让数据与界面智能体面对硬证据
Published:
TL;DR:这期我看的是“证据对象变硬”这件事。四篇论文都不满足于让智能体写一个像样的答案,而是继续追问:科学数据任务能不能被可执行 verifier 检查,表格问答能不能识别隐含预测意图,GUI 智能体能不能到达精确状态,LLM 生成的 reward 能不能在合适的训练阶段再部署。
本期我在看什么
前几期已经反复写过显式状态、可回放工作区和中间层。这期我想换一个角度:当数据智能体和工作流智能体越来越接近真实任务时,评测对象本身正在从“最后回答”变成“可执行环境、隐藏意图、精确界面状态、可验证 reward”。这不是更漂亮的 benchmark 包装,而是把失败暴露得更具体。
这也让结果没那么好看。很多模型仍然失败得很明显。但我觉得这正是好事:失败终于不只是“没完成任务”,而是能被拆成代码没跑通、预测意图没识别、点击命中了控件却没改到状态、reward 在低能力阶段没有意义。
论文细读笔记
D3-Gym: Constructing Real-World Verifiable Environments for Data-Driven Discovery
作者:Hanane Nour Moussa, Yifei Li, Zhuoyang Li, Yankai Yang, Cheng Tang, Tianshu Zhang, Nesreen K. Ahmed, Ali Payani, Ziru Chen, Huan Sun。
机构:The Ohio State University、Cisco Research。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | 项目与数据
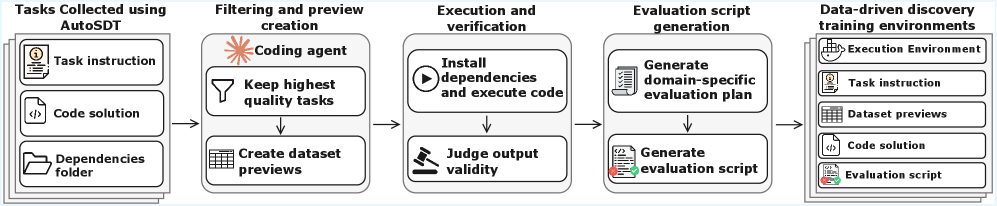
这张图讲清了 D3-Gym 的核心:一个科学仓库不只是给智能体阅读的文本,它可以被加工成带数据预览、参考输出和 evaluation script 的可执行任务。真正重要的是,data agent 的评测应该包含能检查工作的环境。需要谨慎的是,自动构建仍然依赖过滤和验证,benchmark 的可靠性取决于这条管线本身。

