从搜索轨迹到记忆电路,再到世界理论
Published:
TL;DR:本期我想看的是智能体给出答案之前已经学到的结构。OpenSeeker-v2 讨论高质量、长难度搜索轨迹能把纯 SFT 搜索智能体推到什么程度;agent memory circuit 论文把写入、管理、读取三个记忆阶段拆开做电路追踪;Learning-to-Theorize 则把 world model 从“预测下一帧”推向“从观察中归纳可执行理论”。
本期我在看什么
过去几期 Paper Radar 一直在谈外部证据:工作区、执行轨迹、文档图、数据库探索、视觉 focus、预测 latent。这些都重要,但如果每期都只说“让状态可见”,很快会变成同一种文章。本期我想往前看一步:什么样的训练信号、内部电路或表征目标,会让后面的证据真的有用?
我筛了 2026 年 5 月 5 日到 6 日的 arXiv、中文科技媒体、社区线索和实验室/项目页。候选里有 reasoning-intensive retrieval、Workspace-Bench、iWorld-Bench、RoboAlign-R1、VLM curiosity、Agentic-imodels、FINER-SQL、PatRe 和几篇机理论文。最后只保留 3 篇,因为它们都有开放全文、图表足够清楚,而且分别回答同一个问题的三个侧面:搜索智能体需要什么样的训练轨迹,记忆智能体的失败发生在哪个内部阶段,world model 能不能学到可复用的“理论”而不只是下一状态拟合。
论文细读笔记
OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
作者:Yuwen Du, Rui Ye, Shuo Tang, Keduan Huang, Xinyu Zhu, Yuzhu Cai, Siheng Chen。
机构:上海交通大学。
日期/会议:2026 年 5 月 5 日,arXiv 预印本。
链接:arXiv | HTML | PDF | 代码 | 模型
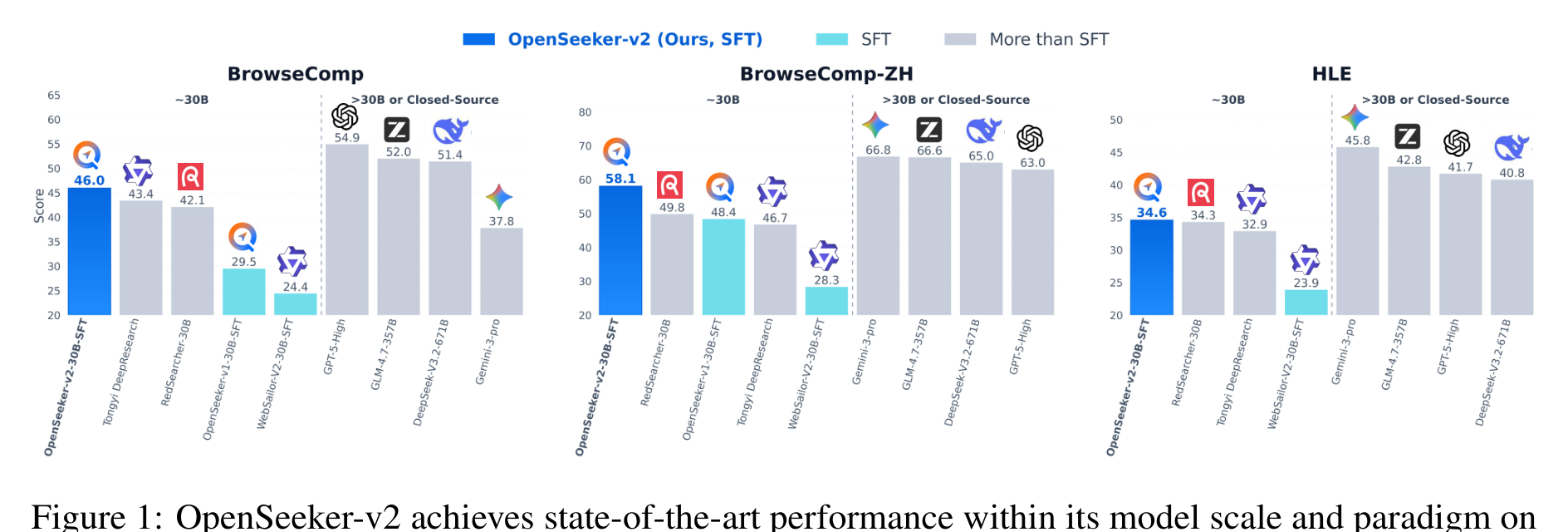
这张总览图给出论文最主要的实验主张:一个 30B 规模、ReAct 范式的搜索智能体,只用 SFT 训练,也能在几个公开 deep-search benchmark 上接近或超过更重的 CPT+SFT+RL 流水线。它支撑的是“轨迹质量可能比训练流程复杂度更关键”这个判断,而不是证明 RL 没有价值。需要谨慎的是,部分 baseline 来自公开报告或 leaderboard,不是同一实验环境下的完整重跑。

工具调用次数图比单纯 leaderboard 更能解释机制。论文报告 OpenSeeker-v2 训练轨迹平均 64.67 步,而 OpenSeeker-v1 是 46.97 步,RedSearcher 是 36.01 步。搜索智能体的 SFT 学到的不只是答案文本风格,而是探索深度、工具选择和证据恢复路径。
一句话核心 idea:OpenSeeker-v2 认为,只要搜索轨迹足够难、信息足够丰富,小规模但高质量的 SFT 数据也能训练出很强的开放搜索智能体。
