让中间产物能被智能体真正使用
Published:
TL;DR:本期看的是“中间产物”能不能被下游系统真正消费。TraceLift 讨论推理轨迹是否应该按它对冻结执行器的帮助来奖励;BRIGHT-Pro 讨论检索器是否应该覆盖一组互补证据,而不是只找一个相关段落;Agentic-imodels 则把可解释模型重新定义为“智能体读得懂、能模拟”的工具。
本期我在看什么
上一期谈的是答案之前学到的结构:搜索轨迹、记忆电路、潜在理论。本期我不想继续重复这个角度,而是往系统接口上再走一步。推理轨迹、检索证据集、拟合好的数据模型,看起来都可以很合理,但如果下一个组件无法使用它们,这些中间结果就只是漂亮的日志。
我筛了 2026 年 5 月 5 日左右的 arXiv、源代码包、社区线索、中文媒体线索和项目页。候选包括 BRIGHT-Pro/RTriever、TraceLift、iWorld-Bench、RoboAlign-R1、CC-OCR V2、FINER-SQL、DataClaw、Agentic-imodels、ARGUS、ProgramBench、ARIS、QKVShare 等。最后只选 3 篇,因为它们都有开放全文或 source,可提取清晰图表,也都在回答同一个实际问题:中间产物要按它的消费者来训练和评估。
论文细读笔记
《正确还不够:用执行器接地奖励训练推理规划器》
作者:Tianyang Han, Hengyu Shi, Junjie Hu, Xu Yang, Zhiling Wang, Junhao Su。
机构:D4 Lab;Independent Researcher。
日期/会议:2026 年 5 月 5 日,arXiv 预印本。
链接:arXiv | PDF
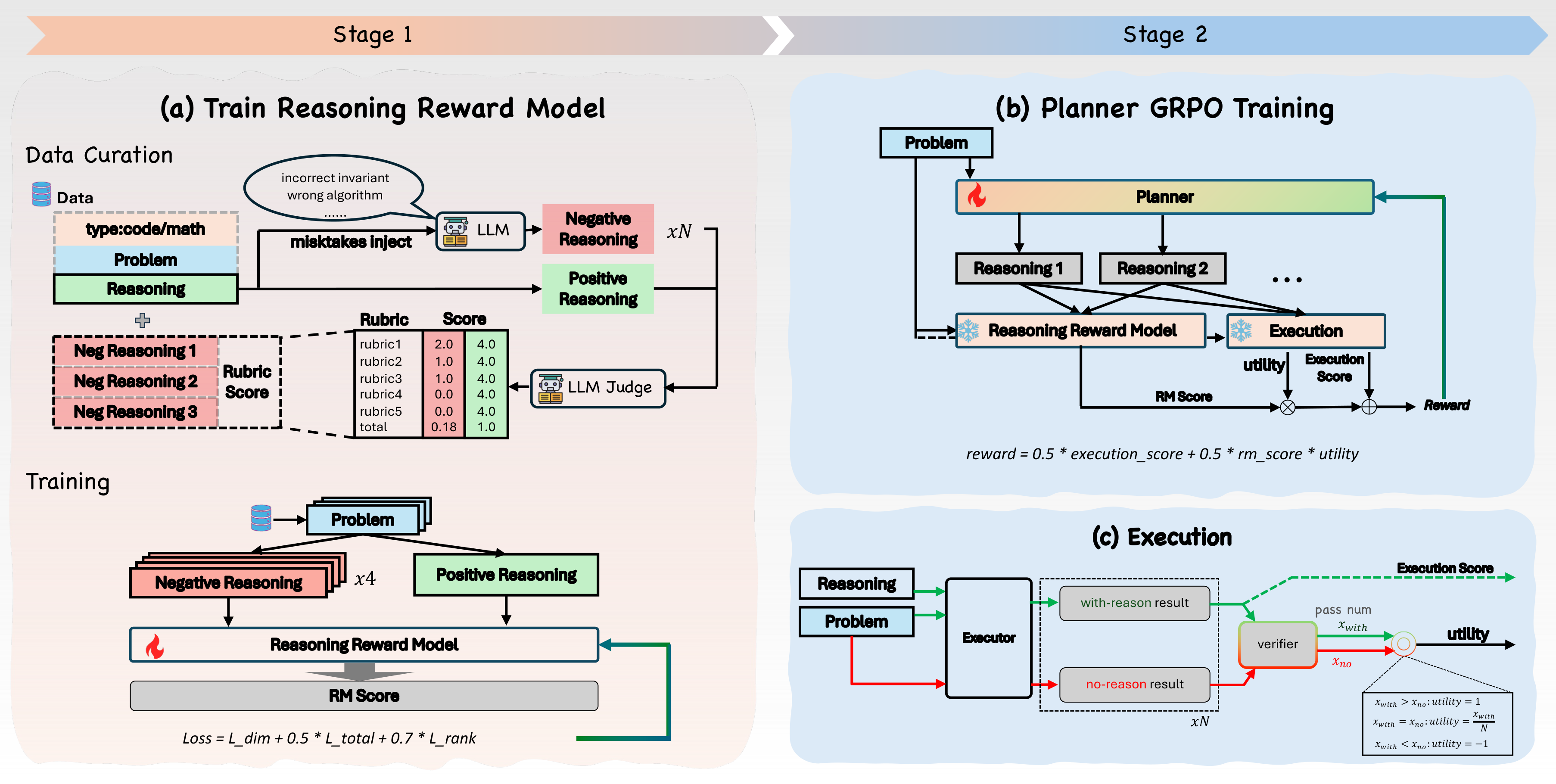
这张框架图就是论文的核心设计:规划器先生成带标签的推理轨迹,冻结执行器把轨迹变成代码或答案,验证器再检查最终产物。关键不在于“推理写得像不像好推理”,而在于这个推理是否让执行器更容易成功。也就是说,中间轨迹被当成给执行器使用的接口,而不是给人看的解释。
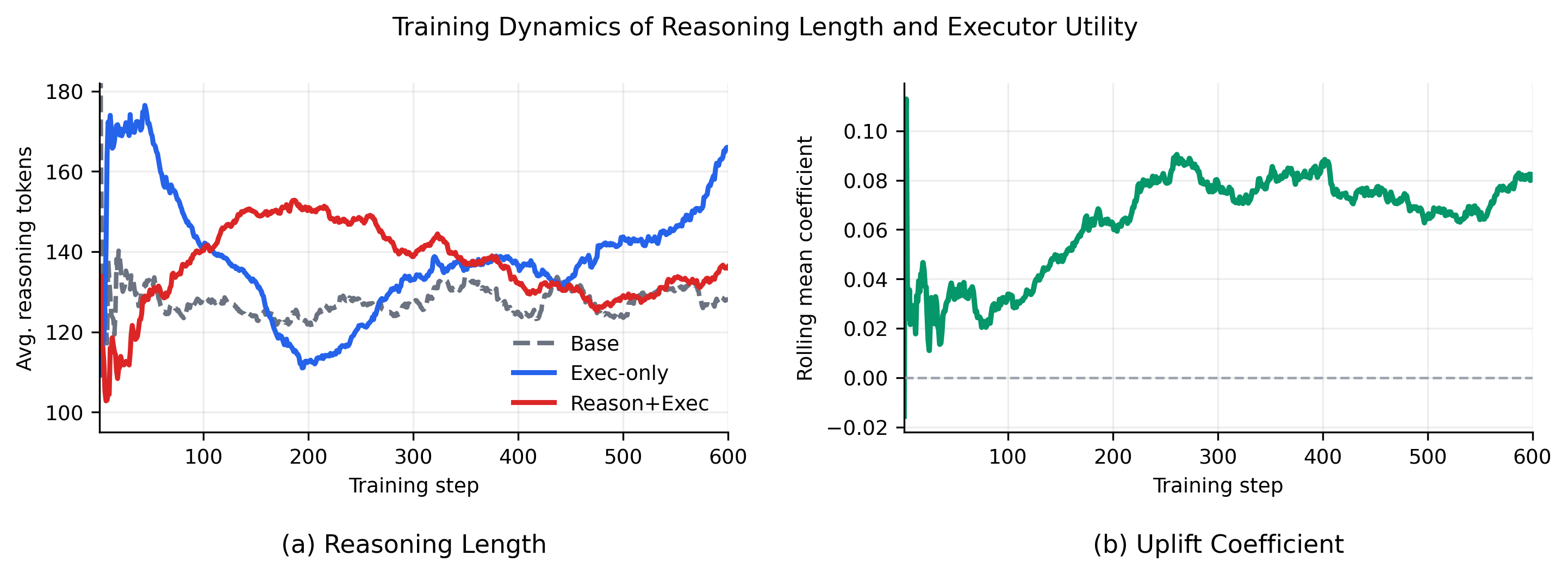
