先看清证据,再让模型回答
Published:
TL;DR:本期没有退回 4 月 30 日,而是保留 5 月 3-4 日的新论文,主题是“模型在回答或生成之前应该先看什么”。FlexSQL 让 data agent 在推理过程中反复检查 schema、取值、执行结果和计划,而不是一次性把 schema retrieval 固定下来。Chart-FR1 把密集图表推理训练成显式视觉聚焦过程,让 reasoning step 绑定 OCR 文本和局部区域。PV-VAE 则把 video VAE 从纯重建改成预测式重建,迫使 latent 携带运动和未来变化信息。
本期我在看什么
最近几期 Paper Radar 讲了很多外部证据表面:workflow trace、文档图结构、reward-model activation、可回放工作区。这条线仍然重要,但本期我想往前挪一步:模型留下证据之前,必须先知道自己该检查什么。
对 data agent 来说,这意味着推理时能继续看数据库,而不是把一次 schema linking 当成最终上下文。对 chart model 来说,这意味着 reasoning chain 要指向局部图形、OCR 文本和 box,而不是把密集图表当成一张普通图片。对视频 world model 来说,这意味着 latent state 要被要求预测未来,而不只是重建已经看到的像素。
我初筛了 24 小时内的新 arXiv 线索,包括 MolmoAct2、multi-agent orchestration trace RL、FlexSQL、MLLM latent reasoning、AcademiClaw、ARA、AutoFocus、long-horizon training、DataClaw 和 PhysicianBench。最后保留三篇,是因为它们都有开放 HTML、方法细节、公式、图表和可定位数字,可以写成真正的 mini explainer。本期也继续落实最近的写作反馈:每篇先讲领域入口,密集表格用 Markdown 重写,关键机制用公式说清楚。
论文细读笔记
FlexSQL: Flexible Exploration and Execution Make Better Text-to-SQL Agents
作者:Quang Hieu Pham, Yang He, Ping Nie, Canwen Xu, Davood Rafiei, Yuepeng Wang, Xi Ye, Jocelyn Qiaochu Chen。
机构:University of Alberta;Simon Fraser University;University of Waterloo;Snowflake;Princeton University;New York University。
日期/来源:2026 年 5 月 4 日,arXiv 预印本。
链接:arXiv | HTML | 代码
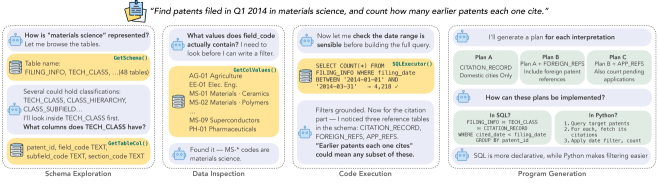
这条 condensed trace 展示了我希望 data agent 具备的行为:不要把数据库当成静态 prompt 附件。它会发现 schema、检查取值、运行局部验证,并保留多个 query interpretation 直到可以测试它们。需要谨慎的是,这只是一个压缩示例,说明机制,但不单独证明系统鲁棒性。
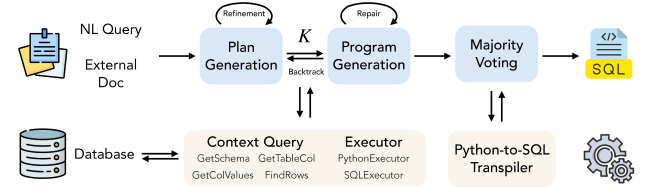
框架图是最有用的系统视角。FlexSQL 包括 plan generation、program generation、repair、plan backtracking,以及跨 SQL/Python 输出的 majority voting。关键点是 backtracking 可以从代码错误回到计划错误:选错表或误解查询意图时,不会被迫只在 SQL 局部修补。
