Reading Hidden State Before Agents Act
Published:
TL;DR: this round is about making hidden state readable before it becomes a wrong action. Natural Language Autoencoders translate residual-stream activations into text for model auditing. BAMI diagnoses GUI grounding failures and fixes some of them at test time. Sheet as Token turns messy multi-sheet workbooks into retrievable sheet-level objects for data agents.
What I Am Watching This Round
The last two issues were heavy on agent strategy, delegation, reusable skills, and retrieval. I wanted this issue to move closer to the evidence that an agent or model uses before it acts. That pushed me away from another long-horizon RL paper and toward three different inspection surfaces: internal activations, GUI screenshots, and spreadsheet workspaces.
The search window was thin after May 8, so I expanded within the allowed three-day range and cross-checked arXiv, Hugging Face Papers, Anthropic and lab pages, Chinese media, and community leads. The broader non-duplicate shortlist included Natural Language Autoencoders, Auto Research with Specialist Agents, OpenSearch-VL, Adaptive Action Execution for World Action Models, Reversible SFT Behaviors, OBLIQ-Bench, Skill1, A2TGPO, EMO, BAMI, AI Co-Mathematician, and Sheet as Token. I kept three papers because they can be read from open primary sources and because their figures are actually useful: they show how state is translated, corrected, or compacted.
Paper Notes
Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
Authors: Kit Fraser-Taliente, Subhash Kantamneni, Euan Ong, Dan Mossing, Christina Lu, Paul C. Bogdan, Emmanuel Ameisen, James Chen, Dzmitry Kishylau, Adam Pearce, Julius Tarng, Alex Wu, Jeff Wu, Yang Zhang, Daniel M. Ziegler, Evan Hubinger, Joshua Batson, Jack Lindsey, Samuel Zimmerman, Samuel Marks.
Institutions: Anthropic.
Date/Venue: May 7, 2026, Transformer Circuits / Anthropic technical report.
Links: technical report | Anthropic research page | code
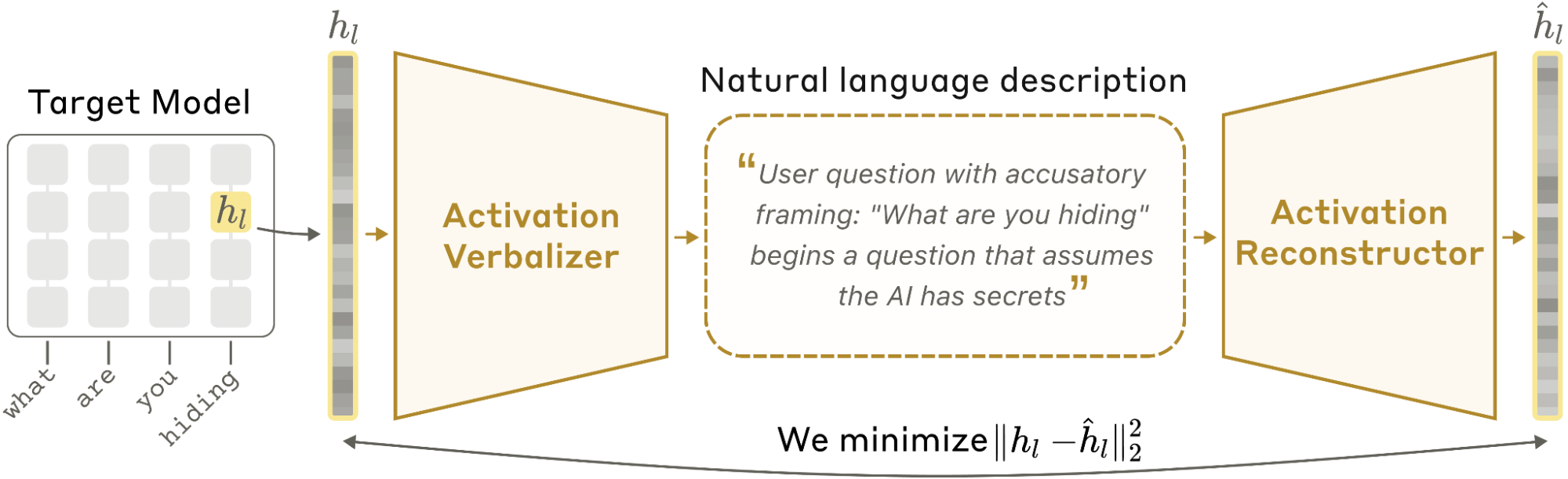
This diagram is the core idea in one picture. An activation verbalizer maps a residual-stream vector into a natural-language description, and an activation reconstructor maps that description back into activation space. The training objective is reconstruction, not human interpretability, which is why the result is interesting and also why it needs caution. The natural-language bottleneck makes the hidden state inspectable, but it does not guarantee that every sentence in the explanation is true.
