Skills, Retrieval, and Memory for Agent Workflows
Published:
TL;DR: this round is about agent-facing state. SkillOS learns how to curate reusable skills from experience. SIRA compresses retrieval into one corpus-discriminative lexical action. HaM-World gives planning a structured latent with memory and geometry so rollouts do not fall apart as quickly.
What I Am Watching This Round
I wanted to avoid another issue that simply says “agents need better evidence surfaces.” These three papers are more concrete than that. One works at the skill layer, one at the retrieval layer, and one at the world-model layer. All three try to make the intermediate object itself something the next module can actually use.
I screened the newest May 7-8 window across arXiv, source packages, and community leads. The broader shortlist included SkillOS, SIRA, HaM-World, OpenSearch-VL, ProgramBench, ARIS, A2TGPO, Workspace-Bench, TabEmbed, and a few mechanism papers. I kept these three because they are fresh, open, and readable end to end, and because each one gives a different answer to the same question: what should the agent keep as state?
Paper Notes
SkillOS: Learning Skill Curation for Self-Evolving Agents
Authors: Siru Ouyang, Jun Yan, Yanfei Chen, Rujun Han, Zifeng Wang, Bhavana Dalvi Mishra, Rui Meng, Chun-Liang Li, Yizhu Jiao, Kaiwen Zha, Maohao Shen, Vishy Tirumalashetty, George Lee, Jiawei Han, Tomas Pfister, Chen-Yu Lee.
Institutions: Google Cloud AI Research; University of Illinois Urbana-Champaign; Massachusetts Institute of Technology.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | PDF
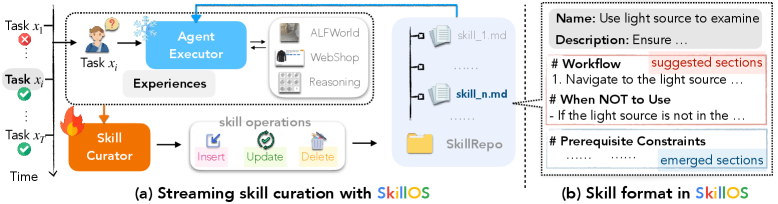
This is the paper’s basic interface. A frozen executor retrieves skills from a SkillRepo and acts, while a trainable curator updates the repo from experience. The point is not to make the executor smarter. It is to make the reusable skill memory better written, better organized, and more useful to the next task.
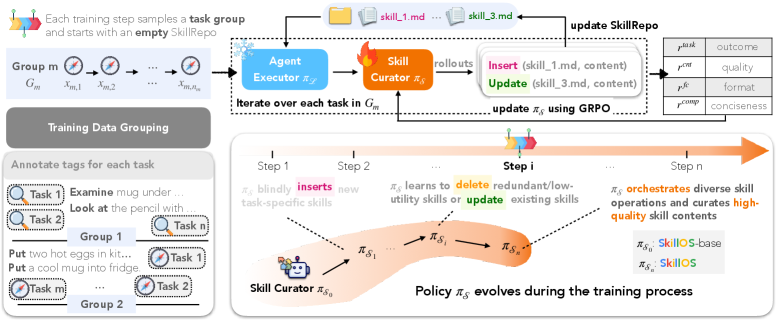
The training pipeline makes the curation problem look like what it is: a delayed-credit problem. SkillOS groups related tasks, starts from an empty repo, and trains the curator with composite rewards that tie later executor outcomes back to earlier curation choices. I like this figure because it makes the memory loop explicit instead of pretending that skill updates are just another prompt edit.
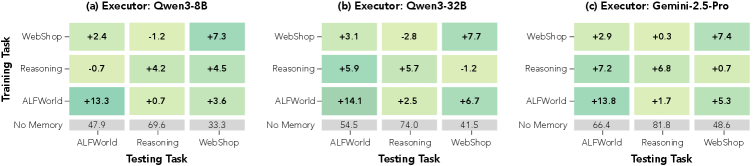
This figure matters because a skill curator that only works with one executor is not very interesting. The paper shows cross-backbone transfer across Qwen3-8B, Qwen3-32B, and Gemini-2.5-Pro. The caveat is simple: the gains are real, but the executor is still frozen, so this is a curation result more than a full co-adaptation result.