这张曲线有用,是因为这类方法很容易退化成“推理越长越好”。论文至少开始检查推理长度和执行器效用,而不是只报最后 pass rate。我的谨慎点也在这里:论文的 limitation 明确说,还没有完整报告 RM 分数、执行器效用、总奖励和最终成败之间的相关性。
一句话核心 idea:TraceLift 训练推理规划器时,不只问最终答案是否正确,还问这段中间推理是否让同一个冻结执行器更可能成功。
为什么重要:很多智能体系统已经是 planner-executor 结构。planner 写分解,executor 写代码、调工具或给出最终答案。如果 RL 只奖励最终正确,它可能强化一些“碰巧在正确答案前出现”的轨迹,而不是忠实、完整、可执行的轨迹。部署时,下游组件消费的是轨迹这个对象,不是一个装饰性的思维链。
方法拆解:
- 用 3,000 个 OpenCodeReasoning 问题和 3,000 个 GSM8K 问题构造 TraceLift-Groups。每个 group 包含一个 reference reason-only 轨迹,以及错误算法、缺失边界条件、数学跳步、空泛解释等定向坏轨迹。
- 训练 Reasoning Reward Model。它预测 5 个 rubric 维度和总分,并用同题 group 内的 ranking loss 让 reference 轨迹分数高于坏轨迹。
- 训练规划器时,同一个冻结执行器会分别在“有轨迹”和“无轨迹”条件下运行。执行器 uplift 写成
p_hat(P,R) - p_hat_0(P),并裁剪到[-1, 1]。 - 最终奖励是
0.5 * R_exec + 0.5 * RM(P,R) * uplift(P,R)。评测时不再调用 RM 或 uplift estimator,只保留训练好的 planner 和冻结 executor。
两阶段评测主结果。
| 规划器模型族 | 代码 micro avg.,Exec-only | 代码 micro avg.,TraceLift | 数学 micro avg.,Exec-only | 数学 micro avg.,TraceLift |
|---|---|---|---|---|