统计图说明 D3-Gym 不是一个玩具 notebook 集合。565 个任务来自 239 个真实科学仓库,覆盖四个学科,也覆盖不同任务类型、输入输出模态、软件包和难度。它不能代表所有科学实践里的混乱,但至少比单一模板的代码题更接近真实数据工作流。
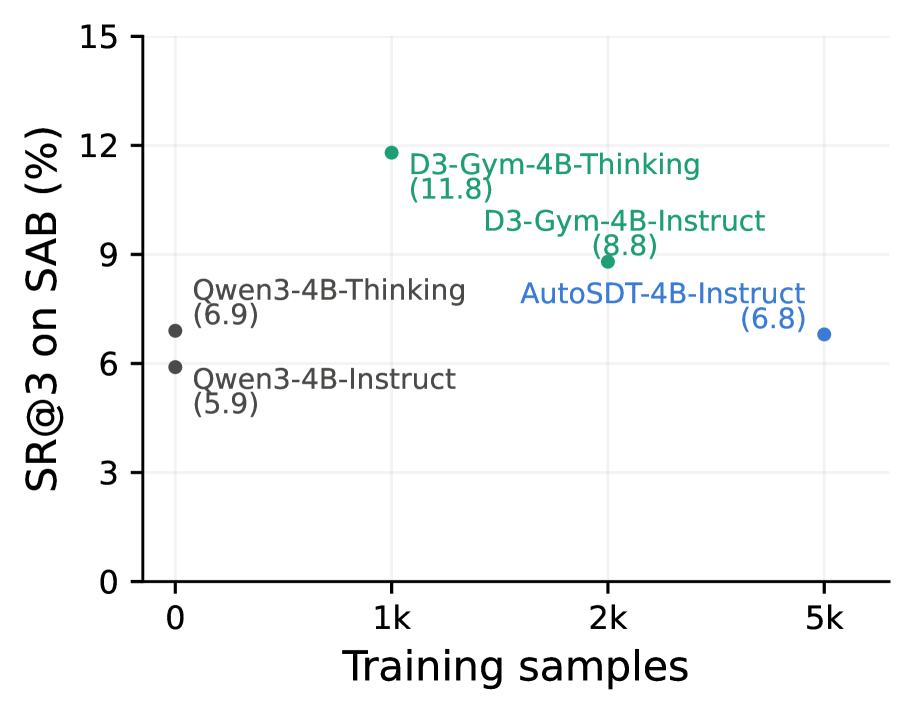
这组曲线说明训练信号确实在起作用。这里我不只看 success rate,也看 valid execution rate,因为一个不能运行的程序不算完成数据发现任务。图里的趋势支持论文的判断:轨迹训练同时改善了科学正确性和可执行性。
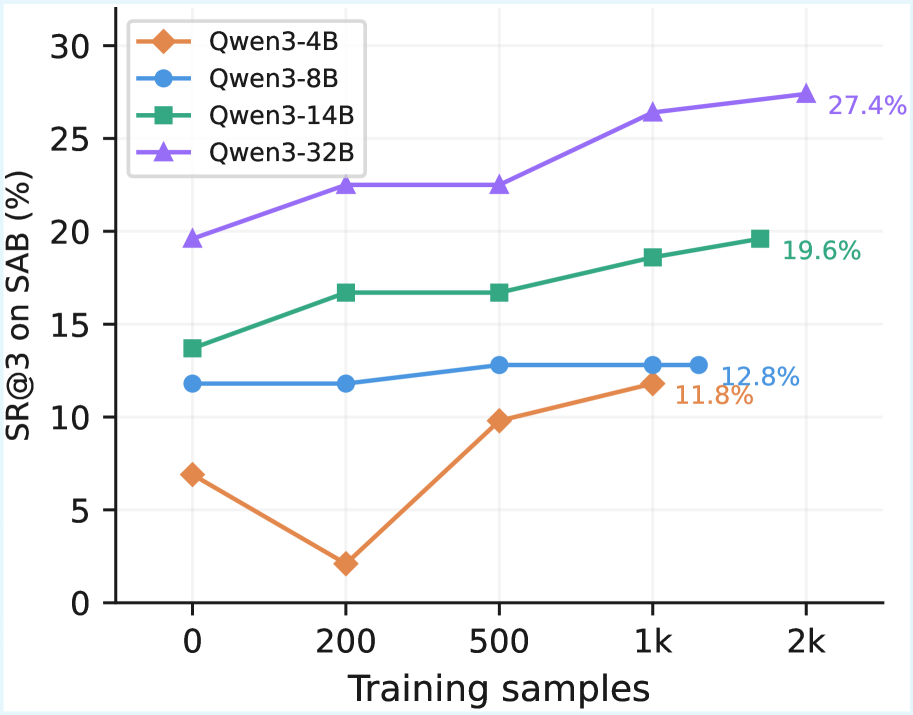
高难度图给了更强的压力测试。论文报告说,用 D3-Gym 轨迹训练后,Qwen3-32B 在 ScienceAgentBench 上的 best-of-three success 提升 7.8 个百分点,在 verified 版本上也有明显提升。我的解读会克制一些:这是一个有价值的训练底座,不等于开放模型已经追上强闭源科学智能体。
一句话核心:D3-Gym 把真实科学仓库转成可运行、可验证的数据发现环境,让 data agent 必须交出能被检查的产物。
为什么重要:数据智能体不该只靠解释分析过程来过关。它需要产出代码、图表或文件,并且这些产物要能被任务特定的科学标准检查。D3-Gym 把评测对象从“回答”推进到“可执行证据”。
方法拆解:
- 从真实科学仓库收集候选任务,筛掉不适合运行或验证的任务。
- 生成数据预览和参考输出,让智能体有上下文但拿不到答案。
- 通过 planning 先确定要检查的 artifact、指标、阈值和容差,再生成 silver evaluation script。
- 用人工 gold script 验证脚本质量,再把环境和轨迹用于模型训练。
关键证据:数据集包含 565 个任务、239 个仓库。50 个任务的验证集上,silver evaluation scripts 和人工 gold scripts 的 pass/fail agreement 达到 87.5%;去掉 planning 或数据预览后,评测质量明显下降。训练结果也显示 Qwen3 系列跨尺度受益,最大模型在原始和 verified 版本上都有 best-of-three success 提升。
