技能、检索与记忆化世界模型
Published:
TL;DR:本期看的是智能体工作流里的“可操作状态”。SkillOS 让智能体从经验里学会维护技能库;SIRA 把多轮搜索压缩成一次有语料意识的词法检索动作;HaM-World 用选择性记忆和几何结构稳定规划用的世界模型潜变量。
本期我在看什么
我这次刻意避开“智能体需要更好证据 surface”这个已经讲了很多次的表述。这三篇更具体:一篇在技能层,一篇在检索层,一篇在世界模型层。它们关心的不是把日志写得更漂亮,而是让中间状态本身能被下一个模块使用。
我筛了 2026 年 5 月 7 到 8 日的 arXiv、开放全文、社区热度和中文媒体线索。候选里有 SkillOS、SIRA、HaM-World、OpenSearch-VL、ProgramBench、ARIS、A2TGPO、Workspace-Bench、TabEmbed,以及一些大模型机理论文。最后只选 3 篇,因为它们足够新、开放全文可读、图表清楚,并且能围绕同一个问题展开:智能体到底应该把什么东西保留下来当作状态?
论文细读笔记
SkillOS:学习为自进化智能体维护技能库
作者:Siru Ouyang, Jun Yan, Yanfei Chen, Rujun Han, Zifeng Wang, Bhavana Dalvi Mishra, Rui Meng, Chun-Liang Li, Yizhu Jiao, Kaiwen Zha, Maohao Shen, Vishy Tirumalashetty, George Lee, Jiawei Han, Tomas Pfister, Chen-Yu Lee。
机构:Google Cloud AI Research;University of Illinois Urbana-Champaign;Massachusetts Institute of Technology。
日期/会议:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | PDF
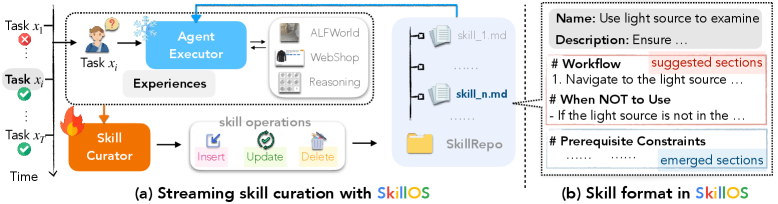
这张图给出了 SkillOS 的基本接口:冻结的执行器从 SkillRepo 检索技能并执行任务,可训练的 curator 根据经验插入、更新或删除技能。重点不是让 executor 自身变强,而是让可复用技能记忆写得更好、组织得更好、对下一道任务更有帮助。
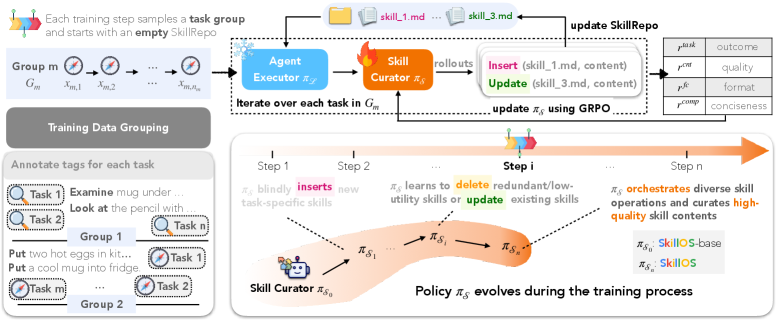