| Qwen2.5-7B | 52.28 | 54.89 | 64.72 | 69.23 |
| Llama3.1-8B | 32.49 | 34.45 | 22.13 | 23.82 |
| Qwen3-4B | 65.88 | 68.32 | 71.50 | 72.34 |
这张表支持的是一个受控的 planner-executor 结论,而不是 leaderboard 结论。每个模型族内部的 executor 是固定的,变化来自 planner 的训练信号。代码和数学都有提升,这点值得看;但论文也诚实地说,No-uplift 和 RM-only 等关键消融还没完成,所以现在不能说每个奖励部件都已经被因果隔离。
我为什么关心:这篇把“推理”从输出文本变成了系统接口。一个好计划应该帮助执行器处理约束、边界条件和推导步骤。这个视角比“答案前面有没有一段看起来合理的 reasoning”更接近真实智能体工程。
局限和问题:当前结果缺少置信区间、成对 flip 分析和完整奖励部件消融。LiveCodeBench 用的是 public/local tests,MBPP-full 也不是 EvalPlus leaderboard 协议。下一步我想看它能否扩展到真实工具轨迹,比如检索动作、SQL 步骤、shell 命令和 GUI 操作。
关联主题:agentic training、规划器-执行器智能体、过程奖励、可消费推理轨迹。
《重新思考推理密集型检索:在智能体搜索系统中评估和训练检索器》
作者:Yilun Zhao, Jinbiao Wei, Tingyu Song, Siyue Zhang, Chen Zhao, Arman Cohan。
机构:Yale NLP Lab;National University of Singapore;NYU Shanghai。
日期/会议:2026 年 5 月 5 日,arXiv 预印本。
链接:arXiv | PDF | Hugging Face collection | 代码/数据
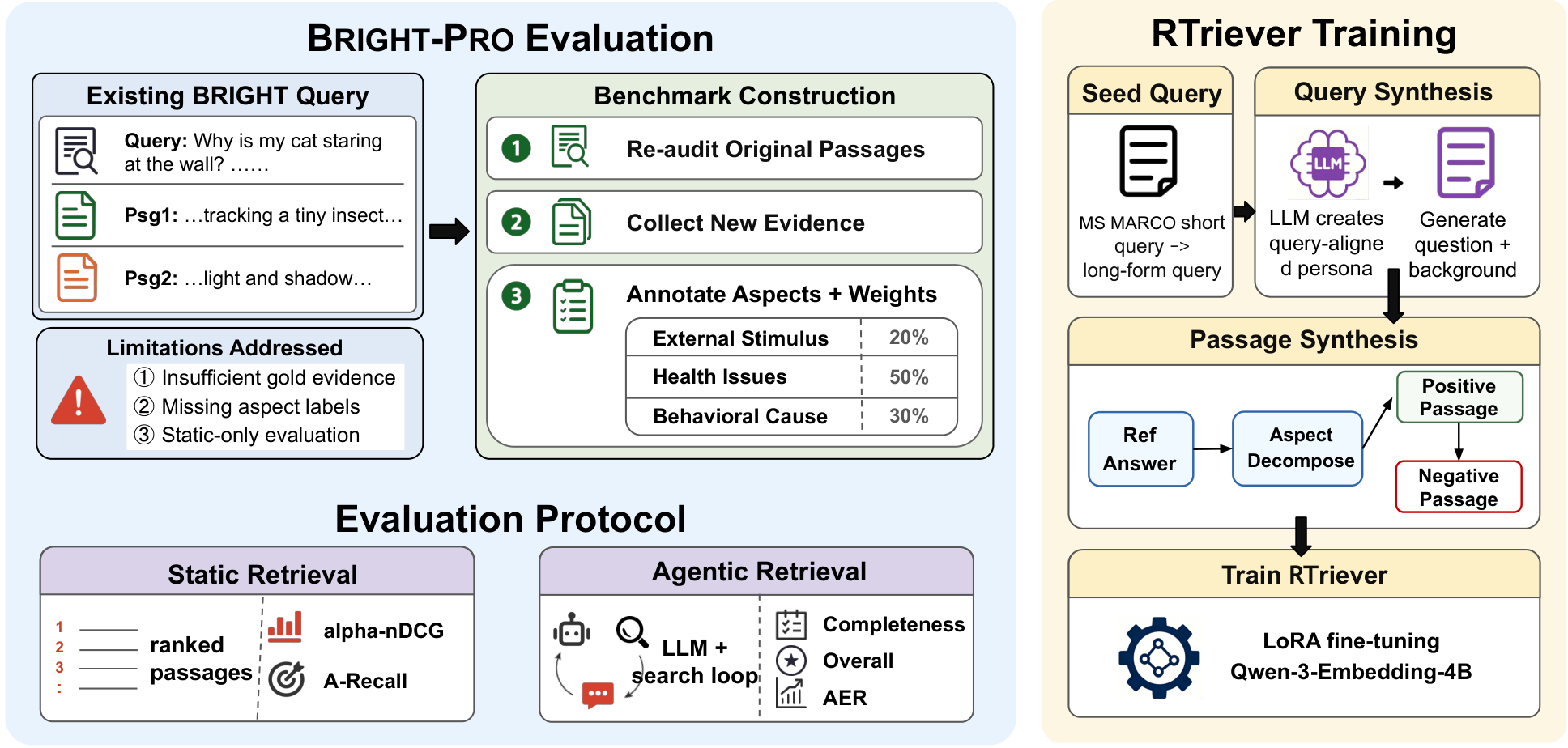
