Hard Evidence for Data and Workflow Agents
Published:
TL;DR: this round is about evaluation objects getting harder. The four papers I chose are not mainly asking whether an agent writes a plausible answer. They ask whether it can pass an executable scientific checker, infer a hidden predictive intent from a table, hit an exact GUI state, or deploy a reward only when the learner is competent enough for that reward to mean something.
What I Am Watching This Round
The last few issues kept returning to explicit state, replayable workspaces, and middle layers. I did not want to repeat that story. The newer thread I see here is a bit sharper: data and workflow agents are being forced to expose the thing they acted on. A benchmark now carries a runnable environment, a table question carries a latent prediction task, a GUI instruction carries exact state labels, and a generated reward is treated as a hypothesis that must survive forked verification.
That feels like progress. It is also uncomfortable, because the numbers are still low. The useful part of this issue is not that agents suddenly look solved. It is that the failure surface is becoming more inspectable.
Paper Notes
D3-Gym: Constructing Real-World Verifiable Environments for Data-Driven Discovery
Authors: Hanane Nour Moussa, Yifei Li, Zhuoyang Li, Yankai Yang, Cheng Tang, Tianshu Zhang, Nesreen K. Ahmed, Ali Payani, Ziru Chen, Huan Sun.
Institutions: The Ohio State University, Cisco Research.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML | artifacts
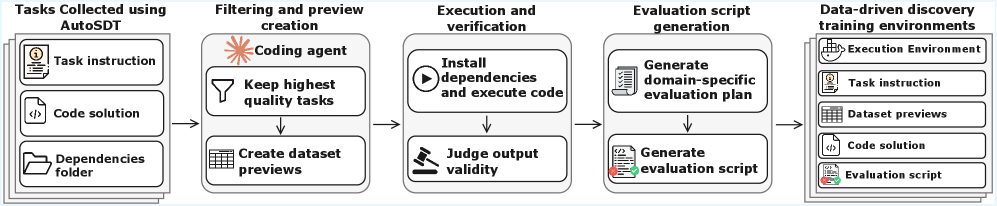
This figure is the paper’s core move: a scientific repository is not just text for an agent to read, it can be turned into an executable task with data previews, reference outputs, and a verification script. The important claim is not that every scientific workflow can be automated this way, but that a data-agent benchmark should include the environment needed to check the work. The caveat is that automatic construction still depends on filtering and validation, so the benchmark is only as trustworthy as that pipeline.

The statistics figure shows why D3-Gym is more than a toy coding set. The 565 tasks come from 239 real scientific repositories across four disciplines, with varied task types, input/output modalities, packages, and difficulty levels. I read this as the dataset’s best defense against overfitting to one neat class of notebook problems, although it still cannot cover the full mess of scientific practice.
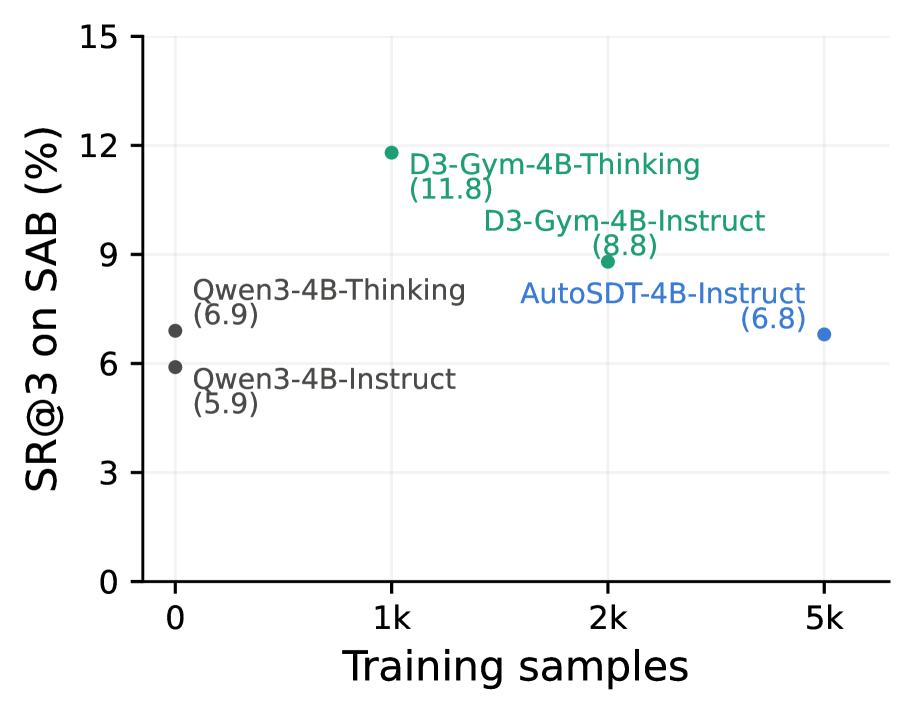
These curves show the training signal doing work on the lower-difficulty setting. The key thing to watch is not only success rate, but valid execution rate: a model that writes code that cannot run has not solved a data-discovery task. The figure supports the paper’s claim that trajectory training improves both scientific correctness and executability.
