先探索再行动,先组证据再作答
Published:
TL;DR:本期我关注的是智能体和世界模型在作答或行动之前应该先做什么。一篇论文把“探索陌生环境”做成可训练能力,而不是指望任务奖励顺便学出来;一篇论文把 deep research 从多条搜索轨迹的投票,改成共享证据图的组装;一篇论文则追问视频 latent prediction 到底有没有学到更像世界模型的表示,而不只看干净分类准确率。
本期我在看什么
最近几期 Paper Radar 已经写过工具路径选择、数据智能体搜索、trace 诊断和 MoE 路由几何。如果这期继续只说“中间状态要可见”,会有点重复。所以我这次换了一个更具体的问题:系统在承诺答案或动作之前,应该先检查、探索或组装什么?
最后选了三篇 2026 年 5 月 15 日的 arXiv 论文。Look Before You Leap 讨论探索作为训练目标;Argus 讨论 deep research 里的证据图;Latent Video Prediction Learns Better World Models 不是狭义 agent 论文,但它给“世界模型”这个词提供了更像样的鲁棒性检验。我也继续把密集结果表改写成 Markdown 表格,避免把小字截图塞进正文。
论文细读笔记
Look Before You Leap:先探索,再行动
作者:Ziang Ye、Wentao Shi、Yuxin Liu、Yu Wang、Zhengzhou Cai、Yaorui Shi、Qi Gu、Xunliang Cai、Fuli Feng
机构:University of Science and Technology of China;Meituan
日期:2026-05-15
链接:arXiv,arXiv HTML
一句话核心 idea:这篇论文认为,面向任务成功率的 RL 可能让智能体更会做已知任务,却更不会探索陌生环境。作者提出 Exploration Checkpoint Coverage,用显式探索奖励训练智能体,并在推理时采用 Explore-then-Act:先用固定预算摸清环境,再把获得的知识交给执行阶段。
为什么重要:很多长程智能体失败并不是因为不会推理,而是太早承诺。它假设房间布局、工具功能、配方规则或交互条件和训练时一样,然后一直执行一个错误计划。真正部署到 GUI、数据库、实验室流程或模拟环境里时,不会探索的智能体很脆。
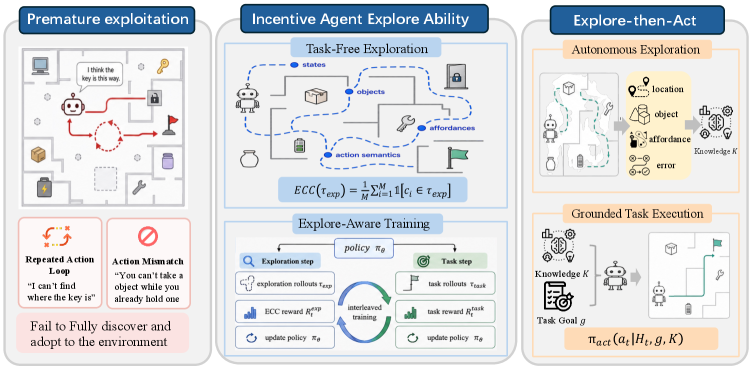
这张图概括了论文的主张。task-only training 会把模型推向熟悉的目标模式,而 exploration-aware training 奖励模型发现环境结构、对象和 affordance。需要谨慎的是,ALFWorld、ScienceWorld 和 TextCraft 里可以定义清楚 checkpoint;真实软件和业务流程里的 checkpoint 往往更噪声、更难自动抽取。