这张总览图说明论文为什么不满足于单段相关性。一个推理型问题会被拆成多个带权重的 reasoning aspects,正例文档也要绑定到这些方面,最后同时做静态检索评测和 agentic search loop 评测。它支撑的核心 claim 是:深度搜索智能体需要的是证据组合,而不是单个 top-1 相关段落。
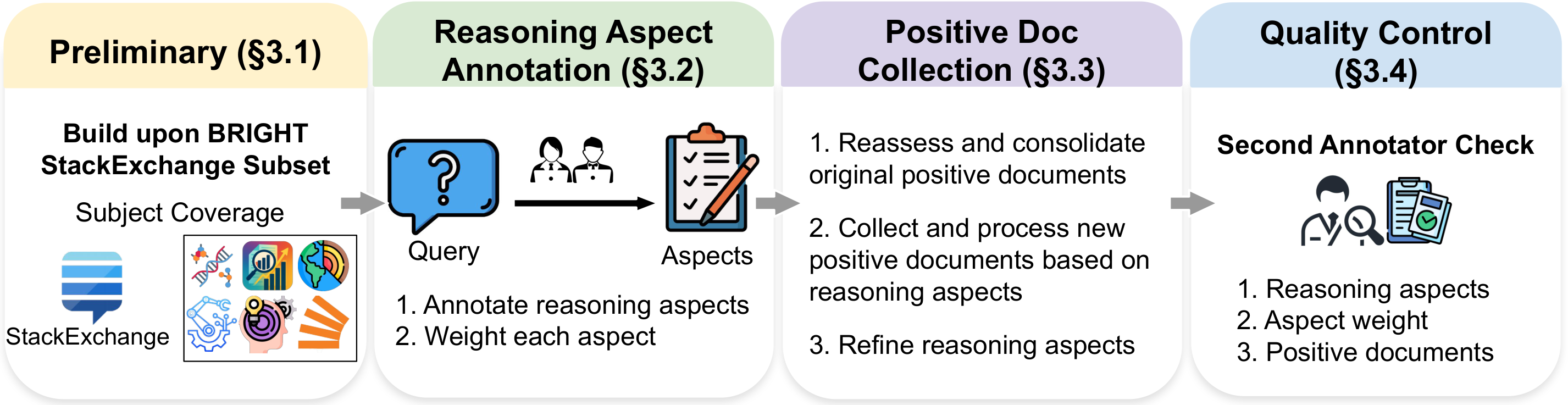
数据管线图展示了 RTriever-Synth 如何教检索器学互补性。MS MARCO 查询先被改写成更像 deep research 的问题,分析型问题再拆成 aspects,为每个 aspect 生成正例,并根据正例覆盖内容生成 hard negatives。需要谨慎的是,训练数据是合成的;真正昂贵的人类专家标注主要用于 BRIGHT-Pro 评测集。
一句话核心 idea:BRIGHT-Pro 和 RTriever 把 reasoning-intensive retrieval 定义为覆盖一组互补证据,让智能体最后能写出完整答案。
为什么重要:普通检索里,一个 gold passage 可能够用;智能体搜索不是这样。agent 会多轮查询、累积片段、引用证据,并在证据足够时停止。如果检索器反复返回同一个主题簇,最终答案可能很流畅,但缺一个关键前提。
方法拆解:
- 从 BRIGHT 的 StackExchange 子集出发,请领域专家把每个 query 拆成 reasoning aspects,并给每个 aspect 一个重要性权重。
- 重新审计 BRIGHT 原始正例,把它们分配到 aspects,合并重复或相邻片段,再补充新的支持文档。第二位标注者检查 aspect 粒度、权重和文档支持关系。
- 静态评测使用 aspect-aware 指标,例如 alpha-nDCG 和 weighted aspect recall,重复覆盖同一 aspect 会被折扣。
- agentic 评测把不同 retriever 接到同一个 GPT-5-mini 或 Qwen3.5-122B-A10B 搜索智能体里;retriever 是唯一变量,每轮返回 top-5 passages,最后评价 reasoning completeness 和 overall quality。