为什么重要:现在提到 frontier deep research agent,常见叙事是昂贵流水线:继续预训练、大规模 SFT、再 RL。OpenSeeker-v2 问的是另一个更可操作的问题:瓶颈到底在优化器组合,还是在训练轨迹太容易、太短、太像答案模仿?对研究助手和数据智能体来说,这不是细枝末节。如果轨迹构造本身就能带来大部分收益,小团队更有机会复现、检查和改进这个能力。
方法拆解:
- 从 OpenSeeker 原有数据构造流程出发,但扩大知识图谱扩展预算,让问题生成基于更大的 evidence subgraph。论文写成
G_sub^(K)=Expand(G, v_seed, K),其中K > k。 - 从更丰富的子图生成问题,并扩大工具集合,让示范轨迹必须做更多搜索动作和证据整合。
- 严格过滤低步数轨迹。最终 SFT 数据只有 10.6k 条,但每条都要求有足够长的工具调用路径。
- 用 Qwen3-30B-A3B-Thinking-2507 做标准 SFT,256k context,最多 200 次工具调用;论文明确没有加入 RL 或额外超参调优。
论文主结果摘录。
| 模型 | 训练方式 | 纯学术团队? | BrowseComp | BrowseComp-ZH | HLE | xbench |
|---|---|---|---|---|---|---|
| WebSailor-V2-30B-SFT | SFT | 否 | 24.4 | 28.3 | 23.9 | 61.7 |
| WebSailor-V2-30B-RL | SFT + RL | 否 | 35.3 | 44.1 | 30.6 | 73.7 |
| Tongyi DeepResearch | CPT + SFT + RL | 否 | 43.4 | 46.7 | 32.9 | 75.0 |
| RedSearcher-30B | CPT + SFT + RL | 否 | 42.1 | 49.8 | 34.3 | 未报告 |
| OpenSeeker-v1-30B-SFT | SFT | 是 | 29.5 | 48.4 | 未报告 | 74.0 |
| OpenSeeker-v2-30B-SFT | SFT | 是 | 46.0 | 58.1 | 34.6 | 78.0 |
这张表是论文支持“简单训练 + 难轨迹”主张的关键证据。OpenSeeker-v2 相比 v1 在 BrowseComp 上提升很明显,在 BrowseComp-ZH 和 xbench 上也有可见收益。我的谨慎读法是:这些数字说明公开 deep-search 行为可以被高质量轨迹显著推动,但不能直接推出私有企业搜索、科学文献检索或数据分析智能体会无缝受益。
我为什么关心:这篇论文把分析单位从“答案像不像好答案”换成了“训练轨迹到底教会模型去找什么”。这和 Paper Radar 自己的工作流很接近。更好的研究助手也许不一定先需要神秘训练配方,而是需要足够难、足够可检查的证据搜索轨迹。
局限和问题:报告篇幅较短,消融主要围绕三个数据修改,而不是系统比较训练算法。下一步我最想问两件事:低步数过滤会不会让模型过度搜索?它能不能学会 calibrated stopping,也就是问题很容易时及时停下?更深一层的问题是数据透明度:哪些图谱问题真的教会了可迁移搜索,哪些只是教会了 benchmark 内移动路线?
