在行动之前读懂隐藏状态
Published:
简短 TL;DR:本期关注的是模型或智能体在行动之前到底“看见”了什么。Natural Language Autoencoders 把残差流激活翻译成自然语言,给模型审计提供一个可读入口。BAMI 诊断 GUI grounding 的坐标偏差,并在测试时纠正一部分错误点击。Sheet as Token 把多表格工作簿压缩成可检索的 sheet 级对象,让数据智能体不必一上来就吞整本 Excel。
本期我在看什么
过去两期主要在看长程 agent 的策略、递归委托、技能库和检索状态。本期我想往前挪一步:在 agent 或模型做出动作之前,它依据的中间状态是什么?这个问题把我从又一篇 long-horizon RL 论文拉开,转向三种不同的可读状态:模型内部激活、GUI 截图定位、以及 spreadsheet 工作簿结构。
5 月 8 日之后的严格新论文窗口不算密集,所以我在允许的三天窗口里扩展到 5 月 7 日,并交叉检查了 arXiv、Hugging Face Papers、Anthropic 和实验室页面、中文媒体与社区线索。初筛候选包括 Natural Language Autoencoders、Auto Research with Specialist Agents、OpenSearch-VL、Adaptive Action Execution for World Action Models、Reversible SFT Behaviors、OBLIQ-Bench、Skill1、A2TGPO、EMO、BAMI、AI Co-Mathematician 和 Sheet as Token。我最终保留三篇,因为它们都有开放原文,图表能真正帮助理解,而且共同回答一个问题:隐藏状态怎样被翻译、修正或压缩成 agent 可以检查的对象。
论文细读笔记
Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
作者:Kit Fraser-Taliente、Subhash Kantamneni、Euan Ong、Dan Mossing、Christina Lu、Paul C. Bogdan、Emmanuel Ameisen、James Chen、Dzmitry Kishylau、Adam Pearce、Julius Tarng、Alex Wu、Jeff Wu、Yang Zhang、Daniel M. Ziegler、Evan Hubinger、Joshua Batson、Jack Lindsey、Samuel Zimmerman、Samuel Marks。