我的判断:这篇很像我希望看到的 data-agent benchmark。它不允许模型躲在漂亮报告后面,输出要能跑,verifier 要能说清楚什么叫科学上可接受。
局限/问题:自动 evaluation script 本身可能变成新的隐藏偏差。下一步我更想看这些 verifier 在更脏、更少被筛选过的科研仓库里能不能站住。
和本期主题的关系:data agents、agentic training、可执行验证、科学工作流。
TopBench: A Benchmark for Implicit Prediction and Reasoning over Tabular Question Answering
作者:An-Yang Ji, Jun-Peng Jiang, De-Chuan Zhan, Han-Jia Ye。
机构:arXiv HTML 页面未注明。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | Benchmark
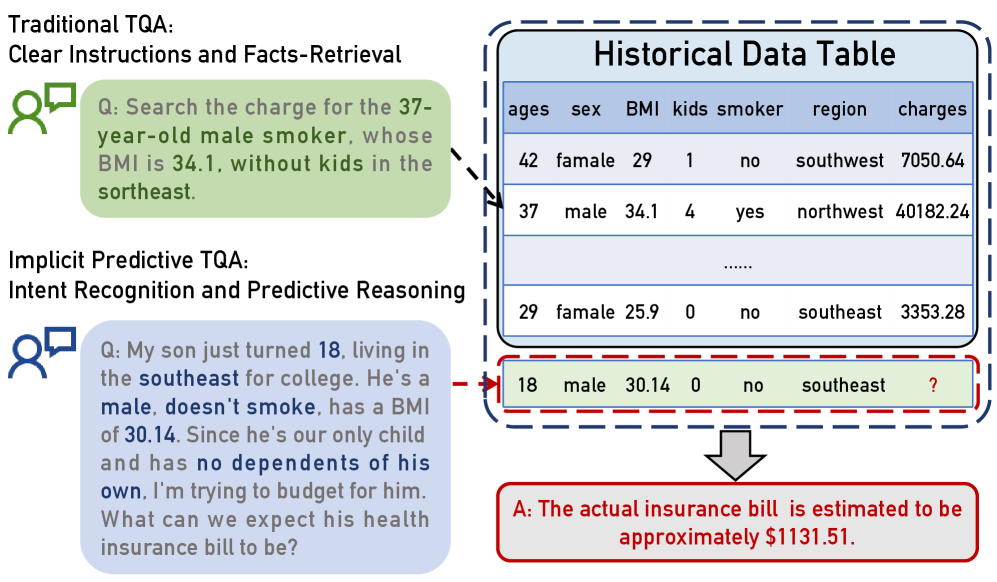
这张图是 TopBench 的入口。传统 table QA 多半是在查找、聚合或显式计算,TopBench 则要求模型意识到用户真正问的是一个未观测结果。这个变化很小,但任务性质完全变了:它不再只是读表,而是意图识别加预测建模。
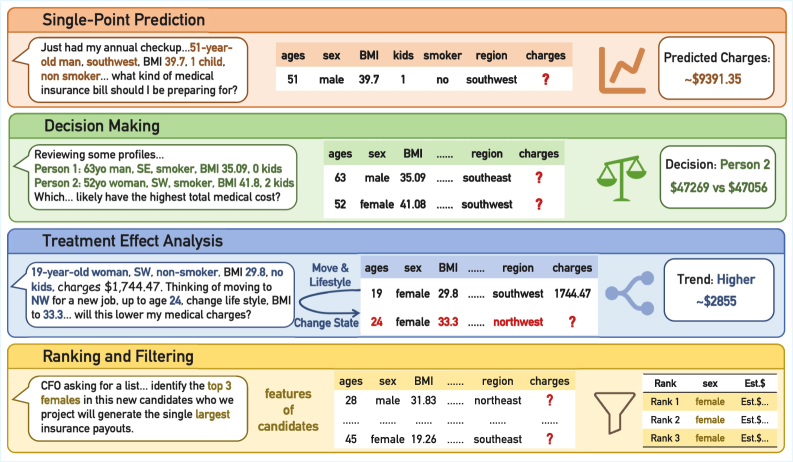
总览图把四类任务展开:单点预测、决策、处理效应分析、排序与过滤。这个设计要求模型同时生成推理文本和结构化输出,而不是只报一个数字。限制也很清楚:相关历史表已经给定,所以它还不是完整的开放式数据发现任务。
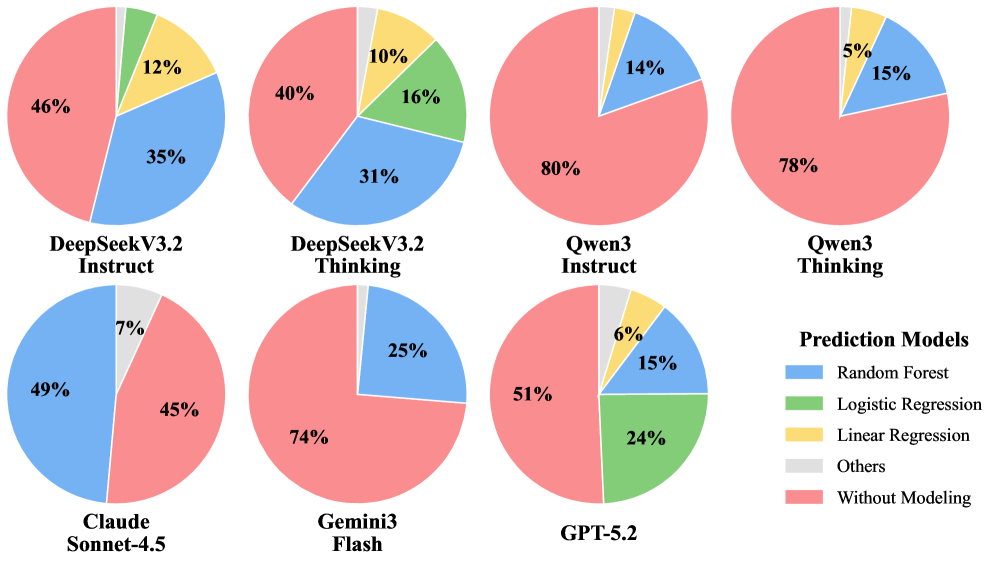
工具使用图解释了很多模型为什么失败。有些模型会调用机器学习库,有些仍然退回简单数据处理,即使问题本质上是预测。这里的瓶颈不是有没有代码执行环境,而是模型能不能先判断“这不是查表题”。
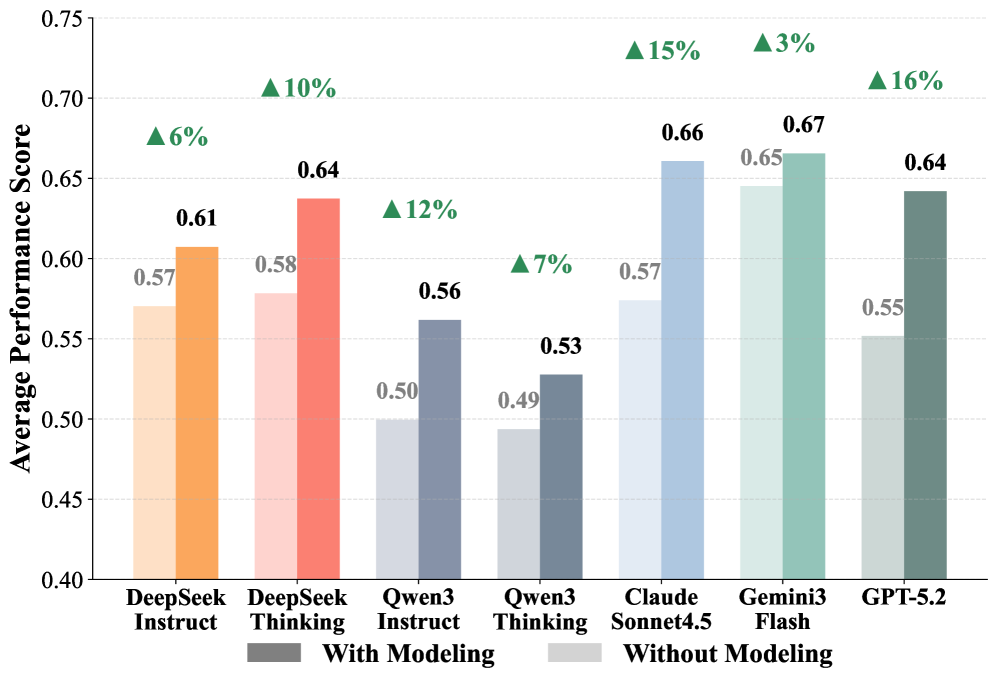