训练管线把问题说得很清楚:技能维护是一个延迟信用分配问题。SkillOS 把相关任务组成 group,从空 SkillRepo 开始,让前面的任务轨迹改写技能库,再用后面的相关任务检验这些修改有没有用。这比“把成功经验存进 memory”更具体,因为它把存什么、怎么改、什么时候删都变成了可训练动作。
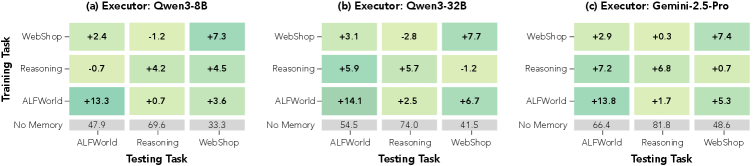
这张图用于回答一个关键问题:curator 是否只适配某一个 executor?论文展示了 Qwen3-8B、Qwen3-32B 和 Gemini-2.5-Pro 执行器下的迁移结果。需要谨慎的是,executor 始终冻结,所以这更像是技能维护策略的泛化,而不是 curator 和 executor 的完整共同适配。
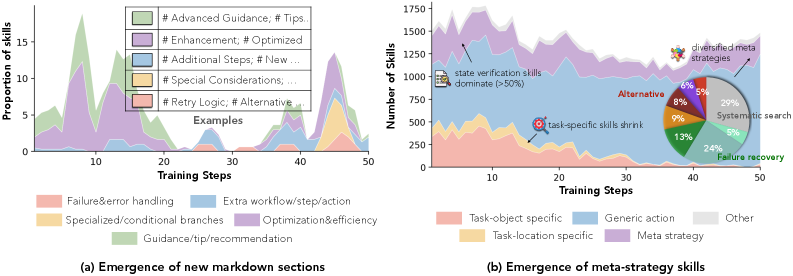
这张演化图值得放进来,因为它展示了技能库在 RL 训练中从泛泛提示变成更具体、更结构化的 Markdown 技能。我会把它看成支持性证据,而不是语义质量的最终证明,因为 judge、检索方式和技能格式都会影响“更好”的定义。
一句话核心 idea:SkillOS 训练一个智能体去维护自己的可复用技能库,让过去经验变成 SkillRepo,而不是变成一堆难以复用的记忆片段。
为什么重要:很多 agent 系统都有技能库、prompt 库或 memory,但通常依赖人工整理或启发式追加。任务一旦以 stream 方式到来,系统就必须判断哪些经验值得保留、哪些技能需要合并、哪些旧技能会误导后续任务。SkillOS 把这个 curation step 变成可学习策略。
方法拆解:
- 系统由冻结 executor 和可训练 skill curator 组成。executor 根据当前任务从 SkillRepo 里检索 Markdown 技能,然后执行动作。
- 训练时构造相关任务 group,让前序任务的轨迹触发技能更新,再用后续任务表现衡量这些更新是否真的有用。
- curator 的奖励由多部分组成:任务结果、函数调用是否有效、技能内容质量,以及对技能压缩性的约束。
- 技能格式被简化成单个 Markdown 文件,包含 front matter 和正文。这让 curator 动作空间可控,但也意味着论文暂时没有测试多文件、可执行脚本、层级技能组合等更复杂的技能形态。
关键证据:
| 设置 | 基线 avg SR / steps | SkillOS avg SR / steps |
|---|---|---|
