Exploration Before Action, Evidence Before Answers
Published:
TL;DR: this round is about agents and world models that should not rush straight to an answer. One paper trains LLM agents to explore an unfamiliar environment before acting. One turns deep research into a shared evidence graph rather than a pile of independent search traces. One asks whether latent video prediction produces world-model representations that survive corruption, occlusion, contact ambiguity, and reversed time.
What I Am Watching This Round
The recent Paper Radar thread has covered tool orchestration, data-agent search, trace diagnosis, and routing geometry. I wanted this issue to avoid repeating the same “make state visible” story. The sharper question this time is: what should a system do before committing?
That led me to three May 15 arXiv papers. Look Before You Leap is about exploration as a trainable skill, not a side effect of task reward. Argus is about assembling missing and contradictory evidence before a deep-research answer. Latent Video Prediction Learns Better World Models is not an agent paper in the narrow sense, but it gives a useful test suite for whether a video representation deserves the “world model” label. I also rebuilt dense tables as Markdown instead of screenshotting them, because the numbers matter and should be readable.
Paper Notes
Look Before You Leap: Autonomous Exploration for LLM Agents
Authors: Ziang Ye, Wentao Shi, Yuxin Liu, Yu Wang, Zhengzhou Cai, Yaorui Shi, Qi Gu, Xunliang Cai, Fuli Feng
Institutions: University of Science and Technology of China; Meituan
Date: May 15, 2026
Links: arXiv, arXiv HTML
Quick idea: the paper argues that task-oriented RL can make agents better at known tasks while making them worse explorers. It introduces Exploration Checkpoint Coverage, trains with explicit exploration rewards, and uses an Explore-then-Act pattern where the agent first maps useful environment facts and only then executes the task.
Why it matters: many long-horizon agent failures look less like missing reasoning and more like premature commitment. The agent assumes a room layout, tool affordance, recipe, or game rule before it has checked the environment. A deployment agent that cannot explore is brittle whenever the UI, database, lab workflow, or simulation differs from the training distribution.
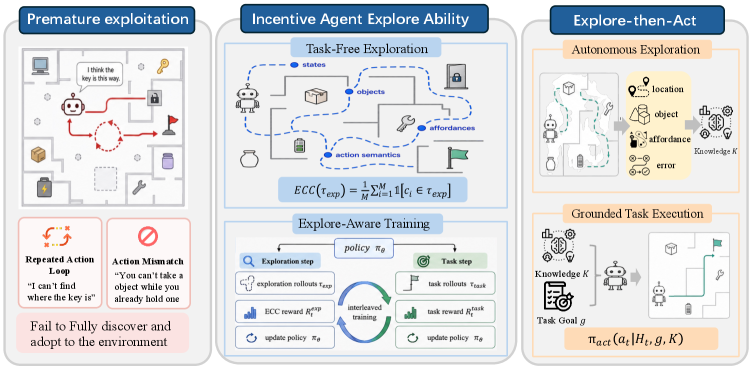
This overview is the paper’s core argument in one picture. Task-only training pushes the agent toward known goal patterns, while exploration-aware training rewards discovering environment structure, objects, and affordances. The caveat is that the authors can define checkpoints in ALFWorld, ScienceWorld, and TextCraft; real software environments may need weaker, noisier checkpoint definitions.