一句话核心 idea:FlexSQL 把 text-to-SQL 变成一个交互式 data-agent 问题,让 schema exploration、value inspection、execution、repair 和 plan revision 贯穿推理全过程。
为什么重要:企业数据库不是早期语义解析 benchmark 里的干净单 schema 世界。论文提到 Spider2.0 的 Snowflake 数据库中,152 个数据库里接近 10% 超过 100 张表,最大的数据库有 60,000 到 72,000 个列。固定 pipeline 如果一开始 schema retrieval 错了,后续执行反馈来得太晚,只能修补表面 SQL,很难修复上游计划假设。
方法拆解:
- FlexSQL 先做轻量预处理:删除全空列,把 schema 相同但只有时间后缀不同的表分组;随后通过
GetSchema、GetTableCol、GetColValues、FindRows等工具按 database -> schema -> table 的层次路由。 - 系统生成 (K) 个多样化自然语言执行计划,并提示每一批计划与前面计划保持差异。计划阶段可以继续看 schema、检查取值、运行测试 query。
- 每个计划可以被实现成 SQL 或 Python。SQL 适合声明式关系查询;Python 适合多步转换、正则、分析库或很难写进单条 SQL 的流程。
- repair 区分 code-level error 和 plan-level error。代码错误触发局部重写;计划错误触发回到 plan generation 并重新探索数据库。
- majority voting 按执行结果聚类,不区分 SQL 或 Python。如果获胜结果来自 Python,系统再把它转译回 SQL,并验证输出一致。
论文中的 Spider2.0 主结果摘要。
| 模型 | 指标 | Spider2-Snow DSR-SQL | Spider2-Snow ReFoRCE | Spider2-Snow FlexSQL | Spider2-SQLite DSR-SQL | Spider2-SQLite ReFoRCE | Spider2-SQLite FlexSQL |
|---|---|---|---|---|---|---|---|
| gpt-oss-120b | Pass@1 | 33.27 | 44.12 | 55.15 | 48.15 | 45.19 | 57.78 |
| gpt-oss-120b | Majority@8 | 50.37 | 48.90 | 59.74 | 51.85 | 54.07 | 64.44 |
| gpt-oss-120b | Pass@8 | 63.24 | 62.32 | 78.68 | 57.78 | 71.11 | 78.52 |
| gpt-oss-20b | Pass@1 | 32.54 | 36.76 | 43.20 | 34.81 | 42.96 | 50.37 |
| gpt-oss-20b | Majority@8 | 42.65 | 43.01 | 50.92 | 37.04 | 46.67 | 54.07 |
最值得看的不是单个最高分。较小的 gpt-oss-20b + FlexSQL 在 Spider2-SQLite 上 Pass@1 达到 50.37,超过表中两个 120B baseline。论文还报告 Spider2-Snow table-level schema linking best-of-8 的 F1 为 95.26,而 DSR-SQL + DeepSeek-V3 为 82.65,ReFoRCE 混合专有模型设置为 80.03。这说明 flexible exploration 改善的是 grounding,不只是多采样。
