Training Signals, Memory Circuits, and Theories of the World
Published:
TL;DR: this round is about structure that is learned before an agent produces the final answer. OpenSeeker-v2 asks how much frontier search-agent behavior can come from carefully filtered SFT trajectories. The agent-memory circuit paper opens the write-manage-read loop and shows that routing, extraction, and grounding emerge at different model scales. Learning-to-Theorize pushes world models away from pure prediction and toward executable, compositional theories inferred from raw observations.
What I Am Watching This Round
The last few issues leaned hard into external evidence: workspaces, traces, document graphs, schema exploration, visual focus, and predictive latents. I still think that is the right deployment instinct, but I did not want another issue whose whole argument is “make the state visible.” This time I looked for papers that ask a slightly earlier question: what kind of internal or training structure makes the later evidence useful?
I screened the May 5-6 window across arXiv, community leads, Chinese media, and lab/project pages. The broader shortlist included reasoning-intensive retrieval, Workspace-Bench, iWorld-Bench, RoboAlign-R1, VLM curiosity, Agentic-imodels, FINER-SQL, PatRe, and several mechanism papers. I kept three papers because each has open full text, enough figures for a real explainer, and a different answer to the same underlying problem: search agents need better trajectories, memory agents need stage-level circuits, and world models need reusable theories rather than only next-state fit.
Paper Notes
OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
Authors: Yuwen Du, Rui Ye, Shuo Tang, Keduan Huang, Xinyu Zhu, Yuzhu Cai, Siheng Chen.
Institutions: Shanghai Jiao Tong University.
Date/Venue: May 5, 2026, arXiv preprint.
Links: arXiv | HTML | PDF | code | model
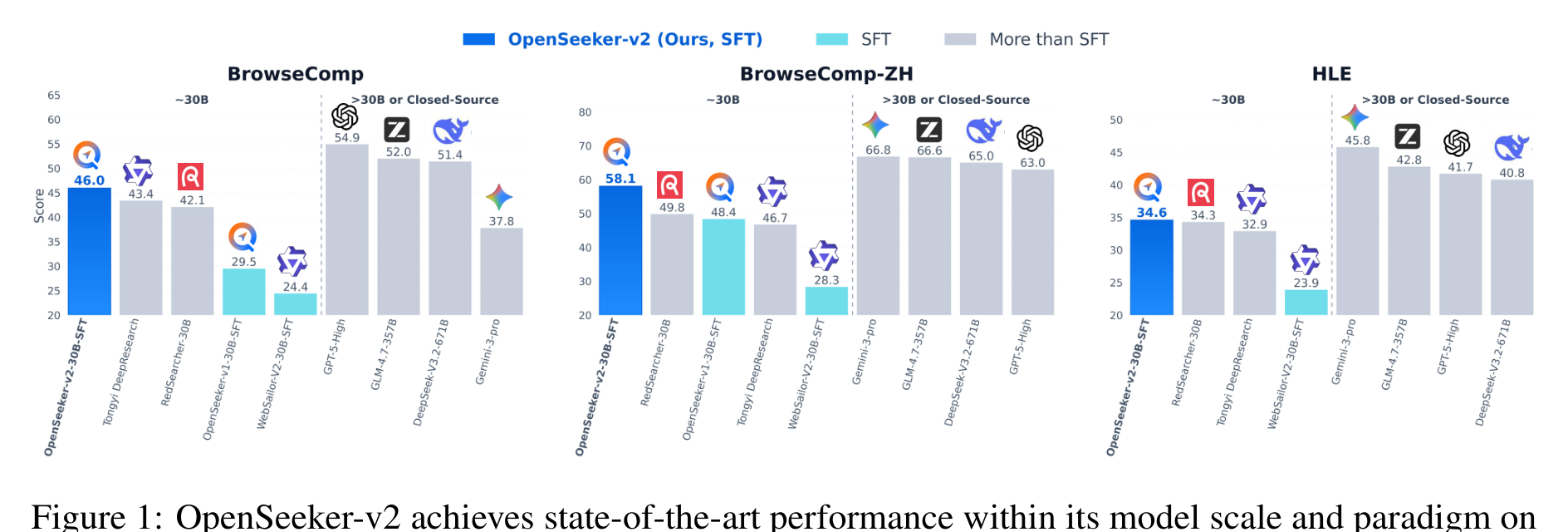
This overview figure is the paper’s main empirical claim: a 30B ReAct-style search agent trained only with SFT can land near or above heavier search-agent pipelines on several public deep-search benchmarks. The figure supports the “trajectory quality before algorithm complexity” reading, not a universal claim that RL is unnecessary. I would read the comparison carefully because some baseline rows come from public reports or leaderboards, not one fully controlled rerun.