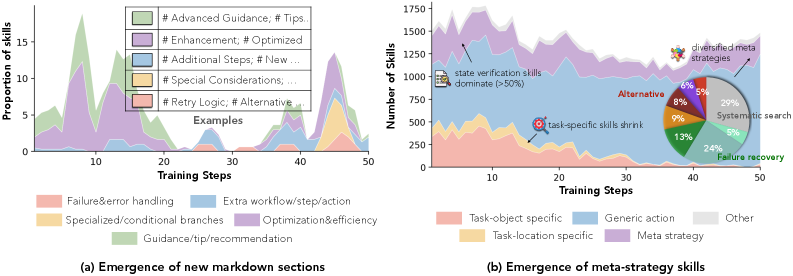
The evolution plot is the qualitative piece I would not skip. The curated skills become more specific and more structured over training, rather than staying as generic snippets. I still treat this as supporting evidence, not proof of semantic improvement, because the judge and the repo format both shape what “better” looks like.
Quick idea: SkillOS trains an agent to write and revise its own reusable skills, so experience becomes a SkillRepo instead of a pile of memories.
Why it matters: a lot of agent systems already have a skill or prompt library, but it is usually hand-built or patched by heuristics. That breaks down once tasks arrive as a stream and the system has to decide what to keep, what to rewrite, and what to delete. SkillOS turns that curation step into a learnable policy.
Method walkthrough:
- Pair a frozen agent executor with a trainable skill curator. The executor retrieves Markdown skills from the repo and uses them to act.
- Build training groups from related task streams so earlier trajectories update the SkillRepo and later tasks test whether those edits helped.
- Train the curator with a composite reward that blends task outcome, valid function calls, content quality, and a compression-style pressure on the produced skill set.
- Keep the skill format simple: a single Markdown file with front matter and body. That keeps the action space tractable, but it also means the paper is testing curation, not full executable skill packaging.
Evidence:
| Setting | Baseline avg SR / steps | SkillOS avg SR / steps |
|---|---|---|
| ALFWorld, Qwen3-8B executor | 47.9 / 21.1 | 61.2 / 18.9 |
| ALFWorld, Qwen3-32B executor | 54.5 / 20.3 | 73.1 / 15.5 |
| Setting | Baseline WebShop score / SR / steps | SkillOS WebShop score / SR / steps | Baseline avg acc | SkillOS avg acc |
|---|---|---|---|---|
| Qwen3-8B executor | 38.6 / 13.6 / 20.1 | 40.6 / 16.5 / 19.4 | 68.9 | 73.8 |
| Ablation | Avg SR | Steps |
|---|---|---|
| Full SkillOS-GRPO | 61.2 | 18.9 |
| w/o content quality reward | 58.6 | 20.1 |
| w/o compression reward | 60.0 | 19.3 |
| w/o grouped tasks | 57.3 | 20.6 |
These tables support a narrow but useful claim: the gains are not just from adding more context. Grouping related tasks and rewarding higher-quality curated content both matter. The paper also says the same curator transfers across executor backbones, which is the part that makes it look like a real curation policy rather than a one-off prompt patch.
Why I care: this paper feels like a practical answer to a thing I keep seeing in agent stacks. A skill library is only useful if the system can revise it from experience without a human reorganizing everything by hand.
Limitations/questions: the repo format is still a single Markdown file, so executable procedures and hierarchical skill composition are flattened away. Retrieval is still BM25-style. The frozen-executor setup is clean for analysis, but it also means the paper is not yet testing joint adaptation of curator and executor.