| ALFWorld,Qwen3-8B executor | 47.9 / 21.1 | 61.2 / 18.9 |
| ALFWorld,Qwen3-32B executor | 54.5 / 20.3 | 73.1 / 15.5 |
| 设置 | 基线 WebShop score / SR / steps | SkillOS WebShop score / SR / steps | 基线 avg acc | SkillOS avg acc |
|---|---|---|---|---|
| Qwen3-8B executor | 38.6 / 13.6 / 20.1 | 40.6 / 16.5 / 19.4 | 68.9 | 73.8 |
| 消融 | Avg SR | Steps |
|---|---|---|
| 完整 SkillOS-GRPO | 61.2 | 18.9 |
| 去掉内容质量奖励 | 58.6 | 20.1 |
| 去掉压缩奖励 | 60.0 | 19.3 |
| 去掉任务分组 | 57.3 | 20.6 |
这些表支持的是一个窄但有用的结论:性能提升不是单纯因为多塞了上下文。相关任务分组和内容质量奖励都在发挥作用。论文还显示同一个 curator 可以迁移到不同执行器,这让它更像一个真正的技能维护策略,而不是某个 prompt 的一次性补丁。
我的判断:我会优先看这篇的原因是,技能库维护是很多真实 agent stack 迟早会遇到的问题。系统如果不能自己整理经验,长期运行后 memory 很快会变成垃圾桶。
局限和问题:技能仍然被压平成单个 Markdown 文件,可执行过程和层级组合还没有进入实验。技能检索主要还是 BM25 风格。冻结 executor 有利于归因,但还没有回答 curator 和 executor 是否应该共同训练。
关联主题:agentic training、自进化智能体、技能库、经验驱动记忆。
SIRA:把检索动作变成一次可解释的语料级决策
作者:Zeyu Yang, Qi Ma, Jason Chen, Anshumali Shrivastava。
机构:Meta Superintelligence Labs;Rice University。
日期/会议:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | PDF
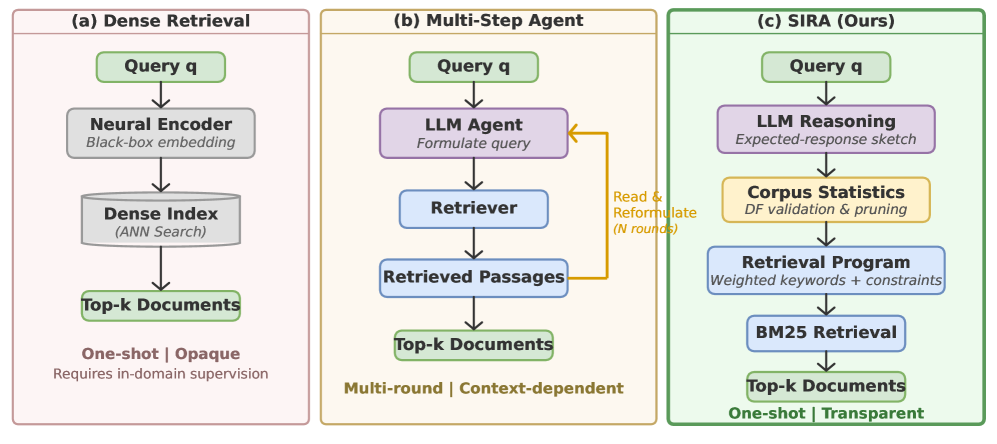
