Intermediate Work That Agents Can Actually Use
Published:
TL;DR: this round is about intermediate work that another system has to consume. TraceLift asks whether a reasoning plan should be rewarded only when it helps a frozen executor. BRIGHT-Pro asks whether retrieval should cover an evidence portfolio rather than one relevant passage. Agentic-imodels asks whether an interpretable model should be readable by an agent, not only by a human analyst.
What I Am Watching This Round
The last issue looked at structures learned before the final answer: search trajectories, memory circuits, and latent theories. I wanted to avoid repeating that framing. This time the common question is downstream usability. A reasoning trace, a retrieved document set, or a fitted tabular model can look sensible in isolation and still fail when the next component has to act on it.
I screened the May 5 window across arXiv, source packages, community leads, Chinese-media leads, and lab/project pages. The broader shortlist included BRIGHT-Pro/RTriever, TraceLift, iWorld-Bench, RoboAlign-R1, CC-OCR V2, FINER-SQL, DataClaw, Agentic-imodels, ARGUS, ProgramBench, ARIS, QKVShare, and several mechanism candidates. I kept three papers because each has open full text/source, enough figures for a real mini explainer, and a different answer to the same practical problem: train the intermediate artifact against its consumer.
Paper Notes
Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
Authors: Tianyang Han, Hengyu Shi, Junjie Hu, Xu Yang, Zhiling Wang, Junhao Su.
Institutions: D4 Lab; Independent Researcher.
Date/Venue: May 5, 2026, arXiv preprint.
Links: arXiv | PDF
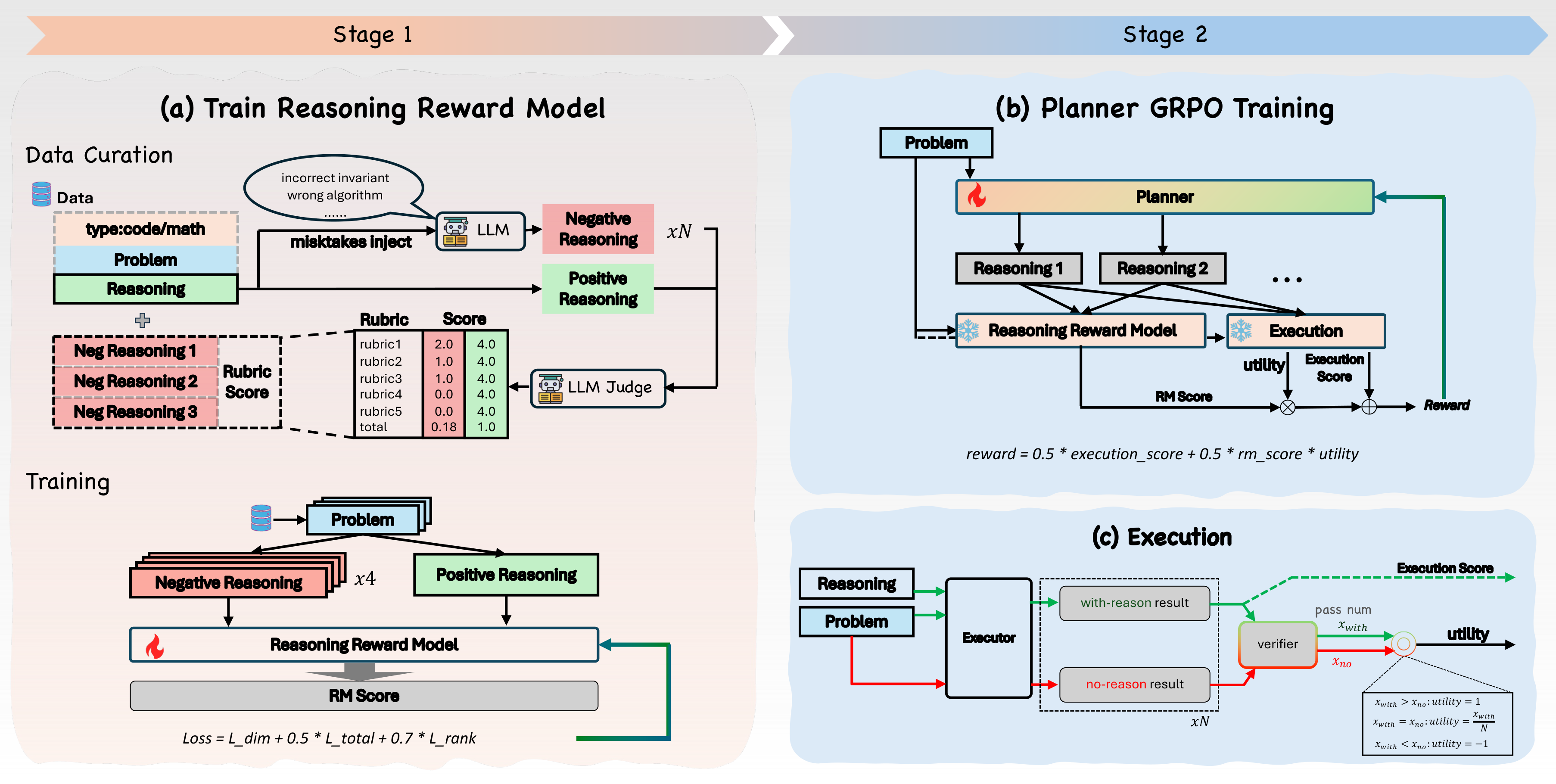
This diagram is the paper’s core design. The planner emits a tagged reasoning trace, a frozen executor turns that trace into code or an answer, and the verifier judges the final artifact. The important move is that TraceLift does not reward reasoning merely because it is fluent or rubric-good; the reward is weighted by measured executor uplift, so a plan has to help the component that consumes it.