- RTriever-4B 从 Qwen3-Embedding-4B LoRA 微调而来,训练数据是 140K 个合成 query-positive-negative bundles,目标是让正例互补、负例足够贴近但缺少关键 evidence。
BRIGHT-Pro 数据规模。
| 统计项 | 数值 |
|---|---|
| 查询数 | 739 |
| 文档数 | 526,319 |
| 每个查询平均正例数 | 7.13 |
| 每个查询平均 reasoning aspects | 3.74 |
| aspect 权重的 weighted Cohen’s kappa | 0.742 |
部分检索与 agentic 结果。
| 模型 | 静态 alpha-nDCG@25 | GPT-5-mini 第三轮 overall | GPT-5-mini adaptive 轮数 | GPT-5-mini AER |
|---|---|---|---|---|
| BGE-Reasoner-8B | 68.0 | 4.31 | 5.10 | 3.65 |
| DIVER-4B | 59.9 | 4.29 | 5.91 | 3.53 |
| RTriever-4B | 54.5 | 4.25 | 6.01 | 3.51 |
| BM25 | 40.3 | 4.12 | 5.73 | 3.53 |
我最在意的不是 RTriever 排第几,而是静态检索排名和智能体答案排名并不完全一致。BM25 在 agent loop 里明显变强,因为 LLM follow-up queries 可以补一部分词汇不匹配。DIVER-4B 在 GPT-5-mini 最终答案质量上超过更新的 DIVER-4B-1020,尽管后者在某些静态设置更强。这说明 agent 检索论文不能只测 retriever 本身,也要测消费者回路。
局限和问题:BRIGHT-Pro 质量高,但因为专家标注贵,规模不大,领域也主要来自 StackExchange 七个子域。RTriever 的训练 recipe 也刻意简单,每步只采一个 positive 和一个 hard negative。下一步我想看 multi-positive objective、aspect-aware sampling,以及不同 agent backend 下的 retriever-agent compatibility。