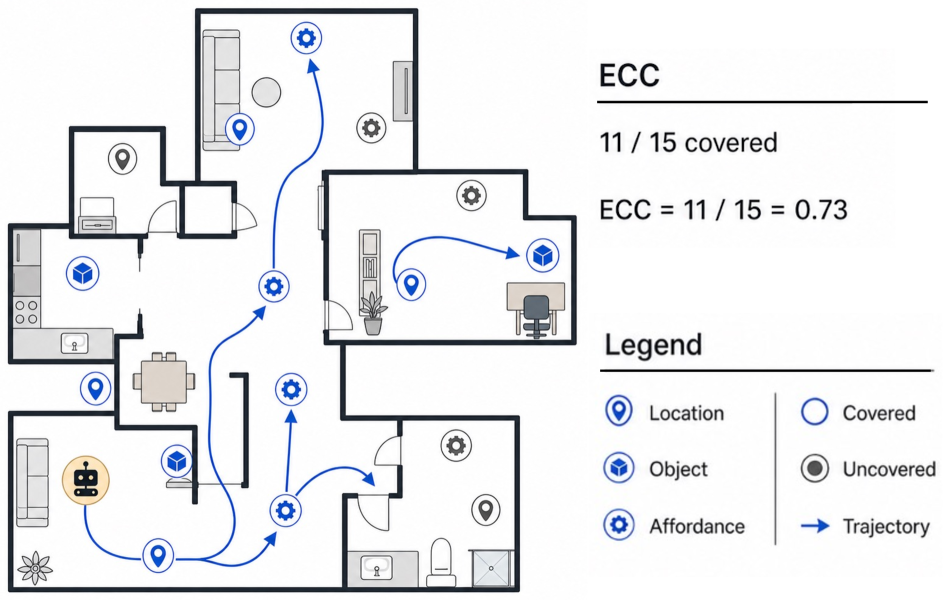
Exploration Checkpoint Coverage, or ECC, measures the fraction of predefined environment checkpoints discovered by a free-exploration trajectory. This is better than counting steps, because a long wandering trace can still miss the useful state. I like the metric because it separates “the model did many actions” from “the model actually learned something about the environment.”
Selected results from the task-free exploration diagnosis:
| Model | Avg ECC across ALFWorld, SciWorld, TextCraft | Avg task delta from Explore-then-Act |
|---|---|---|
| Qwen2.5-7B | 22.2% | -0.7 |
| Qwen2.5-7B + task GRPO | 12.6% | -1.2 |
| Qwen3-4B | 28.5% | -2.2 |
| Qwen3-4B + task GRPO | 18.8% | -0.8 |
| LLaMA3.1-8B | 30.9% | -1.7 |
| GPT-4.1 | 49.3% | +2.0 |
| Claude-Opus-4.5 | 89.5% | +8.6 |
The striking result is not only that stronger closed models explore more. It is that task-oriented GRPO can lower ECC, which supports the paper’s claim that success rewards can produce narrow instrumental policies. Explore-then-Act helps only when the exploration trace contains useful knowledge; shallow exploration becomes extra noise.
The method has three pieces. First, the authors define checkpoints as verifiable states, objects, locations, or affordances for each environment. Second, they train with GRPO under task-only, explore-only, and interleaved schedules; the exploration rollout reward is ECC itself. Third, at inference time, Explore-then-Act lets an explorer spend a fixed budget collecting grounded observations, then passes that knowledge to an executor.
Task success after exploration-aware training:
| Backbone and method | ALFWorld direct | ALFWorld Explore-then-Act | SciWorld direct | SciWorld Explore-then-Act | TextCraft direct | TextCraft Explore-then-Act | Avg direct | Avg Explore-then-Act |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7B zero-shot | 54.4 | 54.1 | 4.9 | 4.3 | 15.4 | 14.3 | 24.9 | 24.2 |
| Qwen2.5-7B task GRPO | 94.4 | 93.2 | 43.9 | 42.6 | 66.8 | 66.5 | 68.4 | 67.4 |
| Qwen2.5-7B interleaved GRPO | 96.9 | 98.5 | 45.8 | 47.2 | 70.1 | 73.7 | 70.9 | 73.1 |
| Qwen3-4B zero-shot | 30.9 | 28.7 | 5.2 | 4.3 | 34.1 | 30.7 | 23.4 | 21.2 |
| Qwen3-4B task GRPO | 84.6 | 84.3 | 54.9 | 53.1 | 82.2 | 83.1 | 73.9 | 73.5 |
| Qwen3-4B interleaved GRPO | 90.5 | 92.7 | 55.2 | 56.9 | 85.9 | 89.0 | 77.2 | 79.5 |
This table is the key evidence that exploration is not just a prettier prompt. Interleaved GRPO improves direct execution and also makes the explicit exploration phase useful. The gains are modest in some environments, but the direction is consistent across the two backbones shown.