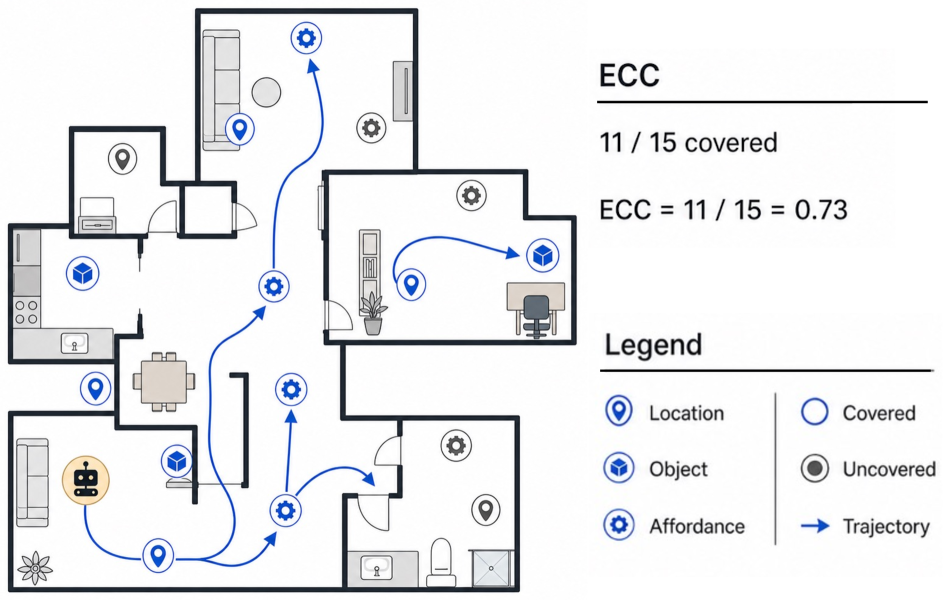
ECC 衡量自由探索轨迹发现了多少预定义环境 checkpoint。它比“走了多少步”更有意义,因为长轨迹也可能只是在原地绕圈。这个指标的价值在于把“模型动作很多”和“模型真的获得环境知识”分开了。
无任务探索诊断的部分结果如下:
| 模型 | ALFWorld、SciWorld、TextCraft 平均 ECC | Explore-then-Act 带来的平均任务变化 |
|---|---|---|
| Qwen2.5-7B | 22.2% | -0.7 |
| Qwen2.5-7B + task GRPO | 12.6% | -1.2 |
| Qwen3-4B | 28.5% | -2.2 |
| Qwen3-4B + task GRPO | 18.8% | -0.8 |
| LLaMA3.1-8B | 30.9% | -1.7 |
| GPT-4.1 | 49.3% | +2.0 |
| Claude-Opus-4.5 | 89.5% | +8.6 |
最值得注意的不只是闭源强模型探索更多,而是 task-oriented GRPO 可能降低 ECC。这个结果支持了作者的判断:只奖励任务完成,容易学出狭窄的工具性策略。Explore-then-Act 也不是万能,只有探索轨迹真的包含可用知识时,它才会帮助后续执行。
方法拆开看有三步。第一步,把 checkpoint 定义成可验证的状态、对象、位置或 affordance。第二步,用 GRPO 分别训练 task-only、explore-only 和 interleaved 三种设置,其中探索轨迹的奖励就是 ECC。第三步,推理时先让 explorer 在固定预算内收集环境知识,再让 executor 带着这些知识完成任务。
探索感知训练后的任务成功率如下:
| Backbone 与方法 | ALFWorld 直接执行 | ALFWorld 先探索再执行 | SciWorld 直接执行 | SciWorld 先探索再执行 | TextCraft 直接执行 | TextCraft 先探索再执行 | 平均直接执行 | 平均先探索再执行 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7B zero-shot | 54.4 | 54.1 | 4.9 | 4.3 | 15.4 | 14.3 | 24.9 | 24.2 |
| Qwen2.5-7B task GRPO | 94.4 | 93.2 | 43.9 | 42.6 | 66.8 | 66.5 | 68.4 | 67.4 |
| Qwen2.5-7B interleaved GRPO | 96.9 | 98.5 | 45.8 | 47.2 | 70.1 | 73.7 | 70.9 | 73.1 |