这张图隔离了预测建模本身的收益。论文还做了一个上界式实验:predict-only ensemble 在单点预测、决策和处理效应任务上超过 Gemini 3 Flash 的端到端 agentic 设置。这个结果提醒我,工具在手不代表模型会选择正确抽象。
一句话核心:TopBench 测的是模型能不能识别表格问题背后的隐含预测意图。
为什么重要:真实业务和科研数据问题经常被说成普通问句,但答案并不在表里。智能体需要识别潜在建模意图,选择历史信号,再给出结构正确的结果。很多 data-agent 产品正是在这里出错:它回答了字面上最容易的查找题,而不是用户真正想要的分析。
方法拆解:
- 从 35 张源表构造 779 个 query,覆盖金融、医疗和咨询式场景。
- 把任务分成单点预测、决策、处理效应分析、排序与过滤。
- 同时评测纯文本推理和 agentic code-execution workflow。
- 用准确率、logic score、recall、NDCG、NMAE、F1 等指标分析不同任务。
关键证据:主结果里没有一个模型全面领先。Gemini 3 Flash 在若干 agentic 场景很强,Claude Sonnet 4.5 在部分分类和排序输出上表现不错,通用 LLM 明显强于传统 tabular specialists。更有价值的是消融:增加语义信息不总是有效,而 predict-only ensemble 在三个核心预测任务上的 0.76、0.72、0.69,超过 Gemini 端到端 agentic 的 0.66、0.65、0.65。
我的判断:我喜欢 TopBench 的原因是,它不把“表格理解”偷换成检索。用户问的是自然语言问题,系统必须判断这是不是一个预测任务,这正是数据智能体最容易装懂的地方。
局限/问题:相关表已经被配好。更难的下一步是完整数据智能:自己找或构造历史表、识别预测意图、建模、说明不确定性。TopBench 只覆盖中段,但已经足够暴露短板。
和本期主题的关系:data agents、文档/表格智能、预测式表格推理、意图消歧。
FineState-Bench: Benchmarking State-Conditioned Grounding for Fine-grained GUI State Setting