关联主题:agentic training、搜索智能体、数据构造、测试时工具使用。
What Happens Inside Agent Memory? Circuit Analysis from Emergence to Diagnosis
作者:Xutao Mao, Jinman Zhao, Gerald Penn, Cong Wang。
机构:香港城市大学;多伦多大学。
日期/会议:2026 年 5 月 5 日,arXiv 预印本。
链接:arXiv | HTML | PDF

这张例子图很适合作为入口,因为记忆失败通常不会表现成 crash。小模型会输出合法的 UPDATE,然后把一个有用记忆用不相关事实覆盖掉;大模型在同一例子上输出 NONE。图里支撑的不是“大模型总是对”,而是外部 memory API 会把不同内部失败都包装成看似合规的 JSON。

写入阶段电路图说明这篇论文不是普通行为 benchmark。对于 “I’m planning a trip to Hawaii.” 这个输入,电路从 subject anchoring,到词级抽取,再到 JSON 输出位置附近的 late-layer hub。需要注意的是,这些是特定 Qwen-3 模型族和 transcoder 设置下的 feature-circuit trace,不是所有记忆系统的通用脑图。
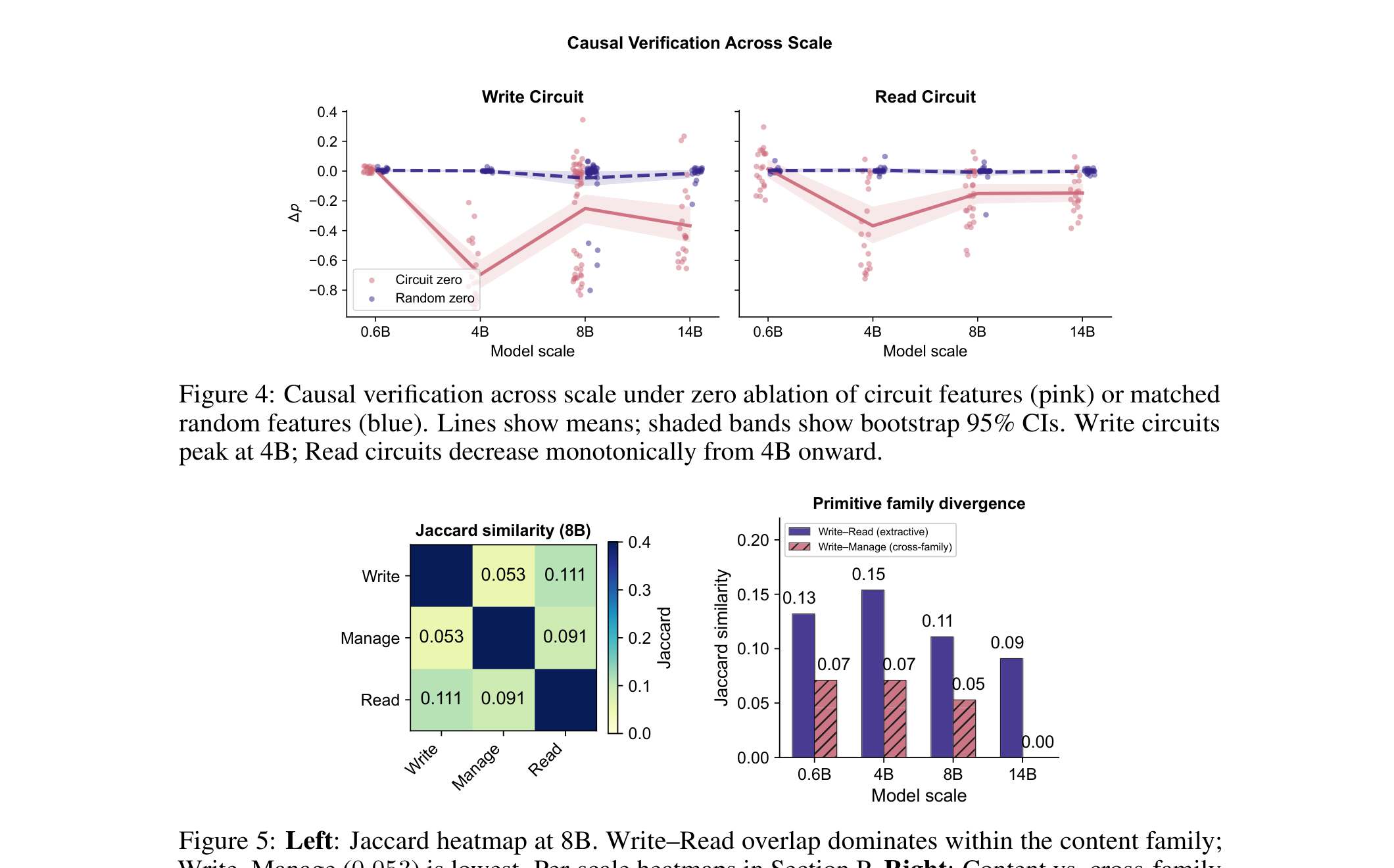
跨尺度因果验证图是这篇最有意思的部分。Manage 路由电路在最小模型里已经可检测,但 Write 和 Read 的内容抽取/ grounding 信号要到更大模型才可靠出现。这解释了一个常见部署现象:小模型好像能正确选择 add/update/delete/none,但内容抽取和读取 grounding 可能是静默失败的。

Jaccard overlap 图把记忆计算分成两个家族:Write 和 Read 共享更多 top features,而它们和 Manage 的重叠更少。这符合论文的解释:抽取和读取复用 late-layer content hub,Manage 更像路由/决策操作。这里也有框架差异:A-MEM 的 Manage 本身包含更多语义演化,所以不同系统里的 “Manage” 不一定是同一种计算。
一句话核心 idea:论文把 agent memory 的 write-manage-read loop 拆成可追踪的 feature circuits,发现路由、抽取、grounding 和可干预性在不同模型尺度上分阶段出现。
