在智能体失败之前读懂执行轨迹
Published:
TL;DR:本期看的是智能体轨迹如何成为训练和诊断对象。A3 用 shell 命令结构给 CLI 智能体做逐步 credit assignment,而不是只看整条轨迹成败。Tool Calling 论文发现,模型内部的工具选择可以线性读出和干预,错误工具调用在 JSON 输出前就有信号。MASPrism 则用小模型 prefill 阶段的 NLL 和 attention,在长多智能体日志里定位可能的失败源头,而且不需要生成诊断长文。
本期我在看什么
最近几期 Paper Radar 已经反复写了很多“可见状态”:技能、计划、引用、activation、GUI 坐标、spreadsheet sheet。这个方向仍然重要,但我不想再写一篇同义的“让状态可检查”。这次 5 月 8 的几篇新论文把问题推进到更操作层:智能体已经留下了执行轨迹,我们能不能用这条轨迹训练下一次行动、在行动前读出风险、或者在失败后更快定位源头?
我从 arXiv、Hugging Face Papers、中文科技媒体、社区链接和 lab blog 里做了 24 小时到 3 天窗口的初筛。候选包括 CA-SQL、The Memory Curse、Rubric-Grounded RL、latent planning probe、AI Co-Mathematician、AutoTTS、HyperEyes、InterLV-Search、Skill1、A2TGPO、world-action model 的自适应执行、MiA-Signature、EMO 和若干 tool-use 诊断论文。最后只保留三篇,因为它们都能开放阅读全文,有足够清楚的图表,而且主题能连成一条线:训练执行中的 agent、读出工具调用前的模型状态、诊断执行失败后的多智能体日志。
论文细读笔记
Learning CLI Agents with Structured Action Credit under Selective Observation
作者:Haoyang Su, Ying Wen。
机构:复旦大学;上海创新研究院;上海交通大学。
日期/场合:2026 年 5 月 8 日,arXiv preprint。
链接:arXiv | HTML | code
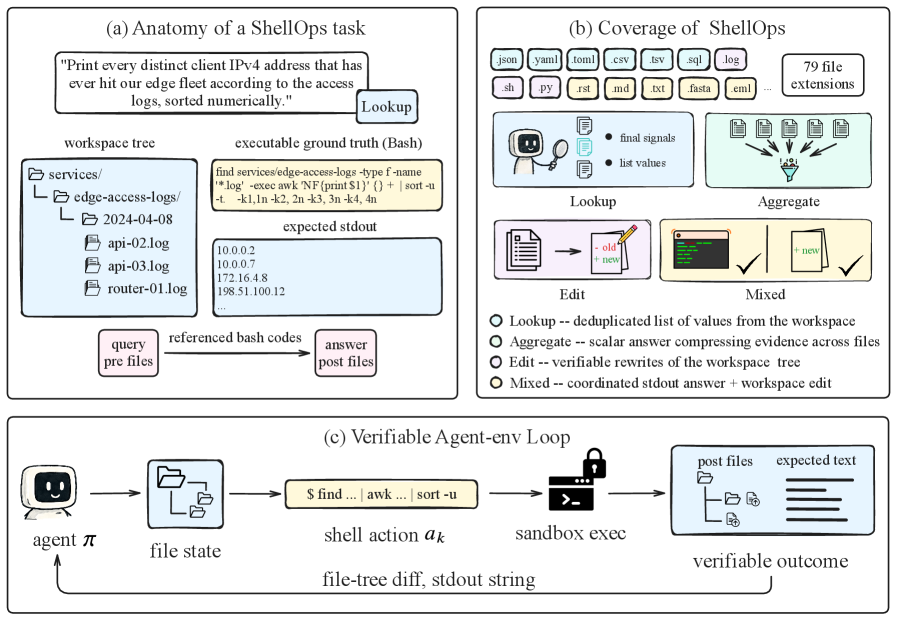
这张图定义了论文里的环境:CLI 智能体接收自然语言任务,面对一个文件系统,执行 shell 命令,最后由终端输出或文件状态的可执行检查打分。关键是动作空间不是整齐的 API 菜单,而是 bash、目录、日志、配置、表格和生成文件。这让它比单次 tool call benchmark 更接近真实 coding agent 和 data agent 的工作场景。
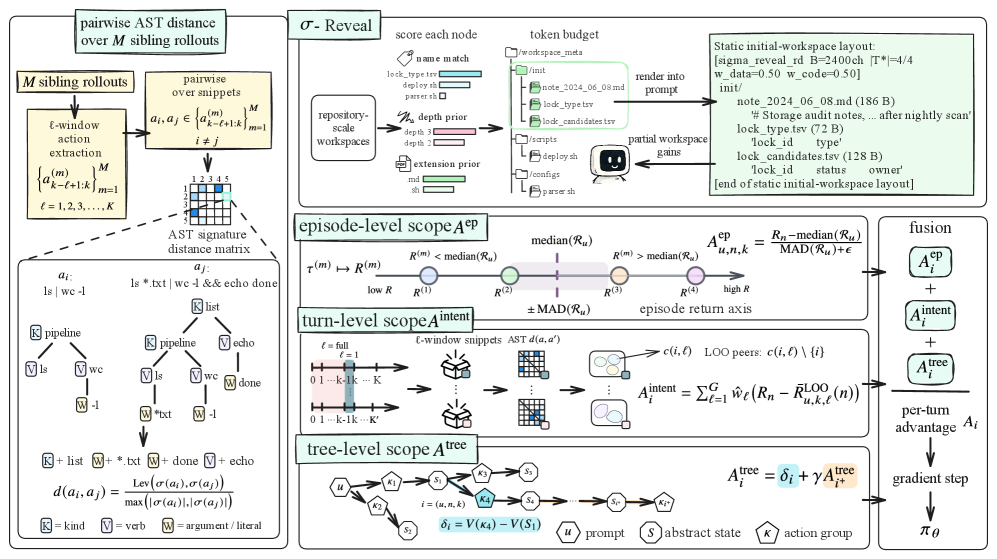