| Qwen3-4B zero-shot | 30.9 | 28.7 | 5.2 | 4.3 | 34.1 | 30.7 | 23.4 | 21.2 |
| Qwen3-4B task GRPO | 84.6 | 84.3 | 54.9 | 53.1 | 82.2 | 83.1 | 73.9 | 73.5 |
| Qwen3-4B interleaved GRPO | 90.5 | 92.7 | 55.2 | 56.9 | 85.9 | 89.0 | 77.2 | 79.5 |
这张表说明,探索并不是换一种 prompt 包装。interleaved GRPO 同时提高直接执行和先探索再执行的表现。部分环境提升并不夸张,但两个 backbone 上方向一致。
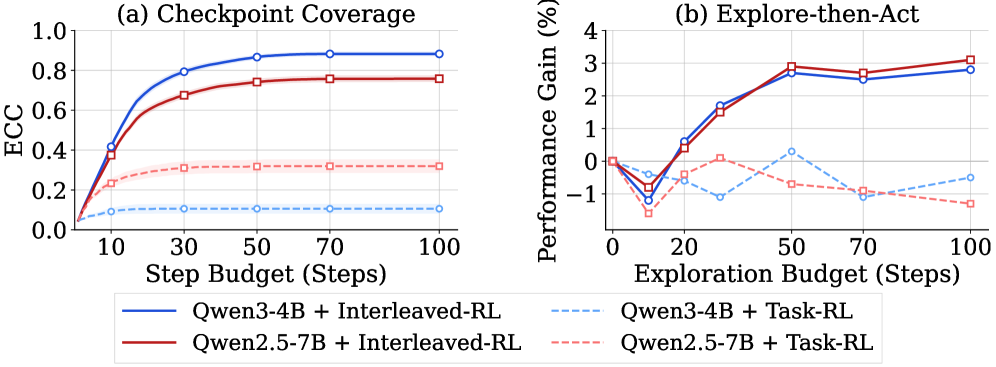
这张图把探索预算和 ALFWorld 下游表现连起来。它提醒我,探索的价值取决于 explorer 多快找到高价值 checkpoint。部署时真正的问题不是“要不要探索”,而是“行动前花多少预算探索才划算”。
失败样本中的行为诊断如下:
| 指标 | task-only training | exploration-aware training |
|---|---|---|
| 重复动作率 | 63.4% | 24.9% |
| 循环率 | 16.0% | 7.7% |
| 信息寻求率 | 1.0% | 7.5% |
| 错误恢复率 | 0.0% | 20.1% |
这张表解释了为什么探索训练即使在没有单独探索阶段时也有帮助。模型少重复无效动作,多寻找信息,也更会从错误中恢复。我的理解是,奖励并不只是让模型“多走走”,而是在训练一种反射:先检查状态,发现不对就换策略。
我的判断:这是一篇很好的 agentic training 论文,因为它点名了一个容易被任务奖励压掉的能力。弱点是 checkpoint 构造。ECC 在 benchmark 里很干净,但如果迁移到企业 GUI、数据库或实验工具,如何自动生成可靠 checkpoint 会是关键难题。
对应主题:agentic training、探索、verifiable rewards、长程智能体、环境状态。
Argus:把 deep research 变成证据图组装
作者:Zhen Zhang、Liangcai Su、Zhuo Chen、Xiang Lin、Haotian Xu、Simon Shaolei Du、Kaiyu Yang、Bo An、Lidong Bing、Xinyu Wang
机构:MiroMind AI
日期:2026-05-15
链接:arXiv,arXiv HTML
一句话核心 idea:Argus 把 deep research 看成证据组装问题。Searcher 负责跑 ReAct 式搜索轨迹;Navigator 维护有向证据图,识别缺失和矛盾,派发新的搜索,再基于图合成可追溯来源的答案。