为什么重要:长期运行的智能体越来越依赖 mem0、A-MEM 或自研 memory store。外部接口看起来很简单:抽取事实、决定增删改查、检索事实、回答问题。但失败链条很长:Write 错了会污染存储,Manage 错了会把污染持久化,Read 错了会从错误 grounding 路径里生成流畅答案。只看端到端准确率,很难知道到底哪个阶段坏了。
方法拆解:
- 把 agent memory 视为三个 LLM forward pass:Write 抽取事实,Manage 选择 add/update/delete/none,Read 根据检索到的 memory 回答。论文研究设置中,retrieval 是 embedding search,不是 LLM 调用。
- 为每个阶段构造带 JSON prefix 的 prompt,让第一个有语义的输出 token 可以作为 attribution target。
- 在 Qwen-3 0.6B、4B、8B、14B 上用预训练 transcoders 做 sparse feature circuit tracing,每个记忆阶段 200 个 attribution graphs。
- 用 feature ablation 和 amplification 做因果验证,再用阶段特异的 feature signature 无监督定位 LongMemEval 失败类型。
Qwen-3 8B 的电路摘要。
| 阶段 | 图数量 | 拓扑 | 典型路径 |
|---|---|---|---|
| Write | 200 | 三阶段抽取 | L22 -> L28 -> L34 -> L35 |
| Manage | 200 | shared trunk + routing | L14 -> L18 -> L35 |
| Read | 200 | memory-conditioned readout | L22 -> L28 -> L34 -> L35 |
这张表把机制压得很清楚:Write 和 Read 共享 late content path,Manage 走另一条更偏路由的路径。层号本身应当视为 Qwen-3 具体结果,但这种 stage-level decomposition 对调试记忆智能体很有启发。
8B 上的诊断准确率。
| 方法 | 准确率 | 需要训练? |
|---|---|---|
| Majority class | 51.0% | 否 |
| Output entropy | 51.5% | 否 |
| Behavioral rules | 45.4% | 否 |
| Logistic regression | 63.4% | 是 |
| Circuit diagnostic | 76.2% | 否 |
诊断表是这篇论文最接近应用的证据。基于电路 signature 的诊断,在论文报告的 8B 设置下超过了行为规则和监督 logistic-regression baseline。必须强调的是,“未检测到失败”不等于答案正确;它只表示这些被发现的 signature 没有按预期方式激活。