这张算法图是理解 A3 的入口。shell 命令先被转成 AST signature,结构相似的动作被放在一起比较,最后 episode、turn 和 tree 三种 credit 信号被融合成逐步 advantage。需要谨慎的是,AST 相似性只是动作意图的代理:两个命令语法很像,但如果路径、文件内容或先前状态不同,实际效果可能完全不同。
一句话核心 idea:这篇论文把 CLI agent 训练看成 executable shell trace 上的延迟 credit assignment 问题,用命令结构和选择性 workspace context 让奖励信号不再只停留在整条轨迹成败上。
为什么重要:coding agent 或 data agent 的失败可能来自没看到相关文件、检查命令选错、也可能是早期正确动作被后面的错误掩盖。普通 episode-level RL 只看到最终分数,很难知道哪一步该被强化。A3 的问题是:shell 命令本身的结构能不能帮模型判断哪一步真正贡献了成功或失败?
方法拆解:
- 作者构造 ShellOps,把 shell 驱动的信息抽取和文件编辑任务统一成可验证环境。标准 corpus 有 1,624 个任务,ShellOps-Pro 额外包含 150 个更难的 OOD 任务,涉及 4,063 个文件,平均每个任务 27.1 个文件,覆盖 42 种可读文本扩展名。
- 对部分可观测问题,sigma-Reveal 在 token budget 下为初始文件树节点打分。它综合文件名是否命中任务文本、目录深度先验、文件扩展名和任务类型的匹配度,然后选择 subtree-closed 的上下文,避免只给模型孤立文件而丢失目录语境。
- 对 credit assignment,A3 用 Tree-sitter 解析 shell 命令,把 AST 线性化成 signature,并用归一化 Levenshtein 距离比较动作结构。这样 RL 可以比较命令意图,而不必让 LLM judge 给每一步打分。
- A3 融合三条 advantage:同一 prompt 下 sibling rollout 的 episode backbone、同一 turn 里结构相似命令的 residual、以及基于抽象轨迹分支的 tree margin。融合后的 advantage 进入 clipped PPO 风格的 sequence loss。
mixed benchmark 上的 exact match 证据。
| 方法 | AB-OS string | AB-DB string | DataBench string | EHRCon string | ShellOps string | TableBench files | AB-DB hybrid | ShellOps files | ShellOps hybrid |
|---|---|---|---|---|---|---|---|---|---|
| ReACT | 57.9 | 15.1 | 63.7 | 61.5 | 26.0 | 18.7 | 37.8 | 7.1 | 7.2 |
