Reading Agent Traces Before They Become Failures
Published:
TL;DR: this round is about agent traces as training and diagnostic objects. A3 trains CLI agents by assigning credit to shell actions rather than only to whole trajectories. The tool-calling paper shows that tool choice is linearly readable and steerable inside language models before the JSON call is emitted. MASPrism uses small-model prefill signals to locate likely failure sources in long multi-agent logs without decoding a diagnostic answer.
What I Am Watching This Round
The last few issues spent a lot of time on visible state: skills, plans, citations, activations, GUI coordinates, and spreadsheet sheets. That line is still useful, but I did not want another issue whose only message is “make state inspectable.” The fresher May 8 papers I kept this time all look at a more operational question: once an agent leaves a trace, can we use that trace to train, steer, or debug the next action?
I screened a 24-hour to three-day pool across arXiv, Hugging Face Papers, Chinese tech media, community links, and lab blogs. The broader shortlist included CA-SQL, The Memory Curse, Rubric-Grounded RL, latent planning probes, AI Co-Mathematician, AutoTTS, HyperEyes, InterLV-Search, Skill1, A2TGPO, adaptive world-action execution, MiA-Signature, EMO, and several tool-use diagnostics. I kept three papers because they are open, non-duplicate, figure-rich, and complementary: one trains the acting agent, one reads the model just before a tool call, and one diagnoses a failed multi-agent execution after the fact.
Paper Notes
Learning CLI Agents with Structured Action Credit under Selective Observation
Authors: Haoyang Su, Ying Wen.
Institutions: Fudan University; Shanghai Innovation Institute; Shanghai Jiao Tong University.
Date/Venue: May 8, 2026, arXiv preprint.
Links: arXiv | HTML | code
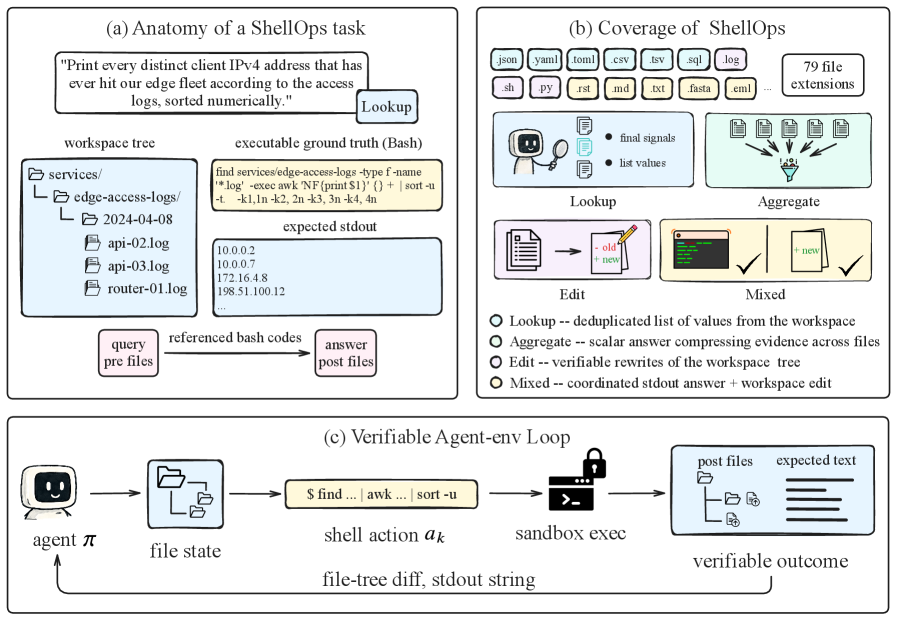
This figure defines the paper’s world: a CLI agent receives a natural-language request, sees a filesystem, runs shell actions, and is scored by executable checks over terminal output or file state. The important part is that the action space is not a neat API menu. It is bash over messy repositories, logs, config files, tables, and generated artifacts. That makes the paper closer to real coding and data-agent workflows than another single-call tool benchmark.