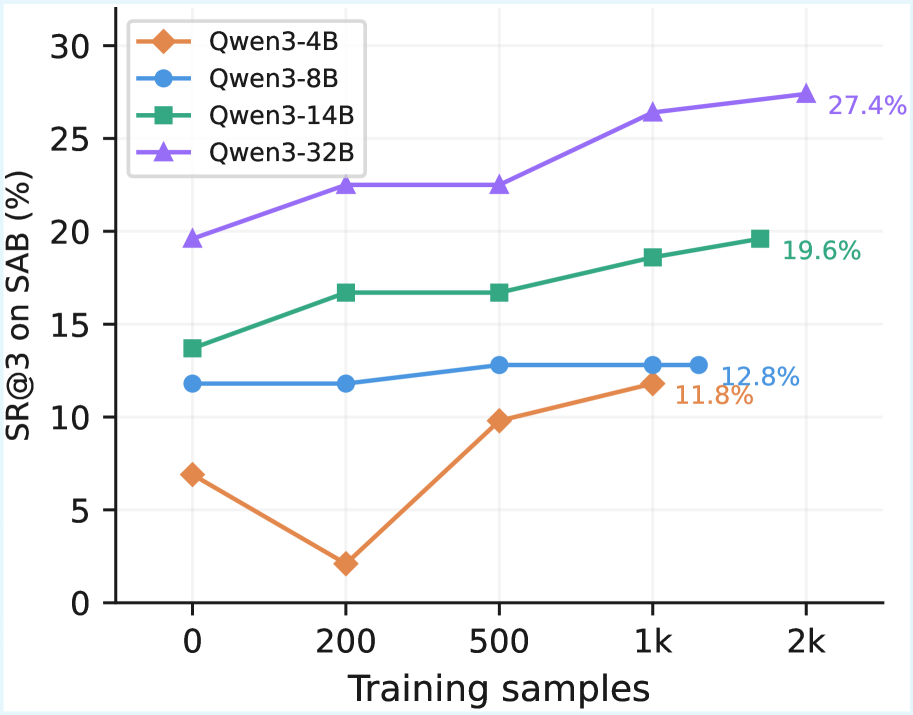
The high-difficulty curves make the same point under a harder regime. The paper reports that D3-Gym trajectory training raises Qwen3-32B by 7.8 absolute points in best-of-three success on ScienceAgentBench, with gains also visible on the verified revision. The cautious reading is that D3-Gym is a useful training substrate, not proof that open models now match strong proprietary scientific agents.
Quick idea: D3-Gym turns real scientific repositories into runnable, verifiable environments for data-driven discovery agents.
Why it matters: a data agent should not be evaluated only by whether it explains an analysis. It should produce an artifact that can be executed, inspected, and scored against a task-specific scientific criterion. D3-Gym pushes evaluation toward that harder object.
Method walkthrough:
- Collect candidate scientific tasks from real repositories and filter them for runnable, data-driven discovery workflows.
- Create dataset previews and reference outputs so the agent has enough context to write a solution without being given the answer.
- Generate silver evaluation scripts through a planning step that specifies target artifacts, metrics, thresholds, and tolerances.
- Validate the resulting scripts against human-written gold scripts, then use the environments and trajectories for model training.
Evidence: the dataset contains 565 tasks from 239 repositories. On a 50-task validation set, the silver evaluation scripts reach 87.5% pass/fail agreement with gold scripts, while ablations show that removing planning or dataset previews damages evaluation quality. Training on D3-Gym trajectories improves Qwen3 models across scales; the largest model’s best-of-three success gain is reported as +7.8 points on the original ScienceAgentBench and +8.4 on the verified version.
Why I care: this is the kind of benchmark data-agent work I want more of. It does not let a model hide behind a fluent report. The output has to run, and the verifier has to encode what counts as a scientifically acceptable artifact.
Limitations/questions: the authors acknowledge environment scale and training method limits, and I would add one more concern: automatic evaluation scripts can become their own hidden benchmark bias. The next thing to chase is whether these generated verifiers transfer to messy repositories that were not selected for clean execution.
Connection to the tracked themes: data agents, agentic training, executable verification, scientific workflows.
TopBench: A Benchmark for Implicit Prediction and Reasoning over Tabular Question Answering
Authors: An-Yang Ji, Jun-Peng Jiang, De-Chuan Zhan, Han-Jia Ye.