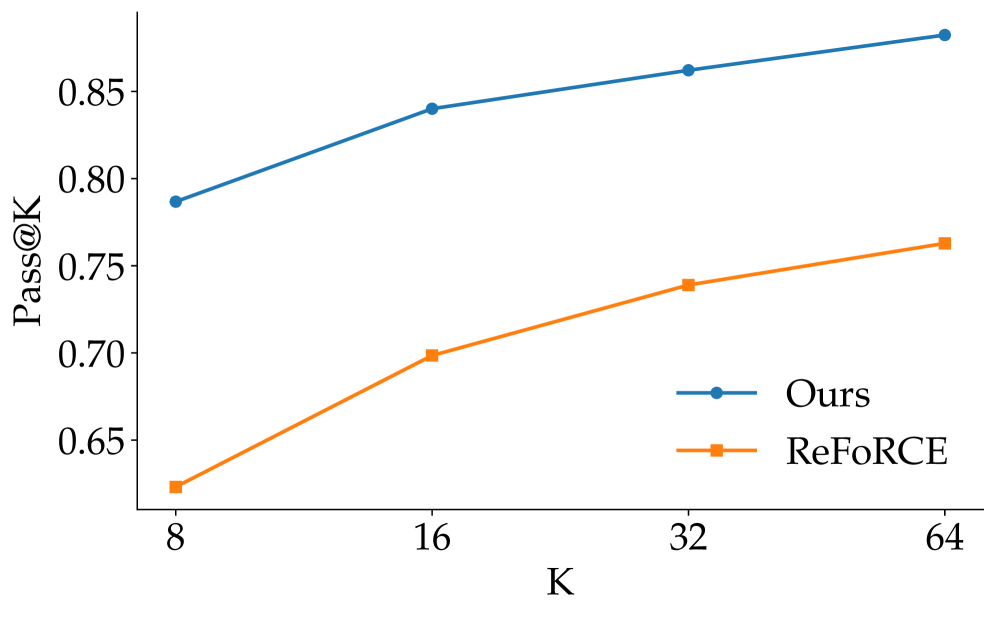
这张图回答了一个实际问题:多给 test-time attempt 是否真的有用。随着 (K) 增大,FlexSQL 相对 ReFoRCE 保持领先;如果 plan diversity 和 execution feedback 真有作用,这正是我会期待的形态。需要注意的是成本问题:扩大 (K) 会买来准确率,但部署系统仍然需要延迟和预算策略。
论文中的消融摘要。
| Spider2-SQLite 设置 | Majority@8 | Pass@8 | Micro Acc. |
|---|---|---|---|
| gpt-oss-120b FlexSQL | 64.44 | 78.52 | 49.69 |
| 去掉 Python | 52.59 | 68.89 | 41.10 |
| 去掉多样化 planning | 55.56 | 83.70 | 50.23 |
| 去掉 plan backtracking | 61.48 | 80.00 | 48.64 |
| 去掉全部 repair | 57.04 | 79.26 | 46.79 |
这组消融把常被混在一起的三个因素拆开了:工具访问、多样化计划、双语言执行。去掉 Python 后 majority accuracy 明显下降,说明 Python 不是装饰性的中间表示,而是在某些分析问题上先解出正确结果,再转译成 SQL。去掉多样化 planning 会降低 majority accuracy 但提升 Pass@8,也提醒我们:更多样的样本可能包含更多单次正确答案,但共识投票会变难。
我的判断:FlexSQL 更像是“数据库调查员”,而不是 SQL 字符串生成器。最强的部分是从 plan error 恢复,因为很多 data-agent 失败不是代码写错,而是代码之前的假设错了。弱点仍然是操作策略:agent 什么时候停止探索,多少 test-time sampling 值得付费,当多个执行结果都看起来合理时,系统如何向用户暴露不确定性?
关联主题:data agents、text-to-SQL、工具 grounded reasoning、基于执行的可审计性。
Chart-FR1: Visual Focus-Driven Fine-Grained Reasoning on Dense Charts
作者:Hongkun Pan, Yuwei Wu, Wanyi Hong, Shenghui Hu, Qitong Yan, Yi Yang, Rufei Han, Changju Zhou, Minfeng Zhu, Dongming Han, Wei Chen。
机构:浙江大学;浙江大学 CAD&CG 国家重点实验室;HiThink Research。
日期/来源:2026 年 5 月 3 日,arXiv 预印本。
链接:arXiv | HTML | 代码

这个例子说明密集图表推理不是普通 VQA。信息密度升高以后,模型必须先决定哪个 legend、subplot、label、局部区域或 OCR 文本与问题相关,然后才谈得上数值推理。需要谨慎的是,图中仍是选择性示例和趋势线,必须和后面的 benchmark 结果一起读。
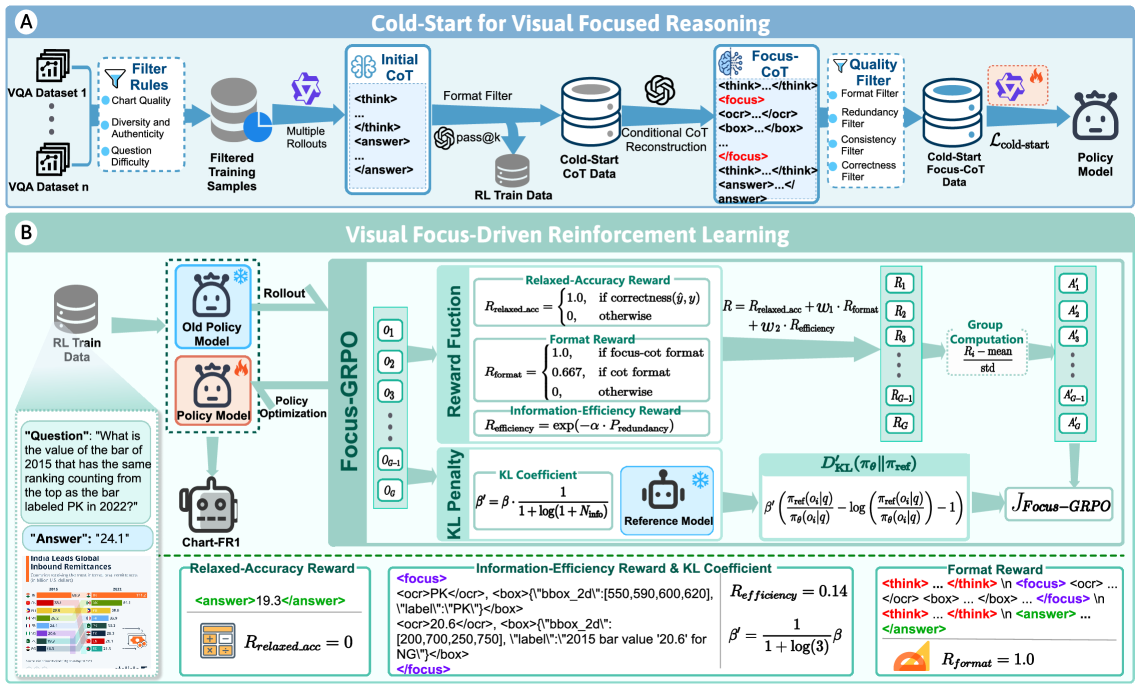
这张总览图基本就是论文方法。第一阶段构造 Focus-CoT cold-start 数据,把 reasoning step 显式连接到 OCR 文本和局部区域。第二阶段用 Focus-GRPO,让 reward 同时关注答案正确、格式为 focus-aware reasoning、以及视觉证据使用是否经济。