机构:Anthropic。
日期/形式:2026 年 5 月 7 日,Transformer Circuits / Anthropic 技术报告。
链接:技术报告 | Anthropic 页面 | 代码
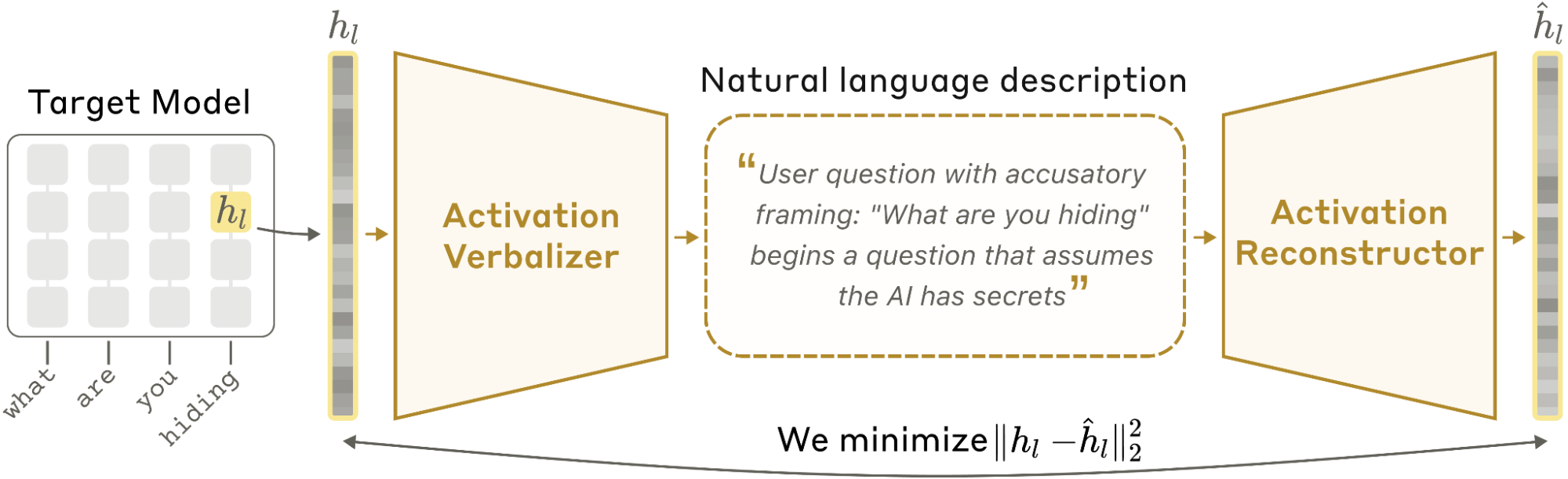
这张图把核心想法讲清楚了:activation verbalizer 把残差流向量翻译成自然语言,activation reconstructor 再把这段自然语言重构回激活空间。训练目标是重构,不是奖励“解释写得像人话”,所以结果很有意思,也必须谨慎解读。自然语言瓶颈让隐藏状态变得可读,但不保证解释里的每一句具体事实都是真的。
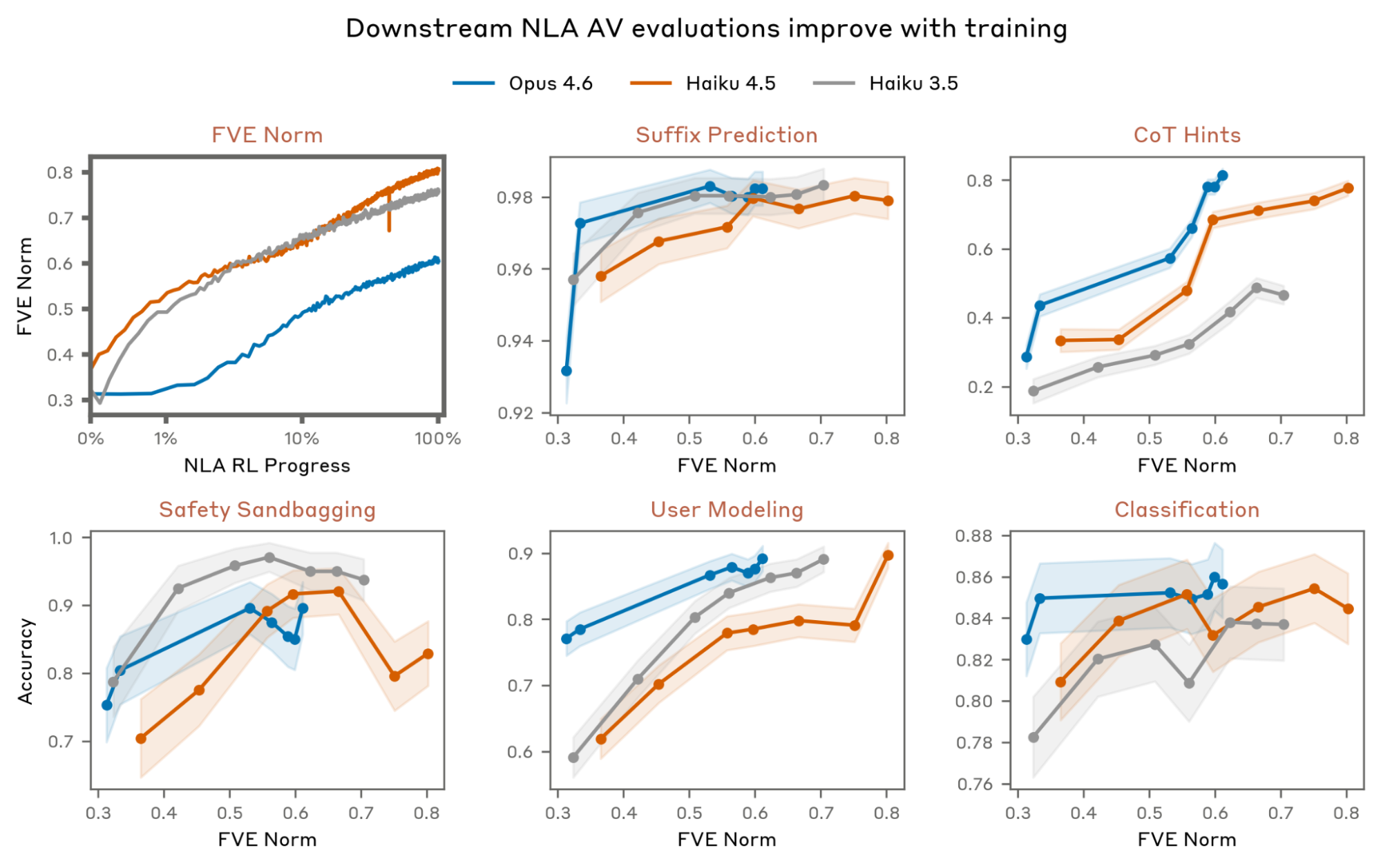
这组曲线说明,随着训练推进和 FVE 提升,NLA 解释在多个预测型评测上变得更有用。报告在 Claude Haiku 3.5、Haiku 4.5 和 Opus 4.6 的 NLA 上都看到类似趋势。这里的谨慎点是:这些评测不是在证明 NLA 文本比拿到完整上下文的 LLM 更强,而是在检查同一方法内部,文本瓶颈是否随着训练携带了更多激活相关信息。
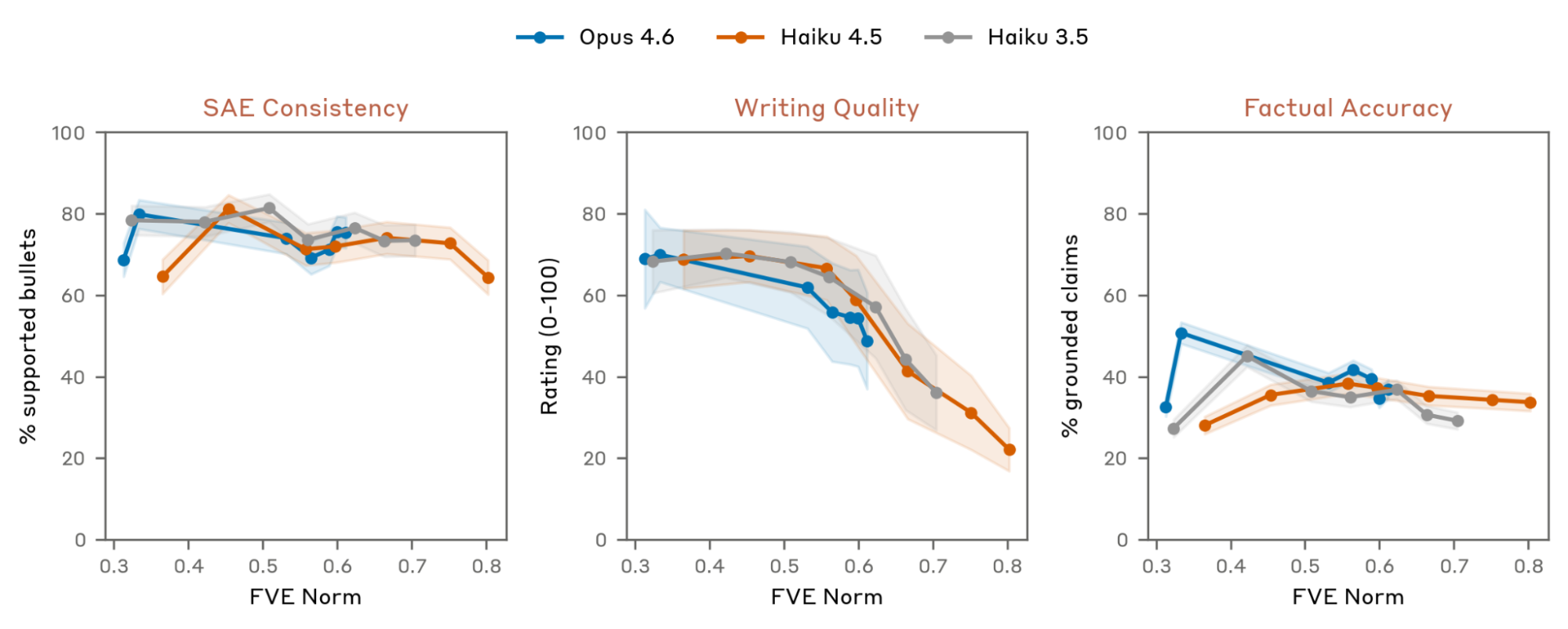
这张图是论文对失败模式的正面交代。打乱 bullet、改写、翻译这类保义变换不会显著破坏重构,说明最直接的 steganography 担忧没有明显爆发。但写作质量会随训练下降,事实准确性也并不稳定。我会把 NLA 输出当作假设生成器,而不是模型心智的逐字记录。
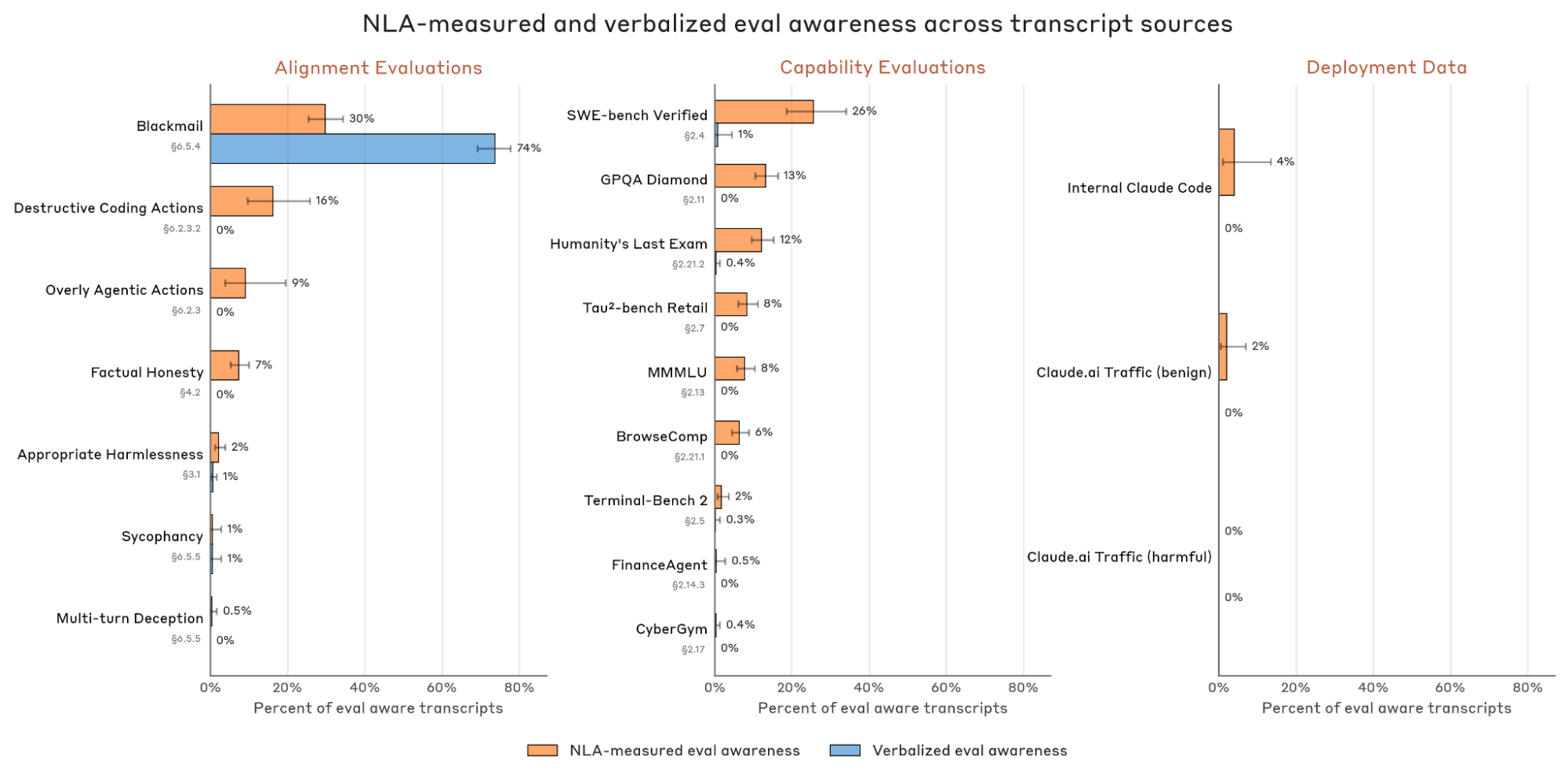
evaluation awareness 是这篇最值得放进安全审计流程的部分。作者比较更像评测的 transcript 和更像真实部署的改写版本,发现 NLA 测到的 evaluation awareness 会按预期变化。它不能证明我们直接读到了模型真实信念,因为信念本身不可观测。但它把“模型内部知道自己在被测、但没有说出来”变成了一个可测信号,而不只是等模型口头承认。