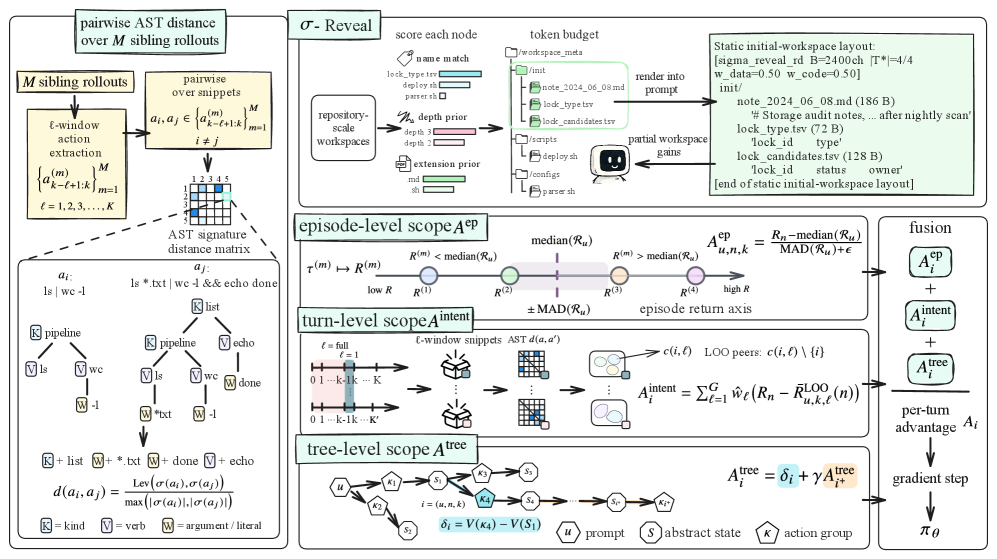
The algorithm figure is the best way to read A3. Shell commands are converted into AST signatures, similar actions are compared structurally, and three credit channels are fused into a per-turn advantage. The caveat is also visible here: AST similarity is a useful proxy for action intent, but two commands with similar syntax can have different effects if paths, file contents, or previous state differ.
Quick idea: the paper treats CLI-agent training as a delayed-credit problem over executable shell traces, then uses command structure and selective workspace context to make the credit signal less blunt.
Why it matters: a coding or data agent can fail because it never saw the relevant file, because it ran the wrong inspection command, or because a good early action got buried under a later mistake. Standard episode-level RL sees only the terminal score. A3 asks whether shell structure itself can help decide which turns deserved credit.
Method walkthrough:
- The authors introduce ShellOps, a verifiable suite of shell-driven tasks. The standard corpus has 1,624 tasks, and ShellOps-Pro adds 150 harder out-of-distribution tasks with 4,063 files, an average of 27.1 files per task, and 42 readable text extensions.
- For partial observation, sigma-Reveal scores nodes in the initial file tree under a token budget. It combines filename matches, depth priors, and extension/type priors, then selects a subtree-closed context so selected files keep directory context.
- For credit assignment, A3 parses each shell command with Tree-sitter, linearizes the AST, and compares action signatures with normalized Levenshtein distance. This gives the RL algorithm a way to compare command intent without asking an LLM judge.
- A3 fuses three advantage channels: an episode backbone comparing sibling rollouts for the same prompt, a turn-level residual comparing structurally similar commands at the same turn, and a tree-level margin comparing abstract branches through the trajectory. The fused advantage then goes into a clipped PPO-style sequence loss.
Exact-match evidence from the mixed benchmark.