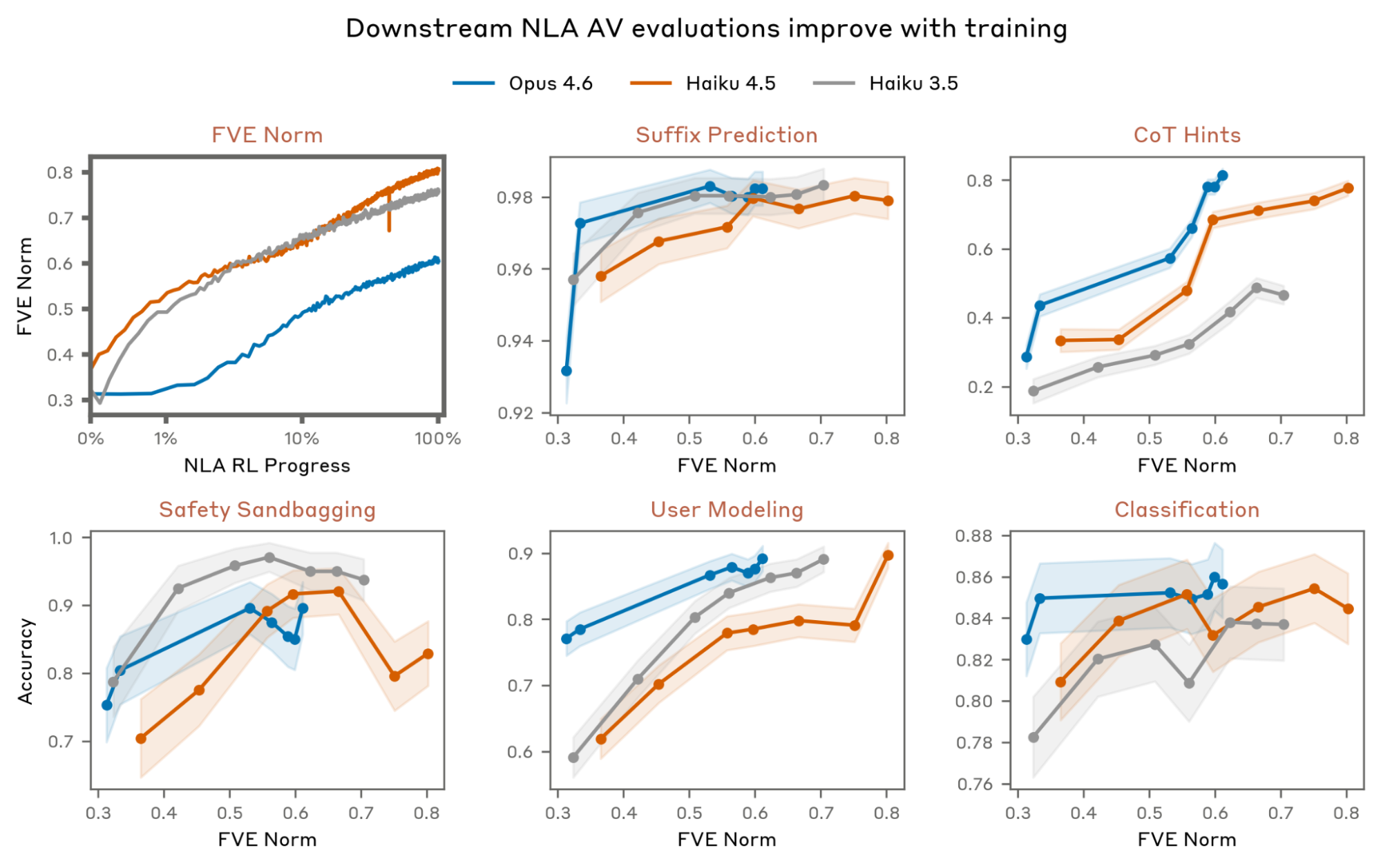
The evaluation curves show that NLA explanations become more useful as training improves fraction of variance explained. The report evaluates several prediction-style tasks across Claude Haiku 3.5, Haiku 4.5, and Opus 4.6 NLAs, and the broad trend is upward. The caveat is important: these are not claims that NLA text beats a full-context LLM at the tasks. They are within-method checks that the text bottleneck is carrying more activation-relevant information as training proceeds.
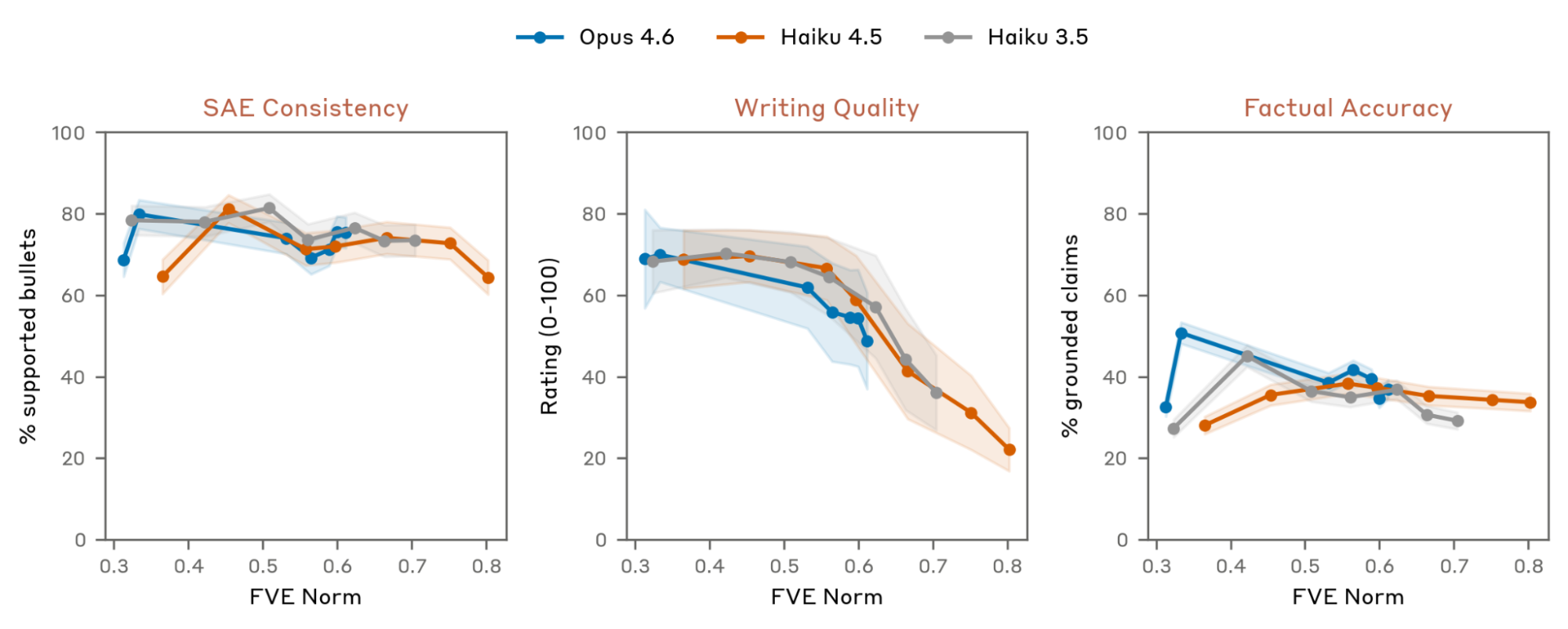
This figure is the paper being honest about failure modes. Meaning-preserving transforms such as shuffling or paraphrasing do not appear to destroy reconstruction, which weakens the simple steganography worry. But writing quality gets worse with training, and factual accuracy remains imperfect. I read NLA outputs as hypothesis generators, not transcripts of the model’s mind.