| GSPO | 61.4 | 12.6 | 70.1 | 45.6 | 25.5 | 24.8 | 43.5 | 10.9 | 11.3 |
| GiGPO | 54.5 | 9.5 | 56.8 | 59.3 | 24.0 | 23.5 | 37.8 | 11.3 | 10.1 |
| RetroAgent | 49.0 | 13.8 | 68.5 | 57.0 | 19.5 | 25.0 | 42.6 | 8.2 | 9.7 |
| A3, vanilla | 58.6 | 23.6 | 74.1 | 66.7 | 46.5 | 30.7 | 46.6 | 26.5 | 21.9 |
| A3 + sigma-Reveal | 60.7 | 26.2 | 77.9 | 67.4 | 48.5 | 31.6 | 46.4 | 25.7 | 24.6 |
最值得看的不是所有格子,而是 ShellOps。这里 agent 要同时处理终端输出和文件状态改变。A3 + sigma-Reveal 在 ShellOps string 上到 48.5,在 ShellOps hybrid 上到 24.6;同一切片里最强非 A3 方法分别只有 27.5 和 11.3。这不能说明 CLI agent 已经解决,但能说明结构化动作 credit 在真正 workspace 形态的任务里有作用。
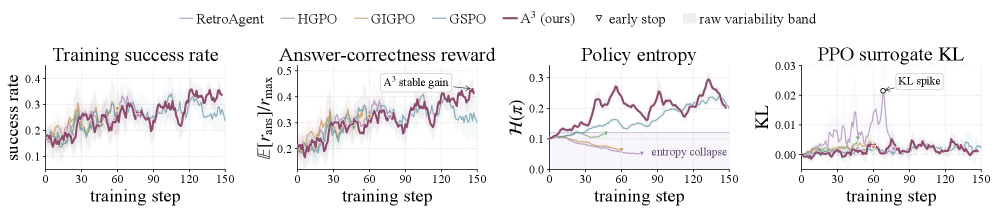
训练诊断图很重要,因为 RL 论文很容易用最终分数掩盖不稳定。A3 在 reward 上升时保持了更稳定的 surrogate KL,而若干 baseline 出现延迟 KL spike、entropy collapse 或 reward plateau。我会把它理解成更新信号更干净,而不是证明它能无缝迁移到 GUI 或浏览器智能体。
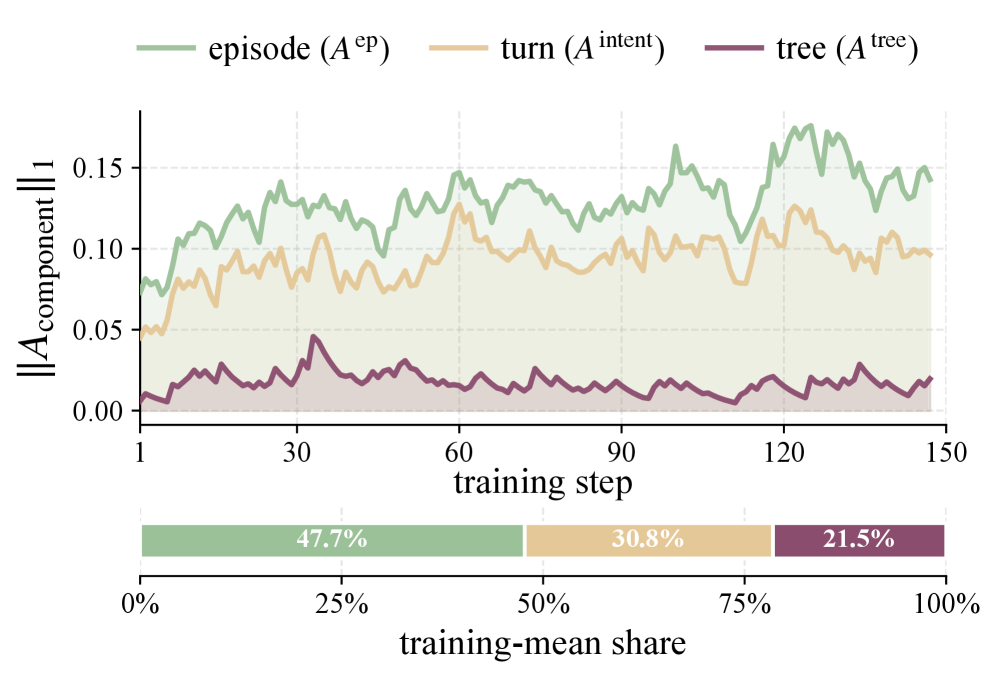
这张消融图说明三条 credit 信号不能简单合并成一个 outcome score。论文报告 episode backbone、turn-level action residual、tree advantage 在 post-weighting 之后的贡献占比分别是 47.7%、30.8% 和 21.5%。右侧的成本图也有价值:A3 试图接近标准 agentic RL 成本,而不是引入一个很慢的 LLM-judge credit loop。
我的判断:我会优先看这篇,因为它回答了 coding agent 训练里很实际的一个问题。shell trace 不只是人类事后看的 log,也可以是训练算法直接消费的结构化对象。如果命令语法和 rollout return 足够给出逐步 credit,我们就能从大量 repository task 中学习,而不必把每一步都改写成自然语言解释再交给 judge。