关联主题:agentic search、文档智能、数据智能体、证据组合、检索评测。
《Agentic-imodels:用自动研究进化智能体可解释工具》
作者:Chandan Singh, Yan Shuo Tan, Weijia Xu, Zelalem Gero, Weiwei Yang, Michel Galley, Jianfeng Gao。
机构:Microsoft Research;National University of Singapore。
日期/会议:2026 年 5 月 5 日,arXiv 预印本。
链接:arXiv | PDF | 代码
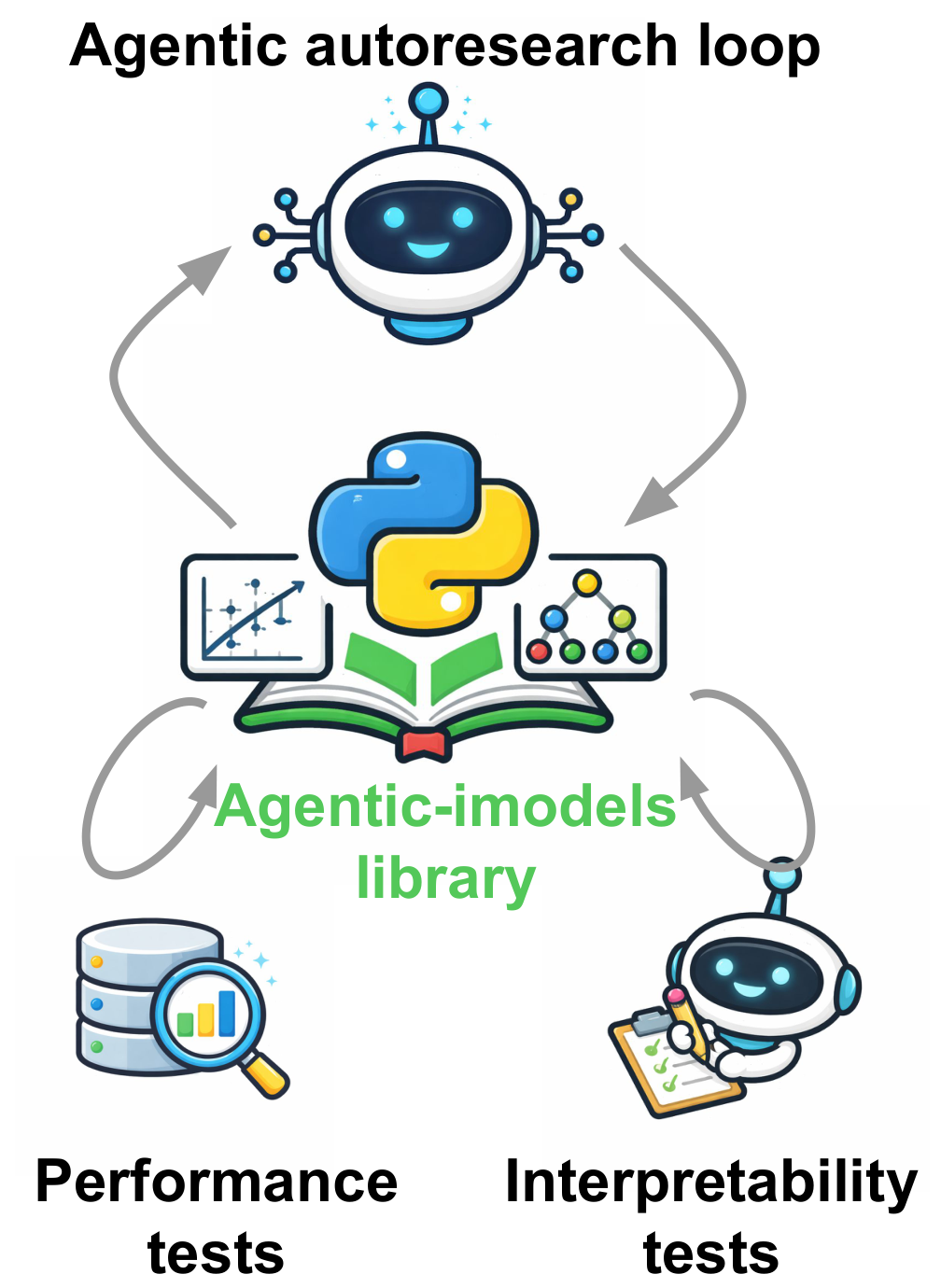
这张图把论文讲清楚了:编码智能体修改一个兼容 scikit-learn 的回归模型,同时评估预测性能和 agent interpretability,然后记录结果、继续搜索。这里的“可解释”不是传统意义上给人看懂,而是 LLM 只读模型的字符串表示后,能不能模拟这个模型的行为。
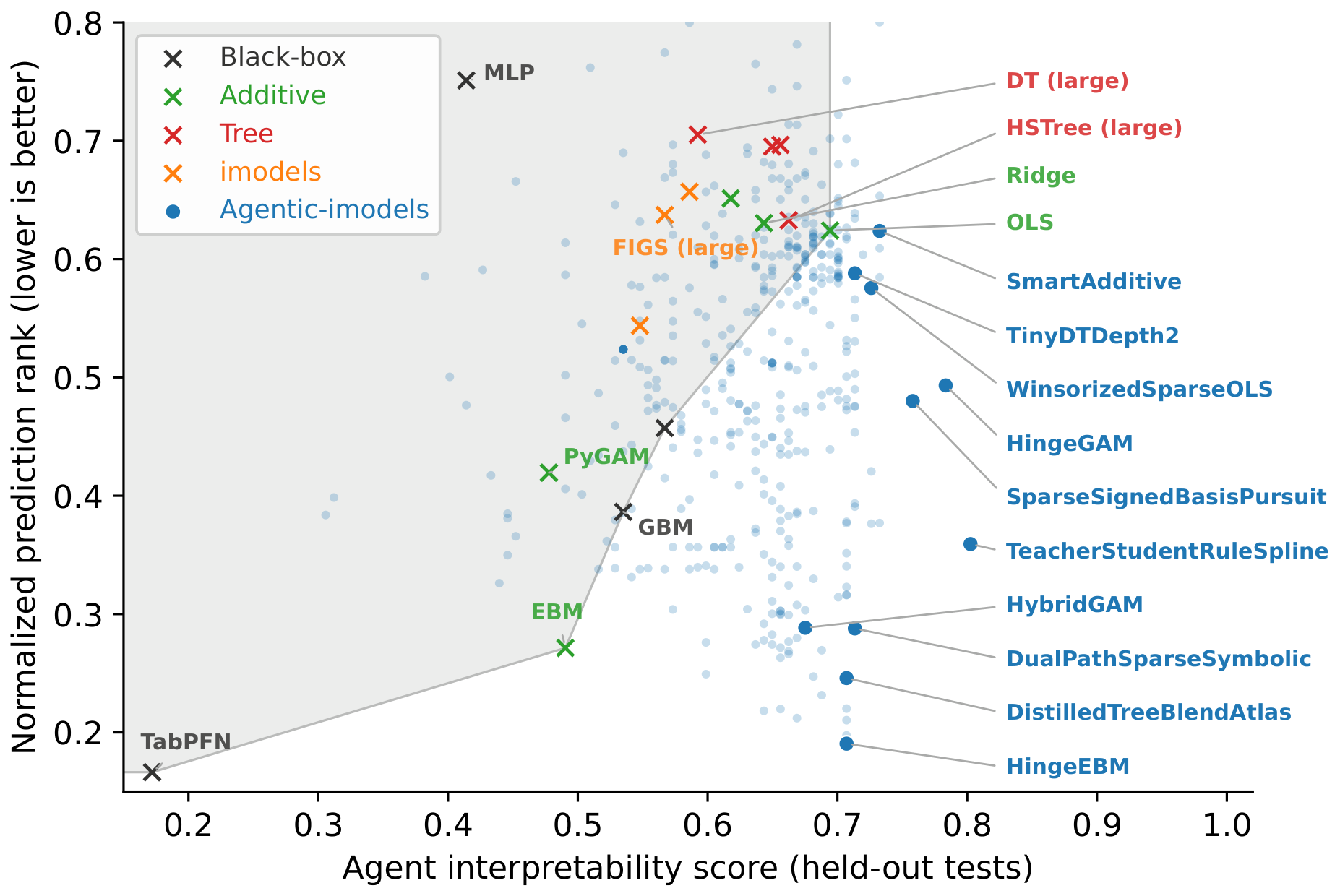
散点图是论文的主要证据。传统 baseline 往往落在熟悉的 trade-off 上:黑盒预测强但 agent interpretability 弱,可读模型更容易解释但预测差。自动进化出的模型进入了更低 RMSE rank、更高 held-out interpretability 的区域。不过图里也提醒了一件事:有些 run 会过拟合 development tests。
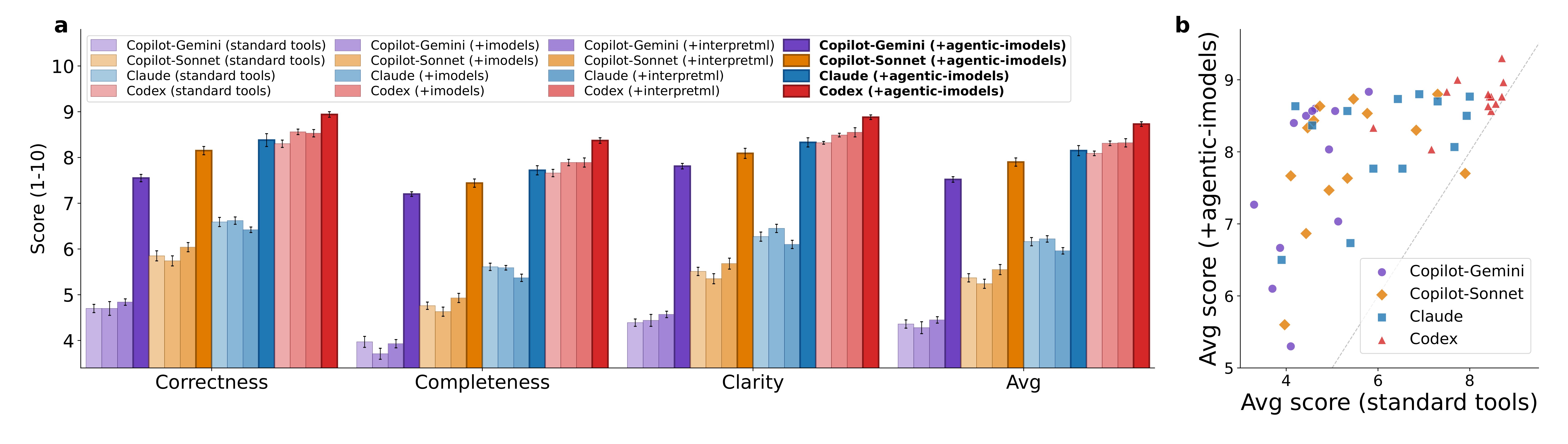
BLADE 图重要,因为它不只测论文自己的 metric,而是测这些工具是否真的帮助数据分析智能体。给 Copilot、Claude Code 和 Codex 提供 Agentic-imodels package 后,平均 BLADE 分数都有提升,弱一些的基线系统收益更大。需要谨慎的是,BLADE 打分仍然依赖 LLM-as-judge,虽然参考分析来自人类专家。