关键证据:跨尺度看,Qwen-3 0.6B 上 Write 和 Read 的 causal gap 分别只有 0.004 和 0.012,在该 tracing 设置下基本不可检测;Manage 已经有 0.259。到 4B,Write、Manage、Read 分别升到 0.697、0.417、0.374。到 8B,电路可 steer 到足以做 conditional intervention:LongMemEval fact recall 从 0.900 到 0.952,QA accuracy 从 0.574 到 0.614。跨系统比较也有价值:A-MEM 和 mem0 的 Read overlap 在各尺度都较高,说明 retrieval grounding 可能会调用相似特征,即使 memory framework 不同。
我为什么关心:这是我这段时间想看到的 agent memory 机理论文。它没有停在“memory 有用”或“memory 会失败”,而是追问哪个内部阶段失败、能不能按阶段修正。对部署中的数据智能体来说,这比又一个 aggregate memory benchmark 更有价值。
局限和问题:范围仍然有限:一个模型族、一套 circuit tracing 工具、短 prompt、两个 memory frameworks。论文 checklist 里也写到代码和数据会在接收后释放,所以现在还不是完全可复现状态。下一步我想看这些 stage signatures 能不能在工具轨迹、多语言记忆、企业私有片段、以及会在模型外部重写事实的 memory store 里保持稳定。
关联主题:大模型机理、agent memory、诊断式可解释性、长程智能体。
Learning to Theorize the World from Observation
作者:Doojin Baek, Gyubin Lee, Junyeob Baek, Hosung Lee, Sungjin Ahn。
机构:KAIST。
日期/会议:2026 年 5 月 5 日,arXiv 预印本;PDF 标注为 ICML 2026 proceedings。
链接:arXiv | HTML | PDF
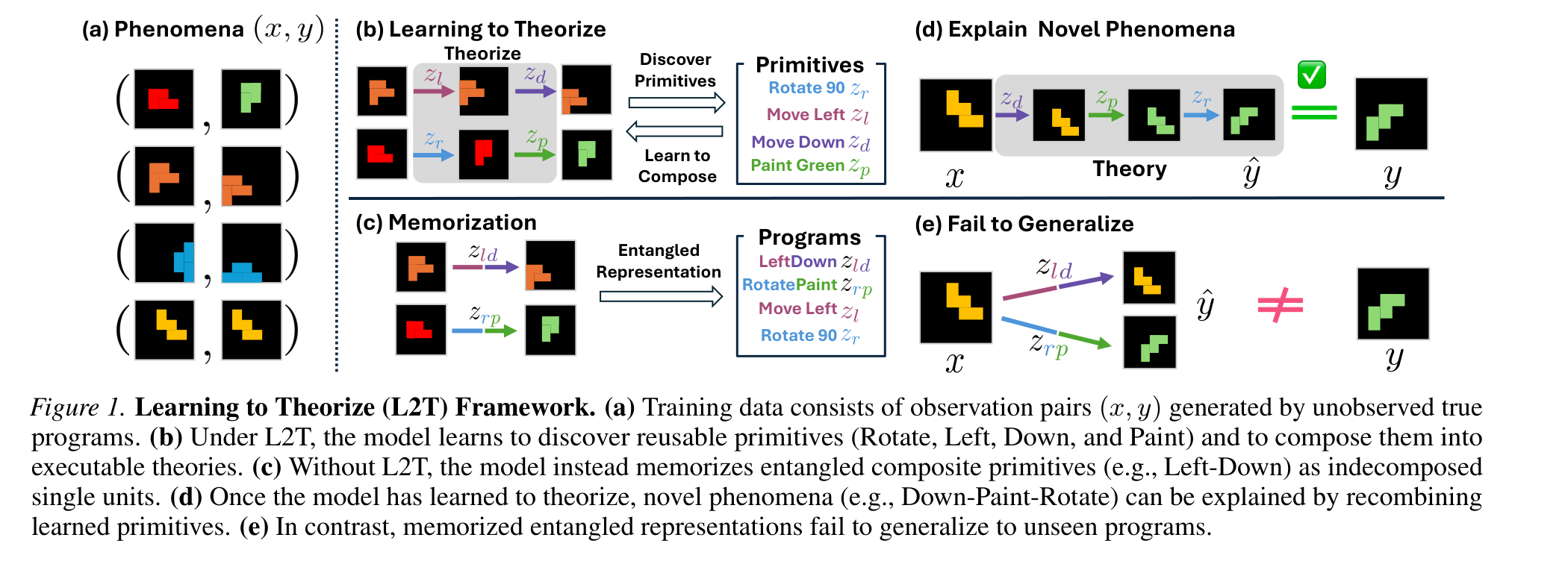
这张框架图给出论文的核心概念转向。模型不应该把 “left-down” 这类组合变换当成一个不可拆的 entangled unit,而应该发现可复用 primitives,再把它们组合成新 program。它是 world model 论文,但这里的“理解世界”不是单纯预测下一 latent state,而是归纳一个能解释观察如何变成另一个观察的可执行机制。