为什么重要:并行搜索智能体常见的问题是重复找同一类证据,长单轨迹智能体则容易把所有东西塞进越来越长的上下文。Argus 给中间研究状态一个结构:证据节点、claim 节点、支持或反驳边。这个结构比“多跑几条搜索”更关键。
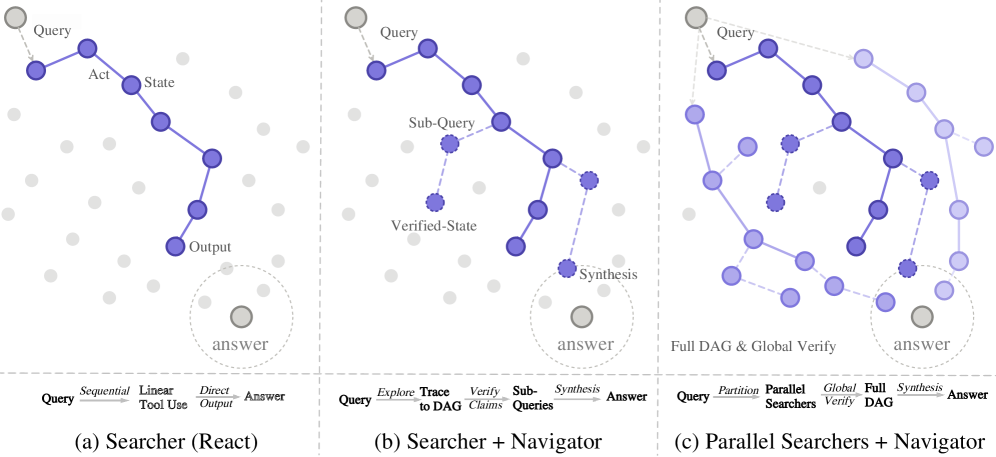
这张图对比了单个 Searcher、Navigator 引导搜索和并行 Argus。区别不是搜索次数更多,而是 Navigator 会针对未填补的证据块发起查询。这正是我关心的 deep research 失败模式:更多 rollout 应该覆盖缺失证据,而不是对同一个半成品答案投票。
案例图展示了共享 evidence board。绿色代表被支持的证据块,红色代表被丢弃的探针,最终答案中的 claim 可以追溯到证据节点。我不会把这张图理解成系统永远忠实,但它确实给审计留下了一个具体表面。
Navigator 的图可以简化成:
G = (E, C, A)
A subset of (E union C) x C x {support, contradict}
E 是证据,C 是 claim,带标签的边说明某个证据或 claim 支持还是反驳另一个 claim。训练时,Navigator 会产生一个带 verification 的 synthesis,以及一个不带 verification 的 shadow synthesis。奖励把答案得分和 verification 带来的增益组合起来,所以模型只有在证据图真的改善答案时才会受益。
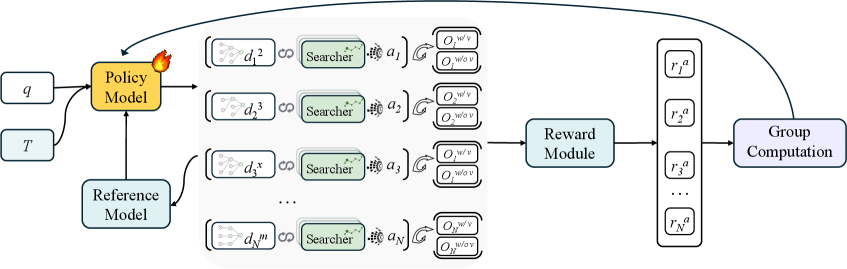
训练图里有一个重要细节:梯度只作用在 Navigator 生成的 token 上。Searcher 轨迹和外部输入被 mask 掉,因此训练的是图构建和合成策略,而不是搜索 actor 本身。风险也在这里:如果 Searcher 找不到关键网页或资料,Navigator 无法凭空补出证据。
BrowseComp 上不同 Searcher backbone 的结果如下:
| Searcher backbone | Searcher | Argus-Solo | Majority vote, K=8 | LLM aggregation, K=8 | Argus-Parallel, K=8 |
|---|---|---|---|---|---|
| Searcher-35B-A3B | 55.0 | 62.2 | 56.2 | 56.5 | 74.5 |
| DeepSeek-V4-Flash-Max | 64.0 | 68.0 | 60.0 | 69.0 | 78.5 |
| Seed-2.0-Pro | 70.2 | 78.6 | 67.0 | 73.8 | 82.4 |
这张表最紧凑地支持了论文论点。在相同或可比的搜索预算下,图引导并行比 majority voting 和普通 LLM aggregation 更好。它也说明另一个事实:Searcher 越强,Argus 上限越高;Argus 改善的是编排,不是资料本身是否存在。