这张图解释了论文为什么要做 SIRA。dense retrieval 是一次性且不透明的;多轮 agent retrieval 灵活,但慢、耗上下文,也容易重复探索。SIRA 想保留一次检索的效率,同时把检索动作做得更像专家:有语料意识、可解释、能利用词法统计。
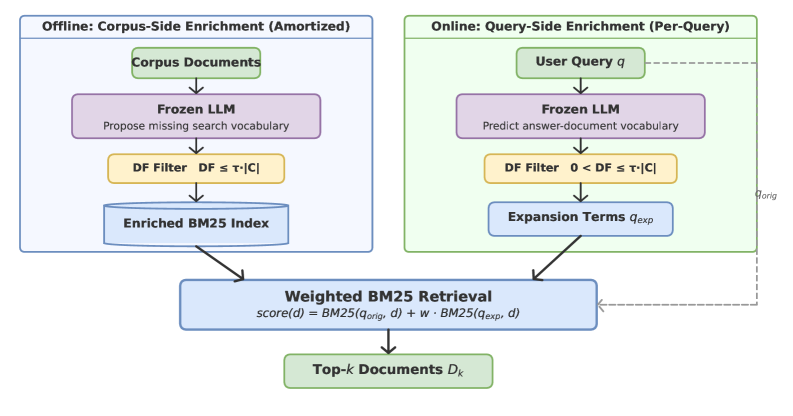
管线故意很朴素。语料侧先离线补充缺失搜索词,查询侧在线预测可能出现在证据里的词,再用 document frequency 过滤掉不存在、太常见或不够区分的词,最后合并成一次加权 BM25 检索。这是一个很有工程感的设计:把 retrieval 当成可控动作,而不是黑盒对话环境。
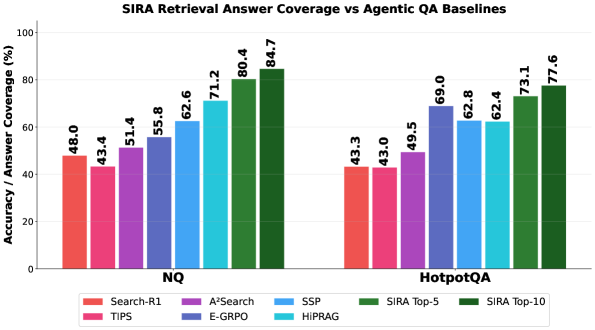
这张图检查静态检索指标之外的下游效果。SIRA 不只是 BEIR 平均分更高,也在 NQ 和 HotpotQA 这样的 QA 设置里提高了 answer coverage。需要谨慎的是,answer coverage 仍是间接指标,它说明证据更容易被取到,但不等于每个 passage 都足以支撑最终回答。
一句话核心 idea:SIRA 让 LLM 负责找出能区分语料中相关证据和干扰项的检索词,再用一次加权 BM25 完成排序。
为什么重要:现在很多 search agent 仍像新手一样工作:先查,读片段,再改写查询,不断循环。这可以提高召回,但代价是 latency、上下文和重复证据。SIRA 的判断是,瓶颈不一定是搜索轮数,而是 agent 能否先形成一个像专家一样的 retrieval action。
方法拆解:
- 语料侧:LLM 离线为每个文档补充用户可能会用、但文档原文没有直接出现的检索词。
- 查询侧:LLM 根据问题预测证据里可能出现、但原始 query 缺失的词。
- 过滤:用 document frequency 检查候选词是否存在、是否过常见、是否有区分度,避免 LLM 生成看似专业但索引里无效的词。
- 检索:把原始 query 和验证后的扩展词合并成一个 weighted BM25 call。
- 评测:同时在 BEIR 检索任务和下游 QA 覆盖率上比较 BM25、SPLADE、E5、Search-R1、GrepRAG、ShellAgent 等方法。
关键证据:
| 模型 | Recall@10 平均 | NDCG@10 平均 |
|---|---|---|
| BM25 | 0.5302 | 0.4247 |
| SPLADE | 0.6253 | 0.5223 |
| E5 | 0.6478 | 0.5434 |