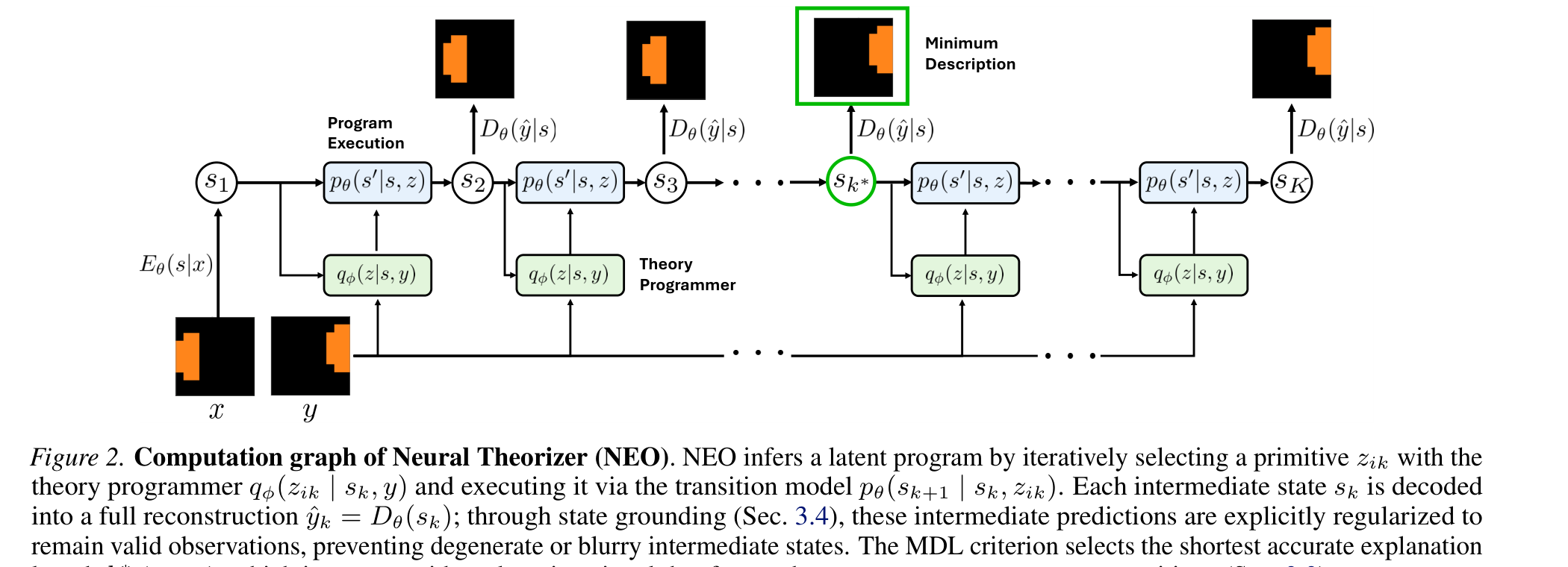
NEO 计算图展示了具体机制。theory programmer 选择一个 primitive z_ik,transition model 在 latent state s_k 上执行它,每个中间状态还会 decode 成 observation 以保持有效。绿色的 MDL 选择很关键:模型被鼓励找最短且准确的解释,而不是用很长的一串操作最后勉强重构目标。
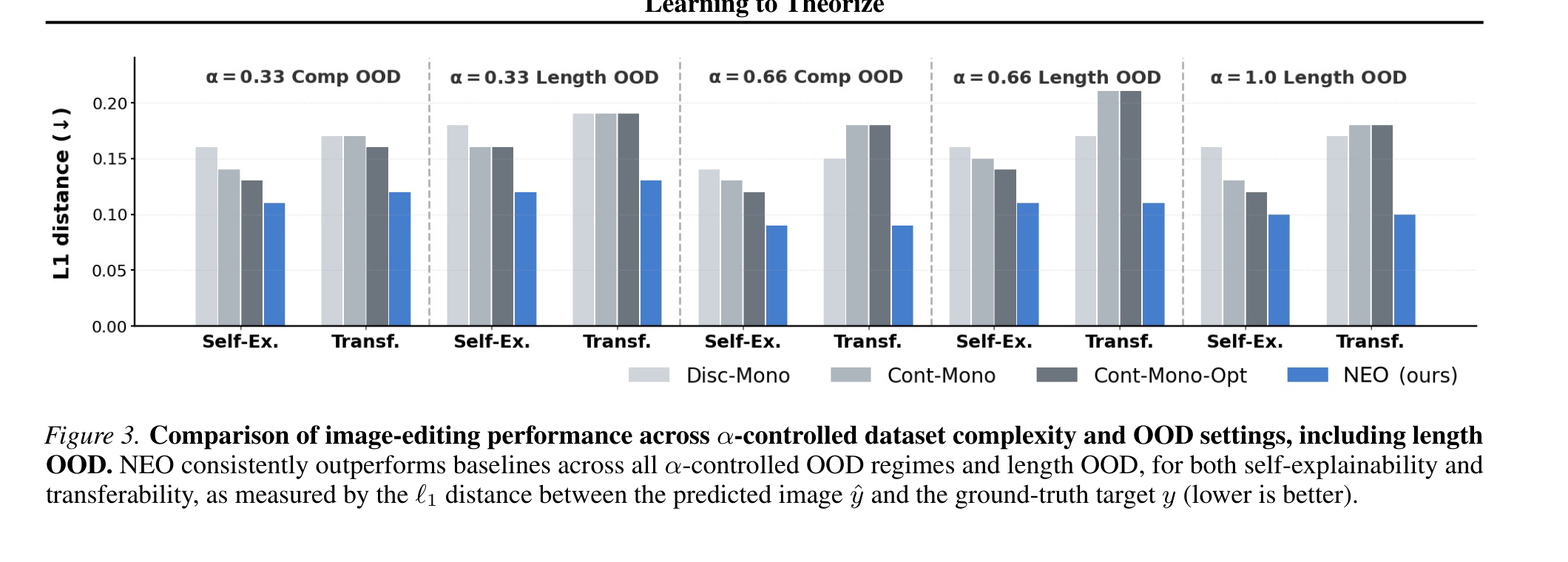
图像编辑结果图说明这不是纯概念文章。论文在受控 dataset complexity 和 OOD 设置下比较,包括 length generalization。图里的主要模式是:显式组合 primitives 对未见组合更有帮助;谨慎点说,这些仍然是合成世界,变换族是可控的。

采样式 test-time scaling 图说明 NEO 可以花更多推理预算搜索候选理论。预算增加后,论文图中 GridWorld accuracy 接近完美。这让方法更像 planning,而不是一次性 predictor;代价也很清楚:更强的 OOD generalization 需要更多 inference compute。
一句话核心 idea:Learning-to-Theorize 把 world model 重新定义为从原始 observation pairs 中归纳可执行 latent programs 的系统,使模型能够把学过的 primitives 组合到未见场景。
为什么重要:很多 world model 文章仍然把理解等同于预测未来 observation 或 latent state。这当然必要,但对需要干预、解释、组合已知操作的智能体来说还不够。如果机器人、数据智能体或科学助手只学到一个平滑的 input-output map,它可能恰好在“熟悉步骤的新组合”上失败。
方法拆解:
- 把 theory 定义为一串 learned primitives:
tau=(z_i1, z_i2, ..., z_iK)。执行就是函数组合:f_tau = f_zK o f_z(K-1) o ... o f_z1。 - 训练只使用原始 observation pairs
(x, y),不观察真实 program。训练 programs 来自受限子集,测试 programs 来自不相交组合,并且可以比训练 program 更长。 - 用 NEO 实例化:theory programmer