局限和问题:作者也明确说 AST 结构只是 proxy。grep foo a.txt 和 grep foo b.txt 形式一样,价值可能完全不同。sigma-Reveal 也是轻量 workspace prior,不是充分证据搜索。下一步我最关心的是:当环境变成浏览器、GUI、远程服务或 notebook,动作语法不再像 bash 那么有信息量时,这套 credit assignment 还能剩多少?
关联主题:agentic training、coding agent、data-agent workspace、trace-level credit assignment。
Tool Calling is Linearly Readable and Steerable in Language Models
作者:Zekun Wu, Ze Wang, Seonglae Cho, Yufei Yang, Adriano Koshiyama, Sahan Bulathwela, Maria Perez-Ortiz。
机构:University College London;Holistic AI;Imperial College London。
日期/场合:2026 年 5 月 8 日,arXiv preprint。
链接:arXiv | HTML
总览图给出了论文的核心 claim:在 activation space 里加入 mean-difference vector,可以把模型选择的工具从一个方向推向另一个方向,而且后续 JSON 参数往往会自动适配新工具 schema。这不是训练 tool-use 的论文,更像是一个针对“选错工具”这种智能体故障的机制研究。
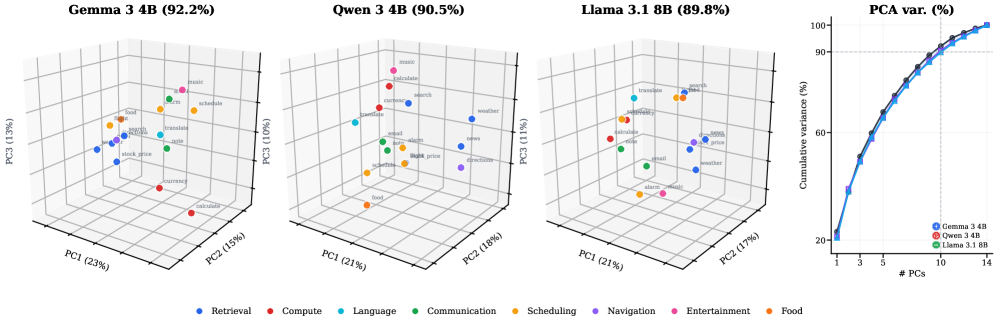
PCA 图显示 tool activation 有几何组织,但这里不能过度解读。作者自己也提醒,matched non-tool prompts 也可能压缩得很好,所以稳妥说法不是“工具身份独占一个极小子空间”。更可靠的结论是:工具身份有线性表示,而且这个表示可以被读出和干预。
一句话核心 idea:在固定工具菜单、单轮 tool call 设置下,模型内部的工具选择有足够强的线性编码,可以在调用发出前被预测、steer,并在某些情况下提示错误风险。
为什么重要:tool call 错误经常在外部动作发生之后才暴露。模型可以发错邮件、建错日程、调用错 API endpoint、运行错命令,同时 JSON 格式完全合法。如果工具选择能在 decoding 完成前读出,agent runtime 就有机会在动作出界之前做监控、审批或拦截。
方法拆解:
- 构造包含工具定义和用户 query 的 prompt。论文测试 Gemma 3、Qwen 3、Qwen 2.5、Llama 3.1,从 270M 到 27B 的 instruction-tuned 模型,也包含若干 base variant。
- 对每个工具,从少量 example query 中收集 residual stream activation 的平均值。source-to-target steering vector 就是目标工具 mean activation 减去源工具 mean activation。