作者:Fengxian Ji, Jingpu Yang, Zirui Song, Yuanxi Wang, Zhexuan Cui, Yuke Li, Qian Jiang, Xiuying Chen。
机构:MBZUAI, United Arab Emirates;Northeastern University, China。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML | Benchmark
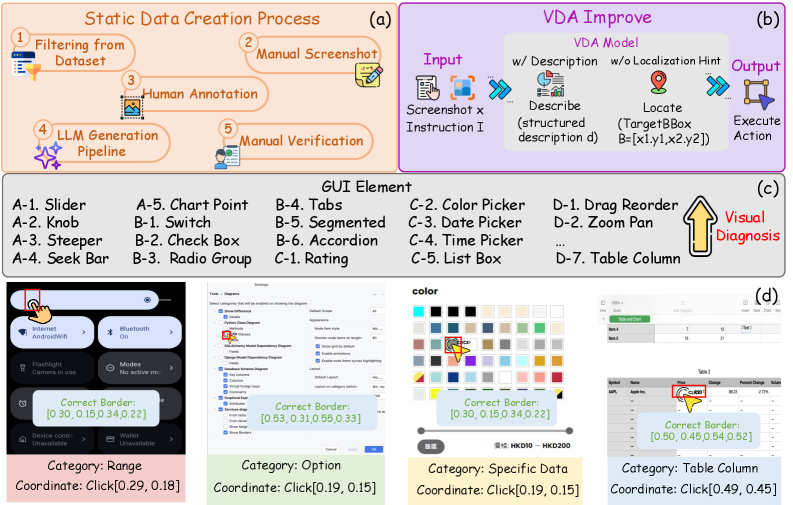
FineState-Bench 的想法很朴素也很狠:点到正确控件,不等于到达正确状态。所以它记录 target state、当前 locate box 和真正能改变状态的 interactable region。这样 GUI agent 的失败不再只是一个二元 task success,而可以拆成具体环节。
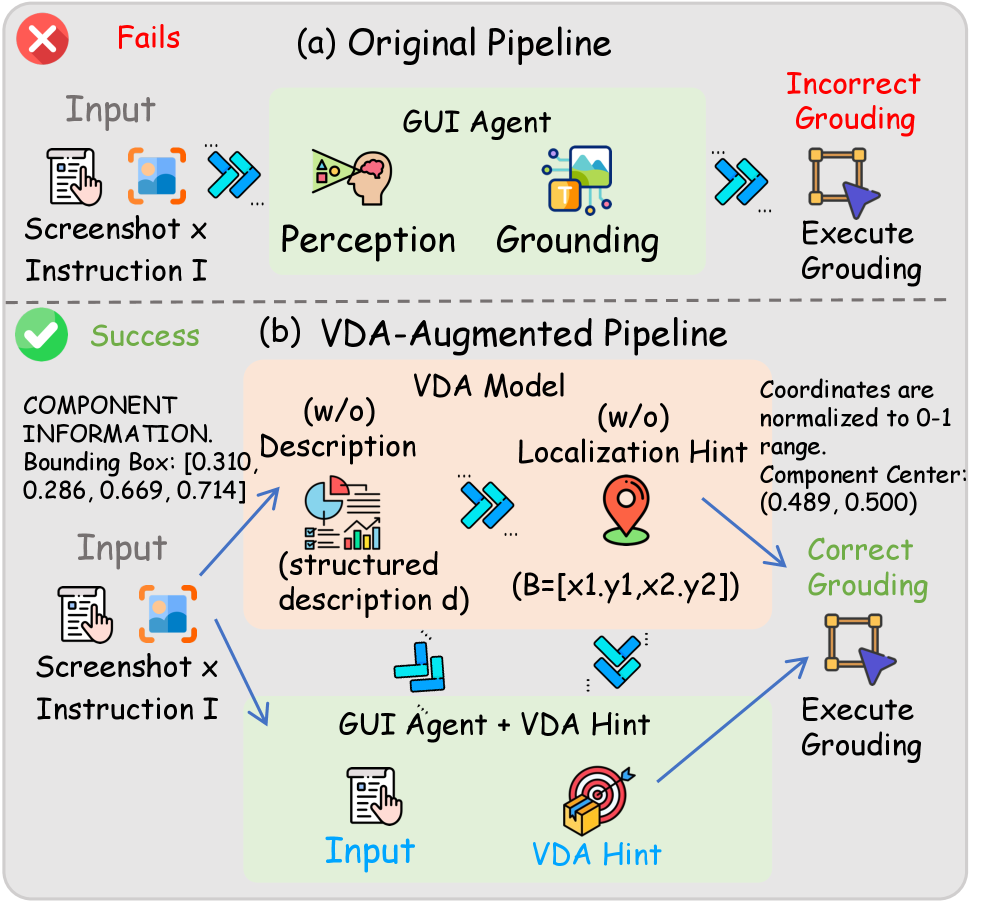
VDA 不是被当成部署组件,而是一个控制变量诊断工具。给模型加 description 或 localization hint,然后观察哪个瓶颈被移动。它把“视觉定位不准”这种模糊说法变成了可以测的干预。

这张样例图说明为什么它比普通 element grounding 难。slider、seek bar、color control、stepper、tree view,以及移动端、网页、桌面组件,都存在“可见控件范围”和“真正改状态的点”不一致的问题。模型可能找到控件,却打不中操作核心。
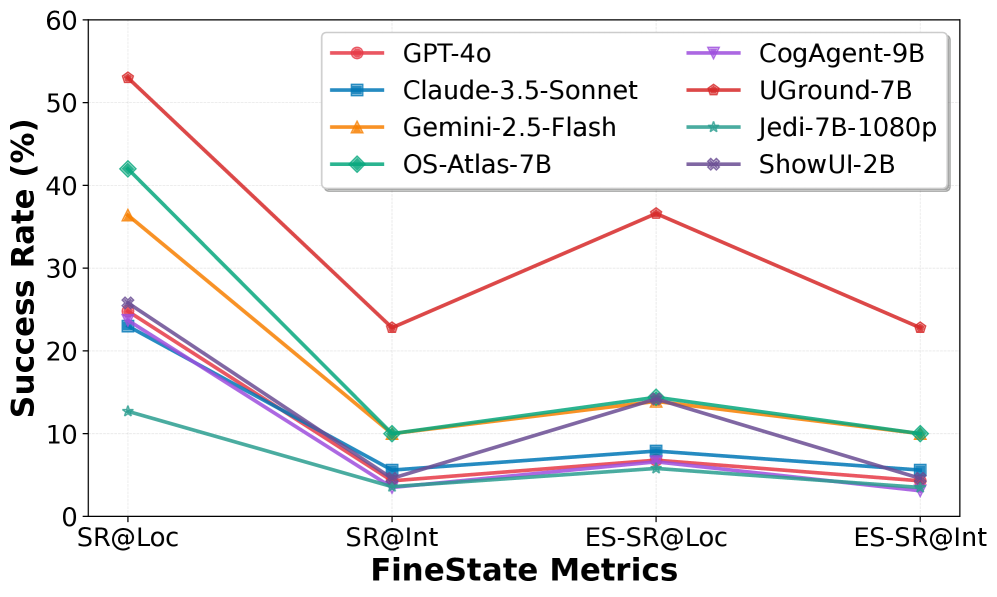
性能退化图是最不舒服的部分。即使模型能认出区域,很多组件上的 exact state setting 仍然断崖式下降。论文报告 ES-SR@Int 在 Web 上最高 32.8%,跨平台平均 22.8%,说明当前 GUI agent 离可靠精细控制还很远。
一句话核心:FineState-Bench 不只评估 GUI agent 能否点到控件,而是评估它能否达到精确目标状态。