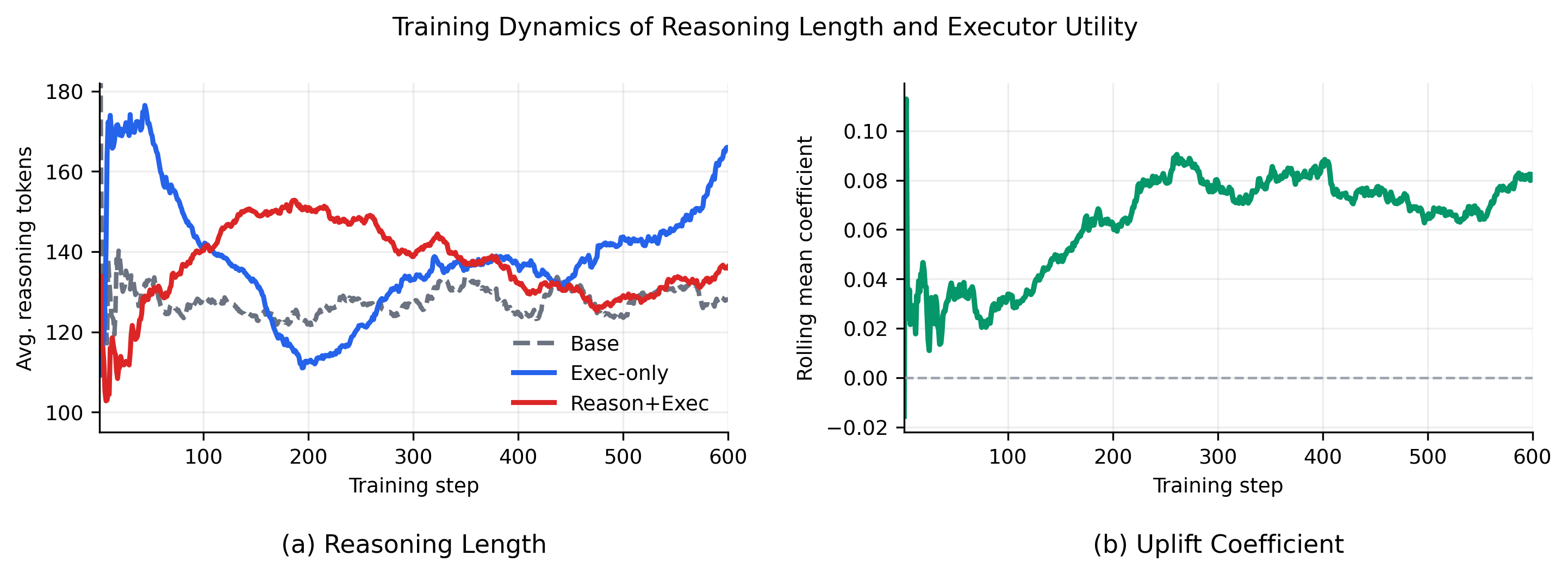
The curve is useful because a method like this can easily collapse into “longer reasoning is better.” The paper uses it to inspect reasoning length and executor utility rather than only final pass rates. I would still treat length as an unresolved confound: the limitation section says the paper has not yet reported full correlations among RM score, executor utility, reasoning reward, and pass/fail flips.
Quick idea: TraceLift trains a reasoning planner with rewards that ask not just “is the final answer correct?” but “did this intermediate trace make the frozen executor more likely to succeed?”