图表示消融如下:
| 变体 | Navigator 看到什么 | BrowseComp |
|---|---|---|
| Full DAG | 证据、claim、支持或反驳边、状态、corroboration strength | 74.5 |
| Bare graph | 证据和 claim,边没有正负标签,只有粗粒度状态 | 72.0 |
| Text only | 按抽取顺序拼接证据和 claim,无边、无状态 | 69.3 |
这个消融很重要,因为它测试证据图是不是装饰。去掉边标签和状态会掉分,把同样材料压平成文本掉得更多。也就是说,结构本身确实改变了 synthesis,而不只是把结果展示得好看一点。
主结果表覆盖 BrowseComp、BrowseComp-ZH、GAIA、SEAL-0、xbench DeepSearch-2510、Humanity’s Last Exam 和 FrontierScience 变体。论文报告 Argus-35B-A3B Parallel 相比 Searcher 在所有列都有提升,比如 BrowseComp 从 55.0 到 74.5,BrowseComp-ZH 从 62.3 到 83.4,GAIA 从 84.5 到 93.2,FrontierScience Research 从 5.4 到 25.0。和闭源系统的横向比较我会谨慎看,因为表里混合了官方报告、复现实验和不同系统假设;最干净的比较还是作者设置里的 Searcher 对 Argus。
我的判断:Argus 是一篇很贴近 document intelligence 和 deep research agent 的论文,因为它把“多检索”推进到“组装缺失证据”。限制是成本。论文提到 Searcher token consumption 从 K=1 的 0.4M 增长到 K=64 的 25.6M,因此这更适合答案价值足够高、需要来源追踪的问题。
对应主题:文档智能、deep research agents、证据图、source attribution、并行智能体编排。
Latent Video Prediction Learns Better World Models:世界模型不能只看干净准确率
作者:Ali J Alrasheed、Aryan Yazdan Parast、Basim Azam、James Bailey、Naveed Akhtar
机构:The University of Melbourne;Monash University
日期:2026-05-15
链接:arXiv,arXiv HTML
一句话核心 idea:这篇论文评估 latent-prediction 视频模型是否比像素重建或对比学习 baseline 更像可用世界模型。作者比较 V-JEPA 2.1、V-JEPA 2、VideoPrism 和 VideoMAEv2,不只看一个干净 top-1,而是看五个鲁棒性维度。