Connection to tracked themes: agentic training, self-evolving agents, reusable skills, experience-driven memory.
Superintelligent Retrieval Agent: The Next Frontier of Information Retrieval
Authors: Zeyu Yang, Qi Ma, Jason Chen, Anshumali Shrivastava.
Institutions: Meta Superintelligence Labs; Rice University.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | PDF
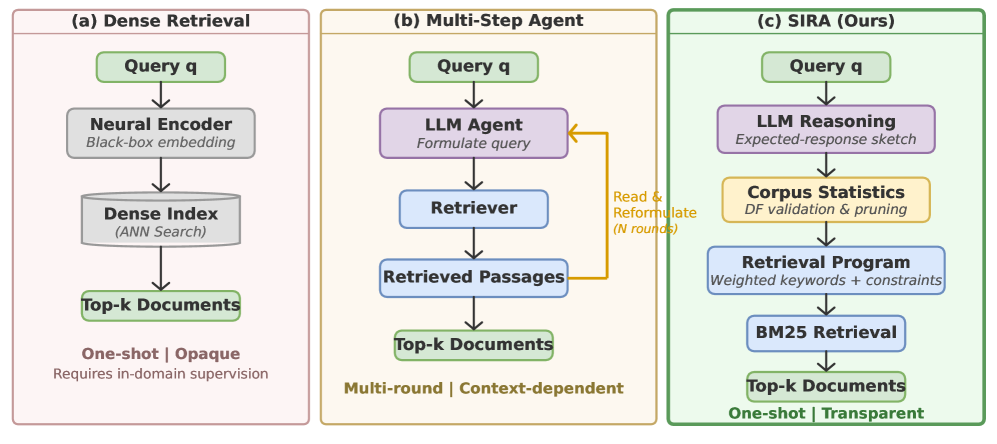
This figure explains why the paper exists. Dense retrieval is one-shot and opaque. Multi-step agent retrieval is flexible but expensive and context-hungry. SIRA tries to get the best part of both: one corpus-aware retrieval action that is still interpretable and still grounded in lexical statistics.
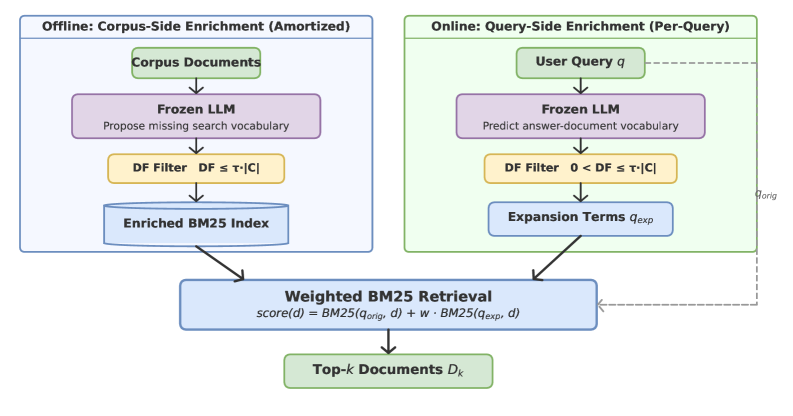
The pipeline is simple on purpose. The corpus gets enriched offline with missing vocabulary, the query gets expanded online with likely evidence terms, and a document-frequency filter removes junk before everything is merged into one weighted BM25 call. That is a strong design choice because it treats retrieval as a controllable action, not a black-box conversation loop.
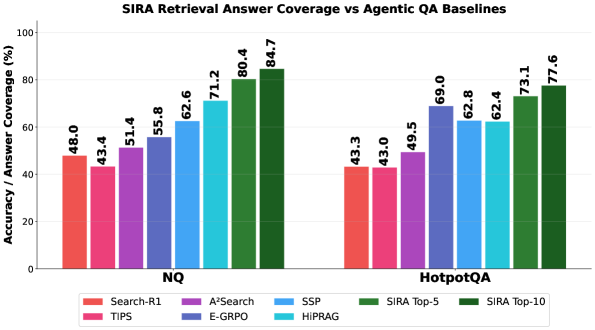
This is the downstream check that matters. SIRA is not just a better retriever by static metrics; it also improves answer coverage when plugged into QA-style agent systems. The caveat is that answer coverage is still an indirect measure, so I would not treat it as proof that every retrieved passage is equally good.