Why it matters: many agent systems already have a planner-executor split. A planner writes a decomposition, an executor writes code, calls tools, or produces the final answer. If RL only rewards final correctness, it can reinforce traces that happen to precede success while still being unfaithful, incomplete, or unusable. That is a real deployment risk: downstream agents consume the trace as an instruction object, not as decorative chain-of-thought.
Method walkthrough:
- Build TraceLift-Groups from 3,000 OpenCodeReasoning problems and 3,000 GSM8K problems. Each group contains a reference reason-only trajectory and targeted flawed variants, such as wrong algorithms, missing edge cases, unsupported math jumps, or content-free reasoning.
- Train a Reasoning Reward Model on grouped supervision. It predicts five rubric dimensions plus an aggregate score, and a ranking loss pushes reference trajectories above flawed trajectories from the same problem.
- During planner GRPO, run the same frozen executor with and without a sampled reasoning trace. The measured uplift is
p_hat(P,R) - p_hat_0(P), clipped to[-1, 1]. - Use the combined reward
0.5 * R_exec + 0.5 * RM(P,R) * uplift(P,R). At evaluation time, the RM and uplift estimator are removed; only the trained planner and frozen executor remain.
Main evidence from the two-stage evaluation.
| Planner family | Code micro avg., Exec-only | Code micro avg., TraceLift | Math micro avg., Exec-only | Math micro avg., TraceLift |
|---|---|---|---|---|
| Qwen2.5-7B | 52.28 | 54.89 | 64.72 | 69.23 |
| Llama3.1-8B | 32.49 | 34.45 | 22.13 | 23.82 |
| Qwen3-4B | 65.88 | 68.32 | 71.50 | 72.34 |
The table supports a controlled planner-executor claim, not a leaderboard claim. The executor is fixed inside each model family, so the gain comes from changing the planner’s training signal. I like that the effect appears across code and math, but I would not overread the mechanism yet: the draft explicitly says no-uplift and RM-only ablations are still pending.
Why I care: this paper gives a clean language for a thing I keep seeing in agent work. Intermediate reasoning should be evaluated as an interface. A plan that helps an executor handle constraints, edge cases, or derivation steps is a different object from a plan that merely co-occurs with a correct answer.