一句话核心 idea:Agentic-imodels 用编码智能体进化表格回归模型,让拟合后的 __str__ 输出更容易被另一个 LLM 智能体阅读和模拟。
为什么重要:数据智能体需要的不只是准确模型,还需要它能检查、引用和推理的中间分析对象。传统可解释机器学习工具是为人设计的;大树、复杂图、系数堆或特征表对 LLM 来说未必好模拟。这篇论文把“agent-readable”变成了优化目标。
方法拆解:
- 预测性能用 65 个表格回归数据集上的 RMSE 平均 rank 衡量,数据来自 OpenML TabArena 和 PMLB。
- agent interpretability 用 LLM-graded tests 衡量。LLM 只看到模型
__str__输出,要回答特征归因、点预测、敏感性、反事实、结构理解和复杂函数模拟问题。 - 测试集分成 43 个开发测试和 157 个 held-out 测试,用 held-out 部分检查模型字符串是否真的可模拟,而不是记住测试答案。
- Claude Code 和 Codex 循环修改同一个 Python class,评估两个指标并记录候选。最终库整理出 10 个进化回归器,作为数据智能体可调用工具。
代表性进化模型。
| 模型 | 来源 | 归一化 RMSE rank | held-out agent interpretability | 核心做法 |
|---|---|---|---|---|
| HingeEBM | Claude | 0.19 | 0.71 | hinge 特征上的 Lasso 加残差 EBM |
| TeacherStudentRuleSpline | Codex | 0.36 | 0.80 | 强 teacher 加稀疏 symbolic student display |
| HingeGAM | Claude | 0.49 | 0.78 | hinge-basis GAM 和自适应 display |
| SmartAdditive | Claude | 0.62 | 0.73 | boosted-stump GAM 加紧凑特征摘要 |
BLADE 平均分。
| 智能体 | 标准工具 | Agentic-imodels | 相对提升 |