| Method | AB-OS string | AB-DB string | DataBench string | EHRCon string | ShellOps string | TableBench files | AB-DB hybrid | ShellOps files | ShellOps hybrid |
|---|---|---|---|---|---|---|---|---|---|
| ReACT | 57.9 | 15.1 | 63.7 | 61.5 | 26.0 | 18.7 | 37.8 | 7.1 | 7.2 |
| GSPO | 61.4 | 12.6 | 70.1 | 45.6 | 25.5 | 24.8 | 43.5 | 10.9 | 11.3 |
| GiGPO | 54.5 | 9.5 | 56.8 | 59.3 | 24.0 | 23.5 | 37.8 | 11.3 | 10.1 |
| RetroAgent | 49.0 | 13.8 | 68.5 | 57.0 | 19.5 | 25.0 | 42.6 | 8.2 | 9.7 |
| A3, vanilla | 58.6 | 23.6 | 74.1 | 66.7 | 46.5 | 30.7 | 46.6 | 26.5 | 21.9 |
| A3 + sigma-Reveal | 60.7 | 26.2 | 77.9 | 67.4 | 48.5 | 31.6 | 46.4 | 25.7 | 24.6 |
The most meaningful numbers are on ShellOps, where the agent must combine terminal output and file-state changes. A3 + sigma-Reveal reaches 48.5 on ShellOps string tasks and 24.6 on ShellOps hybrid tasks; the strongest non-A3 rows in this slice are 27.5 and 11.3. That does not mean the method solves CLI agents, but it does show that action-structure credit is doing work where the environment is truly workspace-shaped.
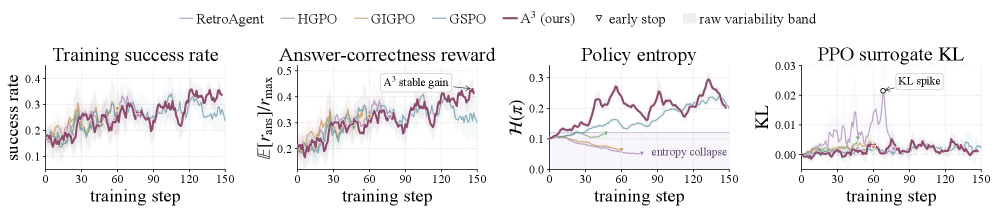
The diagnostics are useful because RL papers can hide instability behind final scores. A3 keeps surrogate KL more stable while reward rises, whereas several baselines show delayed KL spikes, entropy collapse, or plateaus. I read this as evidence for a cleaner update signal, not as proof that the same recipe will remain stable on GUI or browser agents.
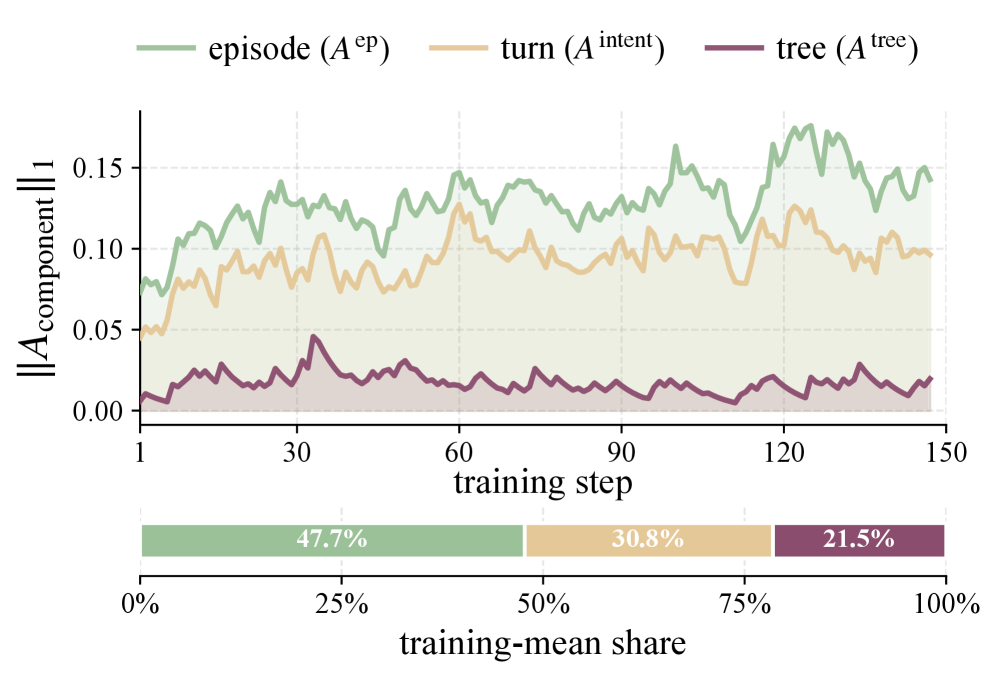
This ablation figure shows why the three credit channels should not be collapsed into one outcome score. The paper reports post-weighting contribution shares of 47.7% from the episode backbone, 30.8% from turn-level action residuals, and 21.5% from the tree advantage. The right panel is also a cost sanity check: the method tries to stay near standard agentic RL cost rather than introducing a slow LLM-judge credit loop.