- 在生成时加入这个 vector,测试模型是否输出目标工具。论文检查了 name-only tools、tau-bench、ToolBench、BFCL v3、匿名工具名控制、列表顺序控制、matched-prompt 控制、SAE features 和 activation patching。
- 用同一套几何结构做风险监控。如果 top-1 和 top-2 工具方向之间的 cosine gap 很小,模型更可能选错工具。
我会保留在一页里的关键结果。
| 检查 | 论文报告结果 | 支撑的判断 |
|---|---|---|
| 4B+ instruction-tuned 模型的 name-only steering | 93-100% | 固定菜单设置下工具选择高度可干预 |
| 五工具 pairwise switching | 60/60 trials, 100%, 95% CI [94, 100] | 效果不是某一对工具的偶然现象 |
| 15 工具跨模型家族 steering | 平均准确率从 270M 的 17% 升到 27B 的 89% | scale 和 instruction tuning 会强化表示 |
| tau-bench airline 同领域 probe | 五个 4B-14B 模型 top-1 为 61-89% | 信号不只是粗粒度 topic axis |
| BFCL base-model readout | readout 69-82%,base generation 只有 2-10% | pretraining 已有工具身份表示,instruction tuning 负责接到输出 |
| 错误风险 gap | Gemma 3 12B 最小 gap 四分位 error 14%,最大 gap 为 0%;Gemma 3 27B 为 17% vs. 1% | activation gap 可以作为调用前预警 |
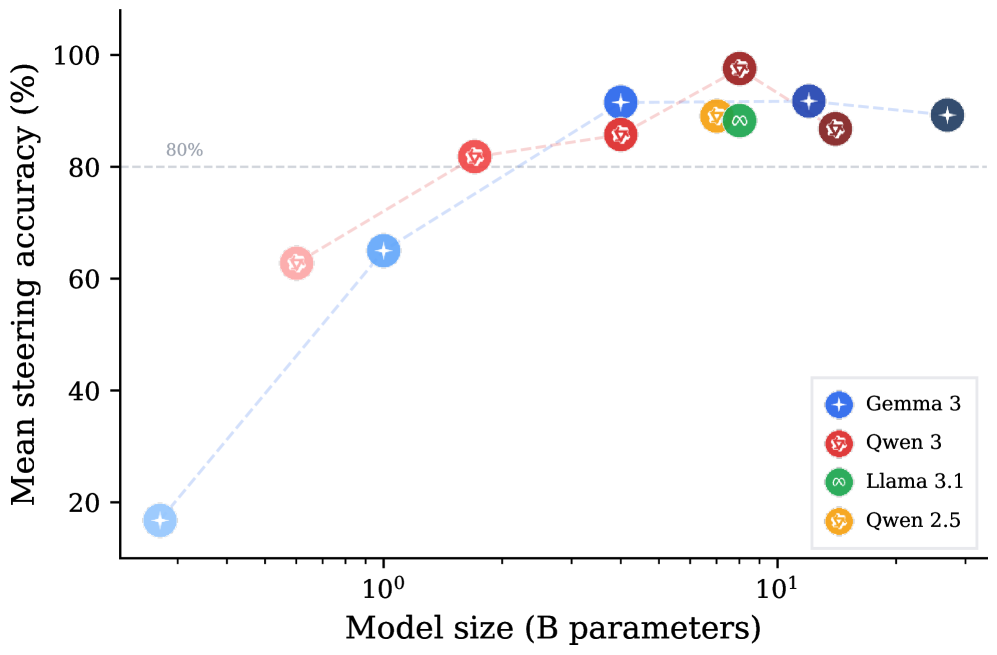
这张 scale 图很实用。1B 以下模型的干预效果较弱,较大的 instruction-tuned 模型更容易被 steer。部署上这意味着,基于表示的工具调用监控未必能直接迁移到很小的本地 agent。
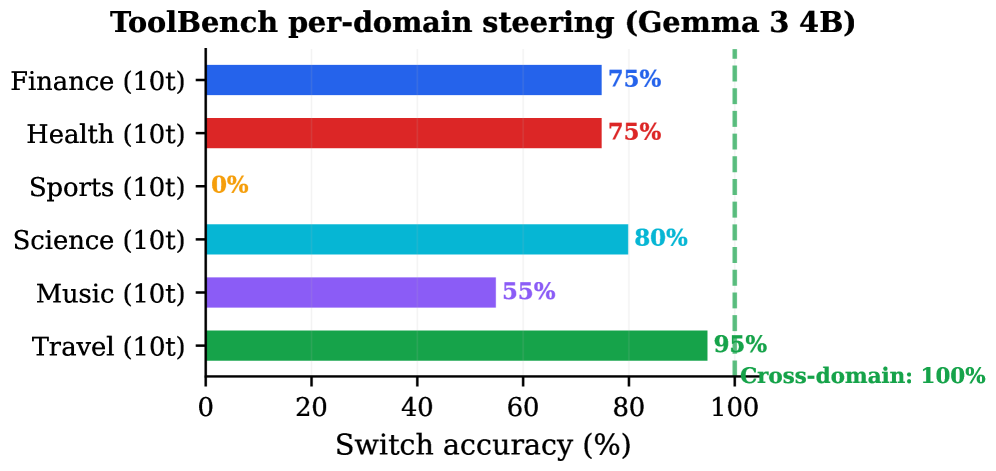
这张图提醒我们真实 API domain 里效果并不均匀。论文提到 sports domain 难,是因为多个工具语义非常接近。产品系统也会遇到类似问题:区分 weather 和 email 可能很容易,区分两个相似的 billing、calendar 或 CRM 操作就未必。