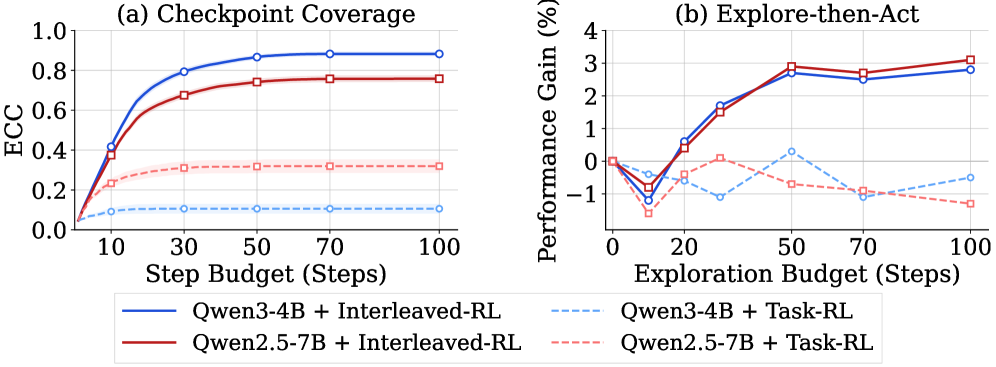
This figure connects exploration budget to downstream ALFWorld performance. It supports a practical point: the value of exploration depends on how quickly the explorer finds high-yield checkpoints. The deployment question is therefore not “should every agent explore?”, but “how much exploration budget should be spent before action?”
Behavior diagnostics from failed direct-execution cases:
| Metric | Task-only training | Exploration-aware training |
|---|---|---|
| Repeated action rate | 63.4% | 24.9% |
| Loop rate | 16.0% | 7.7% |
| Info-seeking rate | 1.0% | 7.5% |
| Error recovery rate | 0.0% | 20.1% |
This table explains why the training helps even without a separate exploration phase. The exploration-aware agent repeats invalid actions less often and recovers from errors more often. My read is that the reward is teaching a behavioral reflex: check state, look for alternatives, and stop hammering the same failed action.
My judgment: this is a strong agentic-training paper because it names a capability that task reward often suppresses. The limitation is checkpoint construction. ECC is clean in benchmark environments, but enterprise workflows, GUI apps, and scientific tools need checkpoint extraction that is reliable without being hand-built for every task.
Connection to tracked themes: agentic training, exploration, verifiable rewards, long-horizon agents, and environment-grounded state.
Argus: Evidence Assembly for Scalable Deep Research Agents
Authors: Zhen Zhang, Liangcai Su, Zhuo Chen, Xiang Lin, Haotian Xu, Simon Shaolei Du, Kaiyu Yang, Bo An, Lidong Bing, Xinyu Wang
Institutions: MiroMind AI
Date: May 15, 2026
Links: arXiv, arXiv HTML
Quick idea: Argus treats deep research as evidence assembly. A Searcher collects ReAct-style traces, while a Navigator builds a directed evidence graph, verifies missing or contradictory claims, dispatches more searches, and synthesizes a source-traced answer from the graph.
Why it matters: parallel search agents often waste compute retrieving overlapping evidence. Long single-agent rollouts have the opposite problem: everything is trapped in one growing context. Argus gives the intermediate research state a shape: evidence nodes, claim nodes, and support or contradiction edges. That structure is the real contribution.
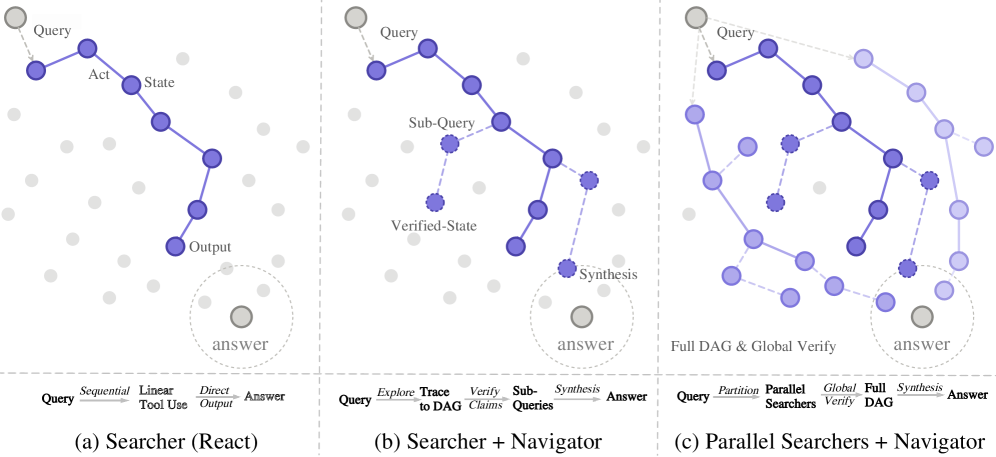
This figure contrasts a standalone Searcher with Navigator-guided and parallel Argus modes. The difference is not just more search calls; the Navigator asks targeted follow-up questions for unfilled pieces. That is exactly the failure mode I care about in deep research agents: more rollouts should cover missing evidence, not vote on the same partial answer.