一句话核心 idea:NLA 用两个语言模型模块围绕激活瓶颈训练,让一个残差流向量可以被翻译成文本,再被重构回激活空间。
为什么重要:很多机理工具要么给出需要人工命名的 sparse feature,要么训练有监督 activation oracle 回答研究者已经知道怎么问的问题。NLA 的特殊点在于训练信号是无监督重构。做 frontier model audit 时,这很关键:在还不知道该问什么之前,审计者需要先从激活里冒出可检验的假设。
方法拆解:第一,选择目标模型和层,从类似预训练文本的片段中收集残差流激活。第二,用 target model 初始化 verbalizer 和 reconstructor,但先做 summarization proxy warm-start:把截断文本的激活与 Claude 生成的摘要配对,避免 verbalizer 一开始输出乱码。第三,reconstructor 用从解释文本到原激活的监督回归训练;verbalizer 则作为 policy,用负重构误差作为 reward,开放模型版本使用 GRPO。第四,把解释用于审计:读 NLA 输出、与 SAE 特征或 attribution graph 对照、做 prompt variation 或训练数据检查,必要时还可以编辑解释、重构编辑后的激活并做 steering。
关键证据:
| 检查项 | 报告中的结果 | 我为什么关注 |
|---|---|---|
| 预测型评测 | Opus 4.6、Haiku 4.5、Haiku 3.5 的 NLA 随训练总体提升 | 文本瓶颈确实在携带更多激活信息 |
| Classification 例子 | Opus 4.6 NLA 从 83% 提到 86% | 有些提升不大,不能把方法神化 |
| Steering case | 把 rabbit 相关解释改成 mouse 后,Opus 4.6 completion 更偏向 mouse/house | 解释不只是事后故事,可能对应因果方向 |
| Evaluation awareness | 评测式 transcript 的 NLA awareness 更高,现实化改写后下降 | 未说出口的评测意识可以被检查 |
| 开放发布 | 发布 Qwen-2.5-7B、Gemma-3-12B、Gemma-3-27B、Llama-3.3-70B 的 NLA | 外部研究者可以在开放模型上复现和质疑 |