The tool-call plot is more diagnostic than a leaderboard row. OpenSeeker-v2’s training trajectories are longer and more demanding than earlier OpenSeeker-v1 and RedSearcher data, with the paper reporting 64.67 average steps per trajectory versus 46.97 and 36.01. That matters because search-agent SFT is not just imitation of answer text; it is imitation of exploration depth, tool selection, and evidence recovery behavior.
Quick idea: OpenSeeker-v2 argues that a small but deliberately difficult set of search trajectories can train a strong open search agent with plain SFT.
Why it matters: the usual story around frontier deep-research agents is expensive: continual pretraining, large SFT mixtures, then RL. The useful question here is whether the bottleneck is really the optimizer stack, or whether many open agents are undertrained on the wrong kind of trajectory. For research assistants and data agents, this is not a cosmetic distinction. If trajectory curation buys most of the gain, small labs can reproduce more of the behavior and inspect the data path more easily.
Method walkthrough:
- Start from the OpenSeeker data-construction pipeline, but scale the knowledge-graph expansion budget from a local neighborhood to a larger evidence subgraph. In the paper’s notation, the expanded subgraph is
G_sub^(K)=Expand(G, v_seed, K)withK > k. - Generate questions from the richer subgraph and equip the agent with a broader tool set, so the demonstrated ReAct trajectories require more search actions and evidence integration.
- Apply strict low-step filtering. The final SFT set keeps trajectories only when their tool-use path is sufficiently long, yielding 10.6k training samples rather than a larger but easier mixture.
- Fine-tune Qwen3-30B-A3B-Thinking-2507 with standard SFT, a 256k context window, and up to 200 tool calls per trajectory. The authors explicitly do not add RL or extra hyperparameter tuning.
Main result slice from the paper.
| Model | Training | Academic team? | BrowseComp | BrowseComp-ZH | HLE | xbench |
|---|---|---|---|---|---|---|
| WebSailor-V2-30B-SFT | SFT | No | 24.4 | 28.3 | 23.9 | 61.7 |
| WebSailor-V2-30B-RL | SFT + RL | No | 35.3 | 44.1 | 30.6 | 73.7 |
| Tongyi DeepResearch | CPT + SFT + RL | No | 43.4 | 46.7 | 32.9 | 75.0 |
| RedSearcher-30B | CPT + SFT + RL | No | 42.1 | 49.8 | 34.3 | not reported |
| OpenSeeker-v1-30B-SFT | SFT | Yes | 29.5 | 48.4 | not reported | 74.0 |
| OpenSeeker-v2-30B-SFT | SFT | Yes | 46.0 | 58.1 | 34.6 | 78.0 |
The table is the paper’s strongest evidence for the simple-training claim. The jump from OpenSeeker-v1 to v2 is large on BrowseComp and still visible on BrowseComp-ZH and xbench, even though the v2 set is only 10.6k examples. The caveat is that these benchmarks measure public deep-search behavior; I would not assume the same recipe transfers unchanged to private enterprise search, scientific literature triage, or data-analysis agents without checking the trajectory distribution.
Why I care: I like this paper because it changes the unit of analysis from “does the final answer look good?” to “what did the training trajectory teach the agent to look for?” That is close to Paper Radar’s own workflow. Better research assistants may not need secret recipes first; they need trajectories whose difficulty forces evidence search instead of answer-style imitation.
Limitations/questions: the report is short, and the ablation story is mostly around the three data changes rather than a broad training-method study. I would next ask whether low-step filtering creates a bias toward over-searching, and whether the agent has a calibrated stopping policy when the answer is easy. The more important follow-up is data transparency: which kinds of graph questions teach transferable search, and which only teach benchmark-specific movement?