Institutions: not specified on the arXiv HTML page.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML | benchmark
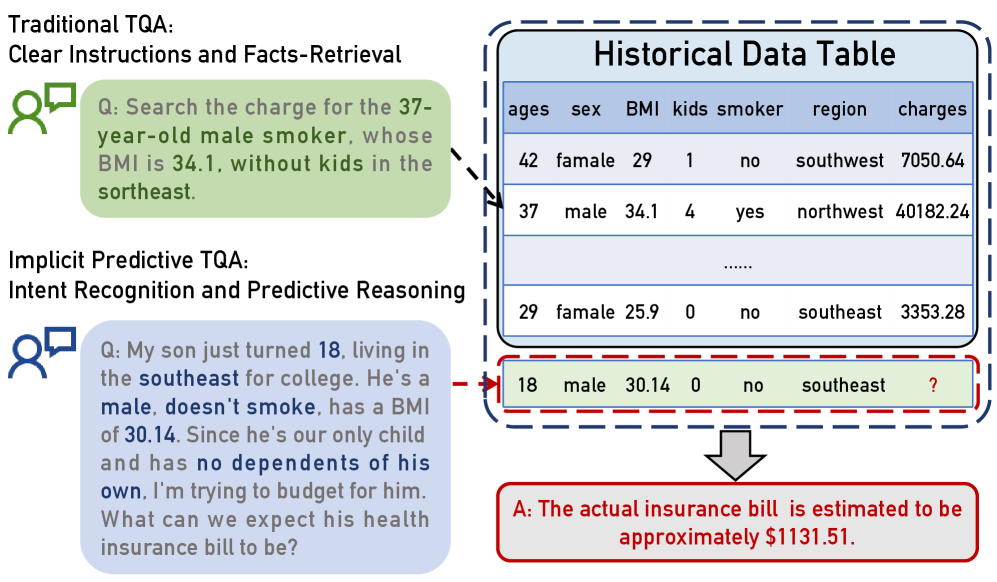
This figure is the cleanest explanation of TopBench. Traditional table QA asks for a lookup, aggregation, or explicit calculation; TopBench asks the model to notice that the user is asking for an unobserved outcome. That small shift changes the task from table reading into intent recognition plus predictive modeling.
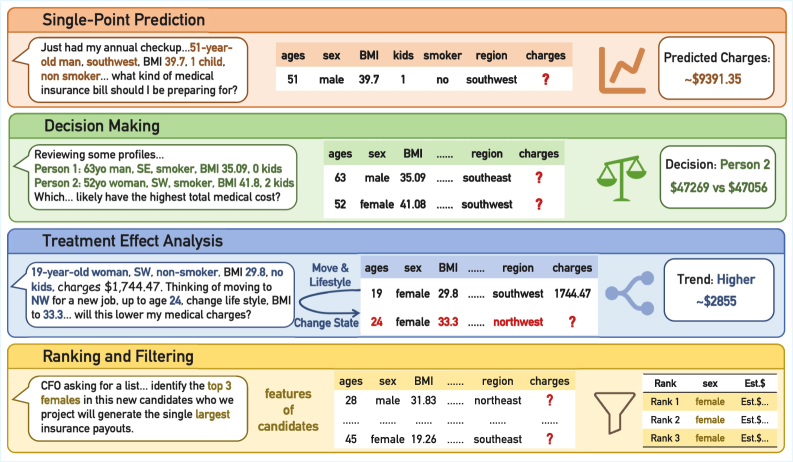
The benchmark overview lays out four task families: single-point prediction, decision making, treatment-effect analysis, and ranking/filtering. The design matters because it forces a model to produce both reasoning text and structured outputs, rather than only a final scalar answer. The caveat is that the relevant historical table is already paired with each query, so this is still one step short of open-ended data discovery.
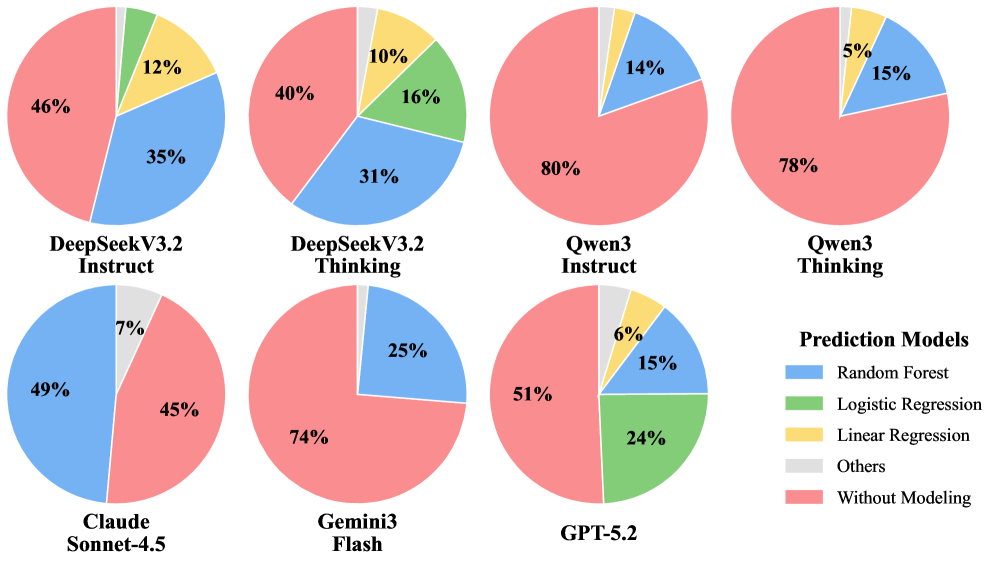
The tool-usage figure explains a lot of the benchmark behavior. Some models reach for ML libraries, while others fall back to simple data manipulation even when the query is predictive. This supports the paper’s diagnosis that intent disambiguation is a bottleneck: if the model thinks the problem is a lookup, better code execution will not fix the reasoning error.