一句话核心 idea:Chart-FR1 训练多模态图表模型先聚焦再推理:模型学会把推理步骤绑定到局部视觉证据,再用 RL 奖励准确且高效的 focus。
为什么重要:chart QA 在图简单时看起来不难,但科学图、商业 dashboard、财务报告里的答案常常藏在 legend、副轴、小字号 OCR 文本或多个 subplot 的比较里。通用 MLLM 可能“看到了整张图”,但没看对位置。这个问题在文档智能里很常见:正确答案需要 evidence path,而不只是最终一句话。
方法拆解:
- Focus-CoT 在 reasoning 中加入
<focus>动作。一次 focus 可以抽取 OCR 文本或定位局部图像区域,后续 reasoning 以这些视觉线索为条件。 - 作者先生成 cold-start 数据:抽取图表问题,生成候选 reasoning path,按格式和正确性过滤,再用 teacher model 插入 focus tag 或修正错误链条,最后过滤掉错误或冗余 focus trace。
- Focus-GRPO 从 old policy 采样多个输出,用 relaxed accuracy、format reward 和 information-efficiency reward 评分。
- information-efficiency reward 惩罚冗余 OCR 文本、重叠 box 和 OCR-box 重复:
- KL penalty 是自适应的。当模型聚焦到更多视觉线索时,KL 约束会放松:
这个设计不大,但很关键。标准 GRPO 对密集图表可能太僵硬,因为难题确实需要更长的视觉搜索。自适应 KL 让证据更多的样本有更大探索空间,同时让简单样本更靠近 reference policy。
Benchmark 本身也是贡献之一。论文用 information richness、efficiency、clarity、interactivity 定义 Chart-ID:
\[\text{Chart-ID}=\frac{S_{\text{rich}}}{2}+\frac{S_{\text{eff}}}{5}+\frac{S_{\text{clar}}}{5}+\frac{S_{\text{inter}}}{10}.\]HID-Chart 包含 734 张图和 1,561 个 QA pair,平均信息密度 3.94,覆盖 10 类图表和 8 个领域。构造流程从约 2,500 张图开始,筛选高信息密度图表,用 GPT-5 生成候选问题,再由五名研究生删除歧义问题、升级过简单问题并标注答案。
论文中的 HID-Chart 数据集摘要。
| 统计项 | 数值 |
|---|---|
| 图表总数 | 734 |
| 平均信息密度 | 3.94 |
| 领域 / 图表类型 | 8 / 10 |
| 平均图像尺寸 | 1090 x 796 px |
| 唯一问题数 | 1,561 |
| 平均问题长度 | 20.9 tokens |
| 唯一答案 token 数 | 1,795 |
训练与视觉线索消融摘要。
| 模型 | ChartQA | CharXiv | EvoChart | ChartBench | PlotQA | 平均 |
|---|---|---|---|---|---|---|
| Qwen2.5-VL-7B | 87.3 | 42.5 | 53.5 | 66.4 | 55.5 | 61.0 |
| Chart-FR1-7B | 91.0 | 46.6 | 59.2 | 75.6 | 62.9 | 67.1 |
| 去掉 Focus-GRPO | 87.6 | 40.8 | 54.8 | 71.6 | 58.5 | 62.7 |