Why I care: this is a clean answer to a problem I keep running into with coding agents. The shell trace is not just a log for humans; it is a structured object for training. If action credit can be computed from bash syntax and rollout returns, then agents can learn from many repository tasks without turning every step into a judged natural-language explanation.
Limitations/questions: the authors are explicit that AST structure is only a proxy. grep foo a.txt and grep foo b.txt can have the same form and completely different value. sigma-Reveal is also a lightweight prior, not a full evidence searcher. My next question is whether this credit assignment survives richer environments where the action syntax is less informative than the state transition: browsers, GUI apps, remote services, and notebooks.
Connection to tracked themes: agentic training, coding agents, data-agent workspaces, trace-level credit assignment.
Tool Calling is Linearly Readable and Steerable in Language Models
Authors: Zekun Wu, Ze Wang, Seonglae Cho, Yufei Yang, Adriano Koshiyama, Sahan Bulathwela, Maria Perez-Ortiz.
Institutions: University College London; Holistic AI; Imperial College London.
Date/Venue: May 8, 2026, arXiv preprint.
Links: arXiv | HTML
The overview gives the paper’s main claim: the model’s chosen tool can be redirected by adding a mean-difference vector in activation space, and the following JSON arguments often adapt to the newly selected tool. This is not a tool-use training paper. It is closer to a mechanism paper for a specific agent failure mode: wrong tool selection before execution.
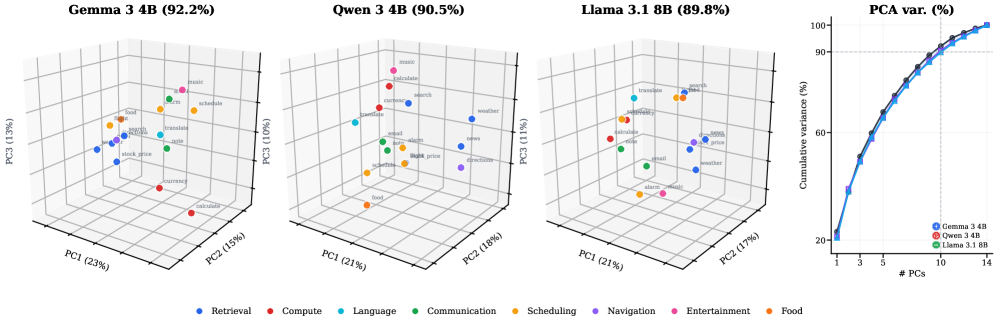
The PCA figure shows that tool activations are geometrically organized, but I would read it carefully. The authors themselves note that matched non-tool prompts can also compress well, so the safe claim is not “tool identity lives in a uniquely tiny subspace.” The safer and more useful claim is that tool identity has a linear representation that can be read and intervened on.
Quick idea: for fixed-menu single-turn tool calls, the selected tool is linearly encoded inside the model strongly enough to predict, steer, and sometimes flag mistakes before the call is emitted.
Why it matters: tool-call failures are often silent until the external action happens. A model can send an email, create a calendar event, call the wrong API endpoint, or run the wrong command while producing perfectly valid JSON. If the tool choice is readable before decoding completes, an agent runtime could monitor uncertainty or apply guardrails before the action reaches the outside world.
Method walkthrough:
- Build prompts with tool definitions and user queries. The paper tests Gemma 3, Qwen 3, Qwen 2.5, and Llama 3.1 instruction-tuned models from 270M to 27B, plus several base variants.
- For each tool, collect average residual-stream activations from a few example queries. A source-to-target steering vector is the mean activation of the target tool minus the mean activation of the source tool.