Connection to tracked themes: agentic training, search agents, data curation, test-time tool use.
What Happens Inside Agent Memory? Circuit Analysis from Emergence to Diagnosis
Authors: Xutao Mao, Jinman Zhao, Gerald Penn, Cong Wang.
Institutions: City University of Hong Kong; University of Toronto.
Date/Venue: May 5, 2026, arXiv preprint.
Links: arXiv | HTML | PDF

This example is the right on-ramp because memory failures rarely look like crashes. A small model can emit a legal UPDATE decision and silently overwrite a useful memory with an unrelated fact, while a larger model returns NONE on the same instance. The figure supports the paper’s claim that external memory APIs hide several different internal failure modes behind fluent JSON.

The write-circuit figure shows why the paper is more than a behavioral benchmark. For the prompt “I’m planning a trip to Hawaii,” the traced circuit moves from subject anchoring, to word-specific extraction, to a late-layer hub around the JSON output position. The caution is that these are feature-circuit traces through a particular model family and transcoder setup, not a universal map of all agent memory systems.
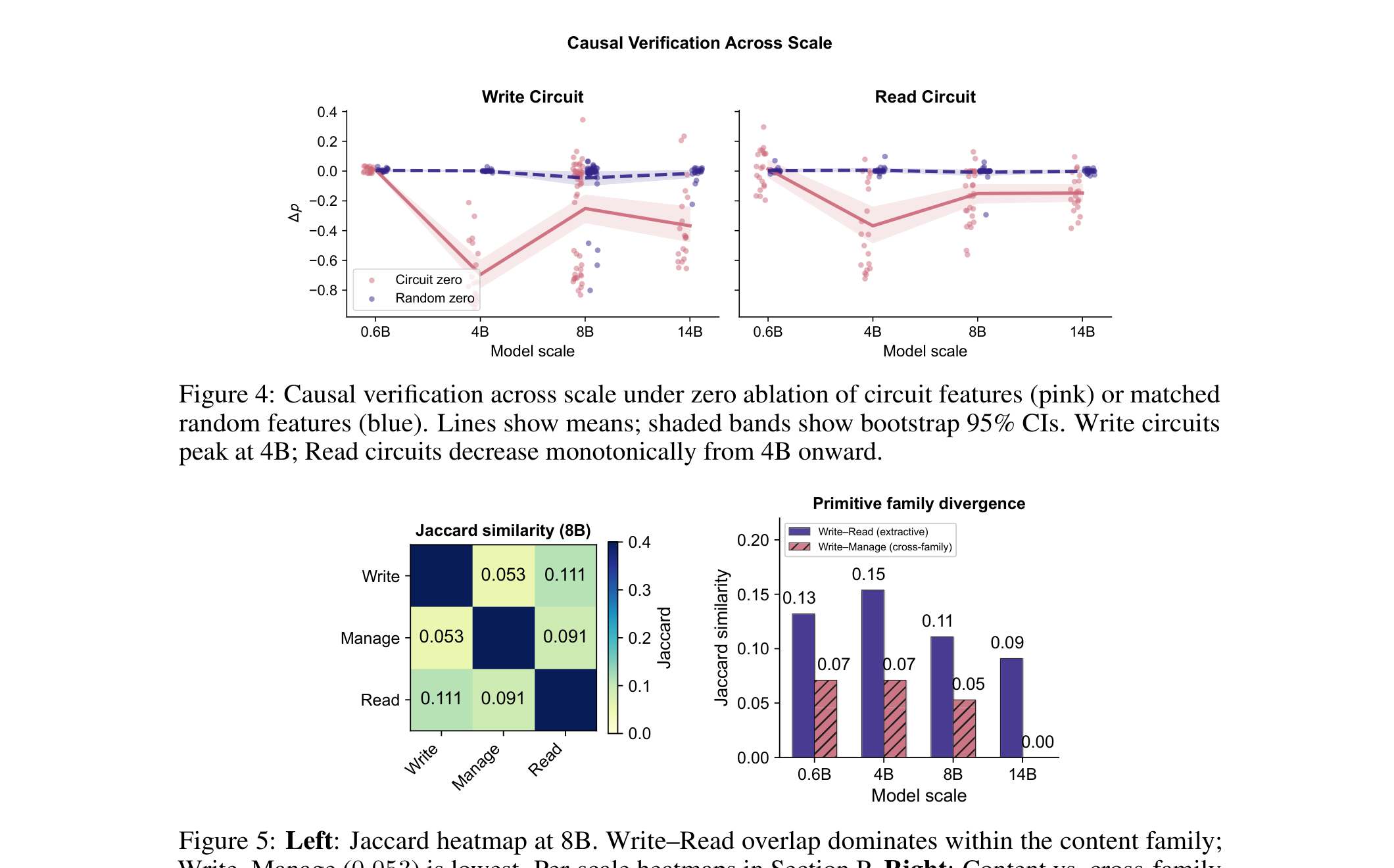
This causal-verification figure is where the scale story becomes interesting. Manage circuits are already detectable in the smallest model, but Write and Read circuits do not show reliable extractive signal until larger scales. The result explains a familiar deployment pattern: a small model can appear to route memory operations competently while still failing at content extraction and grounding.

The overlap plot separates memory computation into two families. Write and Read share more top features than either shares with Manage, which fits the paper’s interpretation that extraction and grounding reuse a late-layer content hub while Manage is more of a routing operation. The caveat is architectural: A-MEM’s Manage stage contains more extractive work than mem0’s, so “Manage” is not the same computation in every memory framework.
Quick idea: the paper traces feature circuits through the write-manage-read loop of agent memory and shows that routing, extraction, grounding, and steerability emerge at different model scales.