| 去掉 Cold-Start | 90.0 | 42.0 | 57.7 | 72.3 | 61.5 | 64.7 |
| 去掉 OCR | 89.6 | 42.5 | 59.0 | 71.5 | 60.1 | 64.5 |
| 去掉 box | 89.9 | 43.2 | 59.7 | 72.4 | 60.6 | 65.2 |
提升不是只发生在作者新 benchmark 上。Chart-FR1-7B 相对 Qwen2.5-VL-7B,把五个 benchmark 的平均分从 61.0 提到 67.1。视觉线索消融也很有价值:去掉 OCR 后平均分比完整模型低 2.6 分,去掉 box 低 1.9 分。这支持论文的核心判断:文字线索和局部区域线索都在实际工作。
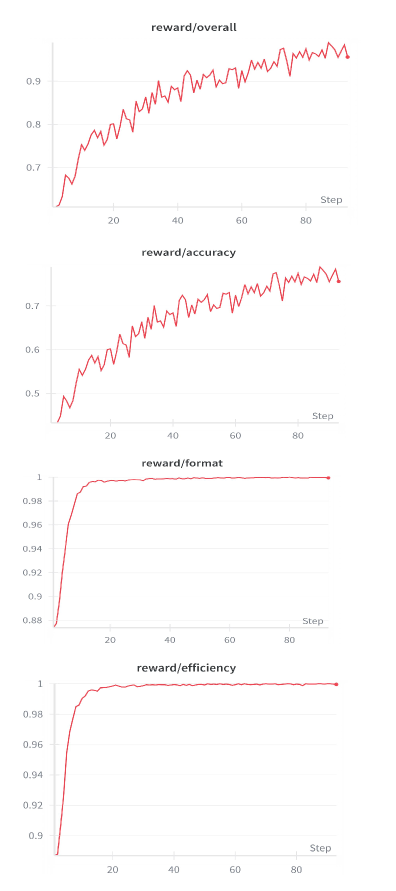
reward curves 让这篇不只是“换了个 prompt 格式”。它展示 Focus-GRPO 训练时 reward component 的变化,说明方法不只依赖 cold-start format。谨慎点在于,reward 曲线本身不能保证证据使用真实可靠;还要结合消融和 dense-chart evaluation 看。
我的判断:我喜欢这篇,是因为它把 chart reasoning 说得不玄。先找相关标记,控制 focus 的冗余,再推理。需要谨慎的是 teacher 和 judge 依赖:GPT-5 出现在数据生成、Chart-ID 打分和部分评估 prompt 中。但方向是对的:视觉文档上的回答应该带显式证据获取步骤,而不是只有最后的自然语言答案。
关联主题:document intelligence、图表推理、多模态 RL、视觉证据 grounding。
Video Generation with Predictive Latents
作者:Yian Zhao, Feng Wang, Qiushan Guo, Chang Liu, Xiangyang Ji, Jian Zhang, Jie Chen。
机构:开放 arXiv HTML 未注明。
日期/来源:2026 年 5 月 4 日,arXiv 预印本。
链接:arXiv | HTML
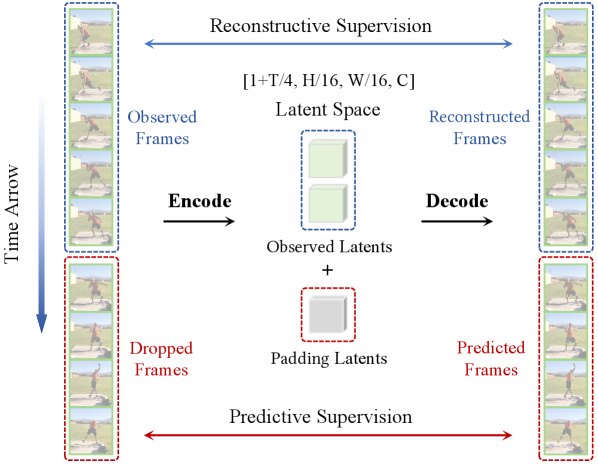
框架图把训练变化讲得很清楚。PV-VAE 随机丢弃未来 frame group,只编码已经观察到的前缀,把缺失 latent slot pad 上,然后要求 decoder 重建完整视频。需要说明的是,这仍是 VAE 训练目标,不是完整 planning agent;它和 world model 的关系在于 latent state 被迫保留什么。
一句话核心 idea:PV-VAE 用预测式重建训练视频 latent,让 latent space 必须编码时间上有用的结构,而不只是重建可见像素。
为什么重要:Video VAE 常被 reconstruction 指标评价,但视频生成器会把 latent 当作 diffusion 的底座。一个能重建清晰 frame 的 latent,不一定适合生成,因为它可能没有组织好运动、时间连贯性和未来动态。这是 world model 的一个小型版本:state 是否有用,取决于它保留了下游过程真正需要的信息。
方法拆解:
- 视频片段被分成 observed frames 和 dropped future frames,(\mathbf{x}=\langle\mathbf{x}{obs},\mathbf{x}{drop}\rangle)。encoder 只看到 (\mathbf{x}_{obs})。