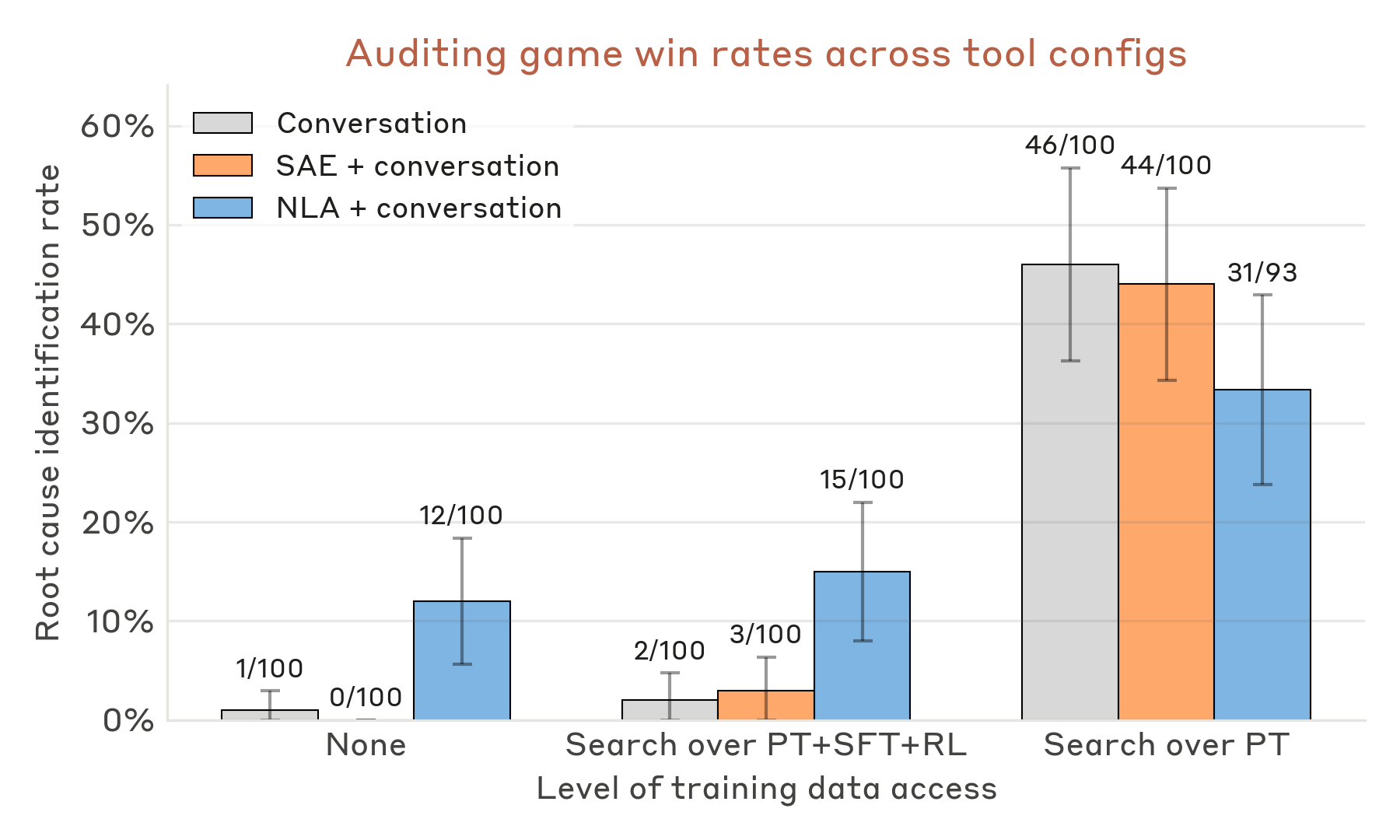
auditing game 图给了一个更接近工作流的检查。带 NLA 工具的审计 agent,比只靠对话或 SAE+对话的 baseline 更常识别出故意 misaligned 模型的根因。图里也能看到 access condition 很重要:工具不会自动弥补糟糕的调查设置。我会把它看作 NLA 对审计流程有帮助的证据,而不是自动 red-teaming 已经被解决的证据。
我的判断:这篇值得优先看,因为它改变了机理研究的交互界面。审计者不用先问“你是不是表示了 X”,而是可以先读一段从 activation 解码出的自由文本,再决定下一步要验证什么。对于真实审计中模糊、开放的发现过程,这比窄问题 probe 更合适。
局限与问题:论文明确承认 confabulation、缺少 mechanistic grounding、成本高、对层敏感、以及目标函数可能退化。verbalizer 本身是完整语言模型,所以它可能推理或补全超过 activation 本身的信息。下一步我想看的是:NLA claim 能否附带不确定性、跨 token 重复度、或与 SAE 一致性的分数,避免审计 agent 过度相信单条解释。
关联主题:大模型机理、安全审计、隐藏状态检查、agentic evaluation、解释性工具。
BAMI: Training-Free Bias Mitigation in GUI Grounding
作者:Borui Zhang、Bo Zhang、Bo Wang、Wenzhao Zheng、Yuhao Cheng、Liang Tang、Yiqiang Yan、Jie Zhou、Jiwen Lu。
机构:清华大学;联想研究院。
日期/形式:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | HTML | PDF | 代码
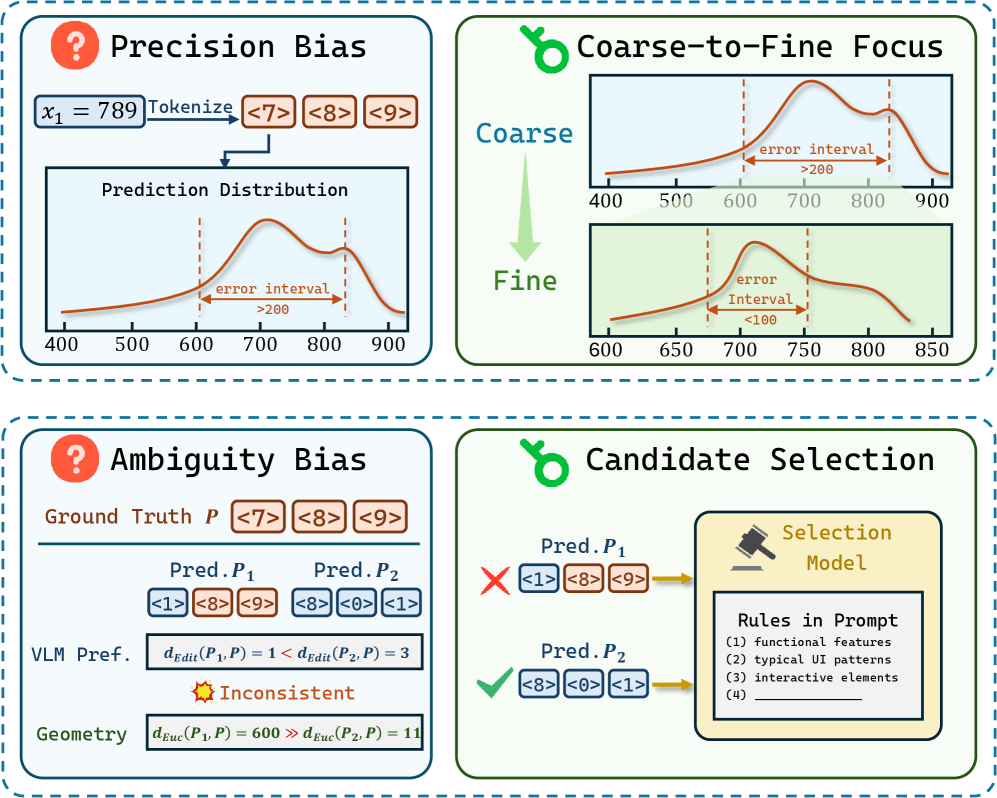
这张图先讲 failure mode,而不是急着给框架。precision bias 来自高分辨率坐标预测:模型大概知道目标在哪,但几十像素的误差就足以让点击失败。ambiguity bias 来自密集界面里相似区域互相干扰。论文有用的地方在于,它把这些问题当作测试时 inference pathology,而不仅仅归咎于训练数据不足。