q_phi(z_ik | s_k, y)选择下一步 primitive,共享 transition modelp_theta(s_{k+1} | s_k, z_ik)执行它。 - 加入两个约束:MDL 长度选择
k* = argmin_k lambda_MDL^k l(y, yhat_k), 以及 state groundingL_state = sum_k ||s_k - sg[E_theta(D_theta(s_k))]||^2, 让中间状态保持有效,也让解释不要无意义地变长。
GridWorld 结果摘录。
| 设置 | 方法 | ID self-ex. | ID transfer | Comp. OOD self-ex. | Comp. OOD transfer | Length OOD self-ex. | Length OOD transfer |
|---|---|---|---|---|---|---|---|
| alpha=0.33 | Cont-Mono-Opt | 0.994 | 0.000 | 0.726 | 0.000 | 0.209 | 0.000 |
| alpha=0.33 | NEO | 0.914 | 0.911 | 0.934 | 0.933 | 0.853 | 0.845 |
| alpha=0.33 | NEO-S, B=64 | 0.993 | 0.970 | 0.995 | 0.976 | 0.978 | 0.907 |
| alpha=0.66 | Cont-Mono-Opt | 0.991 | 0.000 | 0.972 | 0.000 | 0.805 | 0.001 |
| alpha=0.66 | NEO-S, B=64 | 0.997 | 0.987 | 0.998 | 0.987 | 0.991 | 0.949 |
这张表最能说明“program transfer”。连续的 monolithic baseline 能重构不少目标,但把推断出的变换迁移到第二个实例时,transfer 列接近 0。NEO 的 self-explanation 和 transfer 数字很接近,这才像是学到了 theory,而不是只拟合了单个 input-output pair。
Arithmetic factorization 结果摘录。
| 设置 | 方法 | ID transfer | Comp. OOD transfer | Length OOD transfer |
|---|---|---|---|---|
| alpha=0.33 | Disc-Mono | 0.668 | 0.004 | 0.009 |
| alpha=0.33 | Cont-Mono-Opt | 0.001 | 0.000 | 0.000 |
| alpha=0.33 | NEO | 0.792 | 0.345 | 0.038 |