- 丢弃的 temporal group 数量按 maximum dropping ratio 控制的均匀范围采样。observed latent sequence 被 uninformative 或 learnable vector pad 成完整长度。
- decoder 重建完整 clip,包括 encoder 从未看到的未来帧。这迫使 latent space 携带关于视频演化的预测信息。
- 架构使用 3D causal convolution,时间下采样 4 倍,空间下采样 16 倍,latent channel 为 64。
- 训练包括 image pretraining、带 predictive reconstruction 的 video training,以及冻结 encoder、关闭随机丢帧的 decoder fine-tuning,用来减小 train-inference gap。
总 loss 包含重建、时间差分重建、感知损失、GAN loss 和 KL 正则:
\[\mathcal{L}_{total}=\lambda_{rec}(\mathcal{L}_{\text{MSE}}+\mathcal{L}_{\text{Diff}})+\lambda_{lpips}\mathcal{L}_{\text{LPIPS}}+\lambda_{gan}\mathcal{L}_{\text{GAN}}+\lambda_{kl}\mathcal{L}_{\text{KL}}.\](\mathcal{L}_{\text{Diff}}) 值得特别看。静态背景在普通重建里占据大量像素,容易主导优化;重建相邻帧差分则迫使 VAE 把容量更多放到运动和时间变化上。
论文中的生成结果摘要。
| 方法 | Latent config | UCF101 FVD | UCF101 KVD | UCF101 IS | RealEstate10K FVD | RealEstate10K KVD | 训练速度 | 训练显存 |
|---|---|---|---|---|---|---|---|---|
| Hunyuan-VAE | t4s8c16 | 210.30 | 52.81 | 66.40 | 83.45 | 13.23 | 1.64 it/s | 87.36 GiB |
| Wan2.1 VAE | t4s8c16 | 167.10 | 11.54 | 66.04 | 83.84 | 10.64 | 1.88 it/s | 86.44 GiB |
| Wan2.2 VAE | t4s16c48 | 180.79 | 17.80 | 67.32 | 87.15 | 10.11 | 4.96 it/s | 30.90 GiB |
| SSVAE | t4s16c48 | 168.68 | 19.71 | 66.39 | 79.08 | 8.79 | 3.92 it/s | 34.00 GiB |
| PV-VAE | t4s16c64 | 146.37 | 14.52 | 69.72 | 72.50 | 4.06 | 4.40 it/s | 33.34 GiB |
PV-VAE 相对 Wan2.2 VAE 在 UCF101 FVD 上改善 34.42,相对 SSVAE 改善 22.31,同时训练显存接近同类高压缩 VAE。作者还报告相对 Wan2.2 VAE 在 UCF101 上收敛快 52%。它不是无代价胜利:在 Kinetics-400 reconstruction 上,PV-VAE 与高压缩 baseline 可比,但不总是优于 Wan2.2 的重建指标。
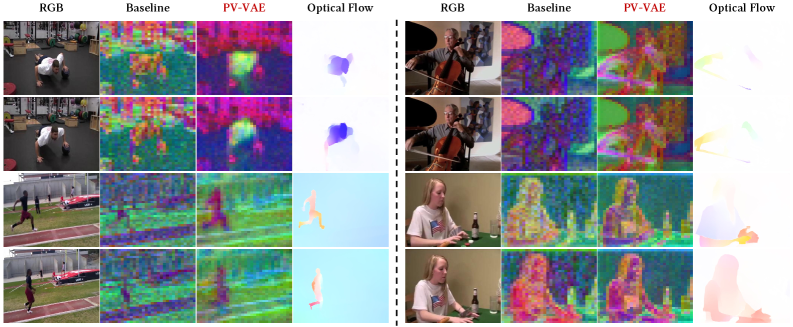
这张 PCA 图把论文从指标故事推进到表征故事。PV-VAE 的 latent activation 更明显对齐运动区域和 optical flow,而静态背景噪声更低。这支持“预测式重建改变 latent 关注对象”的主张,但 PCA 仍是诊断图,不是因果证明。