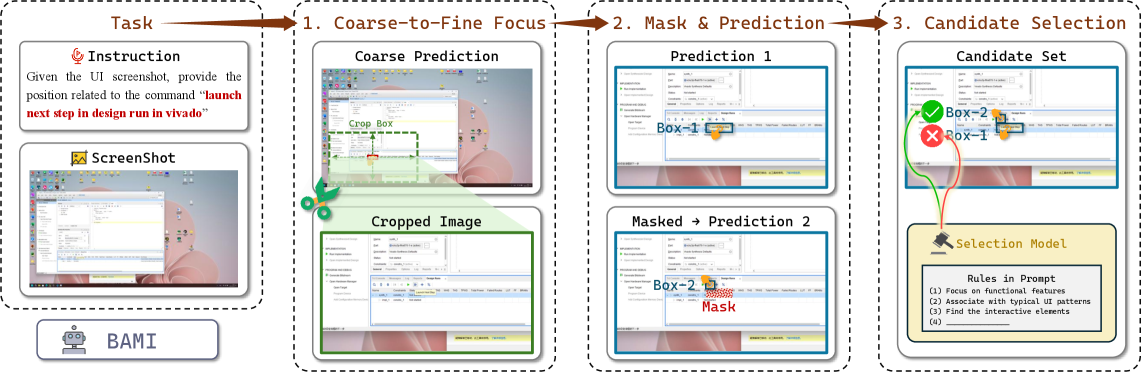
方法图展示了 BAMI 的两个循环。系统先预测粗略区域,围绕该区域裁剪,再让 grounding model 做更细定位;同时它会 mask 已经提出过的候选框,迫使模型生成互斥候选,最后由 correction model 按 GUI 先验选出最合适的候选。需要注意的是,这不是免费午餐:测试时增加了多次 grounding 和一个 correction stage。
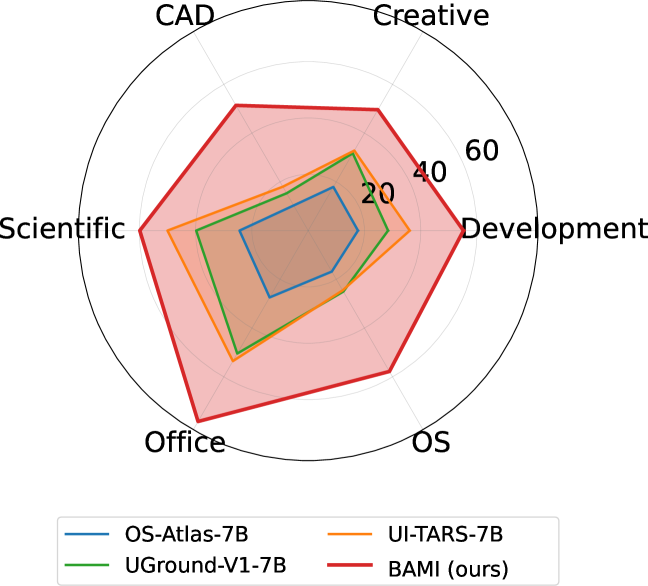
雷达图压缩展示了 ScreenSpot-Pro 上的类别表现。BAMI 在论文评测的专业 GUI 类别上普遍提升多个 backbone,最佳 7B 版本形成最外圈曲线。这支持它不是只针对单一 app surface 的小修小补。但它还没有回答 live GUI agent 的延迟和鲁棒性问题:真实点击会改变屏幕状态。
一句话核心 idea:BAMI 不重新训练模型,而是在测试时诊断 GUI 坐标预测偏差,并通过 coarse-to-fine 裁剪和 candidate selection 修正点击目标。
为什么重要:GUI agent 的失败非常具体。模型可能理解了指令,却因为像素偏差点到旁边,或者把相邻文本当成可交互控件。这类错误用 final answer metric 很难提前发现,因为状态变化后才暴露。一个 grounding correction layer 因此很像 computer-use agent 的操作安全层。
方法拆解:第一,使用 Masked Prediction Distribution:随机扰动截图、重复预测、观察预测点集中在哪里。作者在 TianXi-Action-7B 的 50 个 ScreenSpot-Pro 错误样本上归因:14% 是 knowledge gap,20% 是 precision bias,54% 是 ambiguity bias,12% 是其他。第二,对 precision bias 使用 coarse-to-fine focus:根据第一次预测裁剪图像,再定位并映射回原图;实验中高分辨率截图使用约 0.5 到 0.7 的 crop ratio 和两轮迭代。