Quick idea: SIRA uses an LLM to surface discriminative retrieval terms, then lets BM25 do the actual ranking in one shot.
Why it matters: most agentic search systems still act like novices. They query, inspect snippets, reformulate, and repeat. That can work, but it burns latency and often repeats the same topical cluster. SIRA argues that the real bottleneck is not the number of search rounds. It is whether the agent can form an expert retrieval action that separates evidence from confusers.
Method walkthrough:
- Use an LLM to enrich each document offline with missing search vocabulary.
- Use the same kind of semantic prior on the query side to predict useful evidence terms.
- Filter candidate terms with document-frequency checks so the expansion stays index-visible and nontrivial.
- Combine the original query and the validated terms into a single weighted BM25 retrieval step.
- Evaluate both on BEIR-style retrieval and on downstream QA coverage inside agentic search loops.
Evidence:
| Model | Recall@10 avg | NDCG@10 avg |
|---|---|---|
| BM25 | 0.5302 | 0.4247 |
| SPLADE | 0.6253 | 0.5223 |
| E5 | 0.6478 | 0.5434 |
| Search-R1 (E5) | 0.6161 | 0.5216 |
| SIRA | 0.6908 | 0.5723 |
SIRA is the best average performer in this table, and the gap is not tiny. The paper also reports that it reaches the best Recall@10 on eight of ten BEIR datasets. What I find more interesting than the average is the shape of the result: BM25 remains a strong substrate when the LLM helps it choose the right vocabulary.