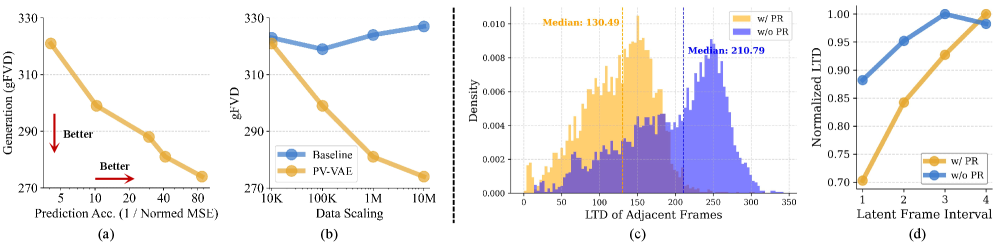
分析图把 prediction accuracy、scaling 和 temporal coherence 连起来。论文报告预测准确性与生成质量相关,PV-VAE 比纯重建更能从数据扩展中获益,latent temporal distance 随 frame interval 更平滑地变化。需要谨慎的是,这些分析都在同一训练设置内完成;我会继续看这种 latent 优势换到不同 diffusion backbone 后是否仍成立。
论文中的消融与 probing 证据。
| 配置 | UCF101 gFVD | Kinetics rFVD | PSNR | SSIM | LPIPS |
|---|---|---|---|---|---|
| Baseline | 174.81 | 3.03 | 33.44 | 0.96 | 0.017 |
| + Predictive Reconstruction | 156.33 | 5.66 | 31.47 | 0.94 | 0.026 |
| + Motion-aware Objective | 150.10 | 5.79 | 31.38 | 0.94 | 0.026 |
| + Decoder Fine-tuning | 146.37 | 3.45 | 32.26 | 0.95 | 0.020 |
| Latent probing 任务 | 无预测式重建 | 有预测式重建 |
|---|---|---|
| Optical flow EPE,越低越好 | 5.9223 | 5.1805 |
| Next-frame MSE,越低越好 | 0.0314 | 0.0289 |
| Point tracking AUC,越高越好 | 70.95 | 76.99 |
消融讲出了一个清楚的过程:predictive reconstruction 先提升生成但伤害重建;motion-aware objective 继续改善生成;decoder fine-tuning 再把重建质量拉回来。probing 任务也有价值,因为它不是只看最终视频分数,而是问 latent feature 是否真的更懂运动。
我的判断:PV-VAE 提醒我们,world-model 式训练可以藏在一个 representation component 里,而不一定是显式 planner。它最强的主张不是“这是完整 world model”,而是“如果要求 latent 预测被遮住的未来帧,latent 会更适合视频生成”。下一步我会看它能否扩展到更长视频、文本条件生成,以及未来依赖动作的机器人交互视频。
关联主题:world models、predictive latents、视频生成、表征设计。
阅读优先级和下期问题
如果目标是 data-agent 产品设计,我会先读 FlexSQL,因为它给了具体工具、循环和失败模式。如果目标是文档智能和 chart QA,我会先读 Chart-FR1,因为它给了“推理绑定视觉证据”的清晰 recipe。PV-VAE 则应该放在 world-model 线继续追:它不是 agent 论文,但让“有用 latent state 应该保留什么”这个问题更锋利。
下期我想继续追三个问题:data agent 能不能学会何时停止探索,而不只是扩大 test-time samples;chart/document model 能否暴露可审计的 focus trace,而不只是训练时有 tag;predictive latent objective 能否加入 action,让它从生成底座走向 planning 底座。