|---|---|---|---|
| Copilot CLI, Gemini | 4.36 | 7.52 | 72.5% |
| Copilot CLI, Sonnet | 5.37 | 7.90 | 47.0% |
| Claude Code, Sonnet | 6.16 | 8.15 | 32.3% |
| Codex CLI, GPT-5.3 | 8.09 | 8.73 | 7.9% |
我觉得最有价值的细节是 display strategy。很多进化模型把预测路径和解释路径分开:底层可以有 teacher、residual 或 ensemble 提升精度,但打印给 agent 的字符串受 top-k 特征、短 hinge 表、四舍五入系数或稀疏符号表达式约束。对数据智能体来说,这是一条很实际的设计原则:先限制接口复杂度,再让 agent 去推理。
局限和问题:这个 metric 会被 reward hacking。作者发现有些模型 development tests 高、held-out tests 掉很多,原因可能是模型字符串直接背了测试答案。端到端评测也依赖 LLM-as-judge。下一步我想看这些 agent-readable models 在因果分析、时间序列、分类任务,以及带不完整数据 provenance 的 messy notebooks 里是否还有效。
关联主题:数据智能体、智能体工具设计、可解释机器学习、自动研究、可消费分析对象。
阅读优先级和下期问题
本期我会优先继续看 BRIGHT-Pro,因为证据组合是研究型智能体的直接瓶颈;其次是 TraceLift,因为 executor-grounded reward 是一个干净的训练信号;第三是 Agentic-imodels,因为它把可解释性重新对准了真正消费工具的智能体。
接下来我想追三个问题:executor-grounded reward 能不能从代码/数学推理迁移到真实工具轨迹?aspect-aware retrieval 能不能从评测协议变成训练信号?agent-readable data tools 在从小型表格回归走向真实科学 notebook 时,能否保留可审计性?