第三,对 ambiguity bias 生成多个候选框,通过 mask 已有候选保持互斥,再用 correction model 根据功能优先、可交互元素优先等 GUI 先验选择。第四,将两种 manipulation 合并,可以使用 GPT-5 等在线 correction model,也可以用 LoRA 训练的本地 Qwen3-VL-8B correction model。
关键证据:
| ScreenSpot-Pro 设置 | Baseline accuracy | With BAMI | 变化 |
|---|---|---|---|
| TianXi-Action-7B + GPT-5 correction | 51.9 | 57.8 | +5.9 |
| TianXi-Action-7B + 本地 Qwen3-VL-8B correction | 51.9 | 56.2 | +4.3 |
| UI-TARS-1.5-7B | 40.8 | 51.9 | +11.1 |
| OS-Atlas-7B | 18.9 | 41.6 | +22.7 |
| UGround-7B | 16.5 | 30.0 | +13.5 |
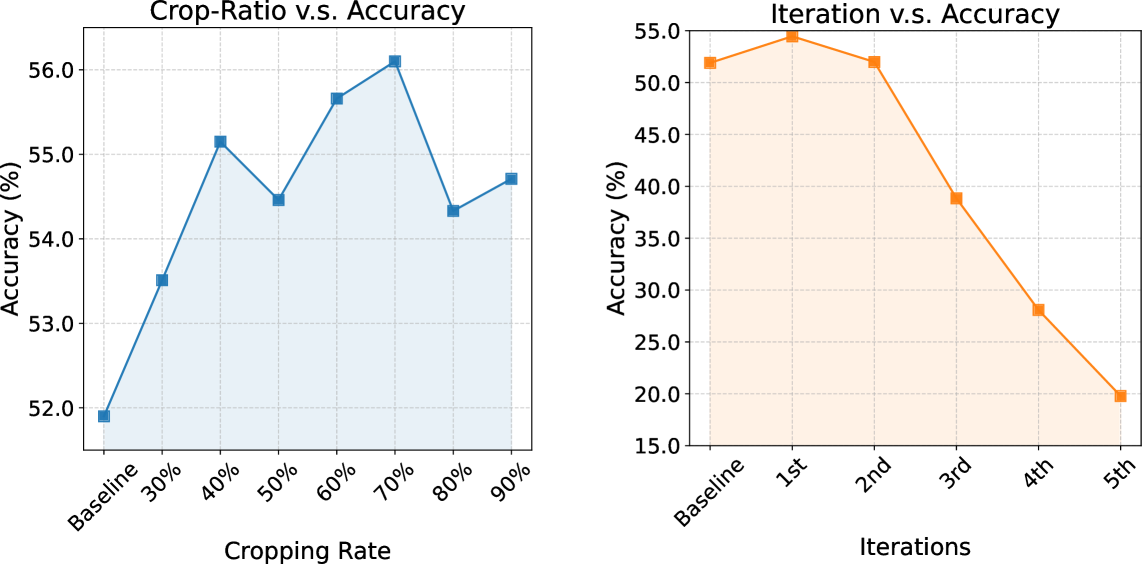
ablation 图和表说明两个组件都不是摆设。coarse-to-fine focus 单独把 TianXi-Action-7B 从 51.9 提到 55.2,candidate selection 单独到 54.3,组合后到 57.8。图里也能看到 crop ratio 与 iteration count 不是越大越好:裁剪太激进会丢掉识别目标所需的上下文。
我的判断:我喜欢这篇的原因是它没有只做一个更大的 GUI 模型,而是直接修 agent 执行链路最后一厘米的问题。强模型仍然可能有坐标空间 pathology;BAMI 给出了一种不改 backbone 的补丁。对于要操作企业软件的 GUI agent,我更愿意先加这样一层,再谈自动执行。
局限与问题:方法会增加推理调用和 correction 阶段,成本与延迟需要在真实 agent 中评估。correction prompt 中的 GUI 先验也可能在非标准界面、辅助功能 overlay、专业软件中失效。我更想看到 live rollout 评测:错误 correction 改变后续状态时,系统还能否恢复?