我的判断:我喜欢这篇,是因为它给了一个非常日常的 agent 风险一个内部 handle。大多数 tool-use guardrail 看的是模型已经承诺后的 JSON;这里模型 hidden state 里有更早的信号。我还不会把 steering 当成自动修复,但我会很想把 top-1/top-2 activation gap 做成日志字段和审批触发条件。
局限和问题:论文刻意限定在单轮、固定工具菜单、JSON schema correctness。多轮 agent 的迁移更脆弱。这个 intervention 本身也不理解外部副作用:它可以换工具名,但不能判断“发邮件”是否被允许。下一步问题是,当工具列表动态变化、工具描述很长、模型还检索了用户上下文时,activation-gap alarm 还能否校准?
关联主题:大模型机理、tool agent、行动前审计信号、agent safety。
MASPrism: Lightweight Failure Attribution for Multi-Agent Systems Using Prefill-Stage Signals
作者:Yang Liu, Hongjiang Feng, Junsong Pu, Zhuangbin Chen。
机构:中山大学。
日期/场合:2026 年 5 月 8 日,arXiv preprint;稿件元数据列出 ASE 2026。
链接:arXiv | HTML
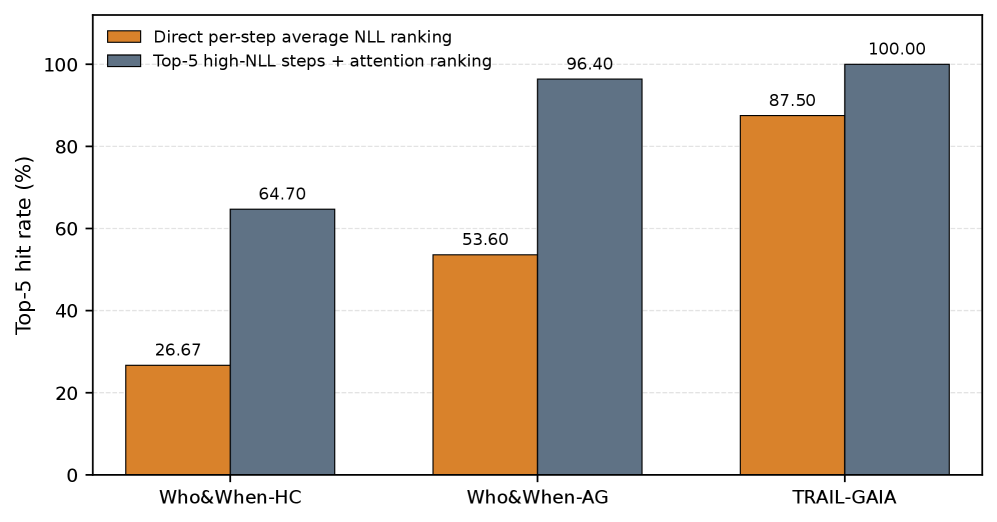
这张图解释了为什么需要 MASPrism。只按局部 NLL 排序不够好;从高 NLL symptom step 出发看 attention,更能找回可能的上游 source step。它支撑的是一个温和但有用的 claim:prefill 内部信号可以把排查范围路由到可疑的上游步骤。它不等于因果证明。
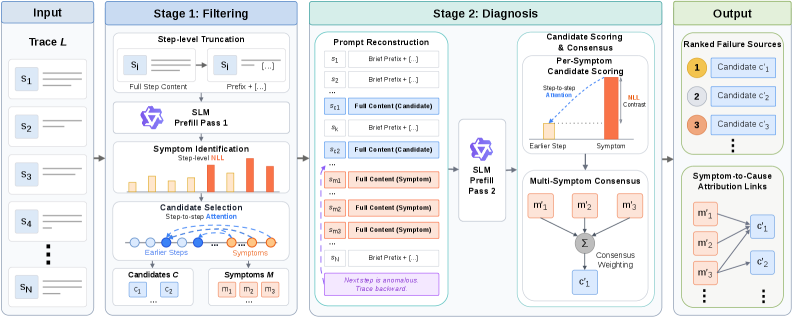
框架分两次 prefill。第一次 Filtering 保留每个 trace step 的前缀,用 NLL 找 symptom-like steps,再用这些 symptom 对前文的 attention 选择候选源头。第二次 Diagnosis 恢复 symptom 和 candidate steps 的完整内容,重新计算信号并排序。我觉得最有意思的是它不生成 output tokens:诊断模型被当作传感器,而不是话很多的 judge。
一句话核心 idea:MASPrism 把小语言模型的 prefill 阶段变成一个长多智能体轨迹的失败归因工具。
为什么重要:多智能体系统的失败很麻烦。最后可见的坏结果可能比真正错误晚很多步出现;重放执行或让大模型 judge 读完整日志都很贵。实用的 debug layer 应该先缩小范围,再让人或更强模型阅读证据。
方法拆解:
- 把失败执行表示成 agent steps 序列。Filtering 先构造截断版 trace:每一步保留固定长度前缀,从而保住全局执行流,而不是只截头或截尾。
- 第一次 prefill 里,计算 step-level NLL,也就是每个 step 内 token NLL 的平均值。高 NLL 标记 symptom:模型觉得这里的轨迹变得异常或难预测。