为什么重要:生产里的 GUI agent 常常以小错失败:slider 差一点、树形菜单选错项、点到了控件但没点到能改变状态的位置。FineState-Bench 给这些失败提供了可度量的语言。
方法拆解:
- 构造 2,209 个静态 GUI 实例,覆盖 desktop、web、mobile。
- 覆盖四类交互和 23 种 UI 组件,每个实例都有 exact target-state label。
- 标注双区域几何信息:较宽的 locate box 和更窄的 interactable-core box。
- 用 SR@Loc、SR@Int、ES-SR@Loc、ES-SR@Int 做分阶段评测,再用 VDA hint 诊断视觉 grounding 瓶颈。
关键证据:基线结果很直接。最佳平均 ES-SR@Int 只有 22.8%,很多模型在“找到控件”和“打中可操作核心”之间有明显落差。加上 VDA localization hint 后,Gemini 2.5 Flash 的平均 ES-SR@Int 提升 14.9 个百分点;消融也显示 localization hint 比单纯文字 description 更关键。
我的判断:这篇是对 GUI agent demo 的一次降温。用户真正关心的不是“看起来点了”,而是状态有没有到位。它主动放弃长程交互,换来对一个失败模式的精确诊断,我觉得这个取舍是对的。
局限/问题:作者也说明这是静态、单点设置。它不覆盖滚动、多步纠错和实时界面变化。下一步需要把这种 exact-state label 接到交互式 rollout 上,同时保留失败归因能力。
和本期主题的关系:GUI agents、界面智能、state-conditioned grounding、智能体评测。
RHyVE: Competence-Aware Verification and Phase-Aware Deployment for LLM-Generated Reward Hypotheses
作者:Feiyu Wu, Xu Zheng, Zhuocheng Wang, Yi ming Dai, Hui Li。
机构:School of Cyber Engineering, Xidian University。
时间/来源:2026-04-30,arXiv 预印本。