Limitations/questions: the current evidence lacks paired confidence intervals, full reward-component isolation, and win/loss flip analysis. LiveCodeBench uses public/local tests, and MBPP-full is not the EvalPlus leaderboard split. The next question is whether the same idea works for real tool-use traces: retrieval actions, SQL steps, shell commands, and GUI operations.
Connection to tracked themes: agentic training, planner-executor agents, process rewards, consumable reasoning traces.
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
Authors: Yilun Zhao, Jinbiao Wei, Tingyu Song, Siyue Zhang, Chen Zhao, Arman Cohan.
Institutions: Yale NLP Lab; National University of Singapore; NYU Shanghai.
Date/Venue: May 5, 2026, arXiv preprint.
Links: arXiv | PDF | Hugging Face collection | code/data
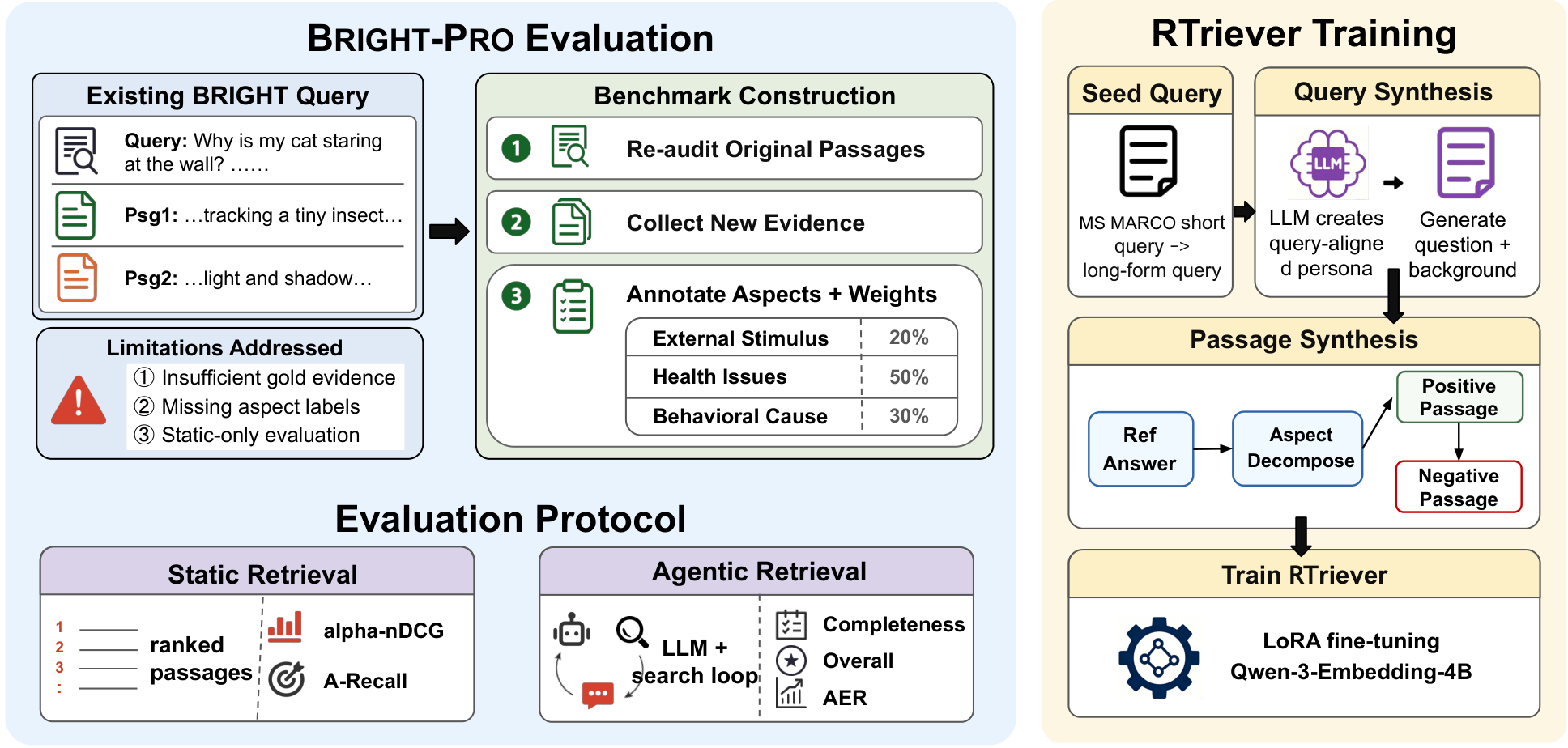
The overview figure explains the paper’s shift from single-passage relevance to multi-aspect evidence coverage. A reasoning-heavy query is decomposed into weighted aspects, positive passages are tied to those aspects, and the retriever is evaluated both statically and inside an agentic search loop. This supports the paper’s main claim: retrieval quality for deep-search agents is about evidence portfolios, not just top-1 topical match.
The data-pipeline figure shows how RTriever-Synth tries to teach complementarity. MS MARCO seeds are rewritten into realistic deep-research queries, analytical queries are decomposed into aspects, positives are generated per aspect, and hard negatives are conditioned on what the positives cover. The caveat is that the training corpus is synthetic; the paper’s human expert annotation is concentrated in BRIGHT-Pro evaluation, not every synthetic training passage.
Quick idea: BRIGHT-Pro and RTriever reframe reasoning-intensive retrieval as finding a balanced evidence portfolio that covers the aspects needed by an agent’s final answer.
Why it matters: current retrievers often look good when one gold passage is enough. Agentic search is different. The agent asks follow-up queries, accumulates snippets, cites evidence, and has to stop when the portfolio is sufficient. If a retriever repeatedly returns the same topical cluster, the final answer may be confident but missing a required premise.
Method walkthrough:
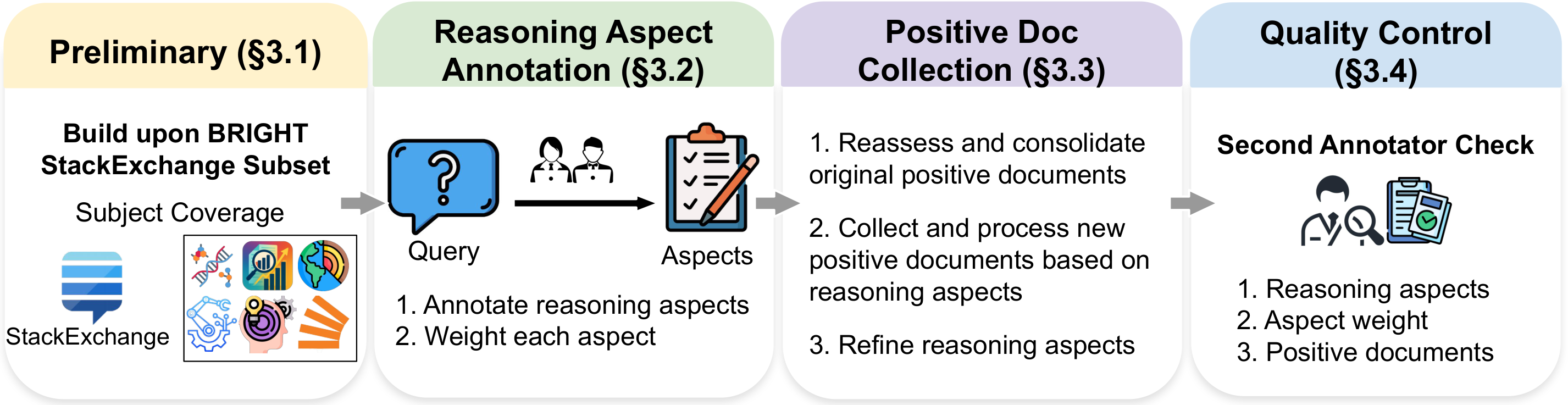
- Start from the StackExchange subset of BRIGHT and ask field experts to decompose each query into reasoning aspects. Each aspect gets a rationale and an importance weight.