Why it matters: long-running agents increasingly depend on memory layers such as mem0, A-MEM, or custom stores. The visible interface is simple: extract facts, update/delete/keep memories, retrieve facts, answer. The hard part is that a wrong Write corrupts the store, a wrong Manage decision persists the corruption, and a wrong Read produces a plausible answer from a bad grounding path. End-to-end accuracy does not tell you which stage failed.
Method walkthrough:
- Treat agent memory as three LLM forward passes: Write extracts facts, Manage chooses add/update/delete/none, and Read answers from retrieved memories. Retrieval itself is embedding-based and is not an LLM call in the studied setup.
- Build stage-specific prompts with JSON prefixes so the first semantically meaningful output token can be used as an attribution target.
- Trace sparse feature circuits across Qwen-3 0.6B, 4B, 8B, and 14B with pre-trained transcoders, using 200 attribution graphs per memory stage.
- Verify causality with feature ablation and amplification, then use stage-specific feature signatures to localize LongMemEval failures without supervised diagnostic training.
Circuit summary at Qwen-3 8B.
| Stage | Graphs | Topology | Canonical path |
|---|---|---|---|
| Write | 200 | Three-stage extractive | L22 -> L28 -> L34 -> L35 |
| Manage | 200 | Shared trunk plus routing | L14 -> L18 -> L35 |
| Read | 200 | Memory-conditioned readout | L22 -> L28 -> L34 -> L35 |
This table makes the central mechanism compact. Write and Read share a late content path, while Manage has a routing-heavy path with different early components. I would treat the layer numbers as Qwen-3-specific, but the decomposition itself is a useful way to think about memory-agent debugging.
Diagnostic accuracy at 8B.
| Method | Accuracy | Requires training? |
|---|---|---|
| Majority class | 51.0% | No |
| Output entropy | 51.5% | No |
| Behavioral rules | 45.4% | No |
| Logistic regression | 63.4% | Yes |
| Circuit diagnostic | 76.2% | No |
The diagnostic table is the practical payoff. The circuit signature does better than simple behavioral rules and a supervised logistic-regression baseline in the reported 8B setting. The important limitation is that “no failure detected” is not a correctness certificate; it only says these discovered signatures did not fire in the expected way.