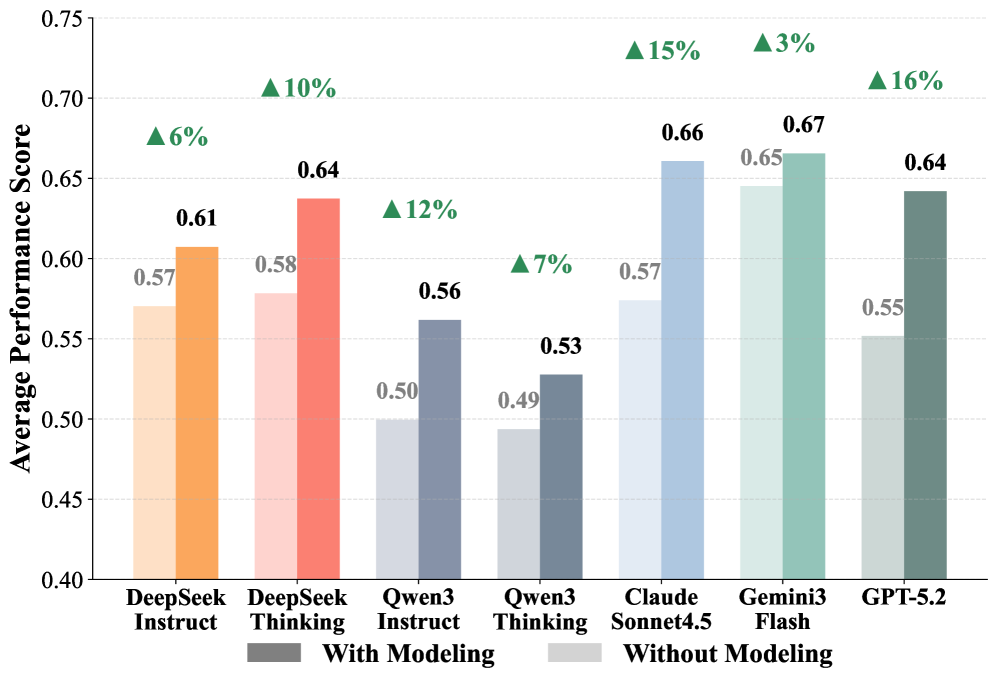
The modeling-impact figure isolates whether predictive modeling itself helps. The paper’s stronger upper-bound experiment reports that a predict-only ensemble beats Gemini 3 Flash’s end-to-end agentic setup on single-point, decision, and treatment tasks. That is a useful warning: current agents may have access to tools, but they do not consistently choose the right modeling abstraction.
Quick idea: TopBench tests whether a model can infer that a table question is really a prediction problem.
Why it matters: many business and scientific data tasks are phrased as ordinary questions, but the answer is not present in the table. The agent has to identify a latent modeling intent, choose the right historical signals, and return a result with the right structure. This is close to the failure mode I see in real data-agent workflows: the model confidently answers the wrong task.
Method walkthrough:
- Build 779 queries from 35 source tables across finance, healthcare, and consulting-style domains.
- Split tasks into single-point prediction, decision making, treatment effect analysis, and ranking/filtering.
- Evaluate both text-only reasoning and agentic code-execution workflows, with task-specific metrics for accuracy, logic, recall, NDCG, NMAE, and F1.
- Analyze whether models use predictive tools, whether semantic hints help, and whether dedicated predictive models expose a higher ceiling.
Evidence: the main results show that no evaluated model dominates the benchmark. Gemini 3 Flash is strong in several agentic settings, Claude Sonnet 4.5 does well on classification-style and ranking outputs, and general LLMs substantially outperform tabular specialists that were trained for more explicit table QA. The ablations are more informative than the leaderboard: richer semantic information helps some tasks but not uniformly, and the predict-only ensemble reaches 0.76, 0.72, and 0.69 on the three core predictive tasks where Gemini’s end-to-end agentic scores are 0.66, 0.65, and 0.65.
Why I care: TopBench is useful because it refuses to treat “table understanding” as retrieval. That is exactly the trap in data-agent products: a user asks a natural-language question, and the system answers the easiest literal version instead of the intended analytical one.
Limitations/questions: the paper is explicit that the relevant table is provided. The harder future task is full-stack data intelligence: retrieve or construct the right historical table, identify the predictive intent, run the model, and explain the uncertainty. TopBench covers the middle of that pipeline, which is already enough to expose serious gaps.
Connection to the tracked themes: data agents, document intelligence, tabular reasoning, intent disambiguation.