Why I care: this is a cleaner answer than “just add more search steps.” It suggests that search agents should learn how to say the right words to the index before they learn how to spin longer search chains.
Limitations/questions: the method assumes the frozen LLM has enough prior knowledge to propose useful enrichment terms. The paper itself says that corpora far outside pretraining coverage may need extra adaptation or fine-tuning. I would also want to see how this behaves under messy enterprise indexes, where the vocabulary is less stable than BEIR.
Connection to tracked themes: agentic search, document intelligence, retrieval evaluation, evidence portfolios.
HaM-World: Soft-Hamiltonian World Models with Selective Memory for Planning
Authors: Haoyun Tang, Haodong Cui, Keyao Xu, Kun Wang, Zhandong Mei.
Institutions: Xi’an Jiaotong University; Huazhong University of Science and Technology; Nankai University; Nanyang Technological University.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | PDF | code
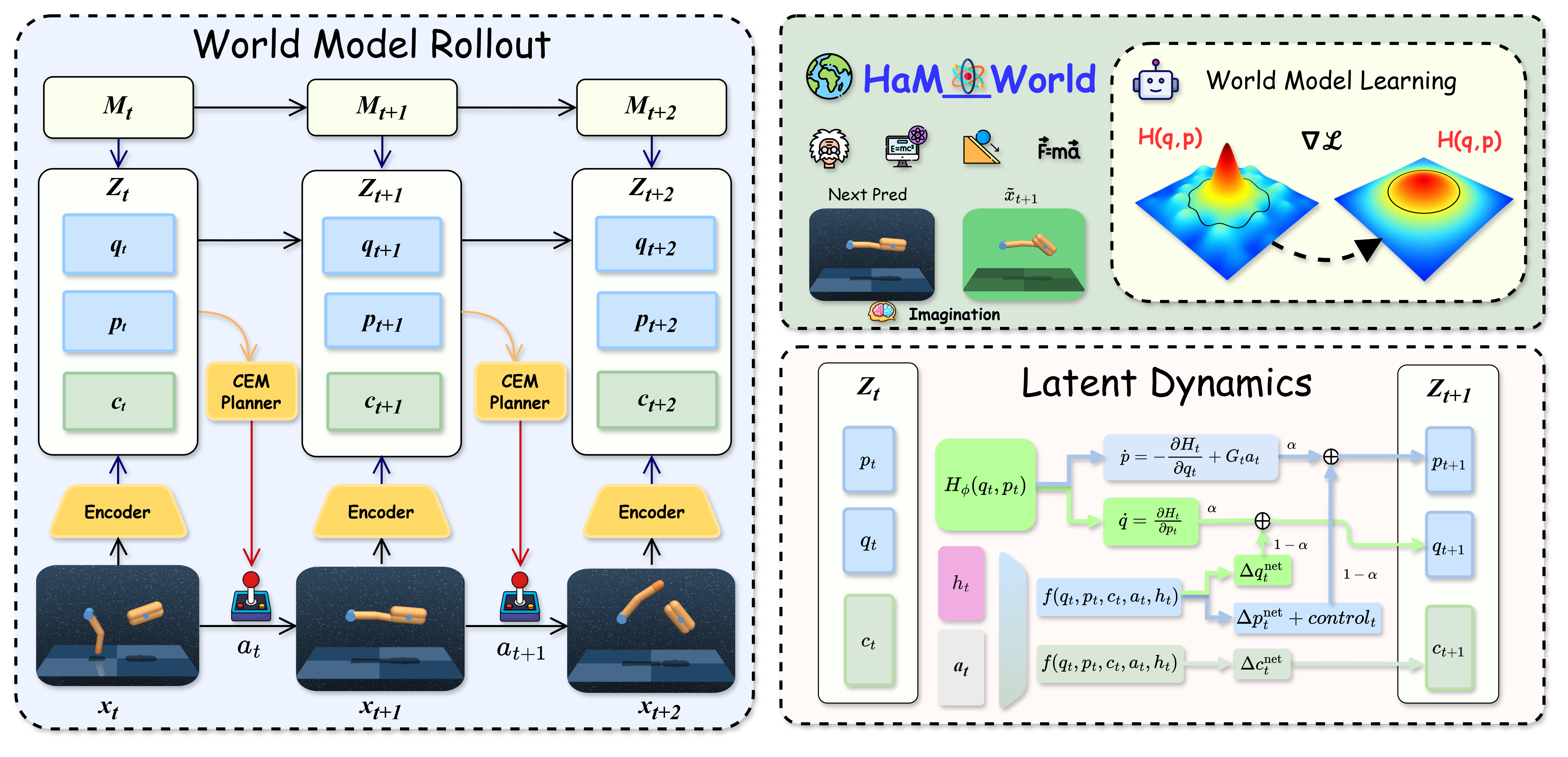
The architecture is the paper’s real statement. Observations are encoded into a structured latent split into q, p, and c, with Mamba-style selective memory feeding the same latent dynamics. The planner then uses that shared latent for prediction, reward/value heads, imagined rollouts, and CEM search. This is a much cleaner world-model interface than just saying “we used a latent.”