Evidence: across scales, the authors report a causal gap of 0.004 for Write and 0.012 for Read at Qwen-3 0.6B, both effectively absent under their tracing setup, while Manage already shows 0.259. At 4B, Write, Manage, and Read rise to 0.697, 0.417, and 0.374. At 8B, the circuits become steerable enough that diagnostic-conditional intervention improves LongMemEval fact recall from 0.900 to 0.952 and QA accuracy from 0.574 to 0.614. The cross-system comparison with A-MEM also matters: Read overlaps remain high across scales, suggesting that retrieval grounding recruits similar features even when the memory framework changes.
Why I care: this is the mechanism paper I wanted for agent memory. It does not stop at “memory helps” or “memory fails.” It asks which internal computation failed and whether that stage can be corrected. That is a healthier target for deployed data agents than yet another aggregate memory benchmark.
Limitations/questions: the scope is one model family, a specific circuit-tracing stack, short prompts, and two memory frameworks. The paper says code and data will be released upon acceptance, so reproduction is not yet fully open. I would next ask whether these stage signatures survive tool traces, multilingual memories, confidential enterprise snippets, and memory stores that rewrite facts outside the model.
Connection to tracked themes: large model mechanisms, agent memory, diagnostic interpretability, long-horizon agents.
Learning to Theorize the World from Observation
Authors: Doojin Baek, Gyubin Lee, Junyeob Baek, Hosung Lee, Sungjin Ahn.
Institutions: KAIST.
Date/Venue: May 5, 2026, arXiv preprint; the PDF lists ICML 2026 proceedings.
Links: arXiv | HTML | PDF
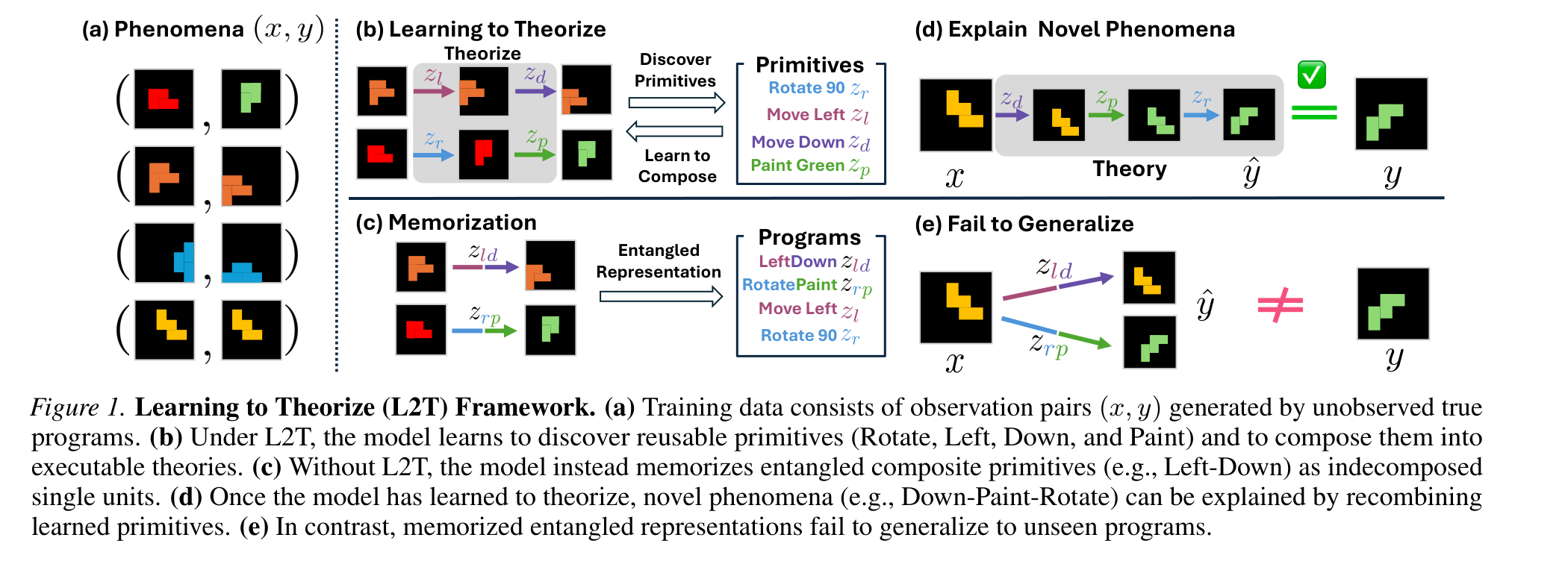
The framework figure gives the paper’s conceptual shift. Instead of learning entangled transformations such as “left-down” as a single unit, the model should discover reusable primitives and compose them into new programs. This is a world-model paper, but its definition of world understanding is not just predicting the next latent state; it is inducing an executable explanation for how one observation becomes another.