FineState-Bench: Benchmarking State-Conditioned Grounding for Fine-grained GUI State Setting
Authors: Fengxian Ji, Jingpu Yang, Zirui Song, Yuanxi Wang, Zhexuan Cui, Yuke Li, Qian Jiang, Xiuying Chen.
Institutions: MBZUAI, United Arab Emirates; Northeastern University, China.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML | benchmark
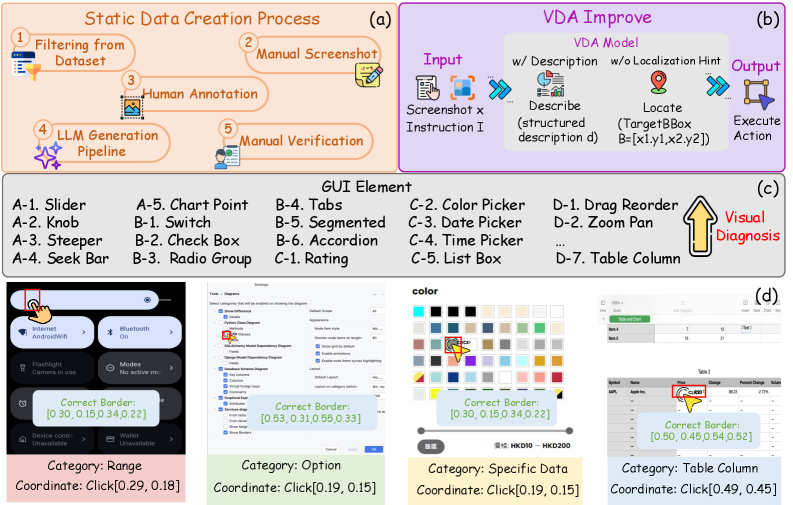
FineState-Bench starts from a simple but punishing idea: clicking the right control is not the same as reaching the right state. The benchmark therefore records the target state, the current locate box, and the interactable operation region. This makes a GUI-agent failure easier to attribute than a binary task-success score.
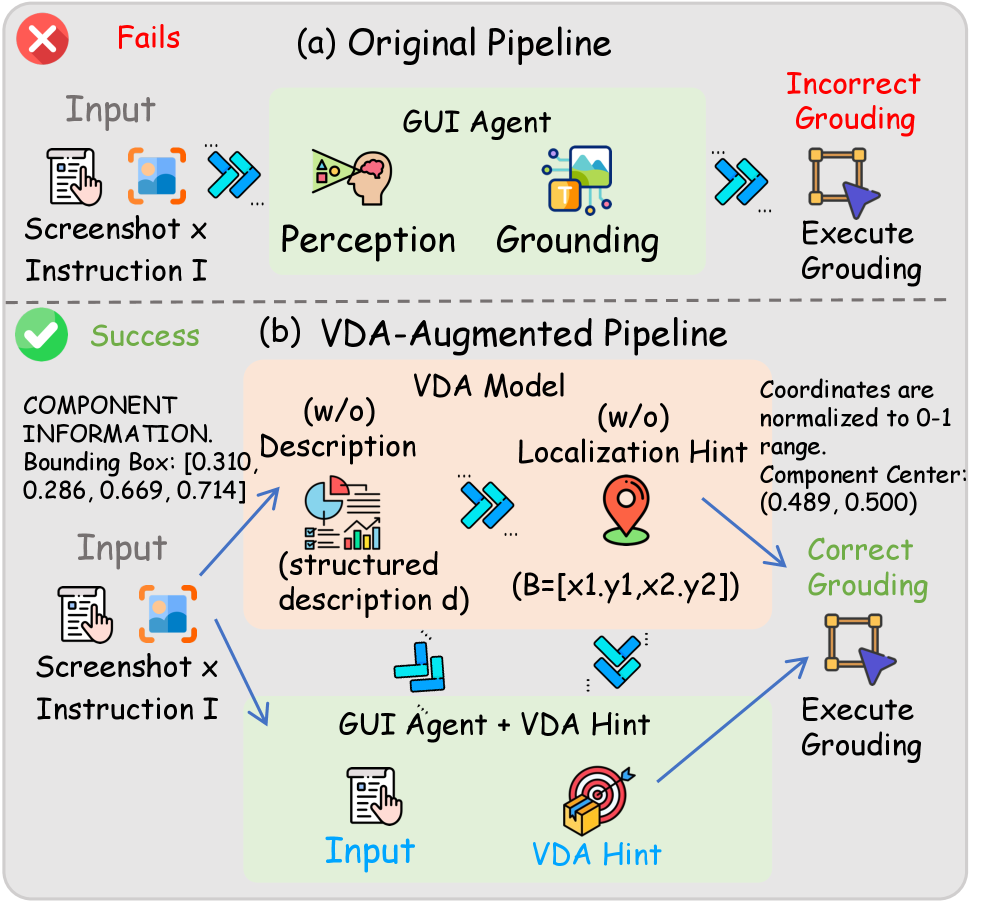
The Visual Diagnostic Assistant is not presented as a deployable agent component. It is a controlled diagnostic: add a description or localization hint and see which bottleneck moves. The figure matters because it turns visual grounding from a vague complaint into a measurable intervention.