- Add that vector during generation and test whether the model emits the target tool. The paper checks name-only tools, real APIs from tau-bench, ToolBench, BFCL v3, anonymous-name controls, list-order controls, matched-prompt controls, SAE features, and activation patching.
- Use the same geometry for monitoring. If the cosine gap between the top-1 and top-2 tool directions is small, the model is more likely to choose wrongly.
Key results I would keep on one page.
| Check | Reported result | What it supports |
|---|---|---|
| Name-only steering, 4B+ instruction-tuned models | 93-100% | Tool choice is highly steerable in the controlled fixed-menu setting |
| Five-tool pairwise switching | 60/60 trials, 100%, 95% CI [94, 100] | The effect is not limited to one favorite tool pair |
| 15-tool steering across model families | Mean accuracy rises from 17% at 270M to 89% at 27B | Scale and instruction tuning sharpen the representation |
| Within-topic tau-bench airline probe | 61-89% top-1 across five 4B-14B models | The signal is not only a broad topic axis |
| BFCL base-model readout | 69-82% readout while base generation is 2-10% | Pretraining can encode tool identity before instruction tuning wires it to output |
| Error-risk gap | Gemma 3 12B lowest-gap quartile has 14% error vs. 0% in highest; Gemma 3 27B has 17% vs. 1% | The representation can act as a pre-action warning signal |
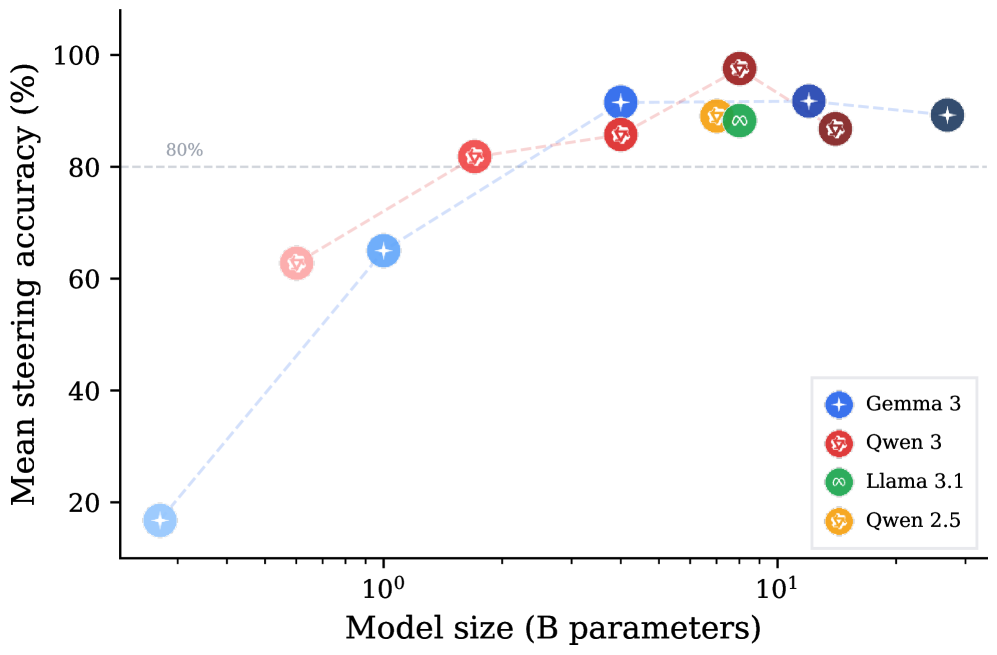
This scale plot is one of the most practical visuals. Below about 1B parameters the intervention is weak, while larger instruction-tuned models become much easier to steer. That matters for deployment: a representation monitor built on this idea may not transfer cleanly to very small local agents.