链接:arXiv | HTML
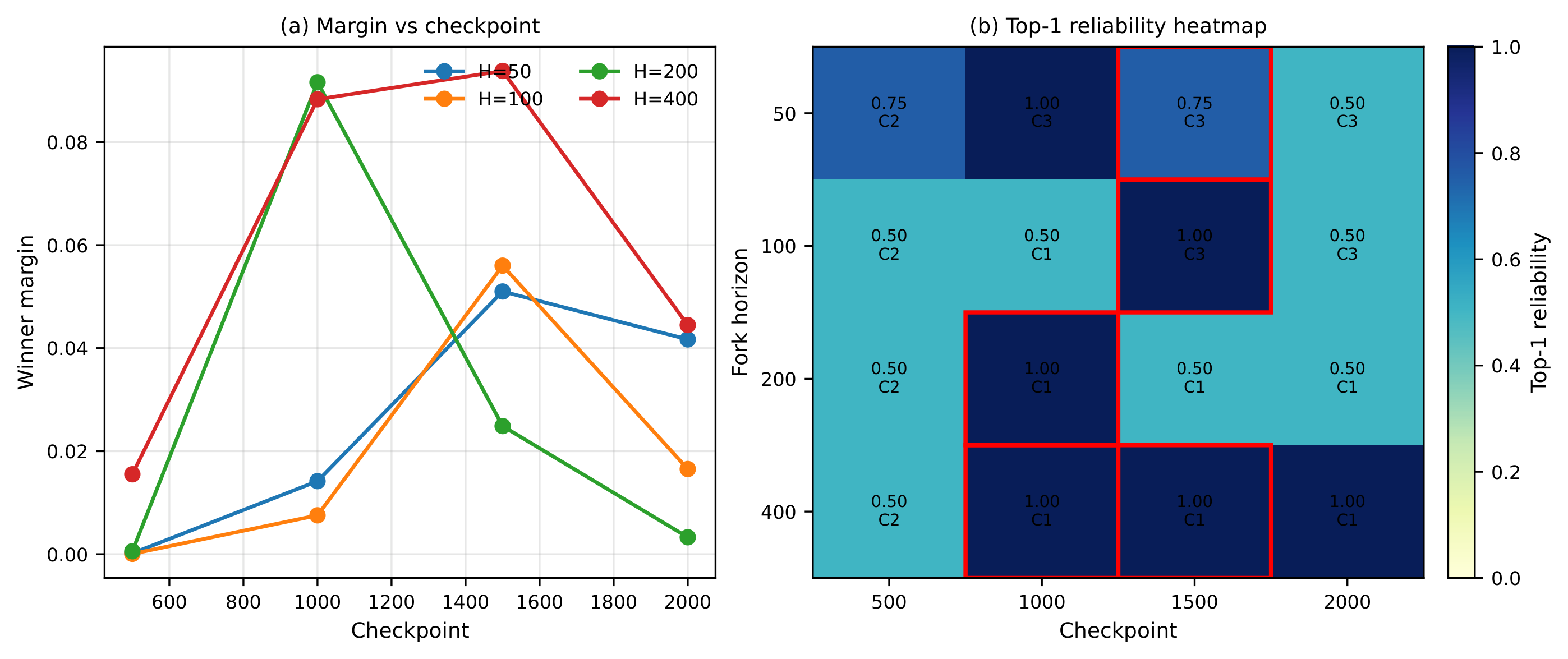
这张图说明为什么 RHyVE 放在本期里。一个 reward candidate 不被当成永远好或永远坏的静态函数,而是要从相同 policy checkpoint 分叉验证。低能力 policy 可能根本到不了 reward 有意义的状态,因此太早判断 reward 会误导训练。
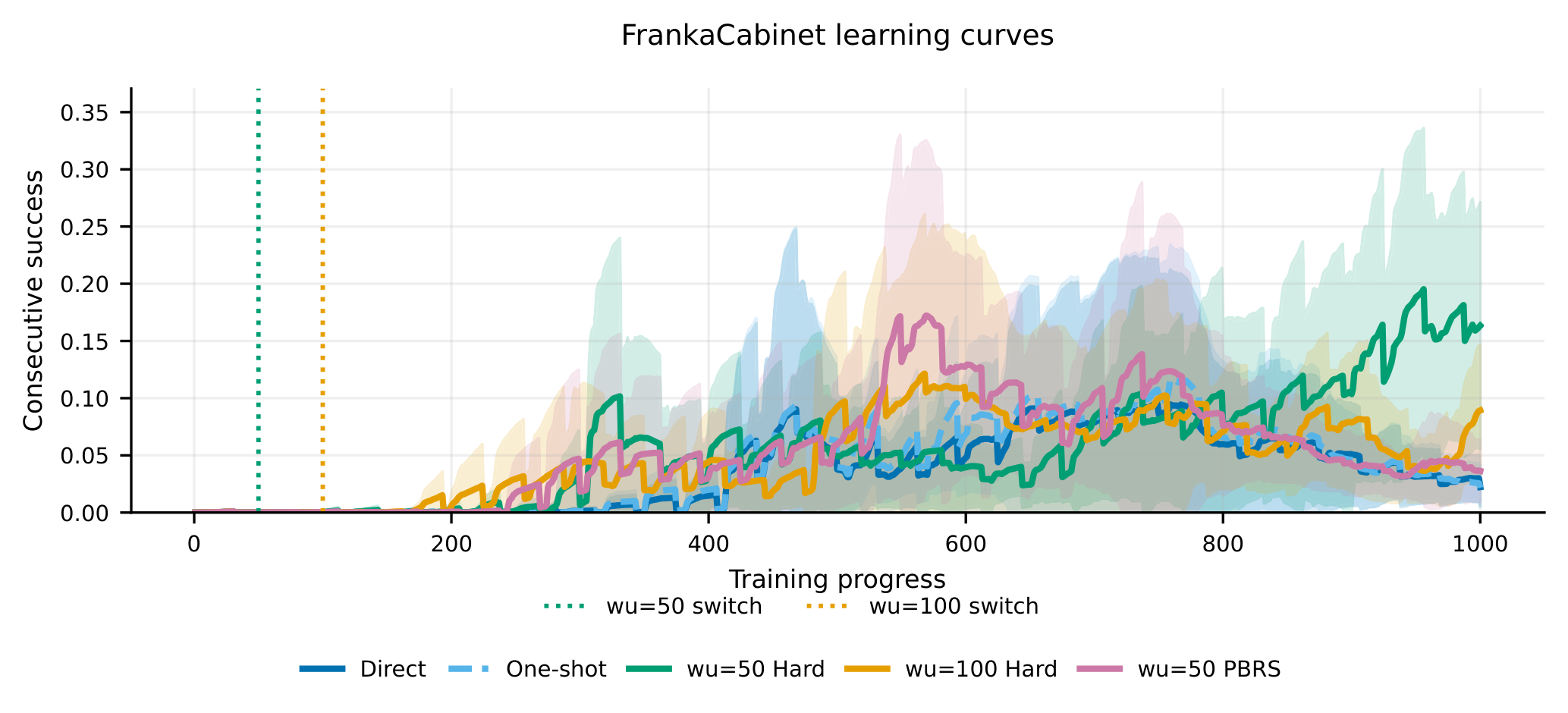
学习曲线显示 phase-aware deployment 为什么有必要。在锁定的 FrankaCabinet 设置里,先 warm-up 再 hard-switch 的规则比直接部署在 peak 和 retained behavior 上更好。作者也很克制:这不是通用 scheduler,高 seed variance 也限制了结论范围。
一句话核心:RHyVE 把 LLM 生成的 reward 当成 hypothesis,它是否有用取决于当前 policy 能力和训练阶段。
为什么重要:agentic training 越来越依赖自动生成 reward,但“生成 reward”和“部署 reward”不是同一个问题。一个 reward 可能在 policy 已经能接近柜门把手后才有信息量,早期直接用反而会误导。RHyVE 把这个时机问题显式化。
方法拆解:
- 把 reward candidate 定义成 hypothesis,而不是固定目标。
- 从共享 policy checkpoint 分叉短 rollout,在相同能力水平下比较 reward。
- 建立 phase profile,判断 reward ranking 什么时候开始有信息量。
- 用 direct、scheduled、held-out selected 或 conservative rule 部署 reward,并测试不该起作用的边界场景。