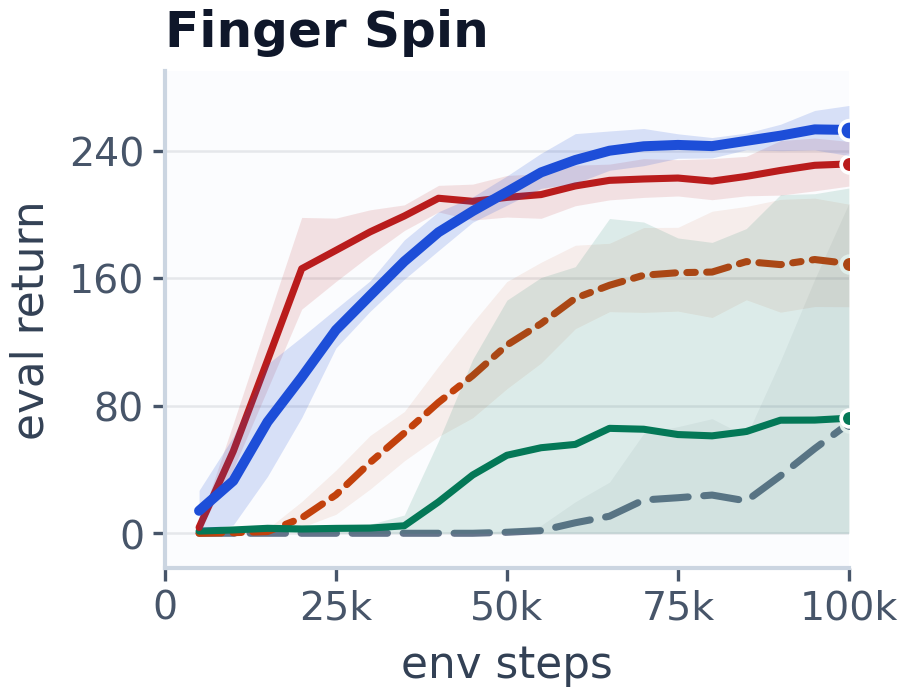
This curve is one of the main control results. HaM-World learns faster and ends up with better return on the task than the baselines, which matters because the paper is really about rollout stability under planning, not just about fitting one-step dynamics. I still read this as a performance plot plus a mechanism check, not as proof that the latent is truly Hamiltonian.
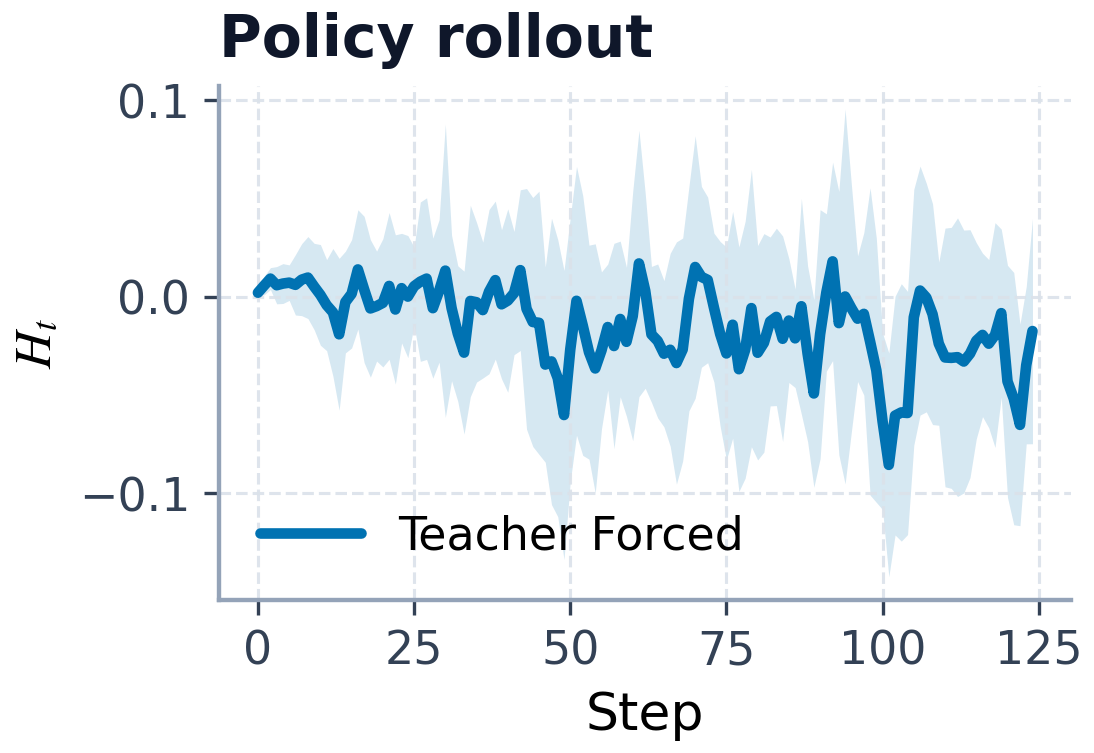
The energy plot is the mechanism evidence I would point to first. The paper uses it to show that action-free energy drift stays bounded and that policy rollouts produce structured energy variation rather than wild collapse. That supports the Soft-Hamiltonian story, but the paper is careful not to claim global Hamiltonian correctness.