| Search-R1 (E5) | 0.6161 | 0.5216 |
| SIRA | 0.6908 | 0.5723 |
SIRA 在这个表里平均最好,而且差距不是微小浮动。论文还报告它在十个 BEIR 数据集中的八个 Recall@10 最高。对我来说,最有价值的结论不是“BM25 又赢了”,而是 BM25 如果有 LLM 帮它选对语料可见的关键词,仍然可以成为很强的 agent 检索底座。
我的判断:这篇比“再多搜几轮”更有启发。它提醒我,search agent 应该先学会怎么对索引说话,然后再谈复杂的多轮搜索策略。
局限和问题:方法假设冻结 LLM 对 query 和语料有足够先验,能提出可靠扩展词。论文也明确说,如果语料远离预训练分布,可能需要 corpus-side adaptation 或 fine-tuning。我还想看它在企业内部文档、代码仓库、扫描 OCR 文档这类词表更混乱的索引上表现如何。
关联主题:agentic search、文档智能、检索评测、证据组合。
HaM-World:带选择性记忆的 Soft-Hamiltonian 世界模型
作者:Haoyun Tang, Haodong Cui, Keyao Xu, Kun Wang, Zhandong Mei。
机构:Xi’an Jiaotong University;Huazhong University of Science and Technology;Nankai University;Nanyang Technological University。
日期/会议:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | PDF | 代码
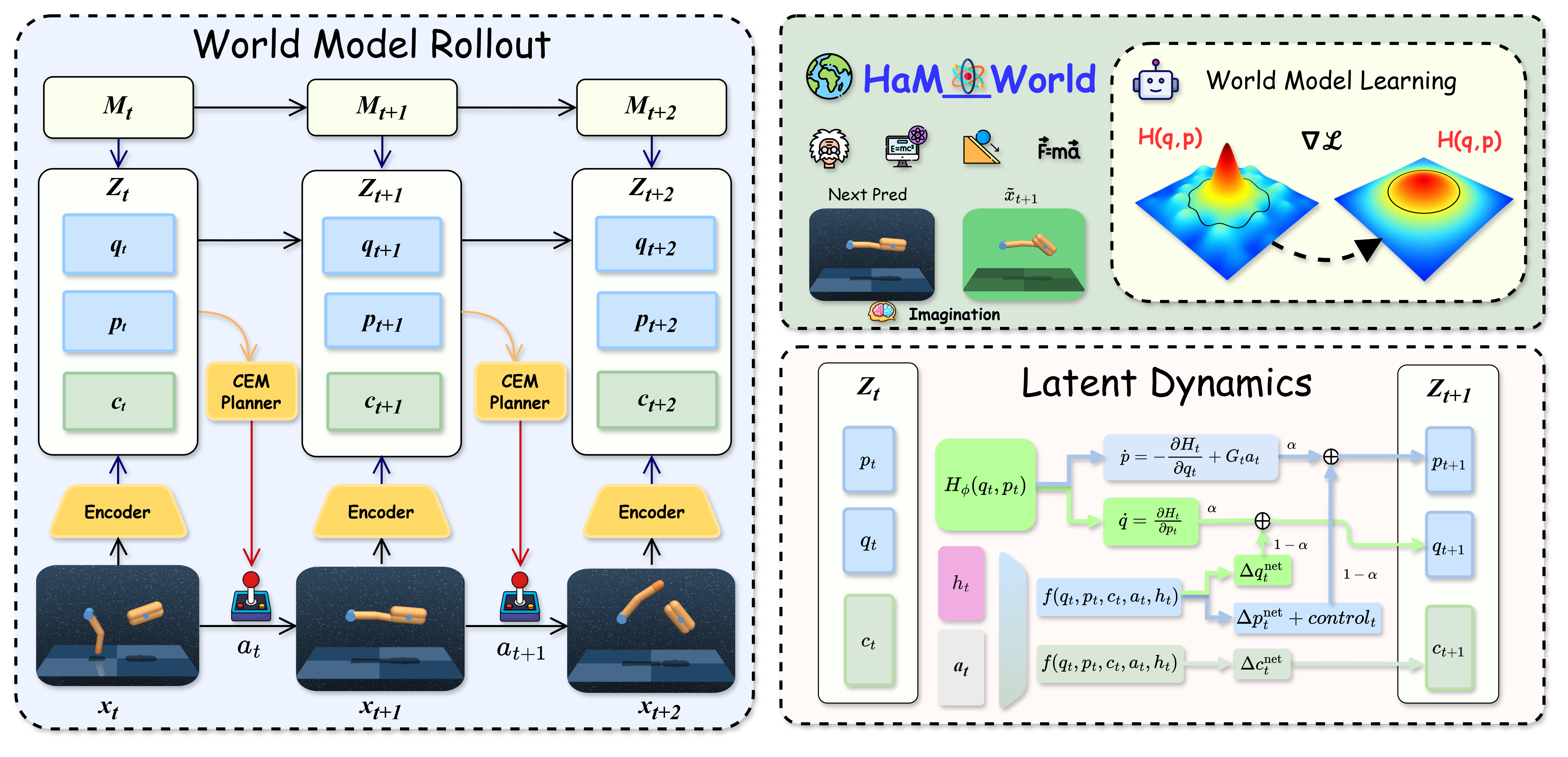
这张架构图是论文最重要的信息。观测被编码成 q、p、c 三部分潜变量,同时 Mamba 风格选择性记忆把历史状态输入到同一套 latent dynamics 中。planner 随后用同一潜变量做 dynamics prediction、reward/value 估计、imagined rollout 和 CEM 搜索。这比“我们用了一个 latent”具体得多。
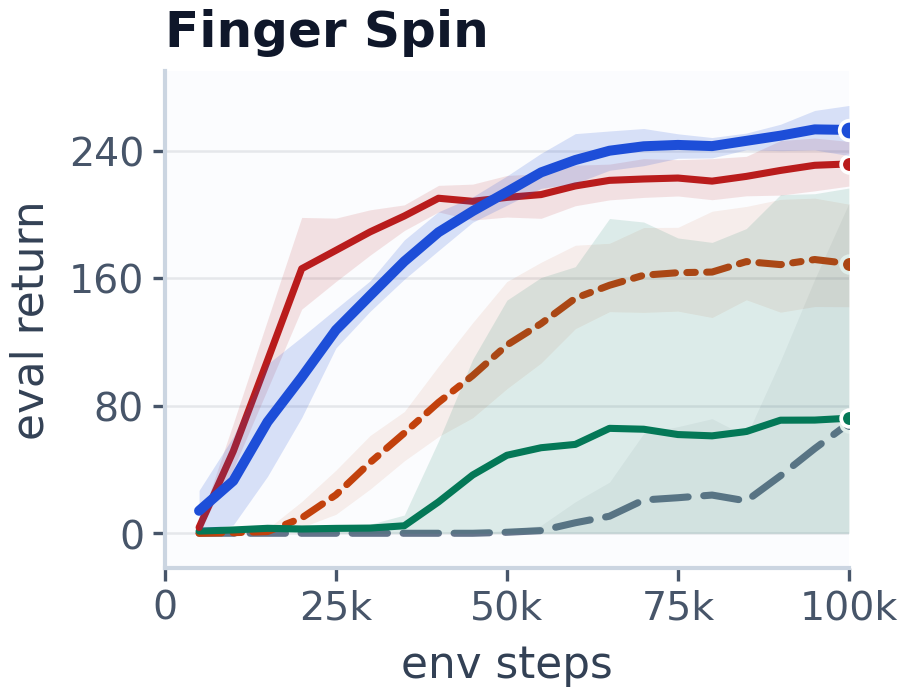