- 从 symptom steps 聚合到更早步骤的 step-to-step attention。被多个 symptom 注意到的早期步骤进入 candidate set。
- 第二次重建 prompt:symptom 和 candidate steps 恢复完整内容,其余步骤继续压缩。第二次 prefill 后用 attention 和方向性 NLL contrast 给候选源头打分,再用 multi-symptom consensus 提升被多个 symptom 重复指向的步骤。
诊断效果和效率证据。
| 方法 | 模型 | Who&When HC Top-1 | Who&When AG Top-1 | TRAIL GAIA loc. acc. | TRAIL SWE-bench loc. acc. |
|---|---|---|---|---|---|
| MASPrism | Qwen3-0.6B | 27.59 | 36.51 | 0.591 | 0.451 |
| All-at-once | GPT-4o | 3.51 | 13.53 | 未报告 | 未报告 |
| Step-by-step | GPT-4o | 8.77 | 15.31 | 未报告 | 未报告 |
| Binary search | GPT-4o | 6.90 | 16.59 | 未报告 | 未报告 |
| A2P | GLM-5.1 | 20.68 | 43.65 | 未报告 | 未报告 |
| AgenTracer | Qwen3-8B + RL | 20.68 | 37.30 | 未报告 | 未报告 |
| TRAIL prompted judge | OpenAI o3 | 未报告 | 未报告 | 0.535 | context too long |
| TRAIL prompted judge | Gemini-2.5-Pro | 未报告 | 未报告 | 0.546 | 0.238 |
MASPrism 并不是所有地方最强;短一些的 AG split 上 A2P 更高。真正有意思的是长轨迹表现。Who&When-HC 平均 51.60 步,MASPrism 用 Qwen3-0.6B 仍然超过列出的几类 baseline。TRAIL SWE-bench 上,一些 prompted judge baseline 会撞 context limit,而两阶段压缩让 MASPrism 还能运行。
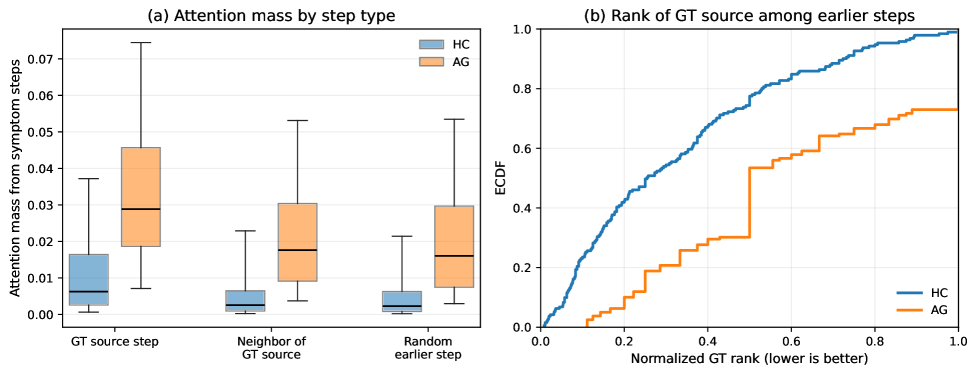
这张图检查 symptom-step attention 是否真的指向上游。ground-truth source steps 收到的 attention mass 高于相邻 source step 和随机早期 step;ECDF 也显示很多 source step 会在候选排序中靠前。作者把它定位为诊断证据,而不是形式化因果估计,这个边界很重要。