Quick idea: HaM-World splits world-model state into geometry, memory, and context so imagined rollouts stay usable for planning over longer horizons.
Why it matters: world models often look fine at short horizons and then drift when planning gets longer or dynamics shift. If the planner-facing latent is unstable, everything downstream inherits that instability. HaM-World attacks the problem by giving the latent a shape: q/p for structured dynamics, c for nonconservative context, and selective memory for history.
Method walkthrough:
- Encode observations into a latent state with a q/p/c split and a Mamba selective memory block.
- Evolve q/p with a soft-Hamiltonian vector field plus residual and control terms, while c captures semantic and dissipative factors.
- Train with a stack of losses: representation alignment, one-step dynamics, multi-step rollout consistency, reward/value heads, policy prior, Hamiltonian alignment, energy regularization, and sparsity terms.
- Use the same latent for reward prediction, value prediction, imagined rollouts, and CEM planning.
Evidence:
| Method | Avg AUC | Finger return | Reacher return | Cheetah return | Cartpole return |
|---|---|---|---|---|---|
| DreamerV3 | 58.6 | 72.3 | 18.4 | 216.4 | 55.8 |
| TD-MPC2 | 107.7 | 232.2 | 105.1 | 155.7 | 15.0 |
| HaM-World | 117.9 | 254.0 | 150.6 | 184.4 | 58.9 |
| Variant | Cheetah return | Finger return | Reacher OOD mass 0.7 | Reacher OOD damp 2.0 |
|---|---|---|---|---|
| Full HaM-World | 184.4 | 254.0 | 159.7 | 139.9 |
| w/o geometric structure | 169.8 | 247.7 | 154.4 | 131.9 |
| Memory = none | 59.2 | 34.0 | 103.6 | 115.4 |
| Memory = GRU | 121.1 | 235.6 | 157.6 | 138.4 |
The first table says HaM-World is the best average control model in this comparison. The second table is the one I trust more for the mechanism story: removing memory hurts a lot, and removing the geometric bias hurts too, but less. That tells me the paper is not just selling a fancy latent split. The memory block is doing real work, and the geometry prior is not decorative.
Why I care: this is the kind of world model I want to believe in for planning. It does not just compress state; it tries to keep the state usable under long rollouts, shifts, and action conditioning.
Limitations/questions: the paper uses state observations and four DeepMind Control Suite tasks, so the jump to pixels, richer morphologies, and contact-heavy settings is still open. The diagnostics support the learned interface, but they do not prove that the dynamics are globally Hamiltonian. I would also want to see how the same design behaves once the environment is less smooth and the planner has more ways to fail.
Connection to tracked themes: world models, structured latents, planning stability, selective memory.
Reading Priority and Next Questions
My reading priority from this round is SIRA first, because retrieval is still the bottleneck I see most often in agent systems. Then SkillOS, because it turns reuse into a trainable policy instead of a manual skill dump. Then HaM-World, because its memory-plus-geometry split is the most likely to transfer beyond a toy benchmark.
The next questions I want to keep in view are simple. Can skill curation survive richer skill formats? Can retrieval-term expansion be learned directly instead of hand-designed? And can structured world-model latents hold up once the environment is noisier than DMC?