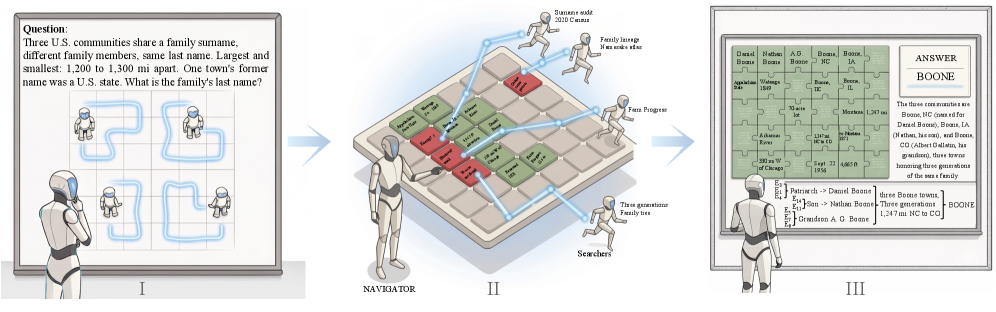
The case figure shows the shared evidence board. Green pieces are corroborated, red pieces are discarded, and the final answer traces claims back to evidence nodes. I would not treat the visual board as proof that the system is always faithful, but it makes the audit surface explicit enough to inspect.
The Navigator’s graph can be summarized as:
G = (E, C, A)
A subset of (E union C) x C x {support, contradict}
E stores evidence, C stores claims, and the labeled edges say whether an evidence or claim node supports or contradicts another claim. During training, the Navigator produces a synthesis with verification and a shadow synthesis without verification. The reward clips a combination of answer score and the verification improvement, so the model is rewarded when the evidence graph actually improves the final answer.
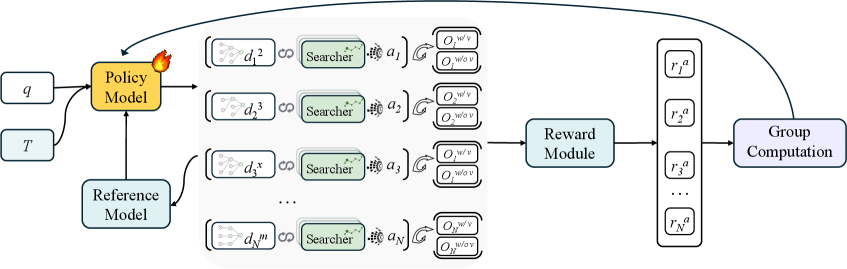
The training pipeline is useful because gradients are applied only to Navigator-generated tokens. Searcher trajectories and external inputs are masked, so the trained component is the graph-building and synthesis policy rather than the web-search actor itself. The risk is that this separates orchestration from retrieval quality: if the Searcher cannot find the right pages, the Navigator cannot invent evidence.
Selected BrowseComp results across Searcher backbones:
| Searcher backbone | Searcher | Argus-Solo | Majority vote, K=8 | LLM aggregation, K=8 | Argus-Parallel, K=8 |
|---|---|---|---|---|---|
| Searcher-35B-A3B | 55.0 | 62.2 | 56.2 | 56.5 | 74.5 |
| DeepSeek-V4-Flash-Max | 64.0 | 68.0 | 60.0 | 69.0 | 78.5 |
| Seed-2.0-Pro | 70.2 | 78.6 | 67.0 | 73.8 | 82.4 |
This table is the most compact evidence for the paper’s thesis. With identical or comparable search budgets, graph-guided parallelism beats majority voting and generic LLM aggregation. The gains also rise with stronger Searchers, which is a useful caveat: Argus improves orchestration, not source availability.