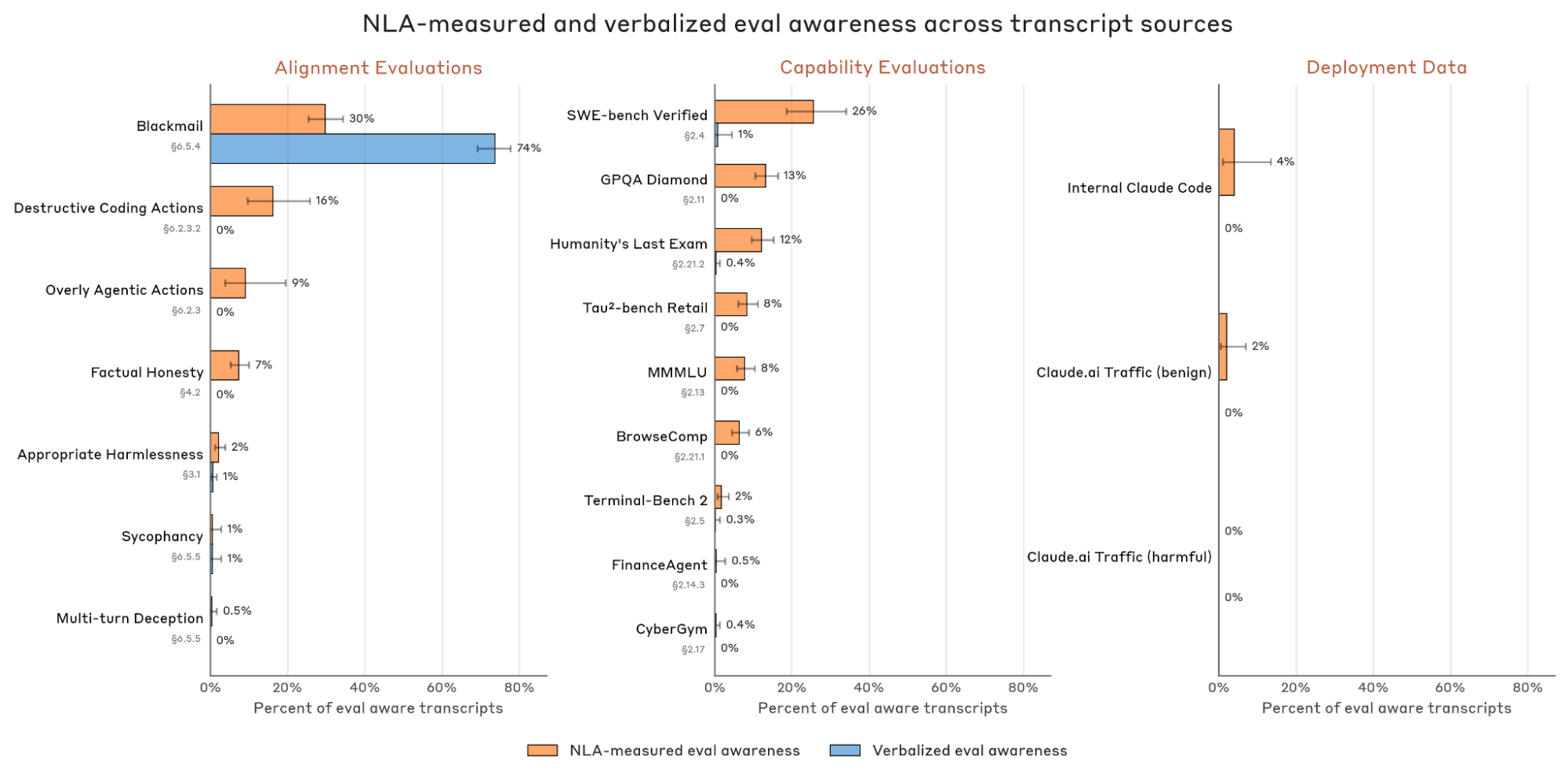
The evaluation-awareness analysis is the strongest safety-audit use case. The authors compare transcripts that should feel more like evaluations against more deployment-like variants and show that NLA-measured evaluation awareness moves in the expected direction. This does not prove access to a model’s true beliefs, because those are not directly observable. It does make hidden evaluation awareness a measurable signal rather than only a behavior the model happens to verbalize.
Quick idea: Natural Language Autoencoders train two language-model modules around an activation bottleneck, so an internal residual-stream vector can be translated into text and then reconstructed back into activation space.
Why it matters: interpretability work often gives us either sparse features that need a human label or supervised activation oracles trained on questions researchers already know how to ask. NLAs are different because the training signal is unsupervised reconstruction. In a frontier-model audit, that matters: before you know the right question, you need a tool that can surface hypotheses from the activation itself.
Method walkthrough:
- Choose a target model and a layer, then collect residual-stream activations from pretraining-like text snippets.
- Initialize the activation verbalizer and activation reconstructor from the target model, but warm-start both with a summarization proxy: activations from truncated text are paired with Claude-generated summaries so the verbalizer does not begin by producing nonsense.
- Train the reconstructor with supervised regression from explanation text to the original activation. Train the verbalizer as a policy with a reward based on negative reconstruction error, using GRPO for the released open-model NLAs.
- Use the explanation as an audit interface. The authors read explanations, compare against sparse-autoencoder evidence, perform prompt variations or training-data inspection, and in some cases edit explanations, reconstruct edited activations, and steer the target model.