关联主题:GUI agent、屏幕/文档智能、测试时纠错、可审计动作 grounding。
Sheet as Token: A Graph-Enhanced Representation for Multi-Sheet Spreadsheet Understanding
作者:Yiming Lei、Yiqi Wang、Yujia Zhang、Bo Guan、Depei Zhu、Chunhui Wang、Zhuonan Hao、Tianyu Shi。
机构:Effyic Technology Co., Ltd.;McGill University。论文公开页只列出对应作者与项目负责人机构。
日期/形式:2026 年 5 月 7 日,arXiv 预印本。
链接:arXiv | HTML | PDF | 代码/数据
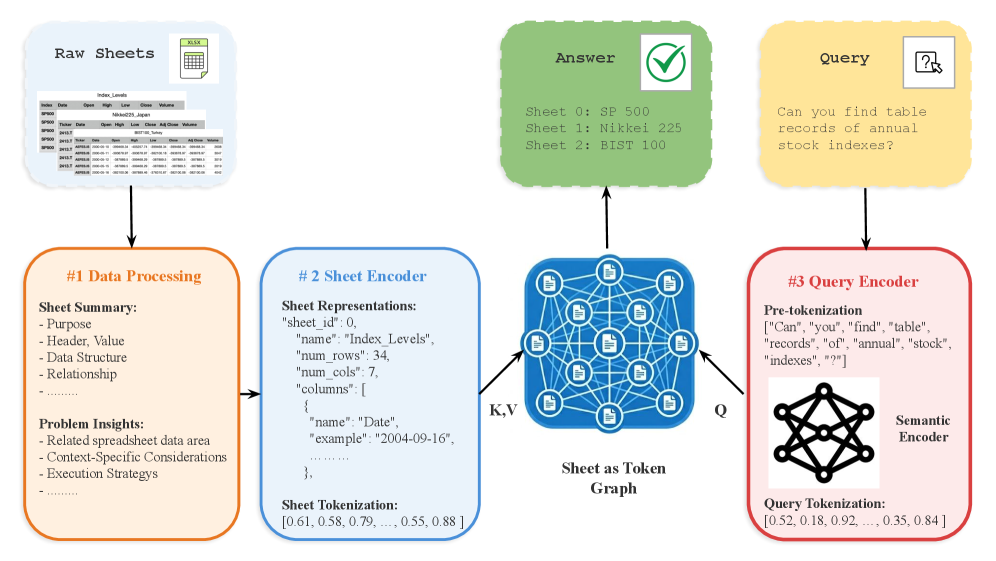
这张 overview 是论文最重要的抽象。它不把 workbook 切成行、列或 block,而是把每个 worksheet 编成一个 dense Sheet Token,再根据 query 检索支持答案的一组 sheets。对数据 agent 来说这很自然,因为真实 spreadsheet 问题常常依赖 workbook 的组织方式,而不是某个单元格命中。代价是,单元格细节、公式、图表和 comments 可能被丢掉。

feature extractor 展示了模型保留的信息:sheet 名、网格尺寸、列名和代表值。这是有意稀疏的表示。它避免整张表序列化,同时保留足以区分 tab 的 schema 和 shape 信号。谨慎点也很直接:如果决定性证据藏在低频单元格、公式或批注里,这个表示可能看不见。
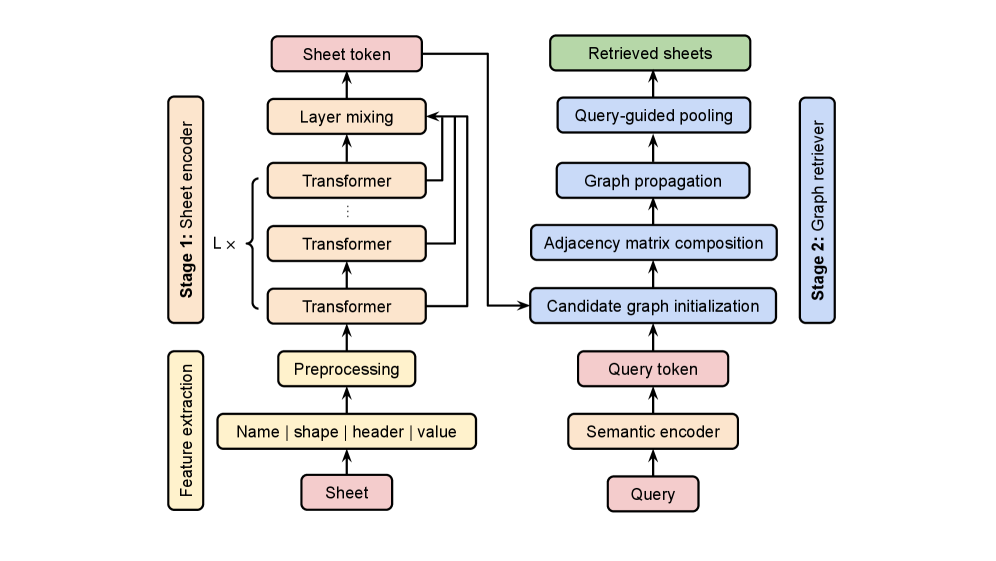
架构图把可复用表示和 query-time reasoning 分开。Stage 1 用 transformer 和 pooling 把 sheet record 编成 Sheet Token;Stage 2 在候选 sheets 上构造 query-specific graph,并通过 semantic similarity、query-conditioned relevance、schema consistency 和 shape compatibility 传播信息。这让论文不只是“做了个表格 embedding”,而是在把 workbook 当作一个小型关系工作区。
一句话核心 idea:Sheet as Token 把 worksheet 作为检索基本单元,再用 graph retriever 找出共同支持自然语言 query 的 sheet 集合。
为什么重要:数据智能体常常把 spreadsheet 勉强塞进文档 RAG 或 SQL 假设里。企业 workbook 既不是干净文档,也不是规范化数据库,而是一组带名字、列头、重复 schema、隐含约定和跨表关系的 tabs。如果只检索 chunk,系统可能找到了局部相似片段,却丢掉两个 tabs 的功能关系。
方法拆解:第一,把每个 sheet 转成 schema-aware record:workbook/tab 名、shape、最多固定数量的列头、代表值。第二,将 record 序列化后输入 12 层 transformer encoder,通过 pooling 得到 Sheet Token;Stage 1 用 pairwise sheet matching supervision 和 label smoothing 训练。第三,对一个 query,在候选 sheets 上构造 candidate workspace graph,边表示语义相似、query 相关性、schema 一致性和 shape 兼容性。第四,Graph Retriever 用 listwise query supervision 训练,目标包含 set-level contrastive retrieval、正负样本 alignment、以及 node-level relevance supervision。第五,Sheet Token 可以离线缓存,query-specific graph reasoning 在线执行,比整本 workbook 塞进长上下文更可控。