Graph representation ablation:
| Variant | What the Navigator sees | BrowseComp |
|---|---|---|
| Full DAG | Evidence, claims, support or contradiction edges, status, corroboration strength | 74.5 |
| Bare graph | Evidence and claims with unlabeled edges and coarse status | 72.0 |
| Text only | Concatenated evidence and claims in extraction order | 69.3 |
This ablation matters because it tests whether the graph is decorative. Removing labeled edges and status hurts, and flattening the same material into text hurts more. The numbers support the claim that evidence structure changes synthesis, not just presentation.
The main benchmark table covers BrowseComp, BrowseComp-ZH, GAIA, SEAL-0, xbench DeepSearch-2510, Humanity’s Last Exam, and FrontierScience variants. The reported Argus-35B-A3B Parallel row improves over its Searcher on every listed benchmark, including BrowseComp 55.0 to 74.5, BrowseComp-ZH 62.3 to 83.4, GAIA 84.5 to 93.2, and FrontierScience Research 5.4 to 25.0. I am cautious about comparing these numbers directly with proprietary agents because the table mixes official reports, reproduced settings, and different system assumptions; the cleaner comparison is Searcher versus Argus under the authors’ own setup.
My judgment: Argus is a strong document-intelligence and deep-research-agent paper because it moves from “retrieve more” to “assemble missing evidence.” The limitation is cost. The paper notes that Searcher token consumption grows from 0.4M at K=1 to 25.6M at K=64, so this is a high-compute approach for questions where the answer justifies the budget.
Connection to tracked themes: document intelligence, deep research agents, evidence graphs, source attribution, and parallel agent orchestration.
Latent Video Prediction Learns Better World Models
Authors: Ali J Alrasheed, Aryan Yazdan Parast, Basim Azam, James Bailey, Naveed Akhtar
Institutions: The University of Melbourne; Monash University
Date: May 15, 2026
Links: arXiv, arXiv HTML
Quick idea: the paper evaluates whether latent-prediction video models behave more like usable world models than pixel-reconstruction or contrastive baselines. It compares V-JEPA 2.1, V-JEPA 2, VideoPrism, and VideoMAEv2 across five robustness axes rather than relying on one clean top-1 score.