- Re-audit BRIGHT positives, assign them to aspects, merge overlapping passages, and collect new aspect-supporting documents with human review. A second annotator checks aspect granularity, weights, and document support.
- Evaluate retrievers statically with aspect-aware metrics such as alpha-nDCG and weighted aspect recall, so repeated retrieval from the same aspect is discounted.
- Evaluate retrievers inside an agentic loop with GPT-5-mini and Qwen3.5-122B-A10B agents. The retriever is the only experimental variable; each round returns top-5 passages, and final answers are judged for aspect coverage and overall quality.
- Train RTriever-4B by LoRA-tuning Qwen3-Embedding-4B on 140K synthetic query-positive-negative bundles, using an InfoNCE objective with complementary positives and positive-conditioned hard negatives.
BRIGHT-Pro data scale.
| Statistic | Value |
|---|---|
| Queries | 739 |
| Documents | 526,319 |
| Average positives per query | 7.13 |
| Average reasoning aspects per query | 3.74 |
| Weighted Cohen’s kappa on aspect weights | 0.742 |
Selected retrieval and agentic results.
| Model | Static alpha-nDCG@25 | GPT-5-mini round-3 overall | GPT-5-mini adaptive rounds | GPT-5-mini AER |
|---|---|---|---|---|
| BGE-Reasoner-8B | 68.0 | 4.31 | 5.10 | 3.65 |
| DIVER-4B | 59.9 | 4.29 | 5.91 | 3.53 |
| RTriever-4B | 54.5 | 4.25 | 6.01 | 3.51 |
| BM25 | 40.3 | 4.12 | 5.73 | 3.53 |
The result I find most interesting is not just where RTriever lands. It is that static rank and agentic answer rank diverge. BM25 climbs inside the agent loop because LLM-issued follow-ups can close vocabulary mismatch. DIVER-4B beats its newer DIVER-4B-1020 sibling on answer quality under GPT-5-mini despite trailing in some static settings. That is exactly why retrieval papers for agents need to evaluate the consumer loop, not only the retriever in isolation.
Limitations/questions: BRIGHT-Pro is high quality but small because expert annotation is expensive, and it currently covers seven StackExchange-derived domains. The synthetic training recipe is deliberately simple: one positive and one hard negative per sampled query at training time. My next question is whether multi-positive objectives and aspect-aware sampling can make the retriever less dependent on the particular agent backend.
Connection to tracked themes: agentic search, document intelligence, data agents, evidence portfolios, retrieval evaluation.
Agentic-imodels: Evolving Agentic Interpretability Tools via Autoresearch
Authors: Chandan Singh, Yan Shuo Tan, Weijia Xu, Zelalem Gero, Weiwei Yang, Michel Galley, Jianfeng Gao.
Institutions: Microsoft Research; National University of Singapore.
Date/Venue: May 5, 2026, arXiv preprint.