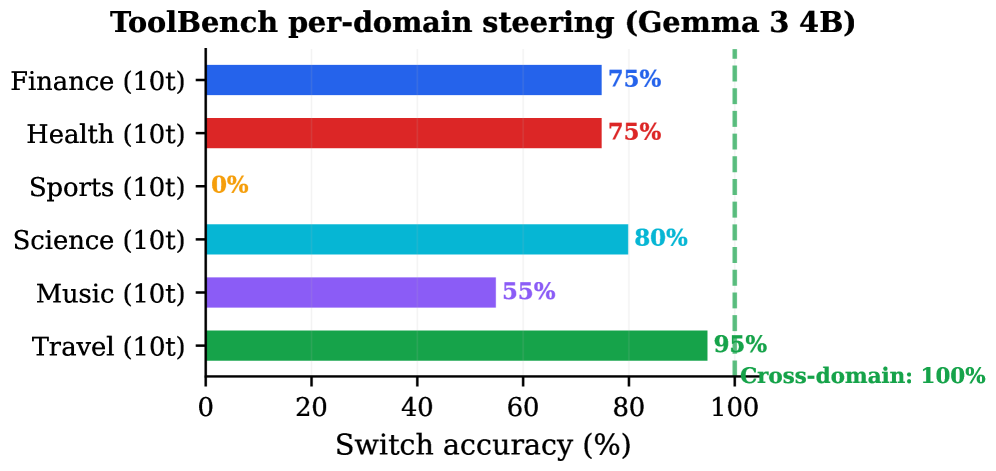
This figure shows that the method is not uniformly strong across real API domains. The paper notes that sports tools are hard because several tools are near-synonymous. That is the right caveat for product systems: a clean linear direction may separate “weather” from “email,” but not necessarily two similar billing, calendar, or CRM operations with overlapping schemas.
Why I care: I like this paper because it gives an internal handle for a very mundane agent risk. Most tool-use guardrails watch the JSON after the model has already committed. Here the model’s hidden state contains a usable early signal. I would not trust steering as an automatic fix yet, but I would absolutely test the top-1/top-2 activation gap as a logging and approval feature.
Limitations/questions: the paper is intentionally scoped to single-turn fixed-menu tool selection and JSON schema correctness. Multi-turn transfer is more fragile. The intervention also does not understand downstream side effects by itself; it can switch a tool name, but it cannot decide whether sending an email is allowed. My next question is whether activation-gap alarms stay calibrated when the tool list changes dynamically, tool descriptions are long, and the model has retrieved user-specific context.
Connection to tracked themes: large model mechanisms, tool agents, pre-action audit signals, agent safety.
MASPrism: Lightweight Failure Attribution for Multi-Agent Systems Using Prefill-Stage Signals
Authors: Yang Liu, Hongjiang Feng, Junsong Pu, Zhuangbin Chen.
Institutions: Sun Yat-sen University.
Date/Venue: May 8, 2026, arXiv preprint / ASE 2026 listed in manuscript metadata.
Links: arXiv | HTML
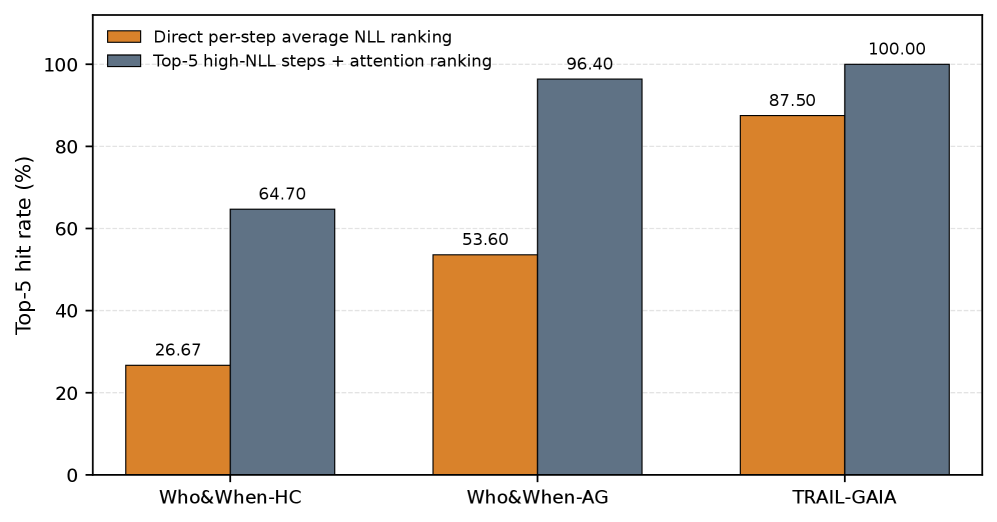
This figure motivates the whole method. Directly ranking steps by local negative log-likelihood is not enough, and attention-based ranking from high-NLL symptom steps does better at retrieving likely source steps. The visual supports a modest claim: internal prefill signals can route attention toward suspicious upstream steps. It does not prove causality.