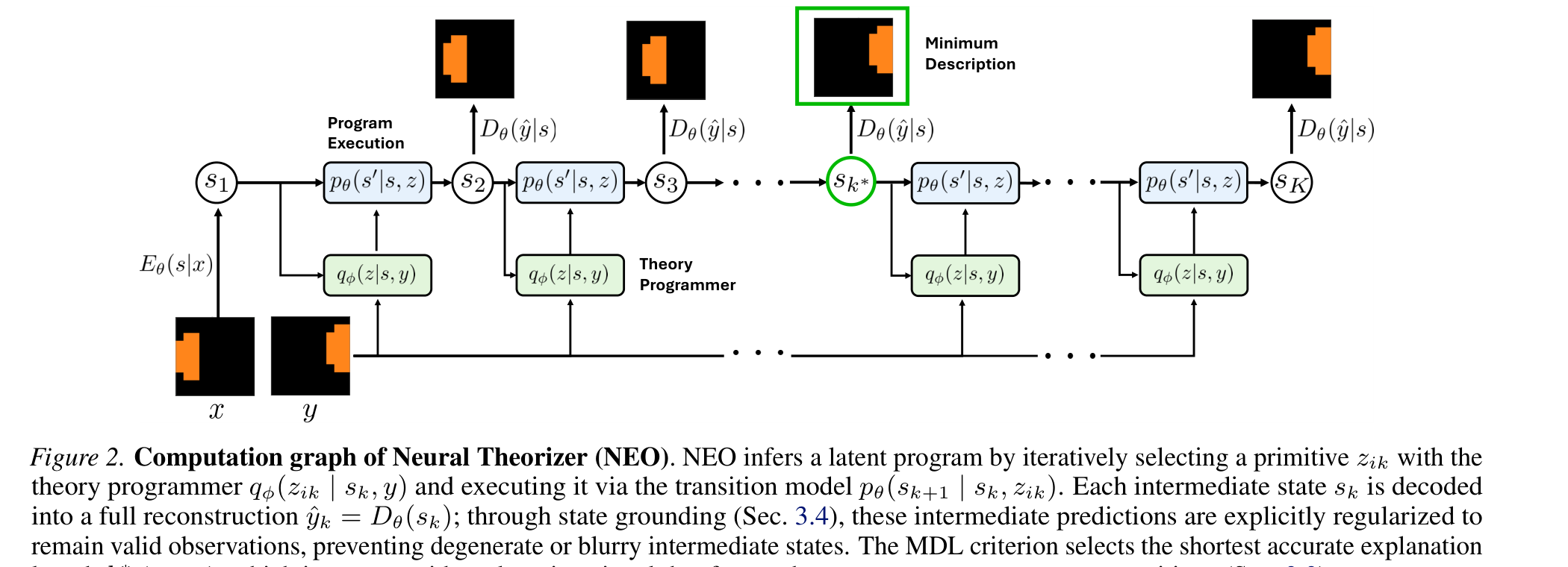
The NEO diagram shows the concrete mechanism. A theory programmer selects a primitive z_ik, a transition model executes it on the latent state s_k, and each intermediate state is decoded so it has to stay close to a valid observation. The green MDL choice is important: the model is pushed toward the shortest accurate explanation, not merely a long sequence that eventually reconstructs the target.