Links: arXiv | PDF | code
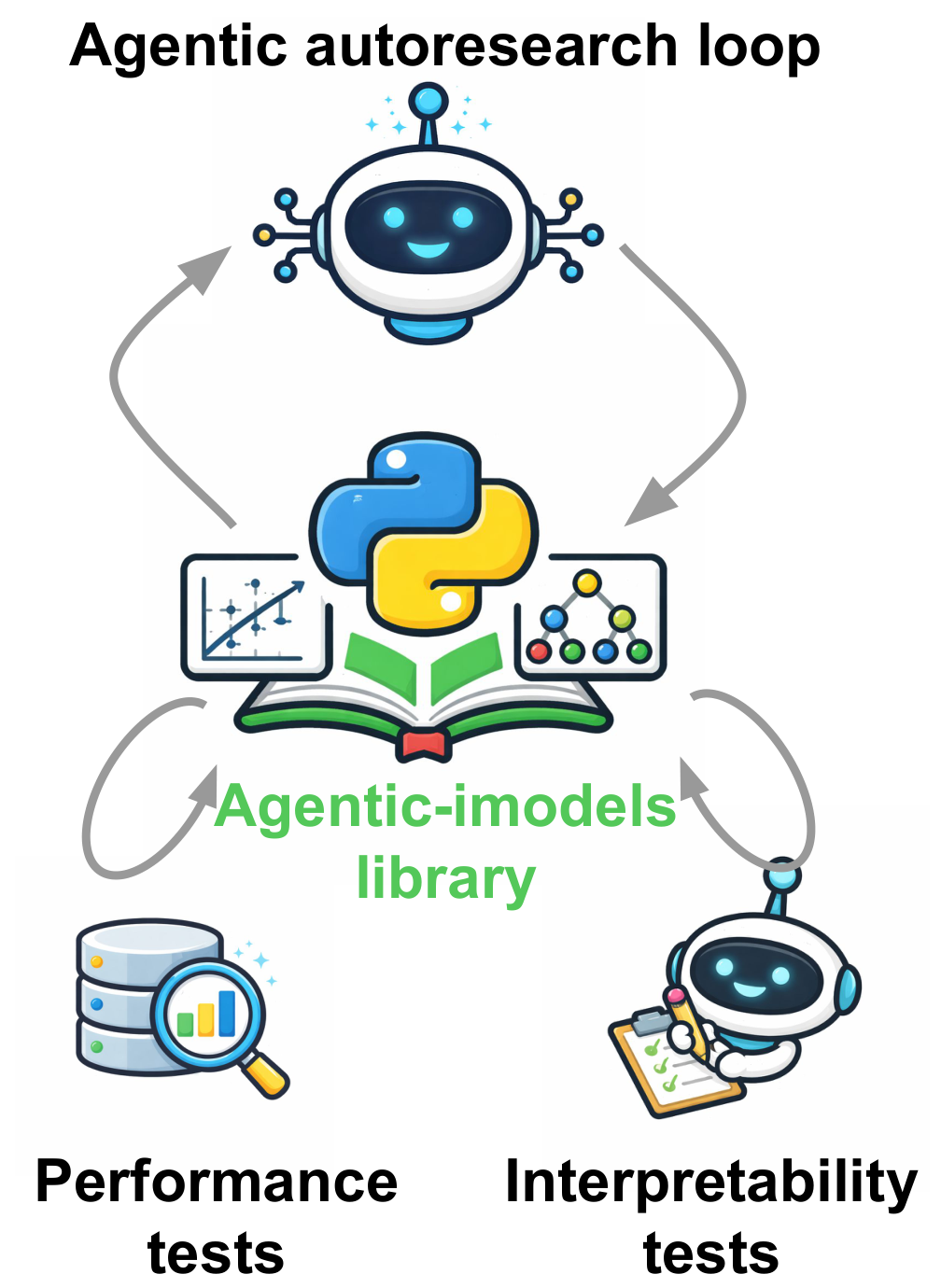
This overview is the paper in one picture: a coding agent edits a scikit-learn-compatible regressor, evaluates predictive performance and agent interpretability, records the result, and continues searching. The target is not human-friendly interpretability in the traditional sense. The target is whether an LLM can simulate the fitted model from its string representation.