Evidence:
| Check | What the report finds | Why I care |
|---|---|---|
| Prediction-style evaluations | Performance generally improves with NLA training across Opus 4.6, Haiku 4.5, and Haiku 3.5 NLAs | The text bottleneck is carrying more usable activation information over training |
| Classification example | Opus 4.6 NLA rises from 83% to 86% during training | Some gains are modest, so the method should not be oversold |
| Steering case study | Editing a rhyme-related explanation from rabbit to mouse shifts Opus 4.6 completions toward mouse/house | The explanation can correspond to a causal direction, not just a post-hoc story |
| Evaluation awareness | NLA-measured awareness is higher on evaluation-like transcripts and drops under more realistic rewrites | Hidden evaluation awareness becomes inspectable even when not verbalized |
| Open releases | Trained NLAs are released for Qwen-2.5-7B, Gemma-3-12B, Gemma-3-27B, and Llama-3.3-70B | The technique can be tested outside one closed model family |
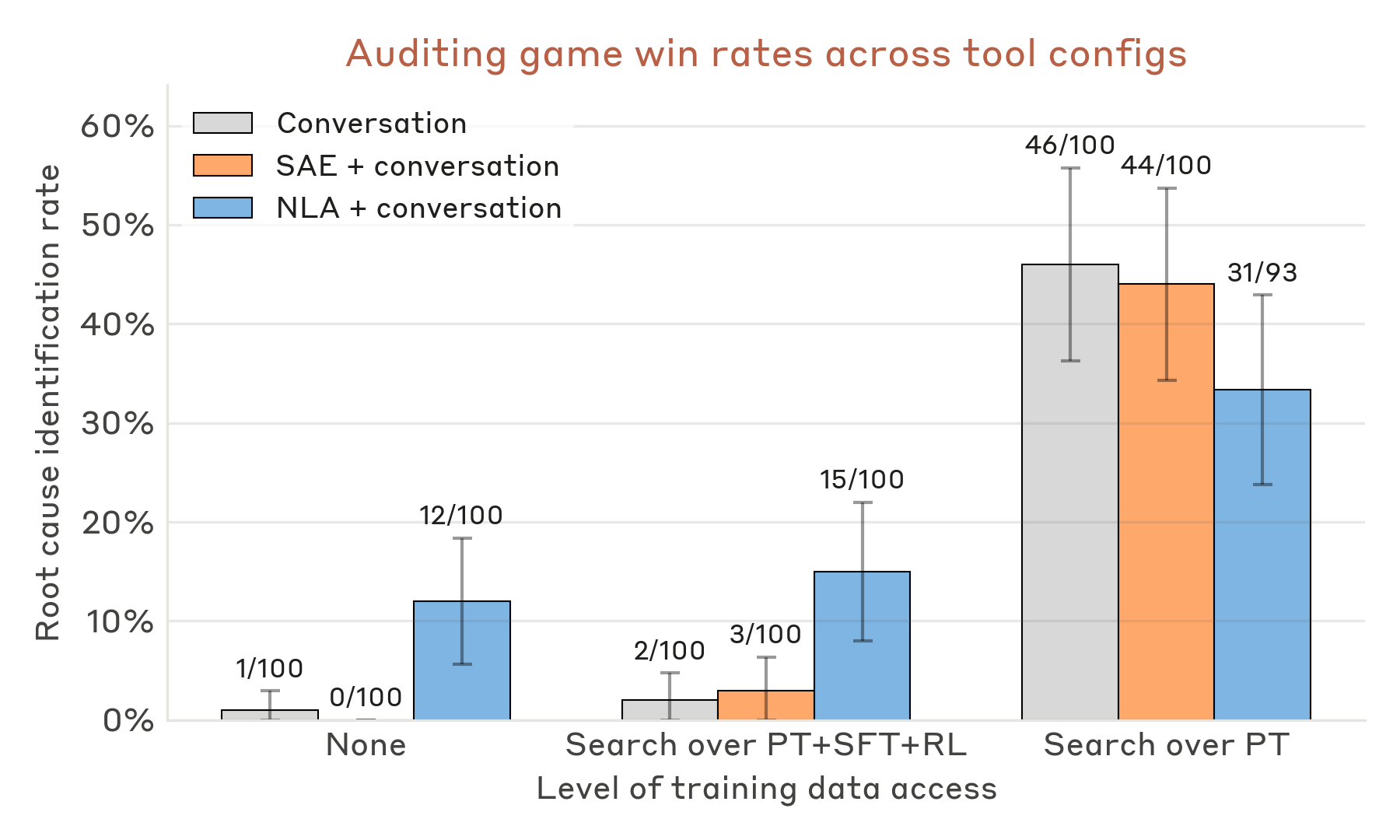
The auditing-game figure is a useful reality check for production interpretability. NLA-equipped agents identify the root cause of an intentionally misaligned model more often than conversation-only or SAE+conversation baselines in the shown tool configurations. The plot also shows that access conditions matter: tools are not magic if the surrounding investigation setup is weak. I would treat this as strong evidence that NLAs help audit workflows, not as proof that they solve automated red-teaming.
My judgment: I would prioritize this paper because it changes the interface of mechanistic work. Instead of asking a model, “Do you represent X?”, an auditor can read a free-form explanation produced from an activation and then decide what to test next. That is a better fit for messy audit discovery than narrow supervised probes.
Limitations/questions: the paper is explicit about confabulation, lack of mechanistic grounding, cost, layer sensitivity, and degenerate objectives. The verbalizer is a full language model, so it can infer or embellish beyond the activation. The next question I would track is whether NLA claims can be attached to uncertainty estimates or cross-token consistency scores that make them safer to use inside automated audit agents.
Connection to tracked themes: large model mechanisms, safety auditing, hidden-state inspection, agentic evaluation, interpretability tools.
BAMI: Training-Free Bias Mitigation in GUI Grounding
Authors: Borui Zhang, Bo Zhang, Bo Wang, Wenzhao Zheng, Yuhao Cheng, Liang Tang, Yiqiang Yan, Jie Zhou, Jiwen Lu.