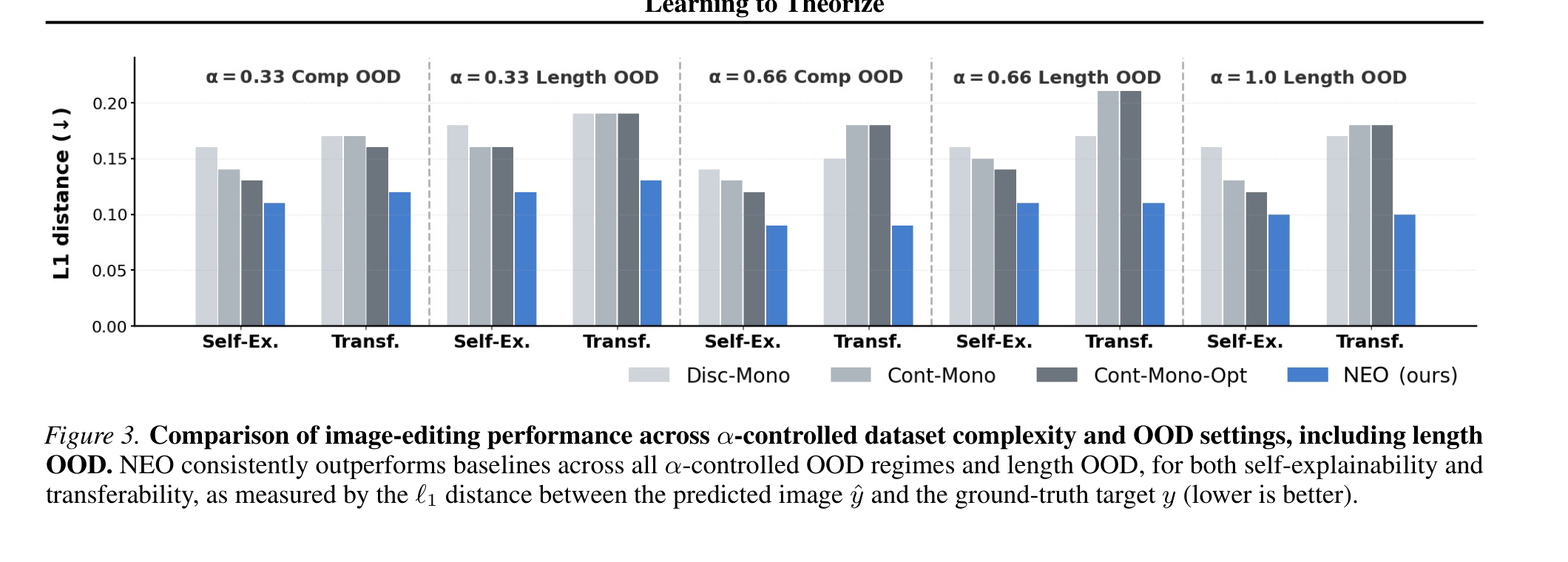
This result figure shows why the method is not only a philosophy of representation. In the image-editing tasks, NEO is evaluated across controlled dataset complexity and OOD settings, including length generalization. The visible pattern is that explicitly composing primitives helps when the test transformation is outside the seen composition set; the caveat is that these are synthetic worlds with known transformation families.

The sampling figure is useful because NEO can spend more inference budget to search over candidate theories. With higher sampling budget, the model approaches near-perfect GridWorld accuracy in the paper’s plot. This makes the method feel closer to planning than a one-shot predictor, but the trade-off is clear: stronger OOD generalization costs more inference.
Quick idea: Learning-to-Theorize reframes a world model as a system that infers executable latent programs from raw observation pairs, so it can reuse primitives in unseen compositions.
Why it matters: most world-model writing still equates understanding with predicting future observations or latent states. That is necessary, but not enough for agents that need to intervene, explain, and compose known operations in new ways. If a robot, data agent, or scientific assistant only learns a smooth input-output map, it may fail exactly where the task asks for a new combination of familiar steps.