这条曲线展示了控制性能:HaM-World 在该任务上学习更快,最终 return 也更高。它不是单纯一条 leaderboard 曲线,因为论文真正关心的是 rollout stability 对 planning 的影响。我的谨慎点是,曲线只能说明控制和训练表现,不能单独证明潜变量真的具有全局 Hamiltonian 结构。
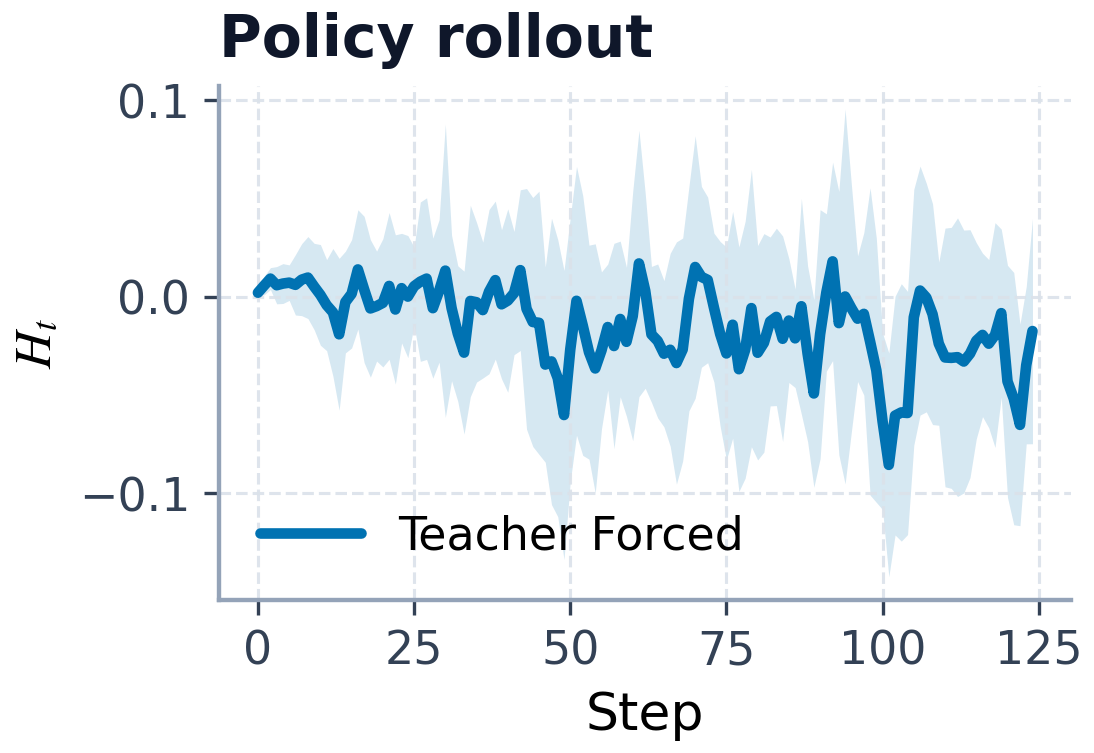
这张 energy 图是机制证据里最值得看的部分。论文用它说明 action-free 情况下能量漂移受控,policy rollout 时能量变化也呈现结构化模式,而不是随 rollout 崩掉。它支持 Soft-Hamiltonian 设计,但作者也没有把它夸成严格物理证明。
一句话核心 idea:HaM-World 把 world-model state 拆成几何结构、上下文和选择性记忆,让 imagined rollouts 在更长 planning horizon 和分布扰动下更可用。
为什么重要:很多 world model 短期预测看起来不错,但一旦用于规划,多步 rollout 很快积累误差。planner-facing latent 如果不稳定,reward/value 估计和 CEM action search 都会被拖垮。HaM-World 的做法是给潜变量一个明确形状:q/p 表达结构化动力学,c 表达非保守上下文,memory 补历史信息。
方法拆解:
- 将观测编码成 q/p/c 潜变量,并接入 Mamba selective memory。
- q/p 通过 soft-Hamiltonian vector field 加残差和控制项演化,c 则承载语义、耗散和非保守因素。
- 训练目标包括 representation alignment、一步 dynamics、多步 rollout consistency、reward/value heads、policy prior、Hamiltonian alignment、energy regularization 和 sparsity 项。
- 规划时,同一个潜变量被用于 reward prediction、value prediction、imagined rollout 和 CEM planner。
关键证据:
| 方法 | Avg AUC | Finger return | Reacher return | Cheetah return | Cartpole return |
|---|---|---|---|---|---|
| DreamerV3 | 58.6 | 72.3 | 18.4 | 216.4 | 55.8 |