Why it matters: “world model” is becoming a loose label for video foundation models. A representation that works on clean action classification may still fail under sensor noise, missing frames, contact ambiguity, or reversed temporal order. This paper is useful because it asks what properties a video world model should preserve before it is used for planning or embodied reasoning.
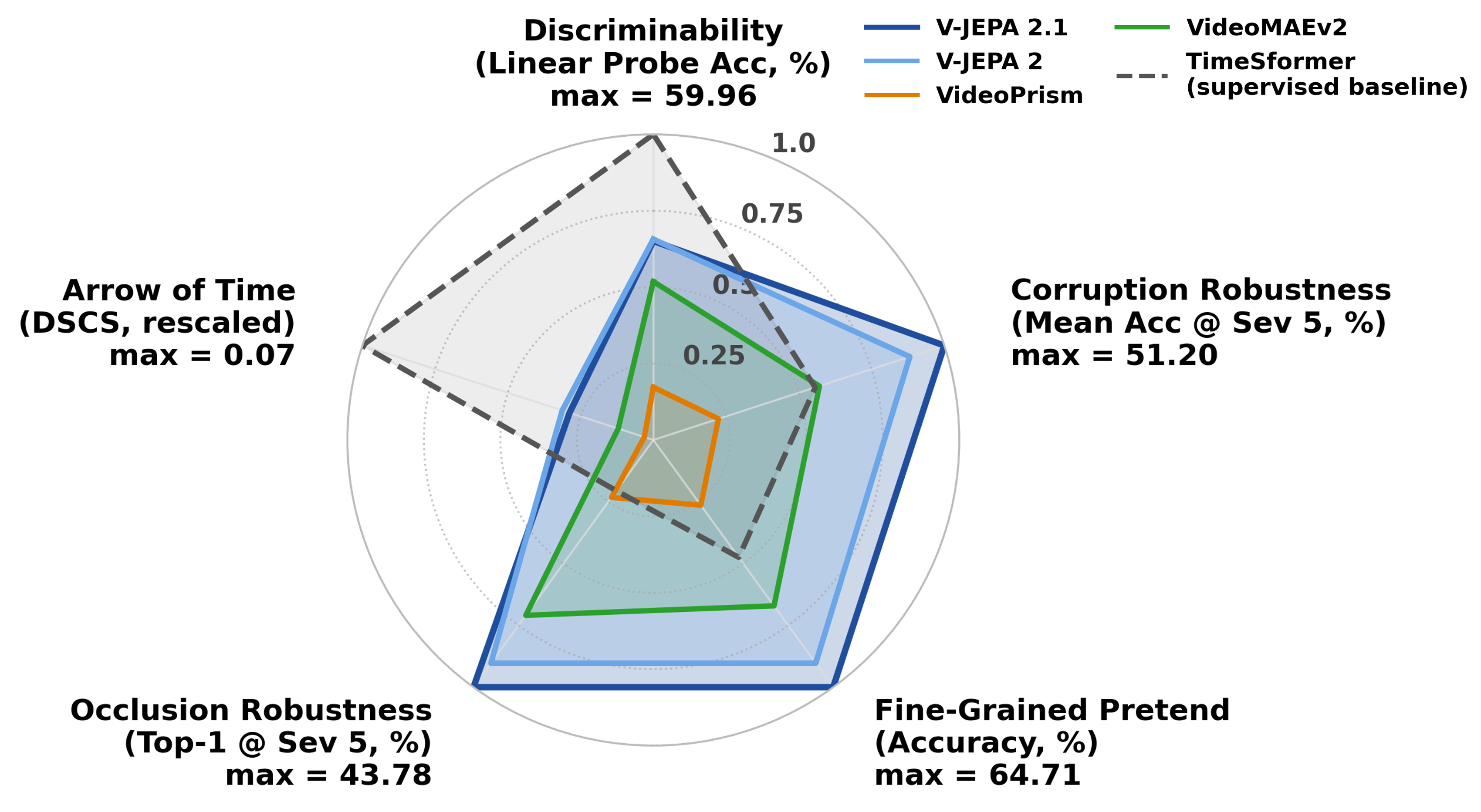
The radar plot summarizes the paper’s multi-axis evaluation on Something-Something v2. V-JEPA variants form the most balanced profiles across discriminability, corruption robustness, fine-grained action discrimination, occlusion robustness, and temporal direction sensitivity. The important caveat is that this is still representation evaluation, not closed-loop planning.
The model comparison behind the experiments:
| Model | Approx params | Pretraining data | Objective | Source |
|---|---|---|---|---|
| V-JEPA 2.1 | 300M | Internet video, over 1M hours | Latent prediction | Meta |
| V-JEPA 2 | 300M | Internet video, over 1M hours | Latent prediction | Meta |
| VideoPrism | 300M | Video plus video-text pairs, 36M clips | Contrastive plus masked prediction | |
| VideoMAEv2 | 300M | Public unlabeled hybrid data | Pixel reconstruction | Open source |
This table matters because the comparison is not simply “bigger model wins.” All four encoders use ViT-Large in the main frozen-encoder comparison, but the objectives differ. The paper’s central claim is that latent prediction changes what the representation keeps.
The evaluation suite uses Something-Something v2, with more than 220,000 videos across 174 human-object interaction classes. The authors probe feature discriminability on 600 videos from 30 classes, corruption robustness on 500 balanced videos under six ImageNet-C corruptions, pretend-action discrimination on 1,992 videos from 22 classes, occlusion robustness on 1,740 videos, and temporal robustness through shuffling, reversal, static replacement, and noise injection. That design is why I selected the paper: it turns “world model” into testable properties.
