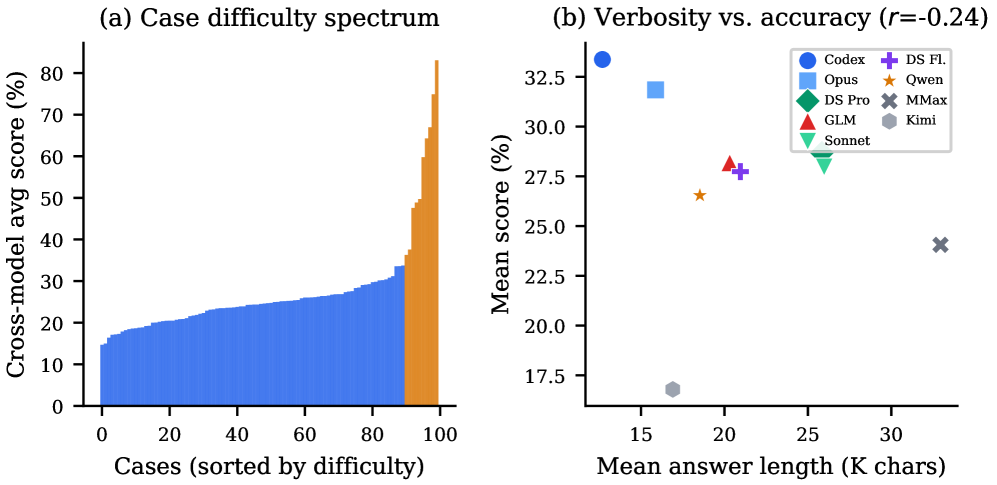
This diagnostic compares cross-model difficulty and answer verbosity. The paper reports a negative verbosity-accuracy relation in this plot, with Codex CLI + GPT-5.5 producing the shortest average answers among the compared systems while scoring highest. I would not over-read that as “short is better”; a terse wrong derivation is still wrong. The safer lesson is that long research traces can hide computation errors, so benchmarks need cell-level derivation checks instead of judging reports by apparent thoroughness.
My judgment: DeepWeb-Bench is a strong fit for Paper Radar because it makes the hidden debt in research agents measurable. The valuable part is the cell-level provenance and failure taxonomy, not just the leaderboard. The risk is judge dependence and construction cost. The benchmark uses an automated GPT-5.5 grader with human validation, and building 100 high-quality matrix tasks with source records is labor-intensive. I would watch whether future releases expose enough reference provenance for external audit without leaking the answer key into model training.
Connection to tracked themes: document intelligence, deep research agents, evidence provenance, calibration, derivation-heavy evaluation, and data-agent audit trails.
Reading Priority and Next Questions
My reading priority is Agent JIT first, then Mem-pi, then DeepWeb-Bench. Agent JIT is closest to an implementation pattern that could change real computer-use latency. Mem-pi is the most interesting training idea because it makes memory selective. DeepWeb-Bench is the evaluation anchor: it reminds me that after agents retrieve evidence, they still need to compute, reconcile, and abstain correctly.
Questions I would track next:
- Can web-agent compilers keep tool invariants current when sites change and hidden state drifts?
- Can generative memory systems expose confidence, provenance, and retirement rules for each piece of guidance?
- Can deep-research benchmarks evaluate private corpora with versioned sources and access control without losing auditability?
- Can training data for research agents target derivation and calibration failures rather than only retrieval breadth?