Method walkthrough:
- Define a theory as a program
tau=(z_i1, z_i2, ..., z_iK)over learned primitive operations. Execution is functional composition:f_tau = f_zK o f_z(K-1) o ... o f_z1. - Train from raw observation pairs
(x, y)without observing the true program. Training programs are drawn from a restricted subset, while test programs come from disjoint compositions and can be longer than training programs. - Instantiate the model as NEO. The theory programmer
q_phi(z_ik | s_k, y)selects the next primitive, and the shared transition modelp_theta(s_{k+1} | s_k, z_ik)executes it. - Add two practical constraints: MDL length selection,
k* = argmin_k lambda_MDL^k l(y, yhat_k), and state grounding,L_state = sum_k ||s_k - sg[E_theta(D_theta(s_k))]||^2, so intermediate states remain valid and explanations do not become unnecessarily long.
GridWorld result slice.
| Setting | Method | ID self-ex. | ID transfer | Comp. OOD self-ex. | Comp. OOD transfer | Length OOD self-ex. | Length OOD transfer |
|---|---|---|---|---|---|---|---|
| alpha=0.33 | Cont-Mono-Opt | 0.994 | 0.000 | 0.726 | 0.000 | 0.209 | 0.000 |
| alpha=0.33 | NEO | 0.914 | 0.911 | 0.934 | 0.933 | 0.853 | 0.845 |
| alpha=0.33 | NEO-S, B=64 | 0.993 | 0.970 | 0.995 | 0.976 | 0.978 | 0.907 |
| alpha=0.66 | Cont-Mono-Opt | 0.991 | 0.000 | 0.972 | 0.000 | 0.805 | 0.001 |
| alpha=0.66 | NEO-S, B=64 | 0.997 | 0.987 | 0.998 | 0.987 | 0.991 | 0.949 |
This table is the cleanest evidence for program transfer. A continuous monolithic model can reconstruct many targets but often cannot transfer the inferred transformation to a second instance; the transfer columns collapse toward zero. NEO’s self-explanation and transfer numbers stay close, which is exactly what I would want from a theory rather than an instance-level mapping.
Arithmetic factorization result slice.
| Setting | Method | ID transfer | Comp. OOD transfer | Length OOD transfer |
|---|---|---|---|---|
| alpha=0.33 | Disc-Mono | 0.668 | 0.004 | 0.009 |
| alpha=0.33 | Cont-Mono-Opt | 0.001 | 0.000 | 0.000 |
| alpha=0.33 | NEO | 0.792 | 0.345 | 0.038 |
| alpha=0.33 | NEO-S, B=1024 | 0.809 | 0.759 | 0.524 |
| alpha=0.66 | NEO-S, B=1024 | 0.939 | 0.959 | 0.696 |
| alpha=1.00 | NEO-S, B=1024 | 0.954 | not applicable | 0.707 |
The arithmetic task is harder for basic NEO, especially on length OOD, but the sampling variant changes the picture. NEO-S with budget 1024 reaches 0.759 compositional-OOD transfer at alpha=0.33 and 0.696 length-OOD transfer at alpha=0.66. The cost is substantial: the paper reports arithmetic NEO-S inference at 4867.3 ms per batch with B=1024, compared with 27.5 ms for basic NEO and 178.9 ms for Cont-Mono-Opt.
Why I care: this paper gives a precise language for a frustration I keep having with world-model papers. A latent predictor can be impressive and still be poor at saying which reusable mechanism caused the transition. NEO is not a general physical world model yet, but it makes the “mechanism as program” hypothesis explicit and testable.
Limitations/questions: the experiments are synthetic and controlled: GridWorld, arithmetic factorization, and image editing. The paper does not show messy embodied data, contact dynamics, partial observability, or natural video. My next question is whether learned primitives remain stable when observations are noisy, actions are hidden, and multiple mechanisms overlap in one episode.
Connection to tracked themes: world models, compositional generalization, latent programs, agent planning.
Reading Priority and Next Questions
My reading priority from this round is: first the agent-memory circuit paper, because it gives a concrete diagnostic interface for a real agent component; second OpenSeeker-v2, because trajectory quality is an actionable training lever; third Learning-to-Theorize, because it is conceptually important but still lives in controlled domains.
Next I want to track three questions. Can search-agent trajectory filters teach stopping, not just longer exploration? Can memory-stage circuits become runtime alarms in real agent stacks rather than offline interpretability objects? And can theory-style world models survive the jump from synthetic transformations to action-conditioned, partially observed environments?