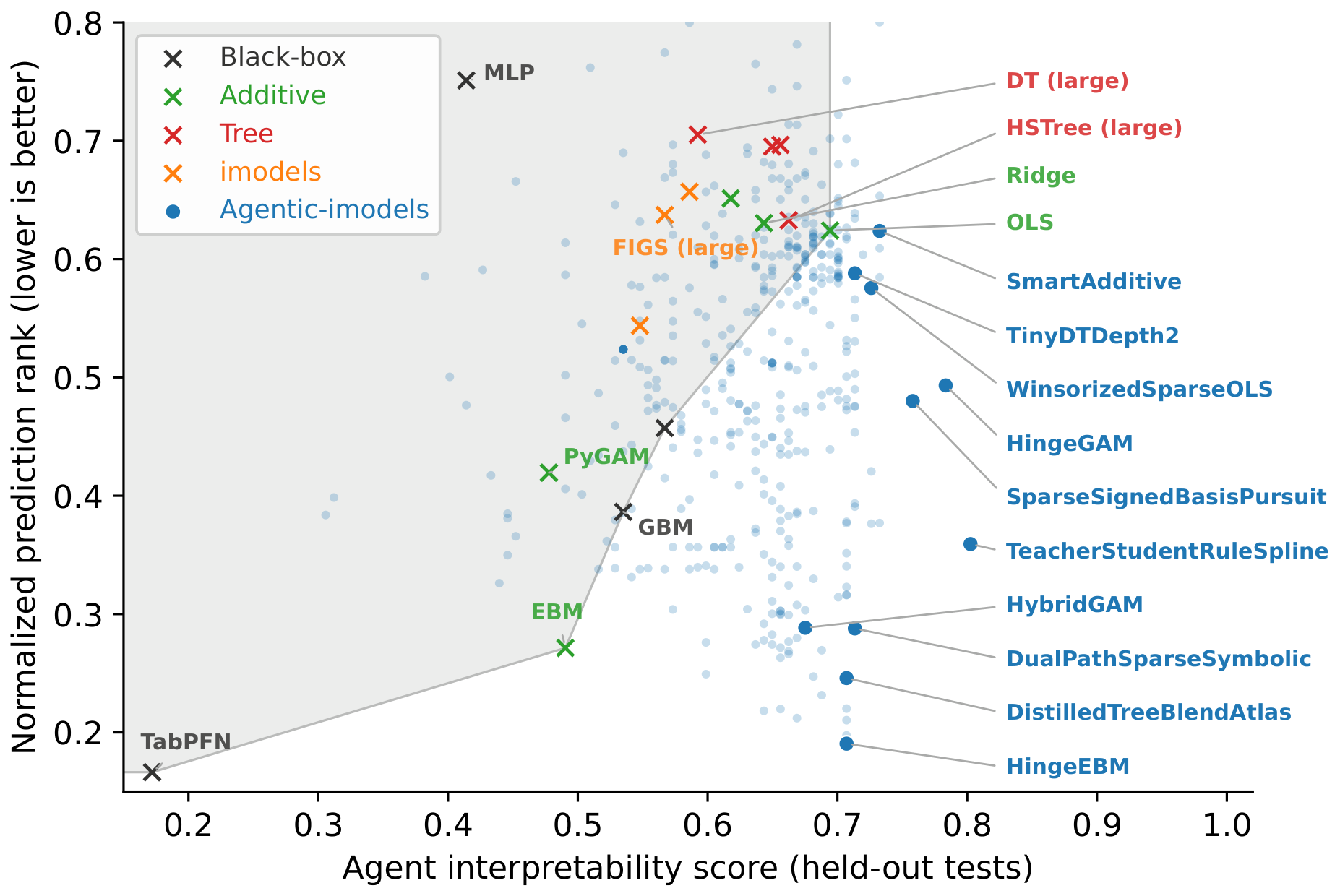
The scatter plot is the central evidence for the model-discovery claim. Baselines occupy a familiar trade-off: strong black-box prediction with weak interpretability, or readable models with worse prediction. The evolved models populate a region with lower normalized RMSE rank and higher held-out agent interpretability, although the plot also warns that some runs can overfit the development interpretability tests.
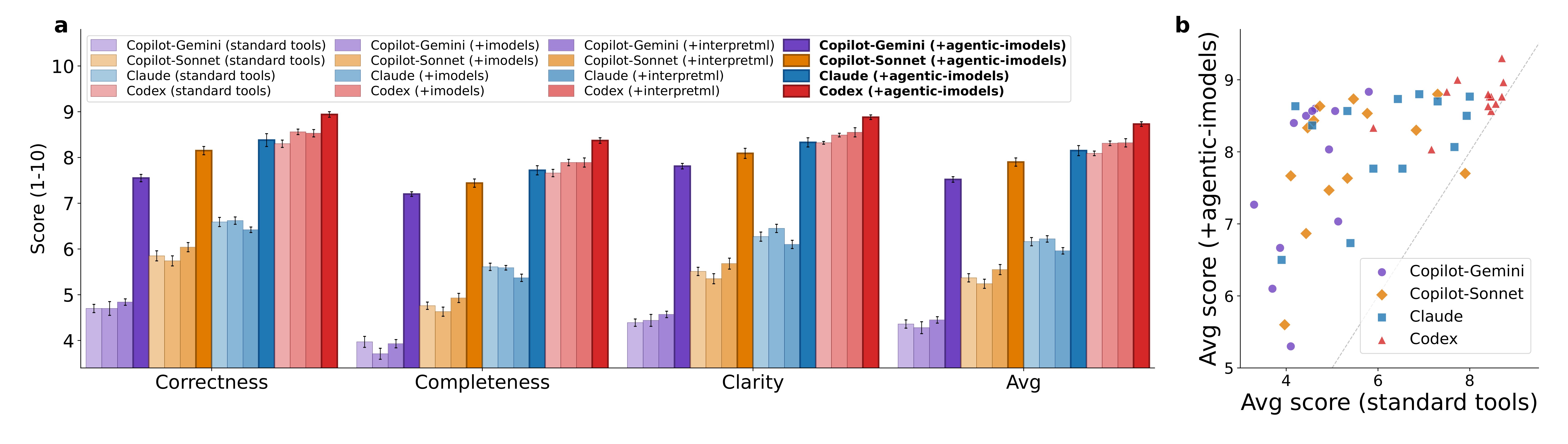
The BLADE figure matters because it tests whether the evolved tools help downstream data agents, not just the paper’s own metric. Giving agents the Agentic-imodels package improves average BLADE scores across Copilot, Claude Code, and Codex settings, with larger gains for weaker baseline systems. The caveat is that BLADE scoring still uses LLM-as-judge, although the reference analyses are written by human experts.