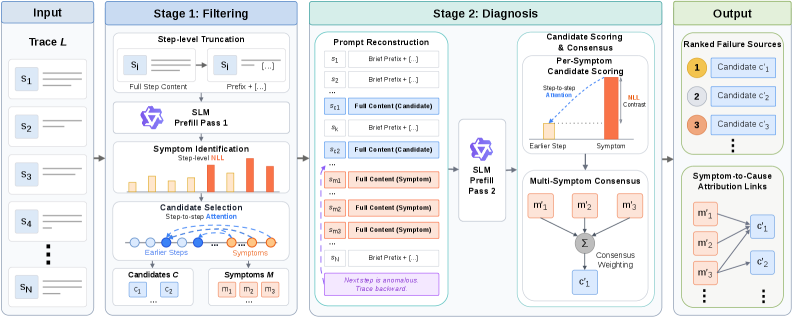
The framework has two passes. First, Filtering keeps a prefix of every trace step, uses NLL to identify symptom-like steps, and uses attention from those symptoms to select earlier candidates. Then Diagnosis restores full content for symptom and candidate steps, recomputes the signals, and ranks likely failure sources. I like that this uses no output tokens; the diagnostic model is used as a sensor, not as a verbose judge.
Quick idea: MASPrism turns the prefill stage of a small language model into a failure-attribution tool for long multi-agent traces.
Why it matters: multi-agent systems fail in an annoying way. The visible bad output may appear many steps after the actual mistake, and replaying or asking a large judge to read the whole trace is expensive. A practical debugging layer needs to narrow the trace before a human or a stronger model spends attention on it.
Method walkthrough:
- Represent a failed execution as a sequence of agent steps. Filtering creates a truncated trace by keeping a bounded prefix of every step, preserving global flow instead of dropping either the beginning or the end.
- During the first prefill pass, compute step-level negative log-likelihood as the average token NLL inside each step. High NLL marks symptoms: places where the trace becomes surprising to the small model.
- Aggregate step-to-step attention from symptom steps to earlier steps. The top earlier steps become candidate failure sources.
- Reconstruct a second prompt: symptom and candidate steps are restored in full, while other steps stay compressed. A second prefill pass recomputes NLL and attention, then scores candidates with attention normalized by symptom attention mass and a directional NLL contrast. A multi-symptom consensus factor boosts candidates repeatedly surfaced by different symptoms.
Diagnosis and efficiency evidence.
| Method | Model | Who&When HC Top-1 | Who&When AG Top-1 | TRAIL GAIA loc. acc. | TRAIL SWE-bench loc. acc. |
|---|---|---|---|---|---|
| MASPrism | Qwen3-0.6B | 27.59 | 36.51 | 0.591 | 0.451 |
| All-at-once | GPT-4o | 3.51 | 13.53 | not reported | not reported |
| Step-by-step | GPT-4o | 8.77 | 15.31 | not reported | not reported |
| Binary search | GPT-4o | 6.90 | 16.59 | not reported | not reported |
| A2P | GLM-5.1 | 20.68 | 43.65 | not reported | not reported |
| AgenTracer | Qwen3-8B + RL | 20.68 | 37.30 | not reported | not reported |
| TRAIL prompted judge | OpenAI o3 | not reported | not reported | 0.535 | context too long |
| TRAIL prompted judge | Gemini-2.5-Pro | not reported | not reported | 0.546 | 0.238 |
MASPrism is not the best row everywhere; A2P is stronger on the shorter AG split. The interesting part is the long-trace behavior. On Who&When-HC, which averages 51.60 steps, MASPrism beats the listed baselines despite using Qwen3-0.6B. On TRAIL SWE-bench, several prompted-judge baselines hit context limits, while the two-pass reduction keeps MASPrism executable.