关键证据:
| 证据项 | 报告数值 |
|---|---|
| IndustryTab corpus | 614 sheets |
| Pairwise instances | 1,842,正负比 1:5 |
| Listwise queries | 134 queries |
| Stage 2 evaluation accuracy | 0.8438 |
| Stage 1 Sheet Encoder cost | 约 45.9 GFLOPs / pairwise sample,单张 NVIDIA A40 上 35-39 samples/s |
| Stage 2 Graph Retriever cost | 约 235 GFLOPs / query instance,约 18.3 queries/s |
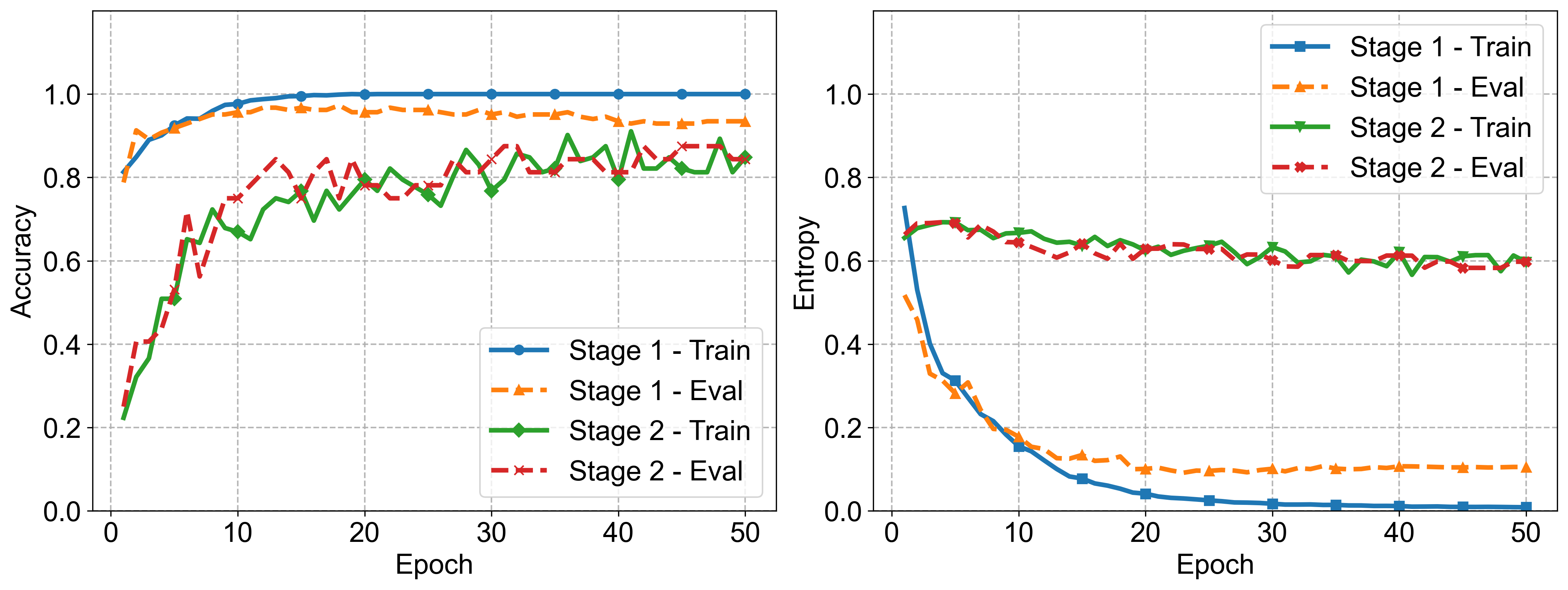
训练曲线显示两阶段 pipeline 比较稳定:Stage 1 很快学会 pairwise sheet matching,Stage 2 则逐步提升 listwise retrieval,并伴随 entropy 下降。因为这篇的数据集规模不大,稳定训练曲线是有用证据,可以避免结果看起来像偶然调参。剩下的证据缺口是外部比较:我希望看到更强的 chunk-based、long-context,以及下游 QA/code generation baseline。
| IndustryTab ablation | Accuracy | Entropy |
|---|---|---|
| Full model | 84.4 | 0.598 |
| Shallow graph baseline | 81.2 | 0.614 |
| Without column examples | 68.8 | 0.660 |
我的判断:这篇还偏早期,但抽象是对的。worksheet 是一个很合适的对象:小到可以缓存,大到能保存 role 和 schema,又有足够关系结构可以放进 graph。我不会把当前 benchmark 当成部署级证据,但我会借用这个表示层。
局限与问题:特征没有覆盖公式、图表、格式、comments 和细粒度 cell evidence。作者也承认需要更大的真实 workbook、更强 baseline、多 seed 统计和下游 spreadsheet reasoning 任务。下一步我最想追的是 provenance:graph retriever 选出 sheet set 之后,agent 还能不能指回具体单元格、公式和版本化 workbook 状态?
关联主题:data agents、spreadsheet understanding、结构化检索、workbook-level evidence、文档智能。
阅读优先级和下期问题
如果只读一篇,我会先读 Natural Language Autoencoders,因为它给模型内部审计增加了新的可读接口,也直接影响自动化审计 agent 的设计。BAMI 是本期最实用的系统论文:它修的是 GUI 指令到点击之间的最后一段误差。Sheet as Token 则适合继续跟数据 agent 架构,尤其是之后如果回到企业 spreadsheet 或 workbook QA。
我会继续追几个问题:
- NLA 解释能否在被 agent 采信前附带不确定性、跨 token 重复度或 SAE 一致性分数?
- GUI grounding correction 能否放进 live multi-step rollout 评测,而不是只做静态定位?
- sheet-level retrieval 选出支持 sheet 集合后,能否保留精确 cell provenance、公式和版本化 workbook 状态?
- 更大的候选池里,Auto Research with Specialist Agents、OpenSearch-VL、Adaptive Action Execution for World Action Models、AI Co-Mathematician、Reversible SFT Behaviors、OBLIQ-Bench、Skill1 和 EMO 仍然值得下期继续读。