消融和成本切片。
| 变体 / 方法 | HC Top-1 | AG Top-1 | GAIA loc. acc. | SWE loc. acc. | 延迟 | 输入 tokens | 输出 tokens |
|---|---|---|---|---|---|---|---|
| MASPrism | 27.59 | 36.51 | 0.591 | 0.451 | 2.66 s | 7,066 | 0 |
| w/o Diagnosis | 5.17 | 33.33 | 0.511 | 0.381 | 未列出 | 未列出 | 未列出 |
| w/o Prompt Restoration | 5.17 | 35.71 | 0.575 | 0.397 | 未列出 | 未列出 | 未列出 |
| w/o Filtering | 6.90 | 33.33 | 0.222 | 0.384 | 未列出 | 未列出 | 未列出 |
| A2P | 未列出 | 未列出 | 未列出 | 未列出 | 17.82 s | 17,748 | 620 |
这个消融是我愿意认真看这篇的原因。只做 Filtering 在长轨迹上不够精确,直接不做 Filtering 又会丢失稳定性。第二次 prefill 的意义在于:只恢复最可能有用的步骤细节,而不是让模型重新吞下整条日志。
我的判断:这篇很接近我希望生产 agent log 具备的形态。第一层是便宜的全局传感器;第二层只恢复可疑片段;人或更强模型最后再读缩小后的证据。它没有新的多智能体规划器那么显眼,但它解决的是 agent 部署后一定会碰到的维护问题。
局限和问题:MASPrism 用 NLL 和 attention 做 routing,不是给出因果判决。高排名步骤应该被检查,不该被自动定罪。下一步最难的是校准:top candidate 多大概率会浪费人的排查时间?这个分数能否变成跨成功、失败、模糊轨迹都可靠的 triage threshold?
关联主题:multi-agent debugging、trace diagnosis、文档/日志智能、轻量审计层。
阅读优先级和下期问题
我的阅读优先级是 A3 第一,tool-calling mechanism 第二,MASPrism 第三。A3 最直接影响 coding/data agent 的训练信号;tool-calling 论文最适合马上变成行动前监控;MASPrism 最偏工程维护,它告诉我们小诊断模型可以低成本指向长日志里值得读的部分。
接下来我会追三件事。第一,CLI credit assignment 能否从 bash-heavy 任务迁移到浏览器、notebook 和 GUI action?第二,tool selection 的 activation-gap alarm 在动态工具目录和用户上下文下还能否校准?第三,trace diagnosis 能否用减少人工 debug 时间来评估,而不只是 source-step top-1 accuracy?