The instance figure shows why the task is harder than standard element grounding. Sliders, seek bars, color controls, steppers, tree views, and mobile/web/desktop components all have different relationships between visible control extent and the exact point that changes state. A model can localize the widget and still miss the operational core.
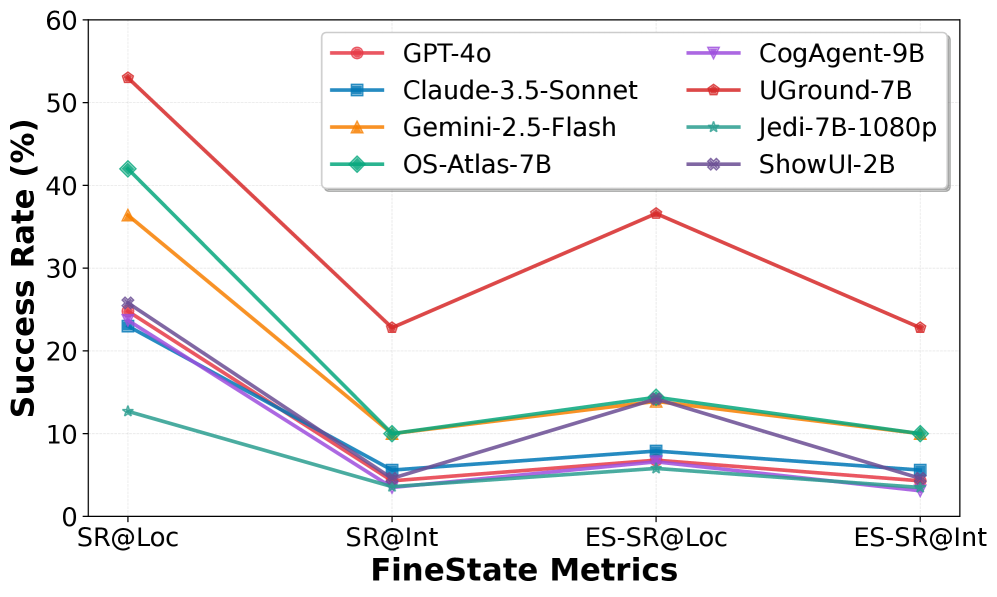
This degradation plot is the uncomfortable part. Even when models recognize the right region, exact state setting collapses sharply for many component types. The paper reports that ES-SR@Int peaks at 32.8% on Web and averages 22.8% across platforms, so current agents are still far from reliable fine-grained GUI control.
Quick idea: FineState-Bench evaluates whether GUI agents can reach an exact target state, not just point at the right UI element.
Why it matters: a production GUI agent often fails in small ways that are hard to catch. It sets a slider slightly wrong, chooses the wrong item in a tree, or clicks the visible widget but not the state-changing area. FineState-Bench gives those failures a vocabulary.
Method walkthrough:
- Construct 2,209 static GUI instances across desktop, web, and mobile platforms.
- Cover four interaction families and 23 UI component types, each with exact target-state labels.
- Annotate dual geometric regions: a broad locate box and a narrower interactable-core box under current and target configurations.
- Score agents with stage-wise metrics: SR@Loc, SR@Int, ES-SR@Loc, and ES-SR@Int, then use VDA hints to isolate visual grounding bottlenecks.
Evidence: the baseline results are stark. The best average ES-SR@Int is 22.8%, and even strong models often show a large gap between locating a component and hitting the interactable core. With VDA localization hints, Gemini 2.5 Flash improves by 14.9 points in average ES-SR@Int, and the ablation shows that localization hints matter much more than textual descriptions alone. That points to visual grounding precision, not only instruction understanding.
Why I care: this paper is a good antidote to vague GUI-agent demos. It asks for exact post-interaction state, which is what users actually care about. I also like that it is intentionally narrow: it gives up long-horizon interaction so it can diagnose one failure mode cleanly.
Limitations/questions: the authors note that this is a static, single-point setting. That is a feature for diagnosis, but it does not model recovery, scrolling, multi-step correction, or live interface dynamics. The next step is to connect FineState-style exact-state labels to interactive rollouts without losing the clean attribution.
Connection to the tracked themes: GUI agents, document/interface intelligence, state-conditioned grounding, agent evaluation.
RHyVE: Competence-Aware Verification and Phase-Aware Deployment for LLM-Generated Reward Hypotheses
Authors: Feiyu Wu, Xu Zheng, Zhuocheng Wang, Yi ming Dai, Hui Li.
Institutions: School of Cyber Engineering, Xidian University.
Date/Venue: April 30, 2026, arXiv preprint.