为什么重要:“world model” 这个词现在被用得很宽。一个模型在干净动作分类上表现好,不代表它能处理传感器噪声、遮挡、缺帧、接触细节或时间反转。本文有价值的地方,是把世界模型表示应该保留的性质拆成可测项。
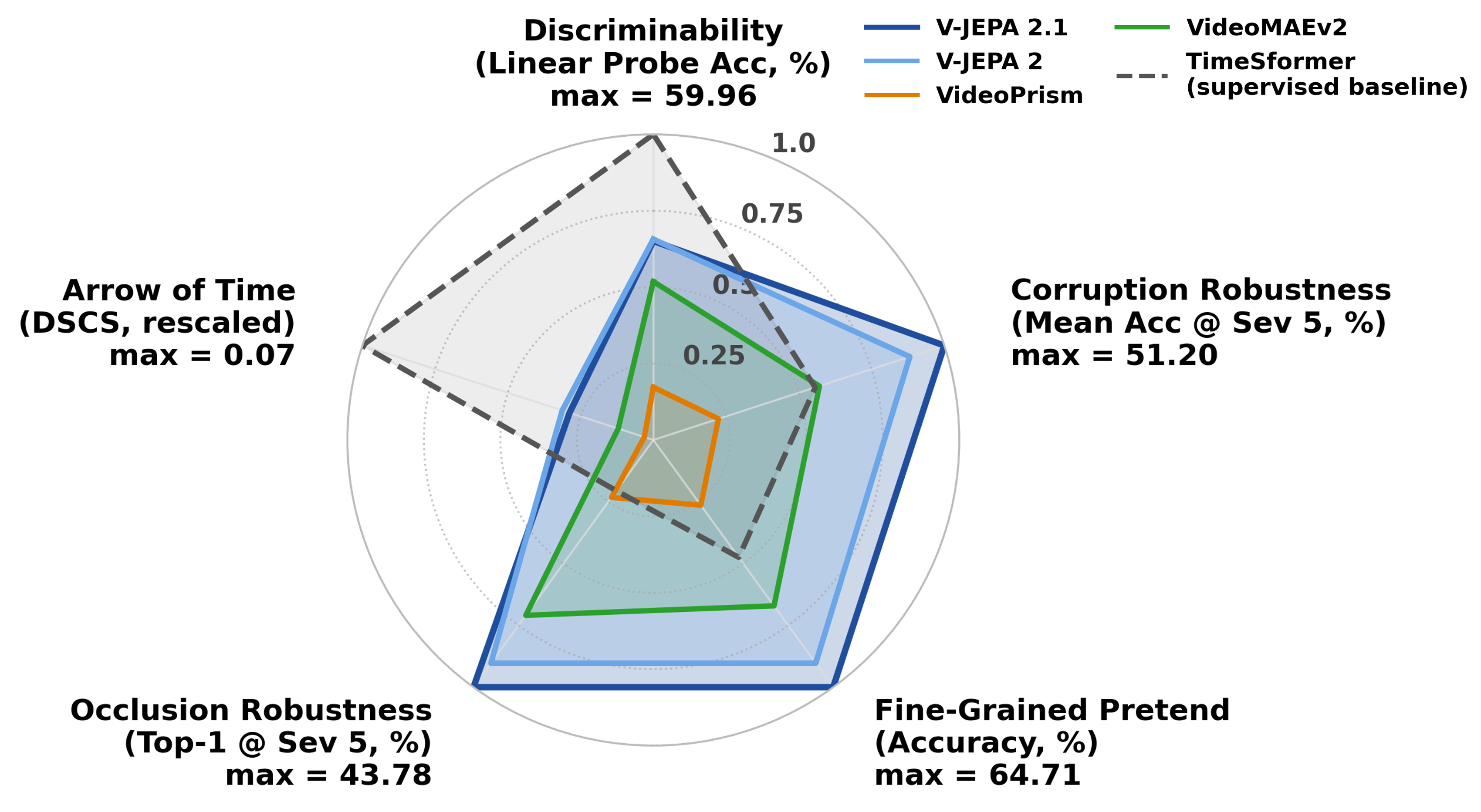
雷达图总结了 Something-Something v2 上的多轴评估。V-JEPA 系列在可分性、腐蚀鲁棒性、细粒度动作区分、遮挡鲁棒性和时间方向敏感性上更均衡。需要注意的是,这仍是表示评估,不是闭环规划或控制实验。
实验中的模型对比如下:
| 模型 | 参数量约数 | 预训练数据 | 目标 | 来源 |
|---|---|---|---|---|
| V-JEPA 2.1 | 300M | 超过 100 万小时互联网视频 | latent prediction | Meta |
| V-JEPA 2 | 300M | 超过 100 万小时互联网视频 | latent prediction | Meta |
| VideoPrism | 300M | 视频加视频文本对,3600 万 clips | contrastive plus masked prediction | |
| VideoMAEv2 | 300M | 公共无标签混合数据 | pixel reconstruction | open source |
这张表说明比较不是简单的“大模型赢”。主实验里四个 encoder 都是 ViT-Large 量级,但训练目标不同。论文核心 claim 是 latent prediction 会改变表示保留什么信息。
评测基于 Something-Something v2,包含 22 万多个视频和 174 类人和物体交互。作者分别评估:30 类 600 个视频上的 feature discriminability,500 个平衡视频上的六类 ImageNet-C corruption,22 类 1992 个视频上的 pretend-action discrimination,174 类 1740 个视频上的遮挡鲁棒性,以及 frame shuffling、reversal、static replacement、noise injection 等时间扰动。这个设计是我选它的原因:它把“世界模型”拆成了一组具体压力测试。
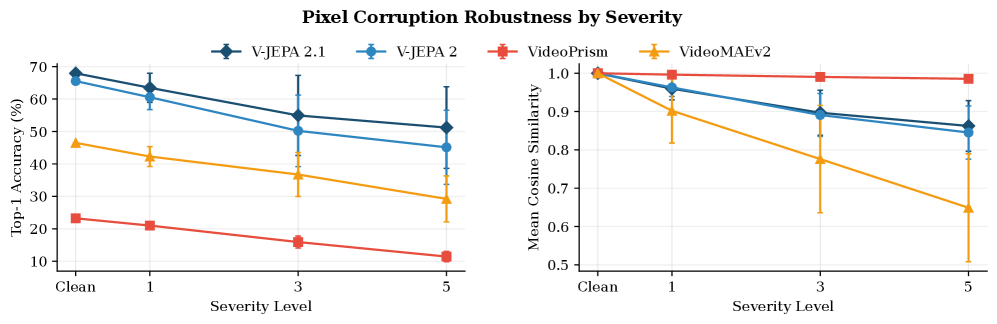
这张图比较了 corruption severity 增大时的分类准确率和 embedding cosine similarity。它给出的提醒很细:表示稳定不等于决策有用。VideoPrism 的 embedding 可以很稳定,但分类结构仍然受损,所以世界模型评估不能只看特征几何是否变化小。