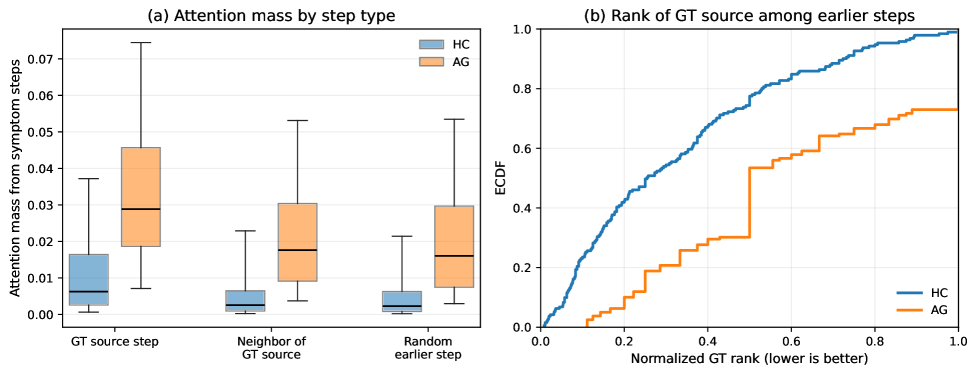
This figure checks whether symptom-step attention actually points upstream. Ground-truth source steps receive more attention mass than neighboring source steps and random earlier steps, and the ECDF shows many source steps ranked near the top among earlier candidates. The authors frame this correctly as diagnostic evidence, not a formal causal estimate.
Ablation and cost slice.
| Variant / method | HC Top-1 | AG Top-1 | GAIA loc. acc. | SWE loc. acc. | Latency | Input tokens | Output tokens |
|---|---|---|---|---|---|---|---|
| MASPrism | 27.59 | 36.51 | 0.591 | 0.451 | 2.66 s | 7,066 | 0 |
| w/o Diagnosis | 5.17 | 33.33 | 0.511 | 0.381 | not listed | not listed | not listed |
| w/o Prompt Restoration | 5.17 | 35.71 | 0.575 | 0.397 | not listed | not listed | not listed |
| w/o Filtering | 6.90 | 33.33 | 0.222 | 0.384 | not listed | not listed | not listed |
| A2P | not listed | not listed | not listed | not listed | 17.82 s | 17,748 | 620 |
The ablation is the reason I would take the architecture seriously. Filtering alone is not precise enough on long traces, and direct no-filter attribution loses stability. The second pass matters because it restores full details only where they are likely to matter.
Why I care: this is close to how I want production agent logs to work. First pass: cheap sensor over the whole trace. Second pass: restore and inspect the suspicious spans. Human or stronger model: only then read the narrowed evidence. It is less glamorous than a new multi-agent planner, but it addresses the maintenance problem that appears after agents are deployed.
Limitations/questions: MASPrism uses NLL and attention as routing signals, not causal proof. A high-ranked step should be inspected, not automatically blamed. The next hard question is calibration: how often does the top candidate waste a human’s time, and can the score be turned into a reliable triage threshold across successful, failed, and ambiguous traces?
Connection to tracked themes: multi-agent debugging, trace diagnosis, document/log intelligence, lightweight audit layers.
Reading Priority and Next Questions
My priority order is A3 first, tool-calling mechanisms second, MASPrism third. A3 has the most direct training signal for coding and data agents. The tool-calling paper is the most immediately useful for pre-action monitoring. MASPrism is the most operational: it says a small diagnostic model can cheaply point at the part of a long trace worth reading.
Next I would watch three lines. First, can CLI credit assignment transfer from bash-heavy tasks to browser, notebook, and GUI actions where syntax is weaker? Second, can activation-gap alarms for tool selection be calibrated under dynamic tool catalogs and user-specific context? Third, can trace diagnosis be evaluated by reduction in human debugging time, not only source-step top-1 accuracy?