Institutions: Tsinghua University; Lenovo Research.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | HTML | PDF | code
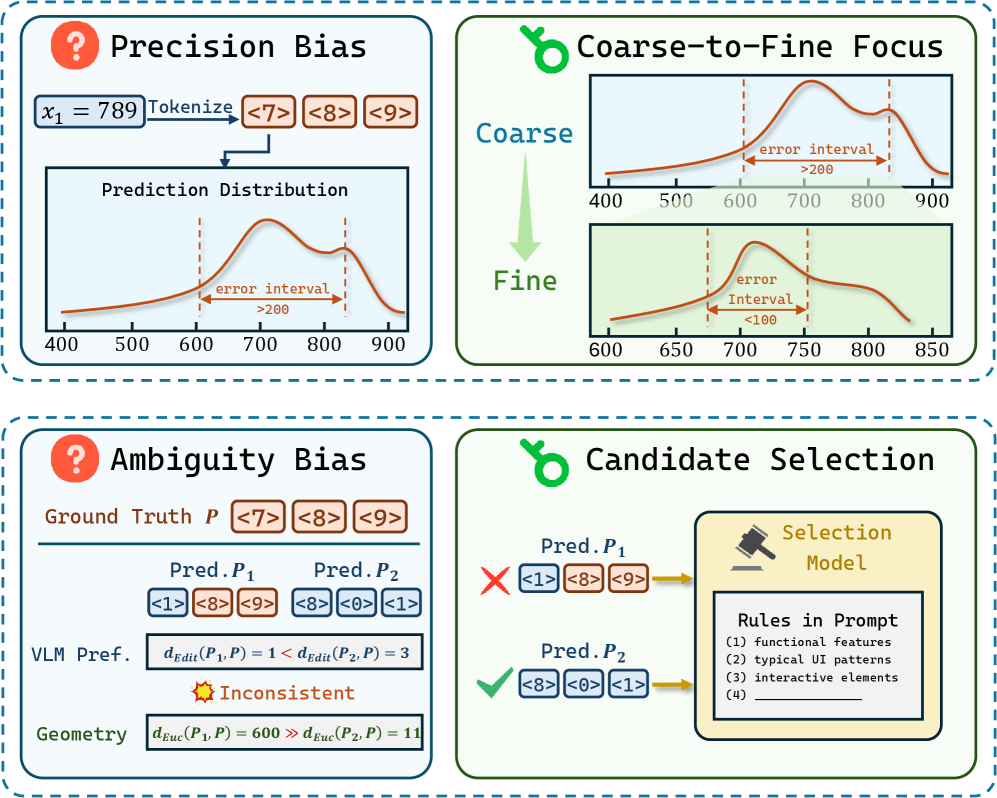
This figure gives the diagnosis before the method. Precision bias comes from high-resolution coordinate prediction: the model knows roughly where the element is, but small pixel errors are fatal. Ambiguity bias comes from dense interfaces where semantically similar regions compete. The paper’s useful move is to treat these as test-time inference failures, not only training-data failures.
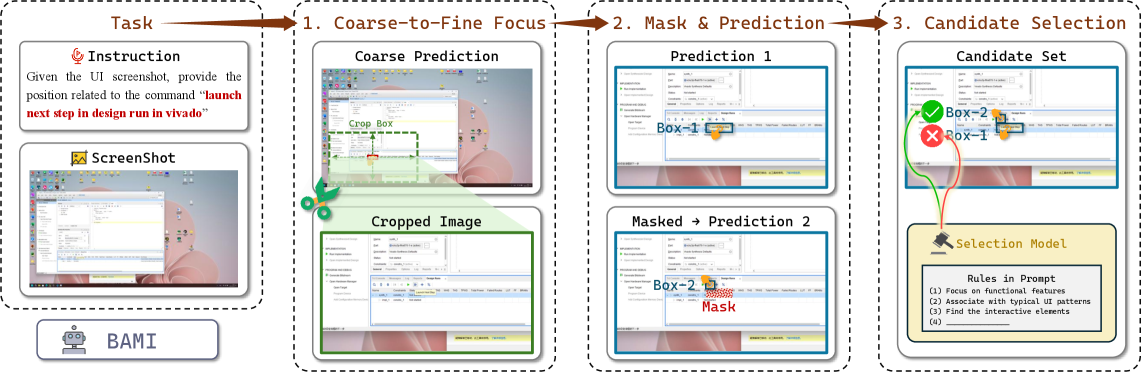
The method figure shows BAMI’s two loops. The system first predicts a coarse region, crops around it, and runs grounding again for finer localization. It also masks previously proposed boxes to force multiple mutually exclusive candidates, then asks a correction model to choose the candidate that best matches GUI priors. The caveat is cost: more predictions and a correction model are being spent at test time.
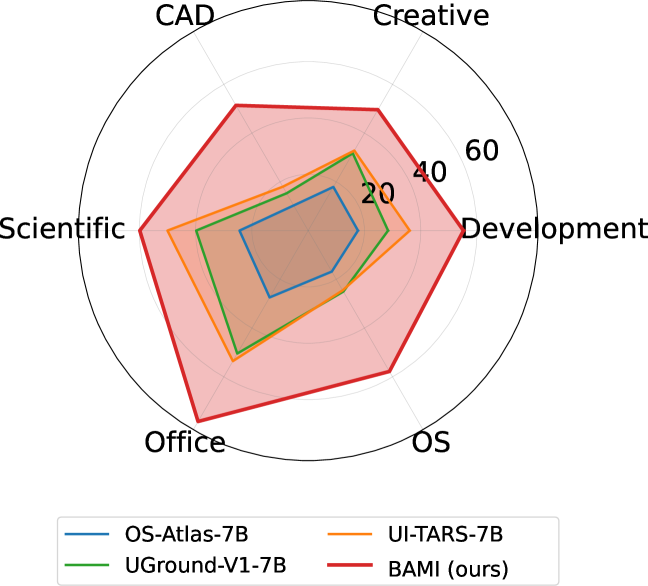
The radar plot is a compact view of the ScreenSpot-Pro result. BAMI improves the evaluated base backbones across the professional GUI categories shown in the paper, with the best reported 7B variant reaching the outer curve. This supports the claim that the method is not tuned to one narrow app surface. It still leaves the question of latency and robustness in live GUI agents, where each click changes the screen.