pretend action 部分对 embodied agent 特别有意思。V-JEPA 系列在需要识别“没有真实接触”的类别上优于 VideoMAEv2,例如假装拿起、假装倒出等。作者的解释是,latent prediction 需要保留更高层的物理状态变化,而像素重建会把容量花在纹理和颜色上,这些细节不一定能区分真实交互和假动作。
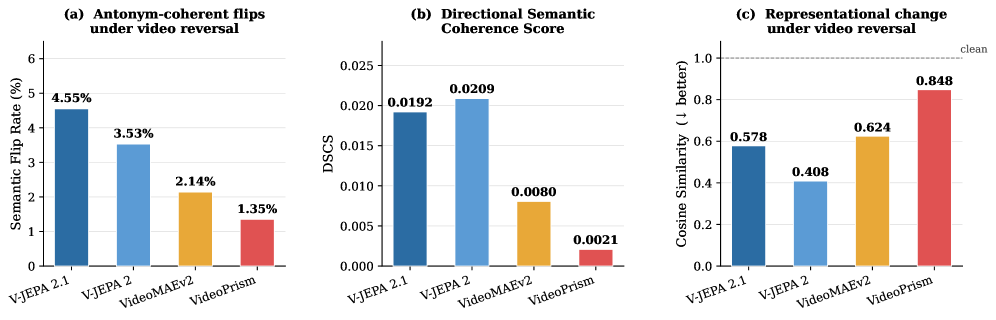
这张图问的是模型是否编码时间箭头。论文使用 semantic flip rate、directional semantic coherence 和 clean/reversed embedding cosine similarity 来衡量。V-JEPA 系列表现出更强的方向语义,而其他模型的稳定 embedding 可能掩盖了时间不敏感。
附录中的一个时间鲁棒性指标如下:
| 模型 | Temporal Dependency Index |
|---|---|
| VideoPrism | 0.17 |
| V-JEPA 2.1 | 0.51 |
| VideoMAEv2 | 0.64 |
| V-JEPA 2 | 0.68 |
这个指标不能简单理解成越高越好。低依赖可能是时间盲,高依赖也可能是脆弱。V-JEPA 2.1 有意思的地方是,它在保持较高准确率的同时只有中等时间敏感性,这更像规划表示需要的平衡。
我的判断:这篇还不能完整证明某个视频模型就是世界模型,但它给了一个比 clean top-1 更好的检验方式。论文没有展示 action-conditioned rollout、counterfactual planning 或闭环控制。不过它确实说明,latent-prediction encoder 能保留一些干净分类看不出来的物理和时间差异。
对应主题:世界模型、latent prediction、表示鲁棒性、物理接触线索、时间推理。
阅读优先级和下期问题
我的优先级是 Argus、Look Before You Leap,然后是 latent video world-model 评测。Argus 最贴近 deep research agent 的部署瓶颈:证据应该被组装,而不是只被检索。Look Before You Leap 是更强的训练信号论文,尤其适合进入陌生环境的 agent。视频论文则给后续 embodied agent 和 world model 提供了一个评测视角。
下期我会继续追这几个问题:
- 探索 checkpoint 能不能从 GUI、数据库或实验环境中自动抽取,而不是人工列清单?
- deep research 的证据图能不能支持人类编辑、矛盾复核和 stale source 检测?
- agentic RL 能不能学会何时探索值得花预算,而不是固定先 Explore-then-Act?
- 视频世界模型的表示鲁棒性,能否预测闭环规划表现,还是只是一种 representation-level proxy?