Links: arXiv | HTML
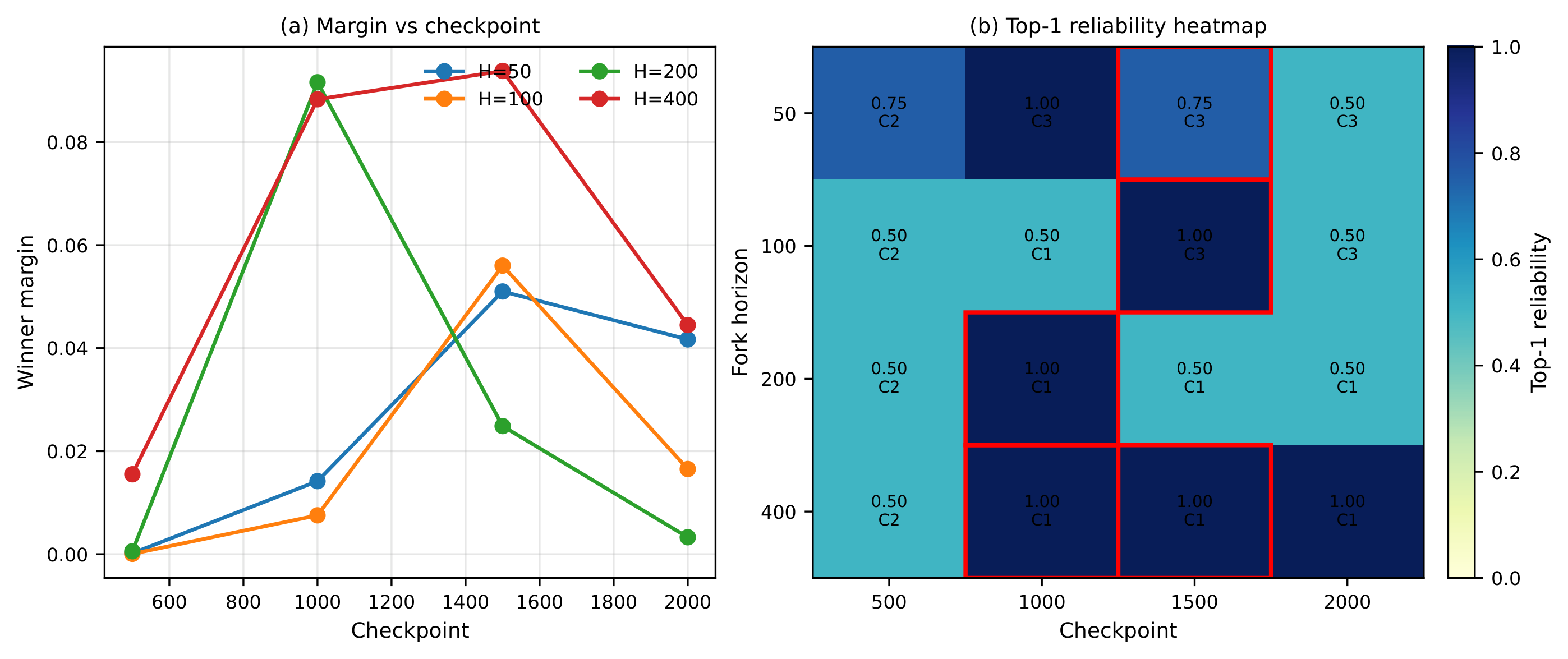
This figure captures the reason RHyVE belongs in this issue. A reward candidate is not treated as a static score function that is good or bad forever. It is verified from shared policy checkpoints, because a low-competence policy may be unable to reveal whether a reward will become useful later.