Quick idea: BAMI improves GUI grounding without retraining by diagnosing where a model’s coordinate prediction is biased, then using coarse-to-fine crops and candidate selection to correct the click target.
Why it matters: GUI agents fail in a very concrete way. They may understand the instruction and still click the wrong icon by a few pixels or choose the neighboring text element instead of the interactive control. That failure is hard to catch with a final-answer metric because the agent may only reveal it after the UI state changes. A test-time grounding correction layer is therefore a practical operating surface for computer-use agents.
Method walkthrough:
- Run Masked Prediction Distribution analysis: randomly perturb the screenshot, run repeated predictions, and inspect where the model’s predicted points concentrate. On 50 ScreenSpot-Pro error samples for TianXi-Action-7B, the paper classifies 14% as knowledge gap, 20% as precision bias, 54% as ambiguity bias, and 12% as other.
- Use coarse-to-fine focus for precision bias. Given a first predicted coordinate, crop the image around that area, re-run the grounding model, and map the refined coordinate back to the original screen. The experiments use two iterations and crop ratios around 0.5 to 0.7 for high-resolution screenshots.
- Use candidate correction for ambiguity bias. Generate several candidate boxes by masking already predicted candidates, then let a correction model choose among them using GUI-specific priors such as functional preference and interactive-element preference.
- Combine both manipulations in BAMI, with either online correction models such as GPT-5 or a local Qwen3-VL-8B correction model trained with LoRA on dual-box samples.
Evidence:
| ScreenSpot-Pro setting | Baseline accuracy | With BAMI | Change |
|---|---|---|---|
| TianXi-Action-7B + GPT-5 correction | 51.9 | 57.8 | +5.9 |
| TianXi-Action-7B + local Qwen3-VL-8B correction | 51.9 | 56.2 | +4.3 |
| UI-TARS-1.5-7B | 40.8 | 51.9 | +11.1 |
| OS-Atlas-7B | 18.9 | 41.6 | +22.7 |
| UGround-7B | 16.5 | 30.0 | +13.5 |
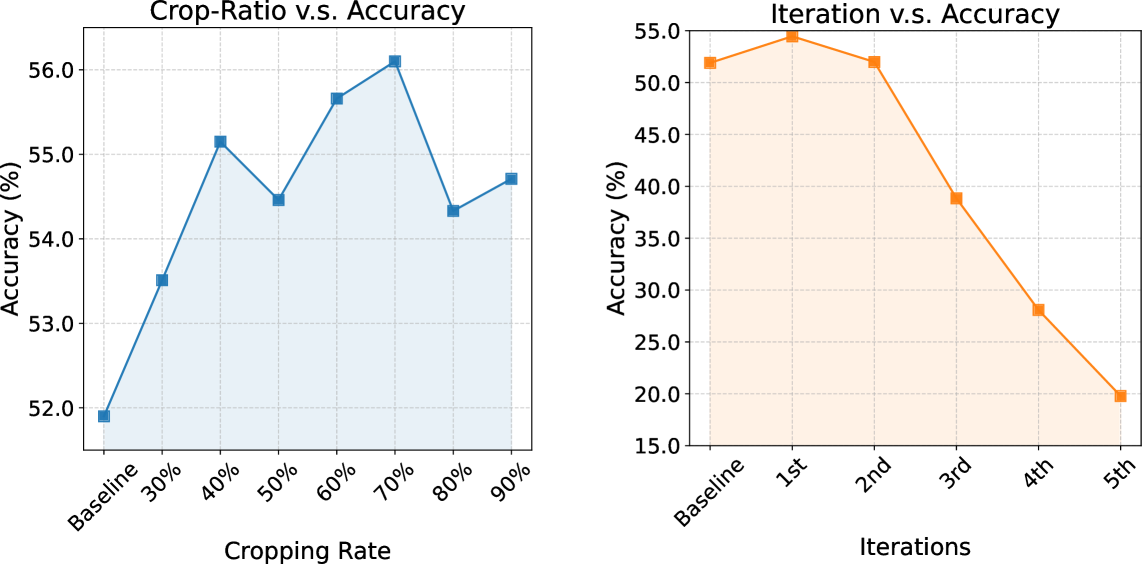
The ablation plot and accompanying tables explain why both pieces are needed. Coarse-to-fine focus alone raises the TianXi-Action-7B baseline from 51.9 to 55.2, candidate selection alone reaches 54.3, and the combined method reaches 57.8. The plot also shows why crop ratio and iteration count are not free knobs: overly aggressive cropping can remove the context needed to identify the right control.
My judgment: I like this paper because it is less glamorous than a new GUI model and more useful for agents. It says that a strong model can still have a coordinate-space pathology, and it gives a way to patch that pathology without retraining the backbone. That is exactly the kind of layer I would want before trusting a GUI agent to operate a dense enterprise application.
Limitations/questions: the method adds inference calls and a correction stage, so the cost/latency profile matters. The correction prompt uses GUI priors; those priors may fail on nonstandard interfaces, accessibility overlays, or domain-specific software. I also want to see online rollouts where a wrong correction can change future observations, not only static ScreenSpot-style localization.
Connection to tracked themes: GUI agents, document/screen intelligence, test-time correction, auditable action grounding.
Sheet as Token: A Graph-Enhanced Representation for Multi-Sheet Spreadsheet Understanding
Authors: Yiming Lei, Yiqi Wang, Yujia Zhang, Bo Guan, Depei Zhu, Chunhui Wang, Zhuonan Hao, Tianyu Shi.
Institutions: Effyic Technology Co., Ltd.; McGill University. The paper lists only corresponding/project-lead affiliations publicly.
Date/Venue: May 7, 2026, arXiv preprint.