Quick idea: Agentic-imodels uses coding agents to evolve tabular models whose fitted __str__ output is easy for another LLM agent to reason over.
Why it matters: data agents do not only need accurate models. They need intermediate analytical objects they can inspect, quote, and reason about without hallucinating the model’s behavior. Traditional interpretable ML tools were built for human readers; their plots, large trees, coefficient dumps, or feature tables may be awkward for an LLM to simulate. This paper treats “agent-readable” as an optimization target.
Method walkthrough:
- Define predictive performance as average RMSE rank over 65 tabular regression datasets from OpenML TabArena and PMLB.
- Define agent interpretability as pass rate on LLM-graded tests. The LLM receives only the fitted model’s
__str__output and must answer quantitative questions about feature attribution, point prediction, sensitivity, counterfactuals, structure, and nonlinear simulation. - Split the tests into 43 development tests used inside the optimization loop and 157 held-out tests used to detect whether the generated model strings actually generalize.
- Run Claude Code and Codex loops that repeatedly modify one Python class, evaluate both metrics, and record each candidate. The final library curates 10 evolved regressors as an installable tool for data-agent workflows.
Representative evolved models.
| Model | Source | Normalized RMSE rank | Held-out agent interpretability | Main idea |
|---|---|---|---|---|
| HingeEBM | Claude | 0.19 | 0.71 | Lasso on hinge features plus a residual EBM |
| TeacherStudentRuleSpline | Codex | 0.36 | 0.80 | Strong teacher with sparse symbolic student display |
| HingeGAM | Claude | 0.49 | 0.78 | Hinge-basis GAM with adaptive display |
| SmartAdditive | Claude | 0.62 | 0.73 | Boosted-stump GAM with compact per-feature summaries |
BLADE average scores from the paper’s per-dataset table.
| Agent | Standard tools | Agentic-imodels | Relative gain |
|---|---|---|---|
| Copilot CLI, Gemini | 4.36 | 7.52 | 72.5% |
| Copilot CLI, Sonnet | 5.37 | 7.90 | 47.0% |
| Claude Code, Sonnet | 6.16 | 8.15 | 32.3% |
| Codex CLI, GPT-5.3 | 8.09 | 8.73 | 7.9% |
The strongest detail is the display strategy. Many evolved models keep one path for prediction and another path for explanation: for example, a teacher model or residual component may improve accuracy, while the printed string is bounded by top-k features, short hinge tables, rounded coefficients, or a sparse symbolic row. That is a useful design pattern for data agents: constrain the interface before asking the agent to reason with it.
Limitations/questions: the metric can be reward-hacked. The authors found models that score high on development tests but drop on held-out tests, sometimes by reciting test answers in model strings. The end-to-end evaluation also depends on LLM-as-judge. I would next ask whether agent-readable models still help when the task requires causal claims, time series, classification, or messy notebooks with incomplete data provenance.
Connection to tracked themes: data agents, agentic tool design, interpretable ML, autoresearch, consumable analytical artifacts.
Reading Priority and Next Questions
My reading priority from this round is BRIGHT-Pro first, because retrieval portfolios are a direct bottleneck for research agents; then TraceLift, because executor-grounded rewards are a clean training idea; then Agentic-imodels, because it reframes interpretability around the real consumer of the tool.
Next I want to track three questions. Can executor-grounded rewards transfer from code/math reasoning to real tool traces? Can aspect-aware retrieval become a training signal rather than only an evaluation protocol? And can agent-readable data tools preserve auditability when agents move from toy tabular regressions to messy scientific notebooks?