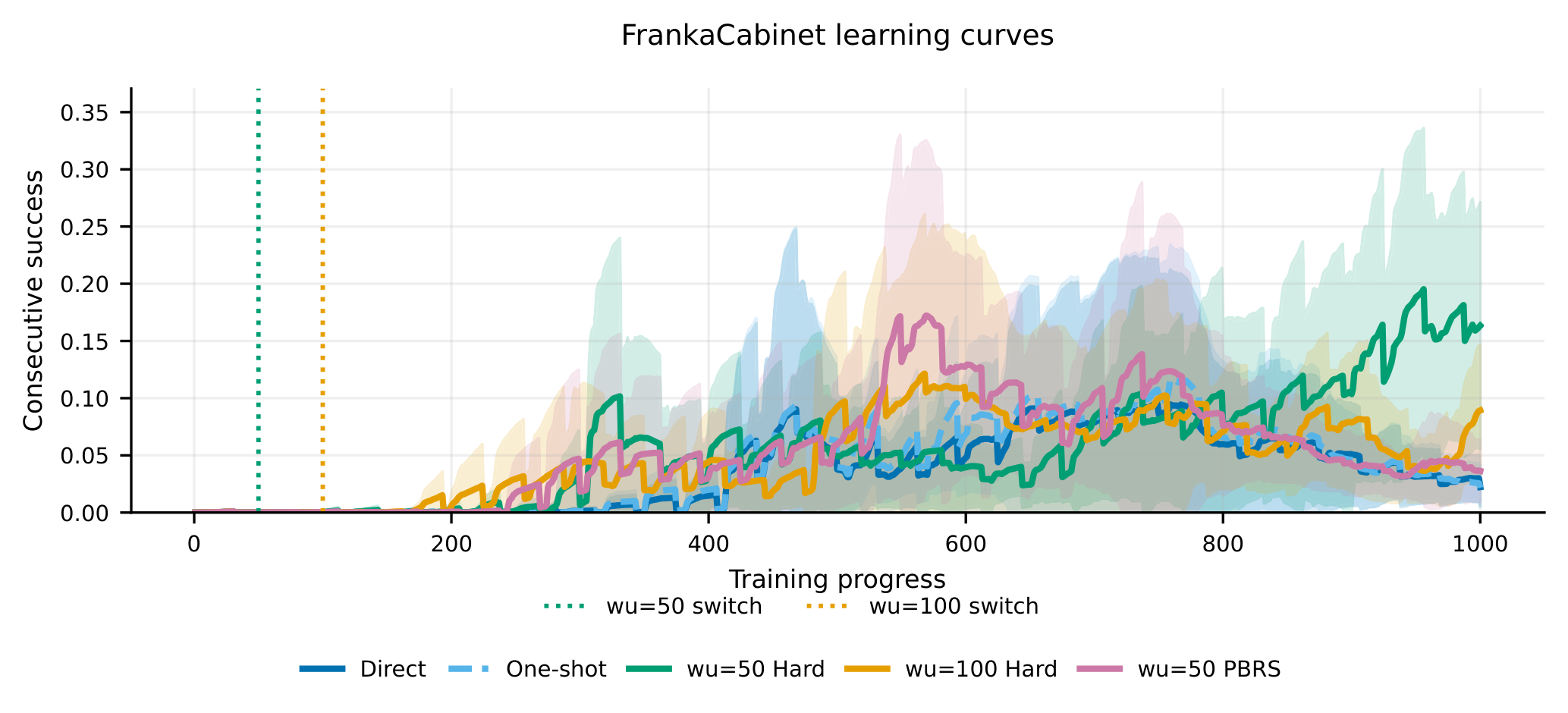
The learning curves show why phase matters. On the locked FrankaCabinet setup, the fixed warm-up then hard-switch schedule improves both peak and retained behavior over direct deployment in the structured reward family. The authors are careful about the scope: this is not a universal scheduler, and high seed variance still limits broad claims.
Quick idea: RHyVE treats LLM-generated rewards as hypotheses whose usefulness depends on policy competence and training phase.
Why it matters: agentic training increasingly leans on generated reward functions, but reward generation and reward deployment are different problems. A reward that is informative after the policy reaches the cabinet handle may be misleading before the policy can even get near it. RHyVE makes that timing issue explicit.
Method walkthrough:
- Define reward candidates as hypotheses rather than fixed objectives.
- Fork short rollouts from shared policy checkpoints to compare candidate rewards at matched competence levels.
- Build phase profiles that show when reward rankings become informative.
- Deploy rewards through direct, scheduled, held-out selected, or conservative rules, then test boundary cases where phase-aware deployment should not help.
Evidence: in the structured FrankaCabinet comparison, the fixed warm-up 50 hard-switch rule reports the strongest mean peak performance and the strongest recomputed final performance among the locked methods. Direct and one-shot deployment stay low in final and tail metrics, while phase-aware deployment retains more behavior. The LLM-generated reward-candidate experiments are messier, which is actually useful: the best deployable rule changes by candidate family, and no fixed warm-up schedule is universally optimal.
Why I care: this is a reward-design paper with an evaluation mindset. It says the right question is not only “can an LLM propose a reward?” but “when does this reward become a reliable training signal for the learner we have now?”
Limitations/questions: the authors are careful not to overclaim. RHyVE does not solve reward switching, does not guarantee safe deployment, and cannot rank rewards when the underlying task/reward setup is not learnable. I would want to see the same idea applied to language-agent environments where reward hypotheses include trace quality, tool correctness, and final answer quality.
Connection to the tracked themes: agentic training, reward design, verification, phase-aware optimization.
Reading Priority and Next Questions
If I had to prioritize follow-up reading, I would put D3-Gym and FineState-Bench first. They make the evaluation object concrete in a way that should affect how future agents are trained. TopBench is next because it catches a very common data-agent failure: answering the literal lookup instead of the intended prediction. RHyVE is narrower, but it gives a useful language for reward deployment.
Questions I would carry into the next round:
- Can executable scientific verifiers be audited for hidden brittleness, not just agreement with gold scripts?
- Can table agents learn to ask for missing historical data instead of hallucinating a prediction from whatever table is present?
- Can exact GUI-state labels be attached to multi-step interactive rollouts?
- Can reward-hypothesis verification be reused for language agents, not only embodied control tasks?
The theme I am taking away is simple: better agents need harder evidence. Not longer answers, not richer demos, but state, code, reward, and artifact checks that survive inspection.