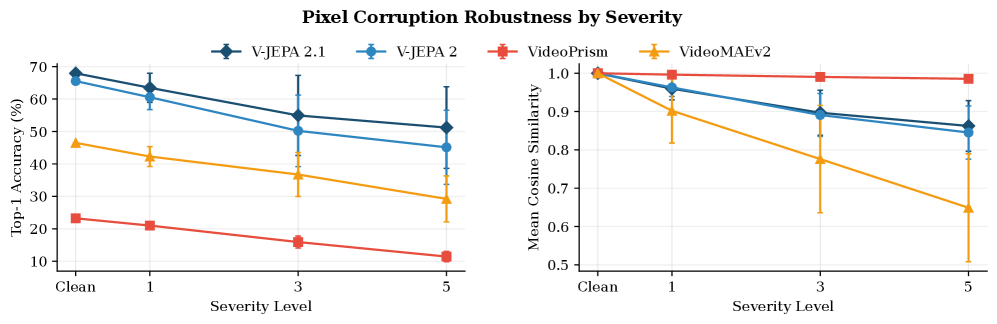
This figure compares classification accuracy and cosine similarity as corruption severity increases. The main lesson is subtle: representational stability is not enough. VideoPrism can keep embeddings geometrically stable while losing decision usefulness, so a world-model evaluation should check both feature stability and downstream class structure.
The pretend-action section is especially relevant for embodied agents. V-JEPA variants outperform VideoMAEv2 on classes where the signal is the absence of contact, such as pretending to pick something up or pretending to pour. The authors argue that latent prediction must preserve higher-level physical state changes, while pixel reconstruction spends capacity on texture and color details that may not distinguish real interaction from simulated interaction.
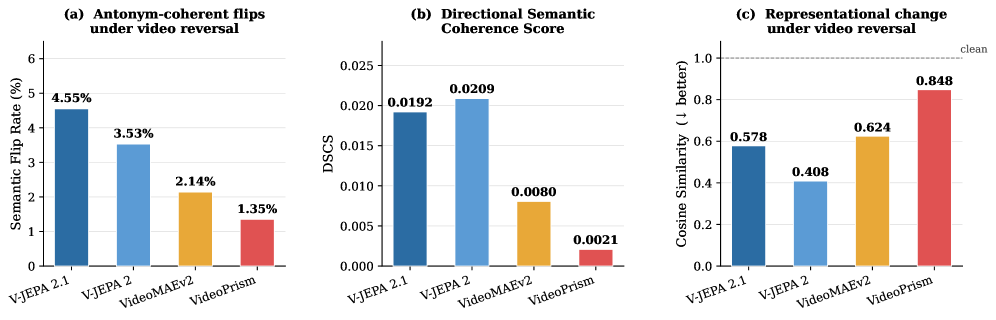
The reversal figure asks whether a model encodes the arrow of time. The paper measures semantic flip rate, directional semantic coherence, and cosine similarity between clean and reversed embeddings. V-JEPA models show stronger directional semantics, while stable embeddings from other models can hide temporal insensitivity.
Selected temporal robustness result from the appendix:
| Model | Temporal Dependency Index |
|---|---|
| VideoPrism | 0.17 |
| V-JEPA 2.1 | 0.51 |
| VideoMAEv2 | 0.64 |
| V-JEPA 2 | 0.68 |
The authors interpret this carefully. Low dependency can mean temporal blindness, while high dependency can mean fragility. V-JEPA 2.1 is interesting because it combines moderate temporal sensitivity with high accuracy, which is closer to what I would want from a planning-facing representation.
My judgment: this is not a complete world-model validation, but it is a useful pressure test for the term. The paper does not show action-conditioned rollouts, counterfactual planning, or closed-loop control. It does show that latent-prediction encoders retain physical and temporal distinctions that clean classification misses, and that is a concrete step toward better world-model evaluation.
Connection to tracked themes: world models, latent prediction, representation robustness, physical contact cues, and temporal reasoning.
Reading Priority and Next Questions
My priority order is Argus, Look Before You Leap, then the latent video world-model evaluation. Argus is closest to a deployable research-agent bottleneck: evidence should be assembled, not merely retrieved. Look Before You Leap is the stronger training signal paper, especially for agents that enter unfamiliar environments. The video paper is a useful evaluation lens for future embodied-agent and world-model work.
Next questions I would track:
- Can exploration checkpoints be derived automatically from GUI, database, or lab environments without hand-authoring a checklist?
- Can deep-research evidence graphs expose enough provenance for human editing, contradiction review, and stale-source detection?
- Can agentic RL systems decide when exploration is worth the extra budget rather than always running Explore-then-Act?
- Can video world-model robustness predict closed-loop planning success, or is it only a representation-level proxy?