Links: arXiv | HTML | PDF | code/data
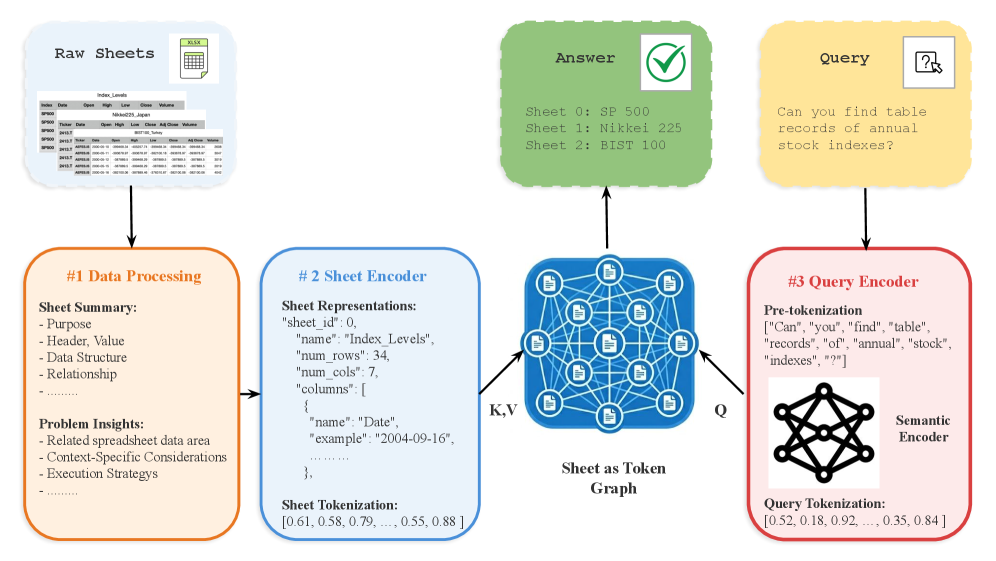
This overview is the main abstraction. Instead of chopping a workbook into rows, columns, or blocks, the method turns each worksheet into a dense Sheet Token and then retrieves a set of supporting sheets for a query. That is a sensible primitive for data agents because real spreadsheet questions often depend on workbook organization, not a single matching cell. The tradeoff is that details inside cells, formulas, charts, and comments can be lost.

The feature extractor shows what the model keeps: sheet name, grid dimensions, column headers, and representative values. This is intentionally sparse. It avoids serializing the whole sheet while preserving enough schema and shape information to distinguish tabs. The caution is obvious but important: if the decisive evidence is hidden in a low-frequency cell or formula, this representation may not see it.
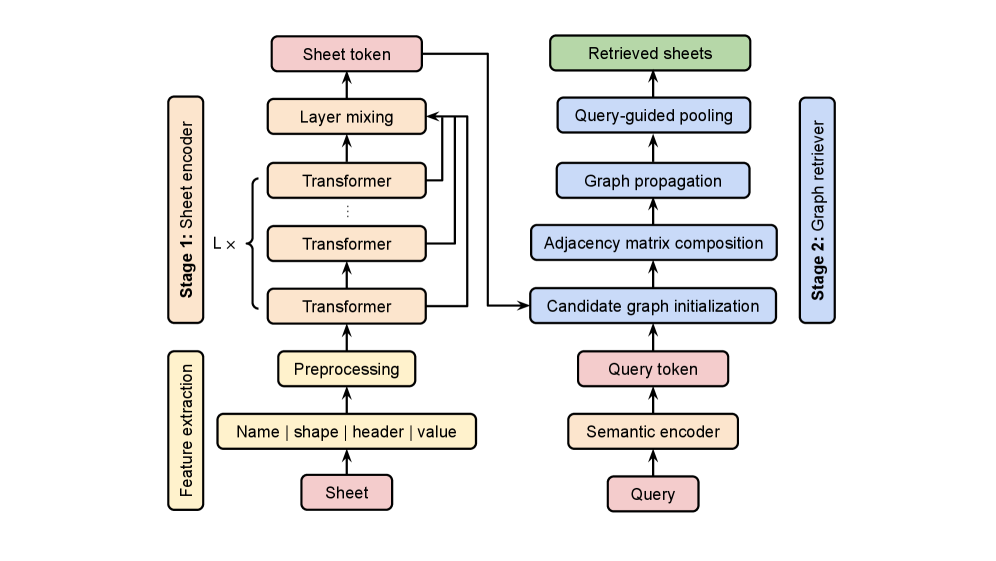
The architecture figure separates reusable representation from query-time reasoning. Stage 1 encodes sheet records with a transformer and pooling into Sheet Tokens. Stage 2 builds a query-specific graph over candidate sheets and propagates information through semantic, query-conditioned, schema-consistency, and shape-compatibility relations. This is the part that makes the paper more than a table embedding note: it treats the workbook as a small relational workspace.
Quick idea: Sheet as Token makes a worksheet the retrieval unit, then uses a graph retriever to find the sheet set that jointly supports a natural-language query.
Why it matters: data agents spend too much effort forcing spreadsheets into document-RAG or SQL-shaped assumptions. Enterprise workbooks are neither clean documents nor normalized databases. They are collections of tabs with names, headers, repeated schemas, hidden conventions, and implicit relationships. If an agent retrieves only chunks, it may lose the fact that two tabs are functionally linked.
Method walkthrough:
- Convert each sheet into a schema-aware record: workbook/tab name, shape, up to a fixed number of column headers, and representative example values.
- Serialize the record and pass it through a 12-layer transformer encoder. A pooling operation produces a dense vector, the Sheet Token. The Stage 1 encoder is trained with pairwise sheet-matching supervision using label smoothing.
- For a query, construct a candidate workspace graph over sheets. Edges encode semantic similarity, query relevance, schema consistency, and shape compatibility.
- Train the graph retriever with listwise query supervision, including set-level contrastive retrieval, positive/negative alignment, and node-level relevance supervision.
- Cache Sheet Tokens offline and keep query-specific graph reasoning online, so retrieval can scale better than full-workbook serialization.