| alpha=0.33 | NEO-S, B=1024 | 0.809 | 0.759 | 0.524 |
| alpha=0.66 | NEO-S, B=1024 | 0.939 | 0.959 | 0.696 |
| alpha=1.00 | NEO-S, B=1024 | 0.954 | 不适用 | 0.707 |
算术任务对基础 NEO 更难,尤其是 length OOD;但采样版本明显改变结果。NEO-S 在 B=1024 时,alpha=0.33 的 compositional-OOD transfer 达到 0.759,alpha=0.66 的 length-OOD transfer 达到 0.696。代价也不小:论文报告 arithmetic 上 NEO-S B=1024 的推理时间是每 batch 4867.3 ms,而基础 NEO 是 27.5 ms,Cont-Mono-Opt 是 178.9 ms。
我为什么关心:这篇论文给了一个很精确的语言来描述我看 world model 时经常遇到的不满。一个 latent predictor 可以很强,但仍然说不清哪个可复用机制导致了状态变化。NEO 还不是通用物理 world model,但它把“机制即 program”这个假设做成了可检验模型。
局限和问题:实验仍然是受控合成任务:GridWorld、arithmetic factorization、image editing。论文没有展示混乱 embodied data、接触动力学、部分可观测、自然视频或显式 action。下一步我想看的是:当 observation 有噪声、action 被隐藏、同一 episode 中多个机制重叠时,learned primitives 还能不能保持稳定?
关联主题:world models、组合泛化、latent programs、agent planning。
阅读优先级和下期问题
本期我会优先继续看 agent-memory circuit 论文,因为它给了真实 agent 组件的诊断接口;其次是 OpenSeeker-v2,因为轨迹质量是马上可以改变的训练杠杆;第三是 Learning-to-Theorize,它概念上重要,但仍在受控领域。
接下来我想追三个问题:搜索智能体的 trajectory filters 能不能教会模型及时停止,而不只是更长探索?memory-stage circuits 能不能从离线 interpretability object 变成真实 agent stack 里的 runtime alarm?theory-style world models 能不能从合成变换跳到 action-conditioned、部分可观测的环境?