关键证据:结构化 FrankaCabinet 对比里,固定 warm-up 50 后 hard-switch 在锁定方法中拿到最强 mean peak performance 和 recomputed final performance。直接部署和一次性部署在 final 与 tail metrics 上都较低,而 phase-aware deployment 保留了更多行为。LLM 生成 reward candidate 的结果更乱,但这正好支持论文主张:最佳部署规则随 candidate family 变化,没有一个固定 warm-up 策略能通吃。
我的判断:这是一篇带评测意识的 reward-design 论文。它不只问“LLM 能不能写 reward”,还问“这个 reward 在当前 learner 身上什么时候才可靠”。这个问题比生成一个看起来合理的 reward 更接近真实训练。
局限/问题:RHyVE 不解决 reward switching 的安全性,也不能在任务本身不可学习时产生有意义排序。我更想看它被搬到语言智能体环境里,reward hypothesis 同时覆盖 trace quality、tool correctness 和 final answer quality。
和本期主题的关系:agentic training、reward design、verification、phase-aware optimization。
阅读优先级和下期问题
如果按后续价值排序,我会先追 D3-Gym 和 FineState-Bench。它们把评测对象变得足够具体,应该会影响后续智能体训练。TopBench 紧随其后,因为它抓住了 data agent 的常见错法:把隐含预测问题当作普通查表题。RHyVE 范围更窄,但给 reward 部署提供了一个有用语言。
我会带到下一期的问题:
- 自动生成的科学 verifier 能不能被审计出隐藏脆弱性,而不只是和 gold script 对齐?
- 表格智能体能不能学会请求缺失历史数据,而不是用眼前表格硬预测?
- exact GUI-state label 能不能接到多步交互 rollout 上?
- reward hypothesis verification 能不能用于语言智能体,而不只用于具身控制任务?
这一期的结论很简单:更好的智能体需要更硬的证据。不是更长的回答,也不是更热闹的 demo,而是经得起检查的状态、代码、reward 和 artifact。