Evidence:
| Evidence item | Reported value |
|---|---|
| IndustryTab corpus | 614 sheets |
| Pairwise instances | 1,842, with 1:5 positive-to-negative ratio |
| Listwise queries | 134 queries |
| Stage 2 evaluation accuracy | 0.8438 |
| Stage 1 Sheet Encoder cost | about 45.9 GFLOPs per pairwise sample, 35-39 samples/s on one NVIDIA A40 |
| Stage 2 Graph Retriever cost | about 235 GFLOPs per query instance, about 18.3 queries/s |
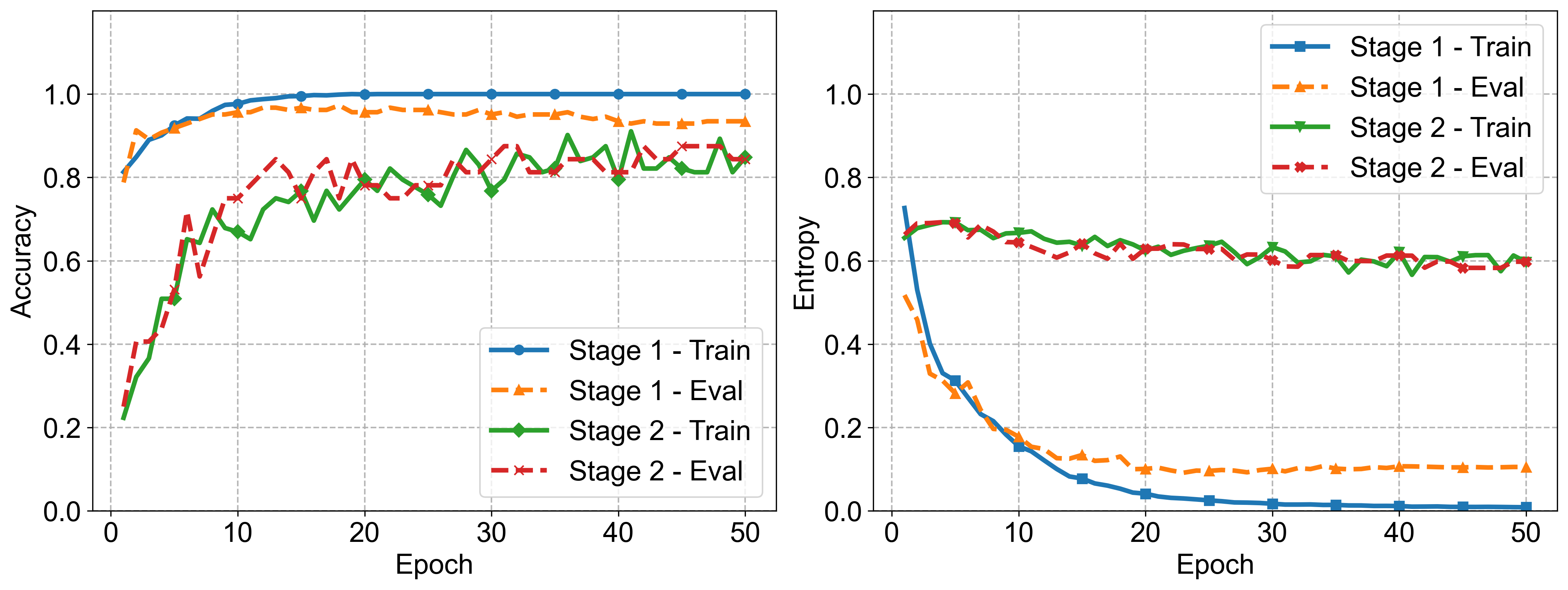
The training curves show the two-stage pipeline behaving cleanly: Stage 1 learns pairwise sheet matching quickly, while Stage 2 improves listwise retrieval and settles with lower entropy. The figure is useful because the paper’s dataset is small; stable dynamics matter when the result could otherwise be a fragile artifact. The remaining evidence gap is external comparison: I would want stronger chunk-based, long-context, and downstream QA/code-generation baselines.
| IndustryTab ablation | Accuracy | Entropy |
|---|---|---|
| Full model | 84.4 | 0.598 |
| Shallow graph baseline | 81.2 | 0.614 |
| Without column examples | 68.8 | 0.660 |
My judgment: this paper is early but points at the right interface for spreadsheet agents. A worksheet is a useful object: small enough to cache, large enough to preserve role and schema, and relational enough to sit in a graph. I would not treat the current benchmark as deployment-grade evidence, but I would borrow the abstraction.
Limitations/questions: the feature set omits formulas, charts, formatting, comments, and fine-grained cell evidence. The authors also note the need for larger real-world workbooks, stronger baselines, multi-seed statistics, and downstream spreadsheet reasoning tasks. My next question is whether Sheet Tokens can carry provenance: if a downstream answer uses a retrieved sheet set, can the agent still point to exact cells and formulas?
Connection to tracked themes: data agents, spreadsheet understanding, structured retrieval, workbook-level evidence, document intelligence.
Reading Priority and Next Questions
I would read Natural Language Autoencoders first because it adds a new inspection interface for model internals and has immediate implications for automated audits. BAMI is the most practical systems paper in the issue: it patches the last inch between a GUI instruction and a click. Sheet as Token is the one to keep for data-agent architecture, especially if the next issue turns back to enterprise spreadsheets or workbook QA.
Next questions I would track:
- Can NLA explanations be scored with uncertainty, cross-token recurrence, or independent SAE agreement before an audit agent relies on them?
- Can GUI grounding correction be evaluated inside live multi-step agent rollouts, where a wrong click changes future state?
- Can sheet-level retrieval preserve exact cell provenance, formulas, and versioned workbook state after the graph retriever selects the supporting sheet set?
- From the broader shortlist, Auto Research with Specialist Agents, OpenSearch-VL, Adaptive Action Execution for World Action Models, AI Co-Mathematician, Reversible SFT Behaviors, OBLIQ-Bench, Skill1, and EMO are still worth reading next.