| TD-MPC2 | 107.7 | 232.2 | 105.1 | 155.7 | 15.0 |
| HaM-World | 117.9 | 254.0 | 150.6 | 184.4 | 58.9 |
| 变体 | Cheetah return | Finger return | Reacher OOD mass 0.7 | Reacher OOD damp 2.0 |
|---|---|---|---|---|
| 完整 HaM-World | 184.4 | 254.0 | 159.7 | 139.9 |
| 去掉几何结构 | 169.8 | 247.7 | 154.4 | 131.9 |
| 无 memory | 59.2 | 34.0 | 103.6 | 115.4 |
| memory 换成 GRU | 121.1 | 235.6 | 157.6 | 138.4 |
第一张表说明 HaM-World 在这组比较里平均控制表现最好。第二张表更能支撑机制判断:去掉 memory 影响非常大,去掉几何结构也有损失但相对温和。这说明论文不是只在卖一个漂亮的 q/p/c 切分;选择性记忆确实承担了很多稳定 rollout 的工作,几何先验则提供了额外约束。
我的判断:我会继续追这篇,因为它把 world model 的潜变量直接对准 planner 使用,而不是只追求重建或一步预测。对规划系统来说,状态压缩不够,状态还必须能经得住 rollout。
局限和问题:实验使用 state observations 和四个 DeepMind Control Suite 任务,离 pixel input、更复杂形体和接触丰富环境还有距离。诊断支持这个接口设计,但不能证明学到的是全局 Hamiltonian dynamics。下一步我想看它在不那么光滑、失败模式更多的环境里是否仍能稳定。
关联主题:world models、结构化潜变量、规划稳定性、选择性记忆。
阅读优先级和下期问题
本期我会优先继续看 SIRA,因为检索仍然是很多智能体系统最常见的瓶颈;然后是 SkillOS,因为它把技能复用变成了可训练策略,而不是人工维护的技能堆;最后是 HaM-World,因为它的 memory + geometry split 有希望从控制 benchmark 迁移到更一般的规划问题。
接下来我想追三个问题:技能维护能不能处理多文件、可执行和层级化技能?检索词扩展能不能从手工设计变成可学习策略?结构化 world-model latent 在比 DMC 更噪声、更不连续的环境里还能不能稳定?